我们知道,数组的最大特点就是:寻址容易,插入和删除困难;而链表正好相反,寻址困难,而插入和删除操作容易。那么如果能够结合两者的优点,做出一种寻址、插入和删除操作同样快速容易的数据结构,那该有多好。这就是哈希表创建的基本思想,而实际上哈希表也实现了这样的一个“夙愿”,哈希表就是这样一个集查找、插入和删除操作于一身的数据结构。
1. 与Collection的不同
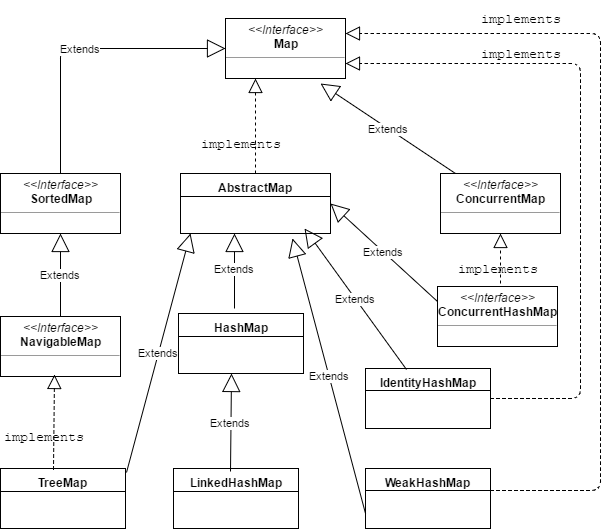
Map接口下的集合与Collection接口下的集合,它们存储数据的形式不同:
a:Collection中元素是孤立存在的(理解为单身),向集合中存储元素采用一个个元素的方式存储。
b:Map接口下的集合,元素是成对存在的(理解为夫妻)。每个元素由key与value两部分组成,通过key可以找对所对应的value。
需要注意的是,Map中的集合不能包含重复的key,值可以重复;每个key只能对应一个值。
2. Map接口中的常用方法
- V remove(K key) ==> 移除集合中的键值对,返回被移除之前的值
- V get(K key) ==> 通过键对象,获取值对象。 如果集合中没有这个键,返回null
- V getOrDefault(K key, V default) ==> 如果对象不存在,就返回一个默认值
- V put(K key,V value) ==> 将键值对存储到集合中。存储的是重复的键,将原有的值覆盖。如果是添加,返回null。如果是update,返回原来的值。
- boolean containsKey(K)
- boolean containsValue(V)
- 遍历:foreach 不能遍历 Map 但是可以遍历Map的 KeySet 或者 EntrySet ```java for(String key : map.keySet()){ //这个set是 HashMap$KeySet Person value = map.get(key); System.out.println(key+”…”+value); }
for(Map.Entry
- void putAll(map)<a name="uuDsY"></a># 3. HashMap设计原理设计出一个简单、均匀、存储利用率高的散列函数是散列技术中最关键的问题。但是,一般散列函数都面临着冲突的问题。两个不同的关键字,由于散列函数值相同,因而被映射到同一表位置上。该现象称为冲突(Collision)或碰撞。为了实现哈希表的创建,这些所有的方法都离不开两个问题——“定址”和“解决冲突”让我们来学习下HashMap的设计:<br />众所周知,HashMap 是一个用于存储Key-Value键值对的集合,每一个键值对也叫做 Entry。这些个键值对(Entry)分散存储在一个数组当中,这个数组就是HashMap的主干。<br />**HashMap 数组每一个元素的初始值都是 Null。**<a name="T6tBS"></a># A. HashMap的默认初始化HashMap的默认初始长度是16,并且每次自动扩展或手动初始化时,长度必须时2的幂。(和下面的hash值位运算有关)[**HashMap加载因子一定是0.75**](https://zhuanlan.zhihu.com/p/149687607)<a name="w7nzX"></a>## B. Put and Get 方法<a name="FNZjG"></a>### a. Put 方法:比如调用 hashMap.put("apple", 0) ,插入一个Key为“apple"的元素。这时候我们需要利用一个哈希函数来确定Entry的插入位置(index):<br />`index = hash("apple")`<br />假定最后计算出的index是2,那么结果如下:<br /><br />但是,因为 HashMap 的长度是有限的,当插入的 Entry 越来越多时,再完美的 Hash 函数也难免会出现 index 冲突的情况。比如下面这样:<br />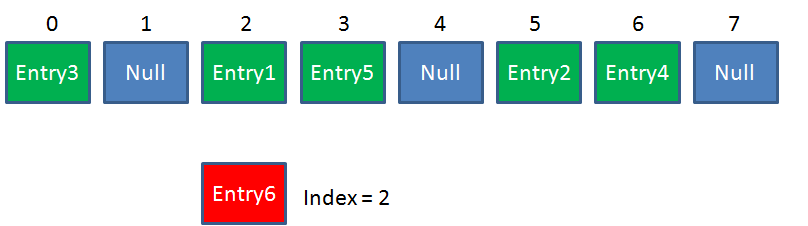<br />这时候该怎么办呢?<br />首先,判断Entry1的hashCode和Entry6是否相等,如果相等就不让插入。<br />其次,如果hashCode不相等,我们可以利用**链表**来解决。**新来的Entry节点插入链表时,使用的是“头插法”。**<br />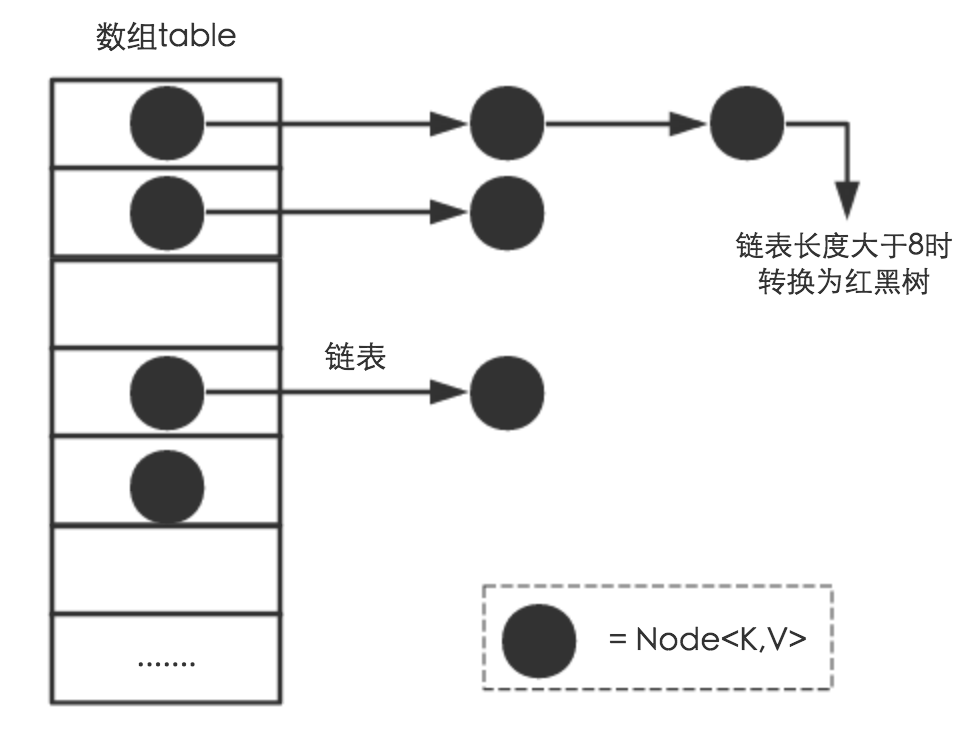<br />当 HashMap 中有大量的元素都存放到同一个桶中时,这个桶下有一条长长的链表,这个时候 HashMap 就相当于一个单链表,假如单链表有 n 个元素,遍历的时间复杂度就是 O(n),完全失去了它的优势。针对这种情况,JDK 1.8 中引入了 红黑树(查找时间复杂度为 O(logn))来优化这个问题。在Java 8 中,如果一个桶中的元素个数超过 TREEIFY_THRESHOLD(默认是 8 ),就使用红黑树来替换链表,从而提高速度。具体实现点[链接](https://blog.csdn.net/wushiwude/article/details/75331926)。```javastatic class Node<K,V> implements Map.Entry<K,V> {//哈希值,就是位置final int hash;//键final K key;//值V value;//指向下一个几点的指针Node<K,V> next;//...}static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // red-black tree linksTreeNode<K,V> left;TreeNode<K,V> right;TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red;}
b. Get 方法
首先会把输入的 Key 做一次 Hash 映射,得到对应的 index:index = Hash(“apple”)
由于刚才所说的 Hash 冲突,同一个位置有可能匹配到多个Entry,这时候就需要顺着对应链表的头节点,一个一个向下来查找。假设我们要查找的Key是 “apple”: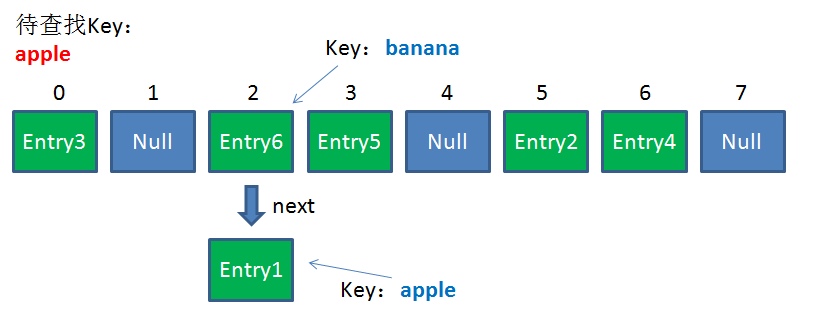
第一步,我们查看的是头节点 Entry6,Entry6 的 Key是banana,显然不是我们要找的结果。
第二步,我们查看的是 Next 节点 Entry1,Entry1 的 Key 是 apple,正是我们要找的结果。
之所以把 Entry6 放在头节点,是因为 HashMap 的发明者认为,后插入的 Entry 被查找的可能性更大。
C. Hash function 详解
HashMap对HashTable的hash算法进行了改进。
- 设计侧重点不同:
- Hashtable默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。
- HashMap默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。HashMap会将其扩充为2的幂次方大小。
- 之所以会有这样的不同,是因为Hashtable和HashMap设计时的侧重点不同。Hashtable的侧重点是哈希的结果更加均匀,使得哈希冲突减少。当哈希表的大小为素数时,简单的取模哈希的结果会更加均匀。而HashMap则更加关注hash的计算效率问题。在取模计算时,如果模数是2的幂,那么我们可以直接使用位运算来得到结果,效率要大大高于做除法。HashMap为了加快hash的速度,将哈希表的大小固定为了2的幂。当然这引入了哈希分布不均匀的问题,所以HashMap为解决这问题,又对hash算法做了一些改动。这从而导致了Hashtable和HashMap的计算hash值的方法不同。
Hash方法不同:
Hashtable直接使用对象的hashCode。hashCode是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值。然后再使用除留余数发来获得最终的位置。Hashtable在计算元素的位置时需要进行一次除法运算,而除法运算是比较耗时的。
int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % hashtable.length;HashMap为了提高计算效率,将哈希表的大小固定为了2的幂,这样在取模预算时,不需要做除法,只需要做位运算。位运算比除法的效率要高很多。HashMap的效率虽然提高了,但是hash冲突却也增加了。因为它得出的hash值的低位相同的概率比较高,而计算位运算为了解决这个问题,HashMap重新根据hashcode计算hash值后,又对hash值做了一些运算来打散数据。使得取得的位置更加分散,从而减少了hash冲突。当然了,为了高效,HashMap只做了一些简单的位处理。从而不至于把使用2 的幂次方带来的效率提升给抵消掉。
static final int hash(Object key){ int h; return (keey == null) ? 0 : (key.hashCode() & (Length - 1)); }长度16或者其他2的幂,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。
如何实现一个均匀分布的hashCode()呢?


若有收获,就点个赞吧
0 人点赞
