
多层神经网络
1. 神经网络的传播过程
神经网络的传播过程我们做一个简化, 先推导出简化情况, 然后再推广到多层多神经元的情况
我们从上面的图中可以看到神经网络的传播过程和一些参数, 我们把这些参数串联起来写成表达式:
上面式子中的 是个非线性函数, 如果不加这个函数, 运算过程就仍然是线性的, 整个神经网络将失去意义, 由上面的5个式子可以得出y值的表达式:

如果没有上面那个非线性函数 :

得到的上面的式子(1.6)在训练数据的过程中其实是等价于上面的式子 , 因为都是线性的, 都是更新同一个位置的参数
, 因为都是线性的, 都是更新同一个位置的参数
介绍一下最简单的非线性函数 ,这个函数也称为阶跃函数
,这个函数也称为阶跃函数
2. 三层神经网络
定理: 三层神经网络可以模拟所有的决策面
首先介绍决策面的概念: 在具有两个类的统计分类问题中,决策面是超曲面,其将基础向量空间划分为两个集合。
分类器将决策面一侧的所有点分类为属于一个类,而将另一侧的所有点分类为属于另一个类, 在二维空间内, 决策面是直线。
c1为第一类样本 c2为第二类样本
设三条直线的表达式为:


然后我们做一个规定: 规定三条直线都大于0时, 取到c1决策面, (可以让 的值为相反数嘛), 我们设计了下面的这个三层神经网络结构, 这个结构就可以完成决策面的构建以及对样本的分类

我们设a1, a2, a3都大于0, 此时要合理构造 , 使得当z1,z2,z3都为1时(因为经过了阶跃函数), y为1
, 使得当z1,z2,z3都为1时(因为经过了阶跃函数), y为1
所以,此时我们取值:  , 当我们取到这一组值的时候, 这个模型就具备了分类的能力, 可以将决策面分割开来, 所以我们这个定理是成立的, 然后我们稍微推广一下, 如果决策面不是三角形, 而是一个n边形, 那么神经元层中有n个神经元
, 当我们取到这一组值的时候, 这个模型就具备了分类的能力, 可以将决策面分割开来, 所以我们这个定理是成立的, 然后我们稍微推广一下, 如果决策面不是三角形, 而是一个n边形, 那么神经元层中有n个神经元
3. 梯度下降法(gradient descent method)
由于神经网络的理论仍然不完备, 仍然没有最优解, 只能通过经验, 所以创造出来的这个算法, 没有一个非常严谨的证明, 也没有SVM的证明那么漂亮, 所以我们只能用公式表达出BP算法的思想, 首先我们先介绍梯度下降法的思想
3.1 梯度下降求局部极值
主要思想: 使用梯度下降的方法, 求局部极值
根据上图, 我们沿着梯度下降的方向走一定的步长 ,此时我们走到了
#card=math&code=f%28%5Comega_1%29&id=K0QsI) ,然后我们再接着走, 直到到达最低点(局部极值)
即: 
但是在这个图中我们可以看到, 它其实并没有达到最小值, 可以说,整个过程是一个试探的过程, 这种方法的好坏与初始值有很大关系
就像下山, 在一个伸手不见五指的夜里站在山上的某一处(好像有点怪), 然后慢慢的试探着周围哪里可以下山, 每次走的步长是步 ,直到我们到了最低点
所以我们总结出求局部极值的步骤:
①找一个
②设k=0, 假设%7D%7B%5Cmathrm%7Bd%7D%20%5Comega%7D%5Cright%7C%7B%5Comega_k%7D%20%3D%200%7D#card=math&code=%7B%5Clarge%20%5Cleft.%20%5Cfrac%7B%5Cmathrm%7Bd%7D%20f%28%5Comega%29%7D%7B%5Cmathrm%7Bd%7D%20%5Comega%7D%5Cright%7C%7B%5Comegak%7D%20%3D%200%7D&id=Lmdji) (k为第k步),退出循环 , 否则 :

上面式子中的alpha可以理解为一个大于0的学习率
3.2梯度下降的证明
为什么我们可以通过梯度下降法来找到极值, 或者说, 我们可以逼近那个极值点, 此时使用泰勒展开来证明它
原始的泰勒公式如下:

然后我们做一个变形, 只展开到一阶:

然后把式子(3.1.1)带入到上面的式子(3.2.1)中得到:

式子3.2.2中第二项中alpha大于0, 因为它是学习率, 中括号里面的也大于0, 所以整个式子是小于 的, 所以可以证明梯度下降是可以取到极值的
的, 所以可以证明梯度下降是可以取到极值的
4. 后向传播算法(back propagation)
4.1简化的bp算法
bp(back propagation)算法是典型的梯度下降法, 我们主要推导的思路是, 先推导下面这个最简单的三层神经网络, 然后再推广到最普适的情况去
输入 , 然后开始调整所有的
, 然后开始调整所有的 ,使得Yi接近y
然后我们针对输入的 , 我们定义一个优化函数 (从最简单的开始, 这个函数也叫损失函数)
, 我们定义一个优化函数 (从最简单的开始, 这个函数也叫损失函数)
然后我们按照以下的步骤来计算:
①先随机取 9个值
9个值
②求上面那个优化函数的极值
对所有的 ,求
,求 的偏导
的偏导
对所有的 ,求
,求 的偏导
的偏导
③顺着极值方向更新参数
④更新之后, 当所有的 和
都为0时, 退出循环
当我们计算这个上面9个变量的偏导的时候, 是有一定顺序的, 是通过链式法则从后向前来计算的, 因为可以先算出来一些变量的偏导数, 然后用先算出来的这部分偏导数来计算出下一部分的偏导, 比如说,先算出来第5层神经元的偏导数了, 然后通过第5层神经元的偏导数可以算出第4层神经元的偏导数
把最开始的5个式子抄过来, (这五个式子至关重要), 推导也都是围绕着这5个式子进行:

我们现在开始从后往前求偏导:
由式子4.1.1可得:

按照链式法则以及神经元的结构从后向前的顺序计算偏导, 由上面那5个式子可以推出:


以上求偏导的参数y, a1, a2是核心参数, 因为这几个数相当于是关键的节点, 在图里也可以看出来, 有点类似于每个神经元的 “y” 值
下面我们来求一些中间参数的偏导数 , 比如 之类的, 此时我们可以利用上面的三个式子来求剩下的参数
第一步: 先求
按照同样的方法计算b的偏导, 由上面那5个式子已知y和b的关系, 所以

我们又又又根据那5个式子已知 y 和 的关系, 所以又又又根据链式法则, 所以可以求出
的偏导

同理可知
第二步: 再求 
又又又又根据那5个式子已知 与
的关系, 所以又又又又根据链式法则求偏导

然后同理我们可以求出

上面的推导是从最后一层的 y 开始后向计算梯度, 前向传播是随机取的值, 然后通过后向传播来纠正前向传播的错误, 最后取到目标函数的极值
但是, 又有了新的问题出现了, 我们在上面定义了#card=math&code=%7B%5Cvarphi%7D%28x%29&id=kQh6S) 是阶跃函数, 这样的话, 其实就没法算了, 因为
%3D0#card=math&code=%7B%5Cvarphi%7D%27%28x%29%3D0&id=mLLxL)

所以我们要把这个函数改成非线性的函数:
1.%3D%5Cfrac%7B1%7D%7B1%2Be%5E%7B-x%7D%7D#card=math&code=%5Clarge%20%5Cvarphi%28x%29%3D%5Cfrac%7B1%7D%7B1%2Be%5E%7B-x%7D%7D&id=RUrML) (sigmoid)

蓝色线为原函数图像, 红色线为导数图像
因为这个函数有性质:
就是说它的导数是可以用它自身来表示的, 这样在计算的时候就很简便, 为什么会简便, 这里讲的比较深, 所以可以去PRML这本书里找答案, 有严谨的证明
2.%3D%5Cfrac%7Be%5E%7Bx%7D-e%5E%7B-x%7D%7D%7Be%5E%7Bx%7D%2Be%5E%7B-x%7D%7D#card=math&code=%5Clarge%20%5Cvarphi%28x%29%3D%5Cfrac%7Be%5E%7Bx%7D-e%5E%7B-x%7D%7D%7Be%5E%7Bx%7D%2Be%5E%7B-x%7D%7D&id=lmexZ) (tanh)

这个函数也有同样的性质, 可以用原函数把导数表示出来,  这里大家可以自己求一下
这里大家可以自己求一下
3.ReLU函数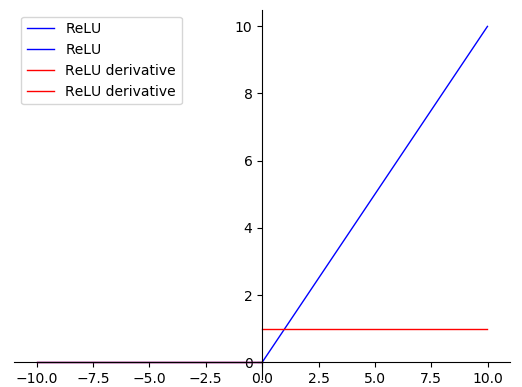


这个函数就更简便了, 就不用多说了
4.leakyReLU
这个函数是上面那个函数的改进, 因为如果x小于0, y全取0, 会损失很多的信息, 神经元中就会有很多的0, 所有我们把小于0的部分倾斜一个角度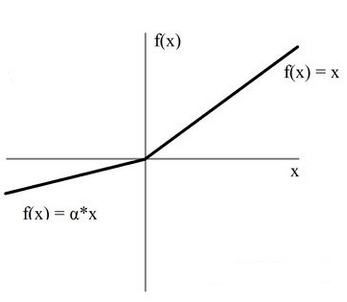
4.2推广的bp算法
我们开始将反向传播算法推广到多层神经网络中去
在广义上的定义与上面的定义有些不同了, 在这里z和a的位置调换了一下, 这里 , 和吴恩达的课程中的顺序相同了
, 和吴恩达的课程中的顺序相同了
首先开始前向传播计算, 然后对问题进行定义, 这一部分的公式很重要, 下面的求偏导都是基于一下的这些式子来求的

我们先说一下这里参数的维度,  其中
其中定义如下

这里可能有同学会问为啥每层的a的维度都是不同的?
我们这里需要说一下定义: 输入的是n个参数, a相当于是每层的输出值, 输出大小与该层的神经元个数有关, 所以每层的神经元个数不同, 每层a的维度就不同, 每层神经元个数是一样的, 那当然a的维度也就是相同的了
然后我们接式(4.2.1)继续计算下一层神经元:
%7D%3D%5Comega%5E%7B(2)%7Da%5E%7B(1)%7D%2Bb%5E%7B(2)%7D%20%5Coverset%7B%5Cvarphi%7D%7B%5Crightarrow%7D%20a%5E%7B(2)%7D%3D%5Cvarphi(z%5E%7B(2)%7D)#card=math&code=%5Clarge%20%5Crightarrow%20z%5E%7B%282%29%7D%3D%5Comega%5E%7B%282%29%7Da%5E%7B%281%29%7D%2Bb%5E%7B%282%29%7D%20%5Coverset%7B%5Cvarphi%7D%7B%5Crightarrow%7D%20a%5E%7B%282%29%7D%3D%5Cvarphi%28z%5E%7B%282%29%7D%29&id=x5DPL)
%7D%3D%5Comega%5E%7B(3)%7Da%5E%7B(2)%7D%2Bb%5E%7B(3)%7D%20%5Cquad%20%5Ccdots#card=math&code=%5Clarge%20%5Crightarrow%20z%5E%7B%283%29%7D%3D%5Comega%5E%7B%283%29%7Da%5E%7B%282%29%7D%2Bb%5E%7B%283%29%7D%20%5Cquad%20%5Ccdots&id=xuuMi)
%7D%3D%5Comega%5E%7B(m)%7Da%5E%7B(m-1)%7D%2Bb%5E%7B(m)%7D#card=math&code=%5Clarge%20%5Crightarrow%20z%5E%7B%28m%29%7D%3D%5Comega%5E%7B%28m%29%7Da%5E%7B%28m-1%29%7D%2Bb%5E%7B%28m%29%7D&id=RMO99)
%7D%3D%5Comega%5E%7B(m%2B1)%7Da%5E%7B(m)%7D%2Bb%5E%7B(m%2B1)%7D%20%5Cquad%20%5Ccdots#card=math&code=%5Clarge%20%5Crightarrow%20z%5E%7B%28m%2B1%29%7D%3D%5Comega%5E%7B%28m%2B1%29%7Da%5E%7B%28m%29%7D%2Bb%5E%7B%28m%2B1%29%7D%20%5Cquad%20%5Ccdots&id=kEqJN)
然后我们算到最后一层, 输出 y :
%7D%3D%5Comega%5E%7B(l)%7Da%5E%7B(l-1)%7D%2Bb%5E%7B(l)%7D#card=math&code=%5Clarge%20%5Crightarrow%20z%5E%7B%28l%29%7D%3D%5Comega%5E%7B%28l%29%7Da%5E%7B%28l-1%29%7D%2Bb%5E%7B%28l%29%7D&id=qlPeg)
%7D%3D%5Cvarphi(z%5E%7B(l)%7D)#card=math&code=%5Clarge%20%5CRightarrow%20y%3Da%5E%7B%28l%29%7D%3D%5Cvarphi%28z%5E%7B%28l%29%7D%29&id=Uxgo6)
根据上面的计算过程有如下定义:
1.网络一共 层
2. 是第k层的分量, 与第k层的神经元个数一致
是第k层的分量, 与第k层的神经元个数一致
3.用  表示
表示 %7D%2Ca%5E%7B(k)%7D%2Cb%5E%7B(k)%7D#card=math&code=z%5E%7B%28k%29%7D%2Ca%5E%7B%28k%29%7D%2Cb%5E%7B%28k%29%7D&id=EhVmU) 的第i个分量
4.输出的y可以是向量, 用 表示 y 的第i个分量
表示 y 的第i个分量
开始推导广义上的bp算法
算法流程:
①随机初始化 
②训练样本(X, Y), 带入网络可求出所有的 z, a, y, 此时Y也是矩阵了
③链式法则求偏导, 定义损失函数, 使损失函数最小化

然后求所有的 <br />④根据所求得偏导更新参数

推广到第m层后的结构图如下: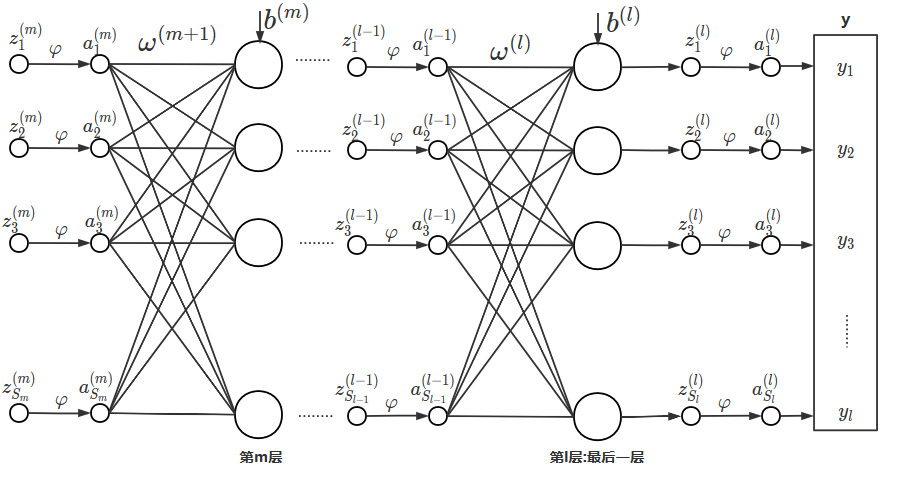
然后再抄一下上面的一些推导式, 方便阅读:
%7D%3D%5Cvarphi(z%5E%7B(1)%7D)%20%5Cquad%5Cquad%20(4.2.3)#card=math&code=%5Clarge%20%5Crightarrow%20a%5E%7B%281%29%7D%3D%5Cvarphi%28z%5E%7B%281%29%7D%29%20%5Cquad%5Cquad%20%284.2.3%29&id=daRVM)
%7D%3D%5Comega%5E%7B(m)%7Da%5E%7B(m-1)%7D%2Bb%5E%7B(m)%7D%20%5Coverset%7B%5Cvarphi%7D%7B%5Crightarrow%7D%20a%5E%7B(m)%7D%3D%5Cvarphi(z%5E%7B(m)%7D)%20%5Cquad%5Cquad%20(4.2.4)#card=math&code=%5Clarge%20%5Crightarrow%20z%5E%7B%28m%29%7D%3D%5Comega%5E%7B%28m%29%7Da%5E%7B%28m-1%29%7D%2Bb%5E%7B%28m%29%7D%20%5Coverset%7B%5Cvarphi%7D%7B%5Crightarrow%7D%20a%5E%7B%28m%29%7D%3D%5Cvarphi%28z%5E%7B%28m%29%7D%29%20%5Cquad%5Cquad%20%284.2.4%29&id=JuuLI)
%7D%3D%5Comega%5E%7B(m%2B1)%7Da%5E%7B(m)%7D%2Bb%5E%7B(m%2B1)%7D%20%5Cquad%20%5Ccdots%20%5Cquad%5Cquad%20(4.2.5)#card=math&code=%5Clarge%20%5Crightarrow%20z%5E%7B%28m%2B1%29%7D%3D%5Comega%5E%7B%28m%2B1%29%7Da%5E%7B%28m%29%7D%2Bb%5E%7B%28m%2B1%29%7D%20%5Cquad%20%5Ccdots%20%5Cquad%5Cquad%20%284.2.5%29&id=RwR3v)
%7D%3D%5Comega%5E%7B(l)%7Da%5E%7B(l-1)%7D%2Bb%5E%7B(l)%7D%20%5Cquad%5Cquad%20(4.2.6)#card=math&code=%5Clarge%20%5Crightarrow%20z%5E%7B%28l%29%7D%3D%5Comega%5E%7B%28l%29%7Da%5E%7B%28l-1%29%7D%2Bb%5E%7B%28l%29%7D%20%5Cquad%5Cquad%20%284.2.6%29&id=HPUro)
%7D%3D%5Cvarphi(z%5E%7B(l)%7D)%20%5Cquad%5Cquad%20(4.2.7)#card=math&code=%5Clarge%20%5CRightarrow%20y%3Da%5E%7B%28l%29%7D%3D%5Cvarphi%28z%5E%7B%28l%29%7D%29%20%5Cquad%5Cquad%20%284.2.7%29&id=M5SnJ)
然后立即推:
设 , 这个设的是中间某一层的, 这里是小m, 根据(式4.2.2, 式4.2.7), 我们先算最后一层的:
, 这个设的是中间某一层的, 这里是小m, 根据(式4.2.2, 式4.2.7), 我们先算最后一层的:

整个过程实际上是与两个神经元的计算方法是完全一样的, 唯一不一样的也就是z和a调换了顺序….
根据式4.2.4, 式4.2.5, 式4.2.7我们接着算中间某一层的:

可能有的同学又又又有了疑问, 就是为啥会有求和西格玛符号嘛, 这里求偏导的链式法则, 要求很多个神经元和一大堆的 , 这一层的每个偏导数都要加起来, 有点类似于求全导数
然后根据式4.2.4我们就可以求最终的 了:


整体的思路就是, 我们用了标有黑桃的这4个式子, 把所有的 求了出来
我们现在算出了所有需要的偏导数, 然后按照既定的步骤更新参数就可以了

若有收获,就点个赞吧
0 人点赞

{kind=link}