
特征选择与特征提取
1.概要
特征选择和特征提取都是降维的方法
特征提取: 特征提取后的新特征是原来特征的一个映射。经典方法有主成分分析(Principle Components Analysis ,PCA)和线性评判分析(Linear Discriminant Analysis,LDA)
特征选择:特征选择后的特征是原来特征的一个子集。这里的经典算法是adaboost
这两种方法看似都是降维的方法, 但是有很大的区别, 我们可以看一下它们的数学描述:
有一个样本集合 , 其中每个样本也都是向量,
, 其中每个样本也都是向量,  , 每个
, 每个 属于C1或者C2类
属于C1或者C2类
特征选择问题(Feature selection):
N个维度有冗余, 如何从 个样本维度中选出M个维度M,
个样本维度中选出M个维度M,  , 使识别率最高
, 使识别率最高
特征提取问题(Feature extraction):
N个维度 从每个样本的N个特征中选出M个特征构造:
从每个样本的N个特征中选出M个特征构造:
看似复杂实际上就是在做一个特征的降维, 由N维降到M维, 降维本身的目的也很明确, 是降低计算量, 减少不必要的计算开销, 举个简单的例子: 我们现在有1000个特征, 训练后预测准确率是95%, 我们用PCA降维到100个特征, 预测准确率有可能是94.99%或者是95.3%, 这样我们就会选择用这种方法
特征提取和选择的方法存在于上个世纪, 但是它是非常有用的传统方法, 现在应用范围也很广
我们要介绍的特征提取方法是主成分分析(PCA), 特征选择方法是Adaboost自适应提升算法, 这两个方法是非常典型的方法, 之后的一些集成学习的方法和一些特征降维的方法都大同小异
2.主成分分析PCA
2.1引言
我们在上个小节说了, PCA的目的就是为了降维, 也就是说要把每个样本N维特征降维到M维, 即
其中Y维度(M×1), A维度为(M×N), x维度为(N×1), b维度为(M×1)
主成分分析可以看成是一个一层的有M个神经元的神经网络, x是没有标签的, 后来hinton发明的自编码器也是受PCA的启发
2.2设计思路
PCA的思路是:寻找使方差最大的方向, 并在该方向上投影, 这里引用PRML中第十二章的一张图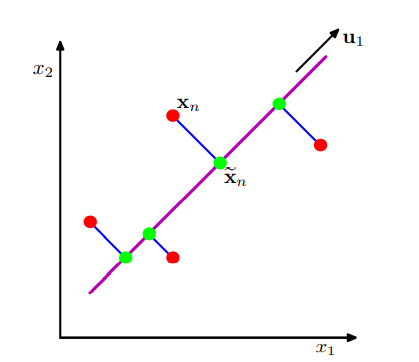
在图中,我们可以看到这是一个二维空间, 现在我们要把他降到一维空间, 在图中方向u1是方差最大的方向, 然后建立直角坐标系后投影, 此时我们就给他降到了u1方向上的以为空间中了, 降维本身这个动作它是会损失信息的, 但投影后最大限度地保存了信息
2.3数学推导
然后我们将上面的方法用数学公式表达出来, PCA给出的方法是将 改造一下, 假设有p个训练样本
改造一下, 假设有p个训练样本 :
:
A写成行向量的形式, 然后写出Y的表达式:
%5C%5C%20a2(x_i-%5Cbar%7Bx%7D)%5C%5C%20%5Cvdots%5C%5C%20a_M(x_i-%5Cbar%7Bx%7D)%20%5Cend%7Bbmatrix%7D%0A%3D%5Cbegin%7Bbmatrix%7Dy%7Bi1%7D%5C%5C%20y%7Bi2%7D%5C%5C%20%5Cvdots%5C%5C%20y%7BiM%7D%20%5Cend%7Bbmatrix%7D%20%5Cquad(i%3D1%5Csim%20p)%20%5Cquad%5Cquad(2.4)%0A#card=math&code=A%3D%20%5Cbegin%7Bbmatrix%7Da1%5C%5C%20a_2%5C%5C%20%5Cvdots%5C%5C%20a_M%20%5Cend%7Bbmatrix%7D%20%5Cquad%5Cquad%0AY_i%3D%20%5Cbegin%7Bbmatrix%7Da_1%28x_i-%5Cbar%7Bx%7D%29%5C%5C%20a_2%28x_i-%5Cbar%7Bx%7D%29%5C%5C%20%5Cvdots%5C%5C%20a_M%28x_i-%5Cbar%7Bx%7D%29%20%5Cend%7Bbmatrix%7D%0A%3D%5Cbegin%7Bbmatrix%7Dy%7Bi1%7D%5C%5C%20y%7Bi2%7D%5C%5C%20%5Cvdots%5C%5C%20y%7BiM%7D%20%5Cend%7Bbmatrix%7D%20%5Cquad%28i%3D1%5Csim%20p%29%20%5Cquad%5Cquad%282.4%29%0A&id=sZWde)
上面式子中每个a都是一个行向量, 这个是要注意的, 现在寻找一个,然后使
方差最大化:

解释一下, 此时 都是已知, 所以只需要找出使式(2.4)方差最大的a1即可, 现在推的是y1与其他值的方差, 所以选谁为基准求方差都是一样的, 其中
的均值如下:

又因为式(2.3)我们可以带入到式(2.6)中, 中括号里面的东西等于0, 故:

上面的运算过程没有什么好解释的, 基本的矩阵运算, 但是这个最后一步的式子(2.7)需要单独解释一下, 我们先看一下这个式子中每一项的维度:
整理一下我们可以得到这样的式子:
我们对式(2.9)有一个定义, 这个矩阵叫协方差矩阵(Covariance Matrix)
所以我们现在根据上面所推导的改写这个问题, 此时这个问题也可以被抽象成一个优化问题, 换一种说法就是, 它可以被抽象成一个使用拉格朗日乘子法求条件极值的问题:
最大化:
限制条件:
解释一下上面这个最优化问题中的限制条件, 我们是在做一个投影, 但是投影长度有很大的, 也有很小的, 所以我们要做一个归一化, 把所有的投影长度限制在0到1中间
然后我们使用拉格朗日乘子法解这个问题, 先构造拉格朗日函数, 然后对它求偏导:

在求偏导之前, 补充几个矩阵求偏导的公式:

上面几个公式需要说明一下, 我们在之前定义了a1是行向量, 求导之后要给它横过来, 所以式(2.13)那里加了一个转置

因此%0A#card=math&code=%5Csum%20a_1%5ET%20%3D%20%5Clambda%20a_1%5ET%20%5Cquad%5Cquad%282.17%29%0A&id=SYtCi)
这个式子我们可以看出来,  是
是 的特征向量,
的特征向量,  是
是 的特征值, 根据这个式子我们可以推出:

通过上面的推导我们发现,  的最大值为
的最大值为 ,最大的方差为
 ,
,  是最大特征值
是最大特征值所对应的特征向量. 且

如果是降到1维, 现在就已经做完了, 若M>1, 就还要找一个方向, 是投影的方差尽可能地大
现在开始找第二个方向
这个方向不能与相近, 否则无意义, 所以选定垂直方向
最大化:
限制条件:
拉格朗日乘子法
构造拉格朗日函数:

求偏导, 和第一个投影方向的计算方法相同:

此时, 我们可以证明 :

由之前的定义可知:

将上面的等式带入式(2.27)中,可得, 同理, 我们得到了下面这个式子:

 是
是 的特征向量,
 是
是第2大的特征值
然后我们开始找第三个方向, 需要与前两个方向垂直
最大化:
限制条件:
 是
是  的特征向量,
的特征向量,  是
是第3大的特征值, 依此类推, 求完所有的
 也就是求完了矩阵A
也就是求完了矩阵A
2.4PCA算法总结
第一步: 求下面的式子

第二步: 求 的特征值

然后求对应的特征向量

第三步: 归一化所有的 , 使
, 使
第四步:
这样我们的降维操作就完成, 其实还有很多降维的方法, 比如SVD奇异值分解, 实质上使将上面的步骤非常快速的求到特征值, 然后完成降维
3.自适应提升算法(adaboost)
3.1引言
adaboost已经属于集成学习的范畴, 之后的gbdt, xgboost等有关树模型的算法也都由adaboost的影子, 集成学习的思想简单来说, 就是用很多个弱分类器组合成一个更强更稳定的强分类器, 比如在adaboost算法中, 在N个样本中用采样的方法获得M个弱分类器, 每次采样的时候用不同的特征, 经过训练过后每个特征具备了不同的权重, 以此来进行特征选择, 当然这M个分类器之间是有权重关系的
adaboost的算法流程
有数据集 共N个样本
共N个样本
我们需要做一个二分类问题: 
输入: 
输出: 分类器
3.2设计思路
大致的思想就是通过采样的方法, 给每次的采样赋上不同的权重, 准确率高的权重就大些, 准确率低的权重就小点, 比较重要的是采样的含义, 这里的采样指的是采特征, 每次采N个样本的不同特征
步骤一
初始化采样权值(每个特征采样的权重):

在初始化时每个特征的权重是均匀的
步骤二
对于 , (M是弱分类器的个数), 用
, (M是弱分类器的个数), 用 采样N个训练样本,在训练样本上获得弱分类器
采样N个训练样本,在训练样本上获得弱分类器
这种采样是有放回的采样, 说明有的样本采的次数多, 有的样本采的次数少, 但是具体采多少, 怎么采由权重D决定, 一开始是均匀采样, 后来根据前面的先验概率不断调整下次被采到的概率
步骤三
计算加权错误率:
先解释一下上面的式子, 它其实等同于错误的个数除以样本数, 这里面的有一个示性函数I, 这个函数的意思是如果分类器错误分类了, 就为1, 若正确分类了, 就为0, 公式如下:

然后我们用错误率 来确定弱分类器
来确定弱分类器 的权重
的权重 :
:

如果该弱分类器的越小, 在后面融合时所占的权重就越大
步骤四
更新权值分布, 当通过一次训练计算出权重之后, 我们就要更新权重了

然后这一步很关键, 先把公式写出来再解释它:

解释一下上面两个式子,exp就是e的x次方这个函数, 我们可以知道 能取到的值只有正负1, 我们还可以知道
能取到的值只有正负1, 我们还可以知道 , 所以在识别正确时,
, 所以在识别正确时,  ,
,  exp小于1, 这样的结果会让
exp小于1, 这样的结果会让 比
比 更小
更小
在识别错误时,  ,
,  exp大于1, 这样的结果会让
exp大于1, 这样的结果会让 比
比 更大, 在下一次学习的时候, 让它多学一学错误的样本
更大, 在下一次学习的时候, 让它多学一学错误的样本
然后前面的的含义时把所有的权重加到一起, 让
 进行一个归一化, 让
进行一个归一化, 让 的取值在0到1之间
的取值在0到1之间
步骤五
回到步骤2, 循环m次
步骤六
最终的识别器

我们可以看到f(x)是把所有的分类器加权求和, 然后用sign(x)输出它的类别(正负样本)

3.3证明
随着M增加, adaboost最终分类器G(x)在训练样本上的错误将会越来越小, 很多弱分类器合在一起会变成一个强分类器
我们需要证明上面这句话
错误率的定义如下:

解释一下, 式(3.7)式一个定义没什么好说的, 式(3.8)是很关键的一步, 也是比较难理解的一步, 分为两种情况讨论:
- 若
 , 则
, 则 , 由式(3.6)可知,
, 由式(3.6)可知,  同号, 所以
同号, 所以 , 可推出 0<exp<1
, 可推出 0<exp<1 - 若
 , 则
, 则 , 所以
, 所以 , 可推出 exp>1
, 可推出 exp>1
实际上式(3.8)满足了两种情况
现在我们把式(3.6)带入到式子(3.8)中:

解释一下这两个公式, 可能有的同学看见了那个像门洞一样的连乘符号, 其实很简单, exp是e的x次方这个指数函数, 指数在上面累加, 放到外面自然就是累乘哩, 就像这个式子  , 可能还有同学要问, 为啥
, 可能还有同学要问, 为啥 变成了
变成了 嘞? 因为我们是从第一步开始推导的, 第一步的权重是均匀的, 然后下面我们接着上面的式子往下算第二步:
嘞? 因为我们是从第一步开始推导的, 第一步的权重是均匀的, 然后下面我们接着上面的式子往下算第二步:

我们来看一下这个推导过程, 式(3.11)是把第一项提出来, 然后把第二项到最后一项甩到后面去, 根据式(3.5)可以得到式(3.12), 然后依此类推, 我们得到了式(3.14)
然后我们开始第二个证明, 证明的核心是下面这个式子:

我们把之前的式(3.6)拿过来:

式(3.16)很容易从式(3.15)推出, 因为 只能取到正负1, 然后此时将式(3.3)带入式(3.17), 通过均值不等式易证:
只能取到正负1, 然后此时将式(3.3)带入式(3.17), 通过均值不等式易证:

在整个推导中 , 原因在于, 我们的弱分类器始终是基于这个数据原始的分布来预测的, 也就是说, 我们其实是有一个先验概率, 有了这个先验概率, 会让加权错误率始终小于二分之一, 最后我们得出
, 原因在于, 我们的弱分类器始终是基于这个数据原始的分布来预测的, 也就是说, 我们其实是有一个先验概率, 有了这个先验概率, 会让加权错误率始终小于二分之一, 最后我们得出 此时可以证明式(3.14)是不断地缩小的, 证明完毕
此时可以证明式(3.14)是不断地缩小的, 证明完毕

若有收获,就点个赞吧
0 人点赞
