一.mac下redis安装和启动:
1.如果homebrew需要更新,则
sudo chown -R $(whoami):admin /usr/localsudo brew cleanup && brew updatesudo chown root:wheel /usr/local
2.安装
brew install redis
这里加sudo会报错。
3.启动
//如果需要后端启动brew services start redis//如果需要前端启动redis-server /usr/local/etc/redis.conf
4.停止
brew services stop redis
二.CentOS7.3下安装和启动:
1.redis需要一些前置安装条件
yum install gcc-c++wget http://downloads.sourceforge.net/tcl/tcl8.6.1-src.tar.gztar -zxvf tcl8.6.1-src.tar.gzcd tcl8.6.1/cd unix./configuremakemake install
2.下载和编译安装redis,并修改配置文件
wget http://download.redis.io/releases/redis-4.0.6.tar.gztar -zxvf redis-4.0.6.tar.gzcd redis-4.0.6/makemake installvi ./tests/integration/replication-2.tcl//修改after为10000make testmv redis-cli redis-server redis-sentinel /usr/bin/cd ..vi redis.conf//修改 bind 127.0.0.1 为 0.0.0.0 可以开放远程访问//修改 daemonize no 为 yes 可以开启后台模式cp redis.conf /usr/bin/
3.启动和关闭redis
cd /usr/local/bin//启动./redis-server ./redis.conf//关闭redis-cli -p 6379 shutdown
4.使用
//-h可指定远程服务器地址 -a可指定密码redis-cli -p 6379 [-h host -a password]//基本操作127.0.0.1:6379> set [key] [value]127.0.0.1:6379> get [key]127.0.0.1:6379> DEL key [key ...]
三.Spring中使用
Spring中用Redis做缓存,一般集成Spring Cache组件。只需要几个注解和配置,就能轻松的应对大多数项目中的缓存的需求。
Spring Cache处理机制是利用aop,默认执行完代理方法后,最后把旧缓存删了。下次读的时候发现没有,正好加载新的值。它一般不出错,是基于操作Redis时间对于操作数据库的时间是几乎忽略不计的这个假设之上。
spring Cache源码比较简单,需要配置一个NamespaceHandlerSupport的实现类CacheNamespaceHandler,来走aop的逻辑。在这个类里边会注册bean定义解析器,最后产生InfrastructureAdvisorAutoProxyCreator。拦截扫描用的CacheInteceptor和BeanFactoryCacheOperationSourceAdvisor在这bean定义的时候被放进去。CacheInteceptor会读配置,让对应产生的CacheManager具体处理缓存逻辑。
四.高并发的情况应对
由于可能在分布式高并发情况下出现JVM的STW情况,这个情况如果出现在写入数据库和删redis之间,有别的线程读取redis,就会有数据不一致情况。这时的做法可以有:
1.延时双删:删了redis之后的一个时间间隔再删一次,保证一定删了。
2.定时任务补偿更新redis。
3.闪电缓存:缓存时间极短,只有几秒。(有缓存击穿风险,在读redis时加分布式锁,如果没有数据就更新redis,读到数释放锁,所有读操作都走redis)
4.基于canel消息队列的redis数据同步。
五.redis底层数据结构:
下图是主数据结构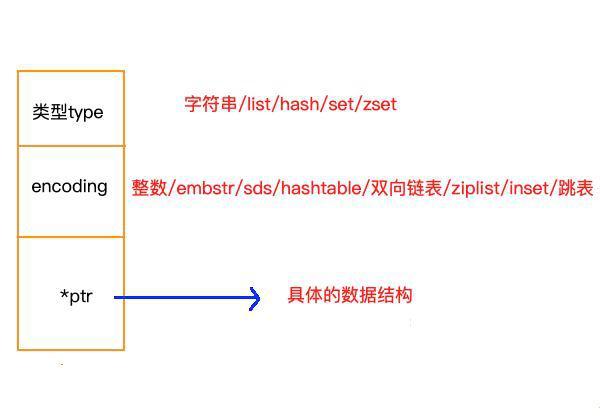
1.字符串:如果是数字,存为字符串需看长度是否39字节以内。如果小于39字节将SDS存到主数据结构中(embstr)。否则独立存储SDS(raw)。
2.list:如果每个元素小于64字节,且元素个数小于512,则分配为ziplist。否则分配为双向链表。
3.hash:条件同上,分配为ziplist。否分配为哈希表。
4.zset:条件同上,分配为ziplist。否则分配为跳表。
5.set:如果所有元素都是整数,且元素个数小于512,则分配为intset。否则分配为哈希表。
设计数据结构时注意:
1.各存储情况代表的存储数据有序性。
2.是否需要有过期时间,set、hash内部不能支持过期。
3.读写频率,是否造成过多次的扩容rehash,考虑其他数据结构?
详细说明:
1.ziplist:
主结构左至右分别是:总大小、尾部指针、元素个数、元素数据、结尾标识
单个数据左至右分别是:前一个数据长度、本数据长度、数据
图上以list的ziplist为例。如果是hash和zeset的ziplist,则一个元素是key,紧接着一个元素是value(zeset为score)。
2.双向链表:
其实就是ziplist的数据结构分段,一个分段能容纳多大可以基于redis配置。
3.intset
很简单,每个数据的位数是固定的,连续的数组存储,也不需要从尾部遍历。
4.跳表
跳表原理抽象的看很像B+Tree,上层是索引,最后一层全是叶子节点数据。但实际上逻辑不太一样。

最多有32个层,头结点含有所有的层。每次插入结点随机决定在哪一层,那一层的所有下层都要添加该结点的索引。同一层中的各结点还会排序后通过backword结点提供反向排序功能。

若有收获,就点个赞吧
0 人点赞
