一.一般的找可能原因的思路:
1.通过故障时间思考是否有定时任务执行,这个任务是不是涉及计算
2.思考最近是不是上线某个可能导致问题的c端功能,它是不是涉及计算,有没有日志可以参考
3.思考是不是接收下游系统调用,或者接收上游系统消息过多而没有限流
由于现在的应用往往布置在弹性容器上,所以很难直接连上去用指令查看情况。以上方法多是基于推测,不能100%保证问题解决。需要一个能实时动态展示CPU负载详细情况的组件帮助定位问题。
二.用async-profiler创建火焰图:
git clone git://github.com/jvm-profiling-tools/async-profilercd async-profiler/make./profiler.sh -d 60 -o collapsed -f /tmp/test_01.txt (java程序的进程编号)cd ..cd FlameGraph/#脚本文件去 https://github.com/brendangregg/FlameGraph 获取perl flamegraph.pl --colors=java /tmp/test_01.txt > test_01.svg#则该svg是所需火焰图文件
火焰图示例: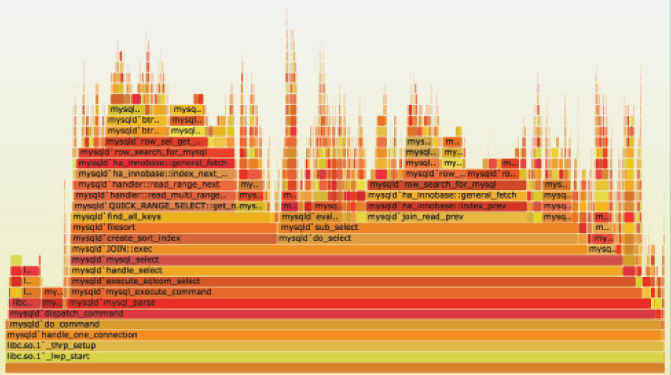
三.观察火焰图的方法:
下边的长方形依赖上边的长方形,所以应该找上层最宽的长方形。
如果生产环境拿不到当时的数据,通常可以对测试环境压测,得到图像并观察。

若有收获,就点个赞吧
0 人点赞
