简单表达式计算符号
> < = != <>(不等于) >= <=
DISTINCT查重
SELECTdistinct department_idFROMemployees;
concat
将所要显示连接列的字符串
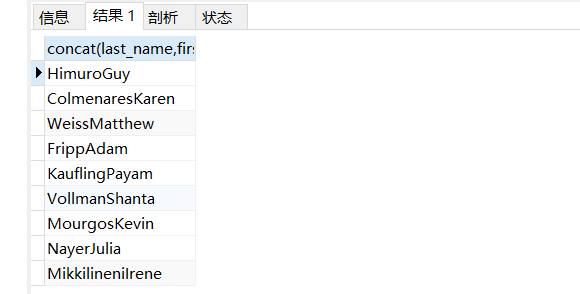
SELECTconcat(last_name,first_name)fromemployees
IFNULL(判断值,返回值)
如果为null,返回指定值
selectDISTINCT IFNULL(commission_pct,0),commission_pctfromemployees

between and
使用 BETWEEN 运算来显示在一个区间内的值
SELECT last_name, salaryFROM employeesWHERE salary BETWEEN 2500 AND 3500;
LIKE
• 使用 LIKE 运算选择类似的值
• 选择条件可以包含字符或数字:
– % 代表零个或多个字符(任意个字符)。
– _ 代表一个字符
SELECT last_nameFROM employeesWHERE last_name LIKE '_o%';
NULL
使用 IS (NOT) NULL 判断空值。
selectlast_name,manager_idfromemployeeswheremanager_id is null;
IN
使用 IN运算显示括号中有可能出现的值(类型要统一)。
SELECT employee_id, last_name, salary, manager_id
FROM employees
WHERE manager_id IN (100, 101, 201);
逻辑运算
AND
AND 要求并的关系为真。
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary >=10000
AND job_id LIKE
‘%MAN%’;
OR
OR 要求或关系为真。
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary >= 10000
OR job_id LIKE ‘%MAN%’;
NOT
指筛选掉指定的数据
SELECT last_name, job_id
FROM employees
WHERE job_id
NOT IN (‘IT_PROG’, ‘ST_CLERK’, ‘SA_REP’);
ORDER BY
order by
进行排序( desc降序,默认(不填或ASC)是升序)**
selectlast_name,job_id,department_id,hiredatefromemployeesorder byhiredate desc;
按别名排序
selectlast_name,job_id,department_id,hiredate datefromemployeesorder bydate ;
多个列排序
• 按照ORDER BY 列表的顺序排序。
SELECT last_name, department_id, salaryFROM employeesORDER BY department_id, salary DESC;
可以使用不在SELECT 列表中的列排序。
分组函数:
分组函数作用于一组数据,并对一组数据返回一个值。
• AVG()
• COUNT()
• MAX()
• MIN()
• SUM()
对数值型数据使用AVG和SUM函数**
selectjob_id,avg(salary),max(salary),min(salary),sum(salary)fromemployeeswherejob_id like '%REP%';

MIN(最小值)和 MAX(最大值)函数
可以对任意数据类型的数据使用MIN和MAX函数
selectmin(hiredate),max(hiredate)fromemployees;
COUNT(计数)函数
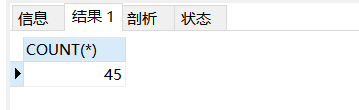
COUNT(*) 返回表中记录总数,适用任意数据类型。
SELECTCOUNT(*)FROMemployeesWHEREdepartment_id=50;
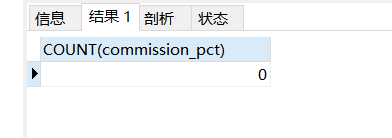
COUNT(expr)返回expr不为空的记录总数
SELECTCOUNT(commission_pct)FROMemployeesWHEREdepartment_id=50;
分组函数
GROUP BY
可以使用GROUP BY子语句将表中的数据分为若干组
WHRER 一定要放在FROM后面
在GROUP BY子句中包含多个列
SELECTdepartment_id dept_id,job_id,SUM(salary)FROMemployeesGROUP BYdepartment_id,job_id;
HAVING 子句
使用HAVING过滤分组:
1、行已经被分组。
2、使用了组函数
3、满足HAVING子句中条件的分组将被显示
多表查询
什么是笛卡尔集?
笛卡尔集的列数为每个表的列数之和,笛卡尔集的行数为每个表的行数相乘。我们经常做的多表查询就是在笛卡尔集中通过筛选条件得出的数据,所以笛卡尔集是多表查询的基础。
Mysql 连接
使用连接在多个表中查询数据。
• 在 WHERE 子句中写入连接条件。
• 在表中有相同列时,在列名之前加上表名前缀
等值连接
SELECTbeauty.id,name,boynamefrombeauty,boyswherebeauty.boyfriend_id=boys.id;
表的别名
• 使用别名可以简化查询。
• 使用表名前缀可以提高执行效率。
SELECTbt.id,name,boynamefrombeauty bt,boys bwherebt.boyfriend_id=b.id;
连接 n个表,至少需要 n-1个连接条件。
例如:连接三个表,至少需要两个连接条件。
练习:查询出公司员工的 last_name, department_name, city

若有收获,就点个赞吧
0 人点赞
