注意:
要将/etc/profile中的环境变量信息拷贝到当前用户家目录下的.bashrc 文件中
一、集群分发同步脚本
1. 在/bin目录下创建xsync文件
cd /binvim xsync
2. xsync集群分发同步Shell脚本
#!/bin/bash#1. 判断参数个数if [ $# -lt 1 ]thenecho Not Enough Arguement!exit;fi#2. 遍历集群所有机器for host in master slave1 slave2doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidonedone
3. 给予 xsync 文件可执行权限,并分发到其他节点上
chmod +x xsync
xsync xsync
二、查看集群所有进程脚本
1. 在/bin目录下创建xcall文件
cd /bin
vim xcall
2. 集群进程查看Shell脚本
#! /bin/bash
for i in master slave1 slave2
do
echo --------- $i ----------
ssh $i "$*"
done
3. 给予 xcall 文件可执行权限,并分发到其他节点上
chmod 777 xcall
xsync xcall
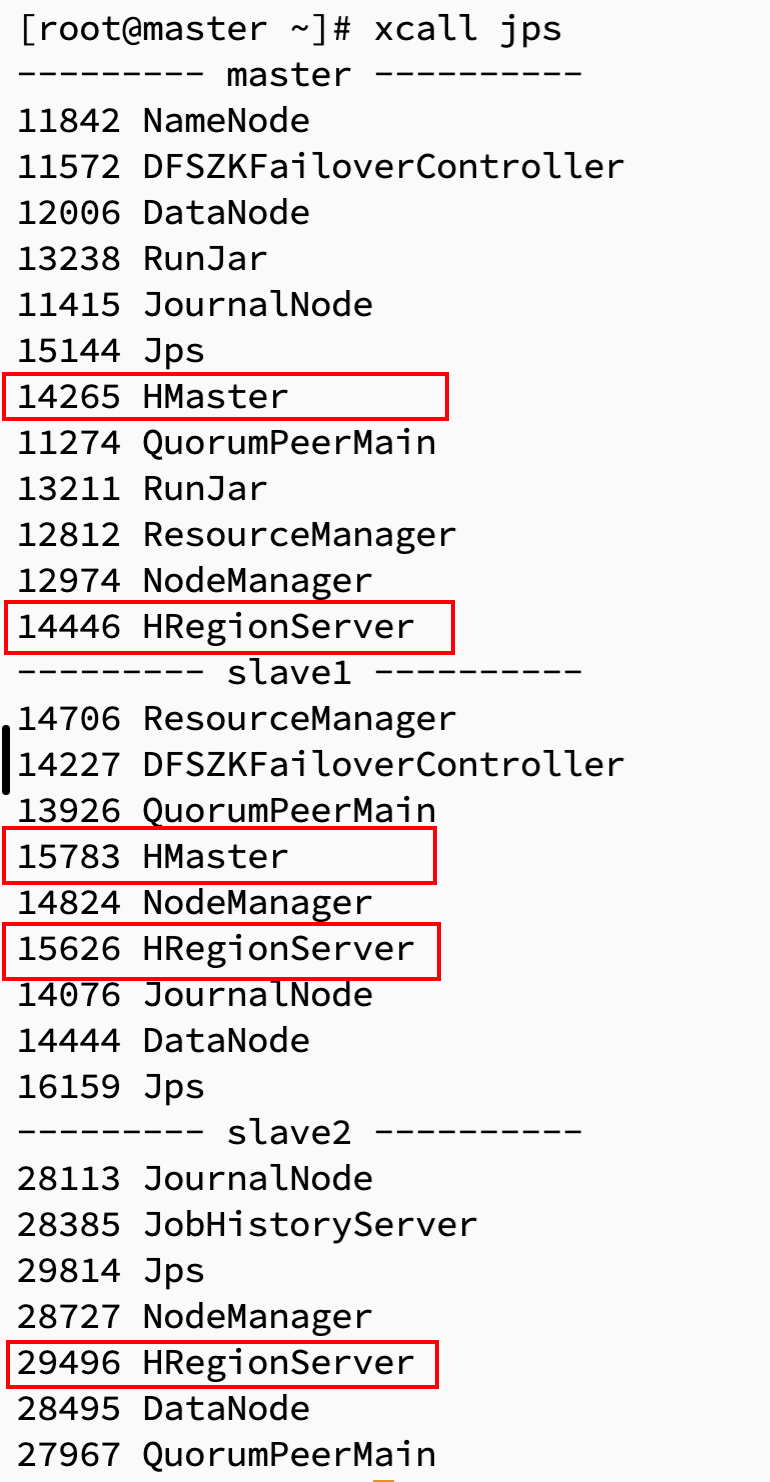
4. 测试 xcall 脚本
xcall jps

三、ZooKeeper 集群管理脚本
1. 在/bin目录下创建 zk 文件
cd /bin
vim zk
2. ZooKeeper 集群管理Shell脚本
#!/bin/bash
case $1 in
"start"){
for i in master slave1 slave2
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "zkServer.sh start"
done
};;
"stop"){
for i in master slave1 slave2
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "zkServer.sh stop"
done
};;
"status"){
for i in master slave1 slave2
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "zkServer.sh status"
done
};;
esac
3. 给予 zk 文件可执行权限,并分发到其他节点上
chmod 777 zk
xsync zk
4. 测试 zk 脚本
zk start
zk status
zk stop



四、 Hadoop HA 高可用集群管理脚本
1. 在/bin目录下创建 hd 文件
cd /bin
vim hd
2. Hadoop HA 高可用集群管理Shell脚本
#判断用户是否传参
if [ $# -ne 1 ];then
echo "无效参数,用法为: $0 {start|stop}"
exit
fi
#获取用户输入的命令
cmd=$1
#定义函数功能
function hadoopManger(){
case $cmd in
start)
echo "启动服务"
remoteExecutionstart
;;
stop)
echo "停止服务"
remoteExecutionstop
;;
*)
echo "无效参数,用法为: $0 {start|stop}"
;;
esac
}
#启动Hadoop
function remoteExecutionstart(){
#zookeeper
echo ========== ZooKeeper ================
for i in master slave1 slave2
do
tput setaf 2
echo ========== 启动 ${i} zookeeper $1 ================
tput setaf 9
ssh ${i} "source /etc/profile ; zkServer.sh start"
done
#journalnode
echo ========== Journalnode ================
for i in master slave1 slave2
do
tput setaf 2
echo ==========启动 ${i} journalnode $1 ================
tput setaf 9
ssh ${i} "source /etc/profile ; hadoop-daemon.sh start journalnode"
done
#zkfc
echo ========== zkfc ================
for i in master slave1 slave2
do
tput setaf 2
echo ==========启动 ${i} zkfc $1 ================
tput setaf 9
ssh ${i} "source /etc/profile ; hadoop-daemon.sh start zkfc "
done
echo "启动historyserver"
ssh slave2 "mr-jobhistory-daemon.sh start historyserver"
echo "启动HDFS"
ssh master "source /etc/profile ; start-dfs.sh"
echo "启动YARM"
ssh master "source /etc/profile ; start-yarn.sh"
}
#关闭HADOOP
function remoteExecutionstop(){
echo "关闭YARM"
ssh master "source /etc/profile ; stop-yarn.sh"
echo "关闭HDFS"
ssh master "source /etc/profile ; stop-dfs.sh"
echo "关闭historyserver"
ssh slave2 "mr-jobhistory-daemon.sh stop historyserver"
#zkfc
echo ========== zkfc ================
for i in master slave1 slave2
do
tput setaf 2
echo ==========启动 ${i} zkfc $1 ================
tput setaf 9
ssh ${i} "source /etc/profile ; hadoop-daemon.sh stop zkfc "
done
#journalnode
echo ========== Journalnode ================
for i in master slave1 slave2
do
tput setaf 2
echo ==========关闭 ${i} journalnode $1 ================
tput setaf 9
ssh ${i} "source /etc/profile ; stop journalnode"
done
#zookeeper
echo ========== ZooKeeper ================
for i in master slave1 slave2
do
tput setaf 2
echo ========== 关闭 ${i} zookeeper $1 ================
tput setaf 9
ssh ${i} "source /etc/profile ;hadoop-daemon.sh zkServer.sh stop"
done
}
#调用函数
hadoopManger
3. 给予 hd 文件可执行权限,并分发到其他节点上
chmod 777 hd
xsync hd
4. 测试 hd 脚本
hd start
hd stop



五、Kafka 集群管理脚本
1. 在/bin目录下创建 kf 文件
cd /bin
vim kf
2. Kafka 集群管理Shell脚本
#! /bin/bash
case $1 in
"start"){
for i in master slave1 slave2
do
echo " --------启动 $i Kafka-------"
ssh $i "kafka-server-start.sh -daemon /usr/local/src/kafka/config/server.properties"
done
};;
"stop"){
for i in master slave1 slave2
do
echo " --------停止 $i Kafka-------"
ssh $i "kafka-server-stop.sh stop"
done
};;
esac
3. 给予 kf 文件可执行权限,并分发到其他节点上
chmod 777 kf
xsync kf
4. 测试 kf 脚本
kf start
kf stop

六、Hive 集群管理脚本
1. 在/bin目录下创建 hv 文件
cd /bin
vim hv
2. Hive 集群管理Shell脚本
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
# 创建日志目录
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
# 检查进程是否运行正常,参数 1 为进程名,参数 2 为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
# 启动服务
function hive_start()
{
# 启动Metastore
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
[ -z "$metapid" ] && eval $cmd || echo -e "\033[47;36m Metastroe 服务已启动\033[0m"
# 启动HiveServer2
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo -e "\033[47;36m HiveServer2 服务已启动\033[0m"
}
# 停止服务
function hive_stop()
{
# 停止Metastore
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo -e "\033[47;33m Metastore 服务未启动\033[0m"
# 停止HiveServer2
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo -e "\033[47;33m HiveServer2 服务未启动\033[0m"
}
# 脚本参数菜单
case $1 in
"start")
echo -e "\033[47;32m 服务启动中,HiveServer2启动时间较长,请等待!\033[0m"
hive_start
;;
"stop")
echo -e "\033[47;32m 服务停止中,请等待!\033[0m"
hive_stop
;;
"restart")
echo -e "\033[47;32m 服务重启中,HiveServer2启动时间较长,请等待!\033[0m"
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo -e "\033[47;36m Metastore 服务运行正常\033[0m" || echo -e "\033[47;31m Metastore 服务运行异常\033[0m"
check_process HiveServer2 10000 >/dev/null && echo -e "\033[47;36m HiveServer2 服务运行正常\033[0m" || echo -e "\033[47;31m HiveServer2 服务运行异常\033[0m"
;;
*)
echo -e "\033[47;31m Invalid Args!\033[0m"
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
3. 给予 hv 文件可执行权限,并分发到其他节点上
chmod 777 hv
xsync hv
4. 测试 hv 脚本
hv start
hv stop

七、HBase 集群管理脚本
1. 在/bin目录下创建 hb 文件
cd /bin
vim hb
2. HBase 集群管理Shell脚本
#! /bin/bash
case $1 in
"start"){
echo " --------启动HBase-------"
ssh master "/usr/local/src/hbase/bin/start-hbase.sh"
};;
"stop"){
echo " --------停止HBase-------"
ssh master "/usr/local/src/hbase/bin/stop-hbase.sh"
};;
esac
3. 给予 hb 文件可执行权限,并分发到其他节点上
chmod 777 hb
xsync hb
4. 测试 hb 脚本
hb start
hb stop

八、Spark 集群管理脚本
1. 在/bin目录下创建 sp 文件
cd /bin
vim sp
2. Spark 集群管理Shell脚本
#! /bin/bash
case $1 in
"start"){
echo " --------启动Spark-------"
ssh master "/usr/local/src/spark/sbin//start-all.sh"
};;
"stop"){
echo " --------停止Spark-------"
ssh master "/usr/local/src/spark/sbin/stop-all.sh"
};;
esac
3. 给予 sp 文件可执行权限,并分发到其他节点上
chmod 777 sp
xsync sp
4. 测试 sp 脚本
sp start
sp stop
八、Zeppline 脚本
1. 在/bin目录下创建 sp 文件
cd /bin
vim zp
2. Zeppline 管理Shell脚本
#! /bin/bash
case $1 in
"start"){
echo " --------启动Zeppline-------"
ssh master "/usr/local/src/zeppelin/bin/zeppelin-daemon.sh start"
};;
"stop"){
echo " --------停止Zeppline-------"
ssh master "/usr/local/src/zeppelin/bin/zeppelin-daemon.sh stop"
};;
esac
3. 给予 zp 文件可执行权限,并分发到其他节点上
chmod 777 zp
xsync zp
4. 测试 zp 脚本
zp start
zp stop

若有收获,就点个赞吧
0 人点赞
