在工作过程中,我们总有倒霉的时候,比如用rm强制误删了一些非常重要的文件,于是这时候赶紧百度一波关于误删怎么恢复的主题,试了n种方式最终可能恢复了,但怎么恢复的,为什么能恢复我们都不知道。所以如果我们知道linux怎么去存文件的话,那在进行删除的时候,应该就知道它干了什么,知道了行为自然就有补救的方案。
磁盘(硬盘)分区
首先得知道所有的数据都是存在磁盘的,所以如果在磁盘里把数据清除了那肯定是还原不了了。那什么是磁盘呢?
磁盘是计算机主要的存储介质,可以存储大量的二进制数据,并且断电后也能保持数据不丢失。早期计算机使用的磁盘是软磁盘(Floppy Disk,简称软盘),如今常用的磁盘是硬磁盘(Hard disk,简称硬盘),所以我们主要关注硬盘即可。
磁盘分区是把物理的磁盘空间按照自己的要求分成N个不同大小的区域,以便OS更好更高效的进行文件存储管理。像我们经常使用的Windows系统中的C、D、E、F盘…等盘符实际就是一个个的磁盘分区。分区与操作系统没有任何关系,因为我们对磁盘分区可以在安装操作系统之前进行。现在磁盘分区也相当于了硬盘分区。
硬盘分区一共有三种:主分区,扩展分区和逻辑分区。
硬盘的分区主要分为主分区(Primary Partion)和扩展分区(Extension Partion)两种,一个硬盘主分区至少有1个,最多4个,扩展分区可以没有,最多1个,且主分区+扩展分区总共不能超过4个,逻辑分区可以有若干个。
- 主分区(Primary Partion):主要是用来启动操作系统的,它主要放的是操作系统的启动或引导程序。
- 扩展分区(Extension Partion):扩展分区是不能使用的,它只是做为逻辑分区的容器存在的,必须再进行分区后才能使用,也就是说它必须还要进行二次分区。
- 逻辑分区(Logical Partion):由扩展分区建立起来的分区,逻辑分区没有数量上限制。扩展分区只不过是逻辑分区的“容器”,实际上只有主分区和逻辑分区进行数据存储。
一个硬盘分区首先要确认在哪个硬盘,然后再确认它所在硬盘内的哪个分区。
操作系统必须安装在主分区上,因为MBR中记录着主分区信息,系统启动的时候会到主分区来查找操作系统引导文件,否则系统将无法启动。又因为磁盘分区表一共64个字节,并且每个主分区的分区信息占16个字节,所以一个磁盘最多能有4个主分区。那么问题来了,我们想要更多的分区怎么办呢?这个时候扩展分区的作用就来了,把最后一个主分区作为扩展分区,再在这个分区下分割出多个逻辑分区,扩展分区实际上是一个类似容器的东西。扩展分区并不是一个真实存在的分区,它只是内存管理链表中的一个指针,指示出哪一块区域是扩展分区。又因为这些扩展分区内的分区实际上都是在一个分区内,只是逻辑上分开,所以叫做逻辑分区。但这对于用户来说看起来系统中有很多分区。
电脑开机时,操作系统通过BIOS(BIOS实际是一个基础输入输出系统,主要用于和计算机硬件打交道)程序把Boot Sector读入内存,然后执行其中的MBR,这个时候BIOS是把启动交给MBR控制, MBR在4个分区表中搜索标致为活动的分区,找到以后把活动分区的第一扇区读入内存,然后开始执行它,以此来运行特定系统的启动程序(LILO、GRUB、NT Loader),此时是操作系统的引导程序来控制系统的启动。接着操作系统进行一系列的初始化工作,最后把系统交给系统内核进行管理,就完成了开机启动的过程。
分区命名
Linux下的硬盘分区的标识一般使用/dev/hd[a-z]X【IDE硬盘】或者/dev/sd[a-z]X【SATA硬盘】来标识,其中[a-z]代表硬盘号,X代表硬盘内的分区号。例如,用hda1、hda2、 hda5、hda6 来标识不同的分区。其中,字母a代表第一块硬盘,b代表第二块硬盘,依次类推。而数字1 代表一块硬盘的第一个分区、2 代表第二个分区,依次类推。1 到4 对应的是主分区(Primary Partition)或扩展分区(Extension Partition)。从5开始,对应的都是硬盘的逻辑分区(Logical Partition)。一块硬盘即使只有一个主分区,逻辑分区也是从5开始编号的,这点应特别注意。
文件系统
磁盘分区完毕后还要进行格式化,之后操作系统才能使用这个文件系统,格式化的理由是因为每种操作系统所设置的文件属性/权限并不相同,所以为了存放这些文件所需的数据,就需要将分区进行格式化,以成为操作系统能够利用的文件系统格式,举个例子 “mkfs.ext3 /dev/sdb1 ”是格式化成 ext3。
下面列举一些文件系统类型:
- ext2 : Linux内核所用的文件系统。它开始由Rémy Card设计,用以代替ext,于1993年1月加入linux核心支持之中。ext2 的经典实现为LINUX内核中的ext2fs文件系统驱动,最大可支持2TB的文件系统,至linux核心2.6版时,扩展到可支持32TB。
- ext3 : ext2的升级版,带日志功能
- ext4:ext3的改进版,修改了ext3中部分重要的数据结构,而不仅仅像ext3对ext2那样,只是增加了一个日志功能而已。ext4可以提供更佳的性能和可靠性,还有更为丰富的功能。
- RAMFS : 内存文件系统,速度很快
- NFS : 网络文件系统,由SUN发明,主要用于远程文件共享
- MS-DOS : MS-DOS文件系统
- VFAT : Windows 95/98 操作系统采用的文件系统
- FAT : Windows XP 操作系统采用的文件系统
- NTFS: Windows NT/XP 操作系统采用的文件系统
- HPFS : OS/2 操作系统采用的文件系统
- PROC : 虚拟的进程文件系统
- ISO9660 : 大部分光盘所采用的文件系统
- ufsSun : OS 所采用的文件系统
- NCPFS : Novell 服务器所采用的文件系统
- SMBFS : Samba 的共享文件系统
- XFS : 由SGI开发的先进的日志文件系统,支持超大容量文件
- JFS :IBM的AIX使用的日志文件系统
- ReiserFS : 基于平衡树结构的文件系统
- udf: 可擦写的数据光盘文件系统
每种操作系统能够使用的文件系统并不相同, 如windows 98 以前的微软操作系统主要利用的文件系统是 FAT (或 FAT16),windows 2000 以后的版本有所谓的 NTFS 文件系统,至于 Linux 的正统文件系统则为 Ext2 (Linux second extended file system, ext2fs)这一个。此外,在默认的情况下,windows 操作系统是不会认识 Linux 的 ext2 的。
传统的磁盘与文件系统之应用中,一个分区就是只能够被格式化成为一个文件系统,所以我们可以说一个 filesystem 就是一个 partition。但是由于新技术的利用,例如我们常听到的LVM与软件磁盘阵列(software raid), 这些技术可以将一个分区格式化为多个文件系统(例如LVM),也能够将多个分区合成一个文件系统(LVM, RAID)! 所以说,目前我们在格式化时已经不再说成针对 partition 来格式化了, 通常我们可以称呼一个可被挂载的数据为一个文件系统而不是一个分区喔!
对于一个磁盘分区来说,在被格式化为相应的文件系统后,整个分区被分为 1024,2048 和 4096 字节大小的块。每个区块都会有自己的编号,便于在inode中进行查找,一个区块只能放一个文件的数据,哪怕是文件小于该区块大小,那么剩下的区块空间也不再使用;一个大于区块大小的文件可以放置于多个区块。
根据块使用的不同,可分为:
- 超级块(Superblock): 这是整个文件系统的第一块空间。包括整个文件系统的基本信息,如块大小,inode/block的总量、使用量、剩余量,指向空间 inode 和数据块的指针等相关信息。
- inode块(文件索引节点) : 文件系统索引,记录文件的属性。它是文件系统的最基本单元,是文件系统连接任何子目录、任何文件的桥梁。每个子目录和文件只有唯一的一个 inode 块。它包含了文件系统中文件的基本属性(文件的长度、创建及修改时间、权限、所属关系)、存放数据的位置等相关信息。每个inode块的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定(现代OS可以动态变化),一般每2KB就设置一个inode。在 Linux 下可以通过 “ls -li” 命令查看文件的 inode 信息。硬连接和源文件具有相同的 inode 。
- 数据块(Block) :实际记录文件的内容,若文件太大时,会占用多个block。
就像一本书有封面、目录和正文一样。在文件系统中,超级块就相当于封面,从封面可以得知这本书的基本信息; inode 块相当于目录,从目录可以得知各章节内容的位置,而数据块则相当于书的正文,记录着具体内容。
为了提高目录访问效率,Linux还提供了表达路径与inode对应关系的目录项(dentry)。它描述了路径信息并连接到节点inode,它包括各种目录信息,还指向了inode和超级块。硬连接时,就是增加一个一个的目录项(dentry),其中他们的inode指向同一个。目录块是描述文件的逻辑属性,只存在于内存中,并没有实际对应的磁盘上的描述,更确切的说是存在于内存的目录项缓存,为了提高查找性能而设计。
挂载
从上文我们可以知道Linux系统中每个分区都是一个文件系统,都有自己的目录层次结构。linux会将这些分属不同分区的、单独的文件系统按一定的方式形成一个系统的总的目录层次结构。这里所说的“按一定方式”就是指的挂载。
将一个文件系统的顶层目录挂到另一个文件系统的子目录上,使它们成为一个整体,称为挂载。把该子目录称为挂载点。
例如要读取硬盘中的一个格式化好的分区、光盘或软件等设备时,必须先把这些设备对应到某个目录上,而这个目录就称为“挂载点(mount point)”,这样才可以读取这些设备。 挂载后将物理分区细节屏蔽掉,用户只有统一的逻辑概念。所有的东西都是文件。
不过在挂载之前,你要首先确定几件事:
- 单一的文件系统不应被重复挂载到某一目录
- 单一目录不能重复挂载多个文件系统
- 要作为挂载点的目录,理论上来说应该是空目录才行
下面给个图体会下(partition 1挂载到 / 下,partition 2 挂载到 /home 下):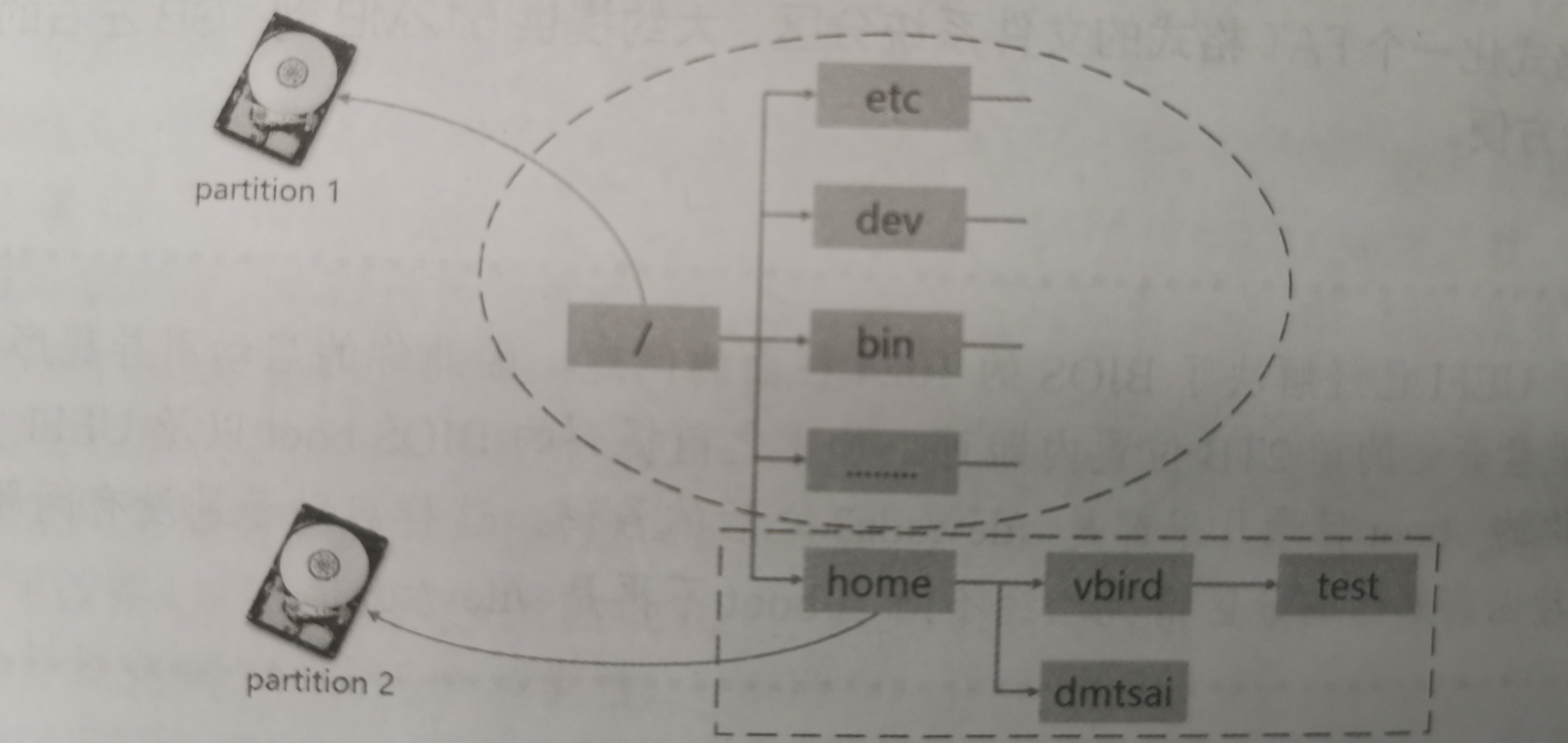
linux使用标准的目录结构,在安装的时候,安装程序就已经为用户创建了文件系统和完整而固定的目录组成形式,并指定了每个目录的作用和其中的文件类型。linux的主要目录结构:
- /bin 二进制可执行命令
- /dev 设备特殊文件
- /etc 系统管理和配置文件
- /etc/rc.d 启动的配置文件和脚本
- /home 用户主目录的基点,比如用户user的主目录就是/home/user,可以用~user表示
- /lib 标准程序设计库,又叫动态链接共享库,作用类似windows里的.dll文件
- /sbin 系统管理命令,这里存放的是系统管理员使用的管理程序
- /tmp 公用的临时文件存储点
- /root 系统管理员的主目录
- /mnt 系统提供这个目录是让用户临时挂载其他的文件系统。
- /lost+found 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什么.chk)就在这里
- /proc 虚拟的目录,是系统内存的映射。可直接访问这个目录来获取系统信息。
- /var 某些大文件的溢出区,比方说各种服务的日志文件
- /usr 最庞大的目录,要用到的应用程序和文件几乎都在这个目录。其中包含:
- /usr/X11R6 存放X window的目录
- /usr/bin 众多的应用程序
- /usr/sbin 超级用户的一些管理程序
- /usr/doc linux文档
- /usr/include linux下开发和编译应用程序所需要的头文件
- /usr/lib 常用的动态链接库和软件包的配置文件
- /usr/man 帮助文档
- /usr/src 源代码,linux内核的源代码就放在/usr/src/linux里
- /usr/local/bin 本地增加的命令
- /usr/local/lib 本地增加的库
文件的管理
linux下面的文件类型主要有:
- 普通文件:C语言元代码、SHELL脚本、二进制的可执行文件等。分为纯文本和二进制。
- 目录文件:目录,存储文件的唯一地方。
- 链接文件:指向同一个文件或目录的的文件。
- 设备文件:与系统外设相关的,通常在/dev下面。分为块设备和字符设备。
- 管道(FIFO)文件: 提供进程之间通信的一种方式
- 套接字(socket) 文件: 该文件类型与网络通信有关
- 字符设备文件:即串行端口的接口设备,例如键盘、鼠标等等。第一个属性为 [c]
创建文件
创建文件,linux先找到一个空的inode节点,把文件的信息记录在这个inode节点中,根据文件内容的大小,申请能够存储这个文件的数据块(Block),从空闲数据块列表中找出相应数量的自由块,将文件内容存放在这些自由块中。最后再将文件inode节点和文件名添加到该文件所属的目录文件下,文件名和inode节点之间的对应关系,将文件名和文件的内容及属性连接了起来。
rm命令干了什么
从上文我们可以知道,所有文件的数据最终都是存储在数据块(block)中的,也就是如果把数据块的数据删除了,那铁定是怎么找都找不回来了,所以rm命令应该不是直接删数据块的操作,那它是干啥的呢?
rm命令仅仅是对文件的inode块动了手脚,也就是清空了关联的inode信息,让它变成自由块重新能够被新文件关联,当然也会把关联的数据块也标识成自由块。这样的话,没了inode,我们自然无法通过正常的操作访问到文件的数据了。
如何还原被删的数据
很明显,在误删了数据后,我们不能再往这个分区写数据了,防止数据块的数据被覆盖,那时候真的覆水难收了。
针对不同的文件系统,就有已有的工具(extundelete、ext3grep)来进行还原,我们关注它们的恢复原理即可:
以ext3grep为例,他首先通过文件系统的root inode(一般为2)来获得所有当前文件系统下文件的信息,包括存在的和已经删除的,这些信息当然也包括文件名和其inode。然后利用inode到日志来去查询该inode所在的block位置,包括直接块,间接块等信息。最后利用dd来将这些信息dump出来,而形成一个文件。
所以如果有操作日志的文件系统,就可通过操作日志来恢复。当你没了这些现在工具的帮助下,自然也可以通过这种方式去写程序来恢复了。

若有收获,就点个赞吧
0 人点赞
