重点:二分查找,归并排序,快速排序
https://blog.csdn.net/weixin_41190227/article/details/86600821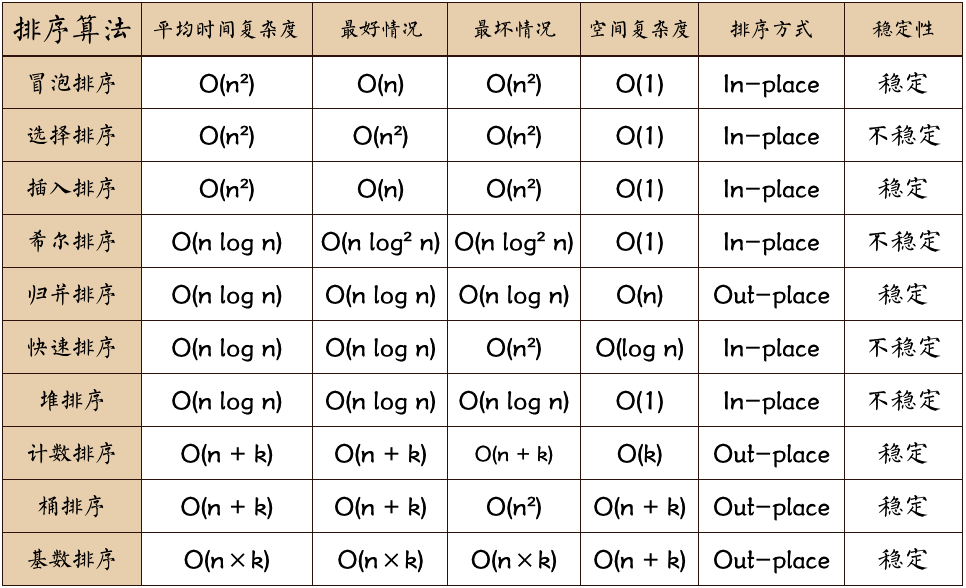

计数排序、基数排序、桶排序属于非比较排序,其他为比较排序
直接插入排序
- 步骤1: 从第一个元素开始,该元素可以认为已经被排序;
- 步骤2: 取出下一个元素,在已经排序的元素序列中从后向前扫描;
- 步骤3: 如果该元素(已排序)大于新元素,将该元素移到下一位置;
- 步骤4: 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
- 步骤5: 将新元素插入到该位置后;
- 步骤6: 重复步骤2~5。

//直接插入排序//size_t大小是由系统的位数决定的,在32位系统中size_t是4字节的,而在64位系统中,size_t是8字节的void InsertSort(vector<int> &input){if (input.empty())return;int cur;for (size_t i = 0; i < input.size() - 1; i++){cur = input[i + 1];//因为i+1所以input.size()-1int pre = i;while (pre >= 0 && input[pre] > cur){input[pre + 1] = input[pre];pre--;}input[pre + 1] = cur;}}
- 最佳情况:T(n) = O(n),数组基本有序时,插入排序复杂度最低
- 最坏情况:T(n) = O(n2)
- 平均情况:T(n) = O(n2)
希尔排序(缩小增量排序)

//希尔排序void ShellSort(vector<int> & input){if (input.empty())return;int len = input.size();int cur, gap = len / 2;while (gap > 0){for (size_t i = 0; i < len - gap; i++){cur = input[i + gap];int preIndex = i;while (preIndex >= 0 && input[preIndex] > cur){input[preIndex + gap] = input[preIndex];preIndex -= gap;}input[preIndex + gap] = cur;}gap /= 2;}}
- 最佳情况:T(n) = O(nlog2n)
- 最坏情况:T(n) = O(nlog2n)
- 平均情况:T(n) =O(nlog2n)
选择排序
是不稳定的
例如 3,3,…,2,1 -> 1, 3, …, 2, 3 -> 1, 2, …, 3, 3
//选择排序void SelectionSort(vector<int> & input){if (input.empty())return;for (size_t i = 0; i < input.size(); i++){int minIndex = i;for (size_t j = i; j < input.size(); j++){if (input[j] < input[minIndex]){minIndex = j;}}int temp = input[minIndex];input[minIndex] = input[i];input[i] = temp;}}
冒泡排序
//冒泡排序void Bubble(vector<int> & input){if (input.empty())return;for (size_t i = 0; i < input.size(); i++){bool flag = false;for (size_t j = 0; j < input.size() - i - 1; j++){if (input[j] > input[j + 1]){swap(input[i], input[j+1]);flag = true;}}if(!flag)break;}}
归并排序
- 步骤1:把长度为n的输入序列分成两个长度为n/2的子序列
- 步骤2:对这两个子序列分别采用归并排序
- 步骤3:将两个排序好的子序列合并成一个最终的排序序列

//归并排序:采用分治法vector<int> merge(vector<int> left, vector<int> right){vector<int> result;for (size_t i = 0, j = 0, k = 0; (j < left.size() || k < right.size());){if ((j < left.size()) && ((k >= right.size()) || (left[j] <= right[k]))){result.push_back(left[j++]);}if ((k < right.size()) && ((j >= left.size()) || (left[j] > right[k]))){result.push_back(right[k++]);}}return result;}vector<int> MergeSort(vector<int> input){if (input.size() < 2)return input;int mid = input.size() / 2;vector<int> left(input.begin(), input.begin() + mid);vector<int> right(input.begin() + mid, input.end());return merge(MergeSort(left), MergeSort(right));}//第二种方法,在原数组上操作void mergeSort(vector<int> &arr, int lo, int hi){if (lo == hi) {return;}int mid = ((hi - lo) >> 1) + lo;//加括号阿!!移位运算符优先级很低mergeSort(arr, lo, mid);mergeSort(arr, mid + 1, hi);merge(arr, lo, mid, hi);}void merge(vector<int> &arr, int lo, int mid, int hi){vector<int> temp(hi - lo + 1, 0);int i = 0, p1 = lo, p2 = mid + 1;while (p1 <= mid && p2 <= hi) {if(arr[p1] <= arr[p2]){//必须是<=,不然就不稳定了temp[i++] = arr[p1++];}else{temp[i++] = arr[p2++];}}while (p1 <= mid) {temp[i++] = arr[p1++];}while (p2 <= hi) {temp[i++] = arr[p2++];}for (i = 0; i < temp.size(); i++) {arr[lo + i] = temp[i];}}
- 最佳情况:T(n) = O(nlogn)
- 最差情况:T(n) = O(nlogn)
- 平均情况:T(n) = O(nlogn)
快速排序
快速排序 的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
- 步骤1:从数列中挑出一个元素,称为 “基准”(pivot );
- 步骤2:重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 步骤3:递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。


三种选取基准的方式:
https://blog.csdn.net/weixin_42636552/article/details/82258184?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
最坏情况:使用第一种,并且数组基本有序。因为每次划分只能使待排序序列减一,此时为最坏情况,快速排序沦为冒泡排序,时间复杂度为O(n^2)。
//快速排序(采用分治法)
int partition(vector<int> & input, size_t start, size_t end){
swap(input[start], input[start + rand() % (end - start + 1)]);
//cout << input[start] << endl;
int pivot = input[start];
while (start < end){
while (start < end){
if (pivot < input[end])end--;
else{
input[start++] = input[end];
break;
}
}
while (start < end){
if (input[start] < pivot)start++;
else{
input[end--] = input[start];
break;
}
}
}
input[start] = pivot;
return start;
}
vector<int> QuickSort(vector<int> & input, size_t start, size_t end){
size_t mid = partition(input, start, end);
if (mid > start)QuickSort(input, start, mid - 1);
if (mid < end)QuickSort(input, mid + 1, end);
return input;
}
堆排序
大顶堆是升序,小顶堆是降序
- 步骤1:将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;
- 步骤2:将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
- 步骤3:由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。

void adjustHeap(vector<int> &input, int i, int len){
int left = 2 * i + 1;
int right = 2 * i + 2;
int maxIndex = i;
if(left < len && input[left] > input[maxIndex]){
maxIndex = left;
}
if(right < len && input[right] > input[maxIndex]){
maxIndex = right;
}
if(maxIndex != i){
swap(input[i], input[maxIndex]);
adjustHeap(input, maxIndex, len);//向下调整
}
}
void HeapSort(vector<int> &input){
int len = input.size();
for(int i = len / 2 - 1;i >= 0;i--){
adjustHeap(input, i, len);
}
while(len > 1){
swap(input[0], input[len-1]);//此时input[0]是最大值
len--;
adjustHeap(input, 0, len);//向下调整
}
}

若有收获,就点个赞吧
0 人点赞
