Zookeeper是一个分布式协调服务的开源框架。主要用来解决分布式集群中应用系统的一致性问题,例如怎样避免同时操作同一数据造成脏读的问题。分布式系统中数据存在一致性的问题。
1. Zookeeper简介
1.1 Zookeeper是什么?
- Zookeeper本质上是一个分布式的小文件存储系统。提供基于类似于文件系统的目录树方式的数据存储,并且可以对树中的节点进行有效管理。
- Zookeeper提供给客户端监控存储在zk内部数据的功能,从而可以达到基于数据的集群管理。诸如:统一命名服务(dubbo)、分布式配置管理(solr的配置集中管理)、分布式消息队列(sub/pub)、分布式锁、分布式协调等功能。
1.2 Zookeeper的架构组成
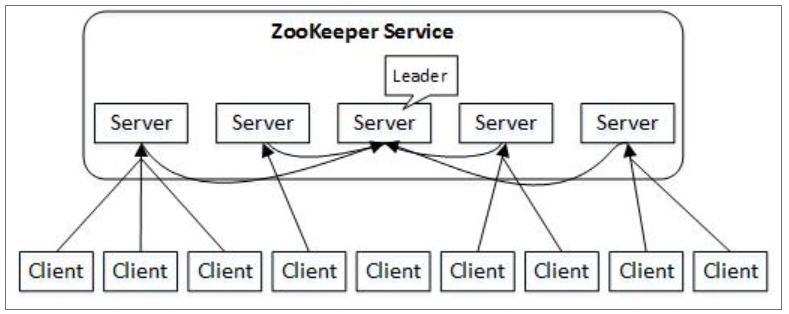
Leader**(核心组件,事务请求的唯一处理者;不是用户手动执行,而是选举出来的)**
- Zk集群工作的核心角色
- 集群内部各个服务器的调度者
- 事务请求(写操作)的唯一调度和处理者,保证集群事务处理的顺序性;对于create,setData,delete等有写操作的请求,则要统一转发给leader处理,leader需要决定编号、执行操作,这个过程称为一个事务。
Follower(处理读请求,转发事务请求到Leader;参与Leader的选举)
- 处理客户端非事务(读操作)请求
- 转发事务请求给Leader
- 参与集群Leader选举投票2n-1台可以做集群投票
此外,针对访问量比较大的zk集群,还可以新增观察者就角色。
Observer
- 观察者角色,观察zk集群的最新状态变化并将这些状态同步过来,其对于非事务请求可以进行独立处理,对于事物请求,则会转发给Leader服务器进行处理
- 不会参与任何形式的投票只提供非事务服务,通常用于在不影响集群事务处理能力的前提下提供集群的非事务处理能力。增加了集群增加并发的读请求。
ZK也是Master/Slave架构,但是与之前不同的是ZK集群中的Leader不是指定而来,而是通过选举产生。
1.3 Zookeeper特点
- zk:一个领导者(leader),多个跟随者(follower)组成的集群。
- leader负责进行投票的发起和决议,更新系统状态。
- follower用于接收客户请求并向客户端返回结果,在选举Leader过程中参与投票。
- 集群中只要有半数以上节点存活,zk集群就能正常服务。
- 全局数据一致:每个server保存一份相同的数据副本,Client无论连接到哪个server,数据都是一致的。
- 更新请求顺序进行。
- 数据更新原子性,一次数据更新要么成功,要么失败。
2. Zookeeper环境搭建
2.1 Zookeeper的搭建方式
Zookeeper安装方式有三种,单机模式和集群模式以及伪集群模式。
- 单机模式:zk只运行在一台服务器上,适合测试环境;
- 伪集群模式:就是在一台服务器上运行多个zk实例;
- 集群模式:zk运行于一个集群上,适合生产环境,这个计算机集群被称为一个“集合体”
2.2 Zookeeper集群搭建
下载
首先下载稳定版本的zookeeper
上传
下载完成后,将zk压缩包zookeeper-3.4.14.tar.gz上传到linux系统/opt/software
解压 压缩包
tar -zxvf zookeeper-3.4.14.tar.gz -C ../servers/
修改配置文件创建data与log目录
#创建zk存储数据目录mkdir -p /opt/server/zookeeper-3.4.14/data#创建zk日志文件目录mkdir -p /opt/server/zookeeper-3.4.14/data/logs#修改zk配置文件cd /opt/server/zookeeper-3.4.14/conf#文件改名mv zoo_sample.cfg zoo.cfgvim zoo.cfg#更新datadirdataDir=/opt/server/zookeeper-3.4.14/data#增加logdirdataLogDir=/opt/server/zookeeper-3.4.14/data/logs#增加集群配置##server.服务器ID=服务器IP地址;服务器之间通信端口:服务器之间投票选举端口server.1=linux121:2888:3888server.2=linux122:2888:3888server.3=linux123:2888:3888#打开注释#zk提供了自动清理事务日志和快照文件的功能。这个参数制定了清理频率,单位是小时autopurge.purgeInterval=1
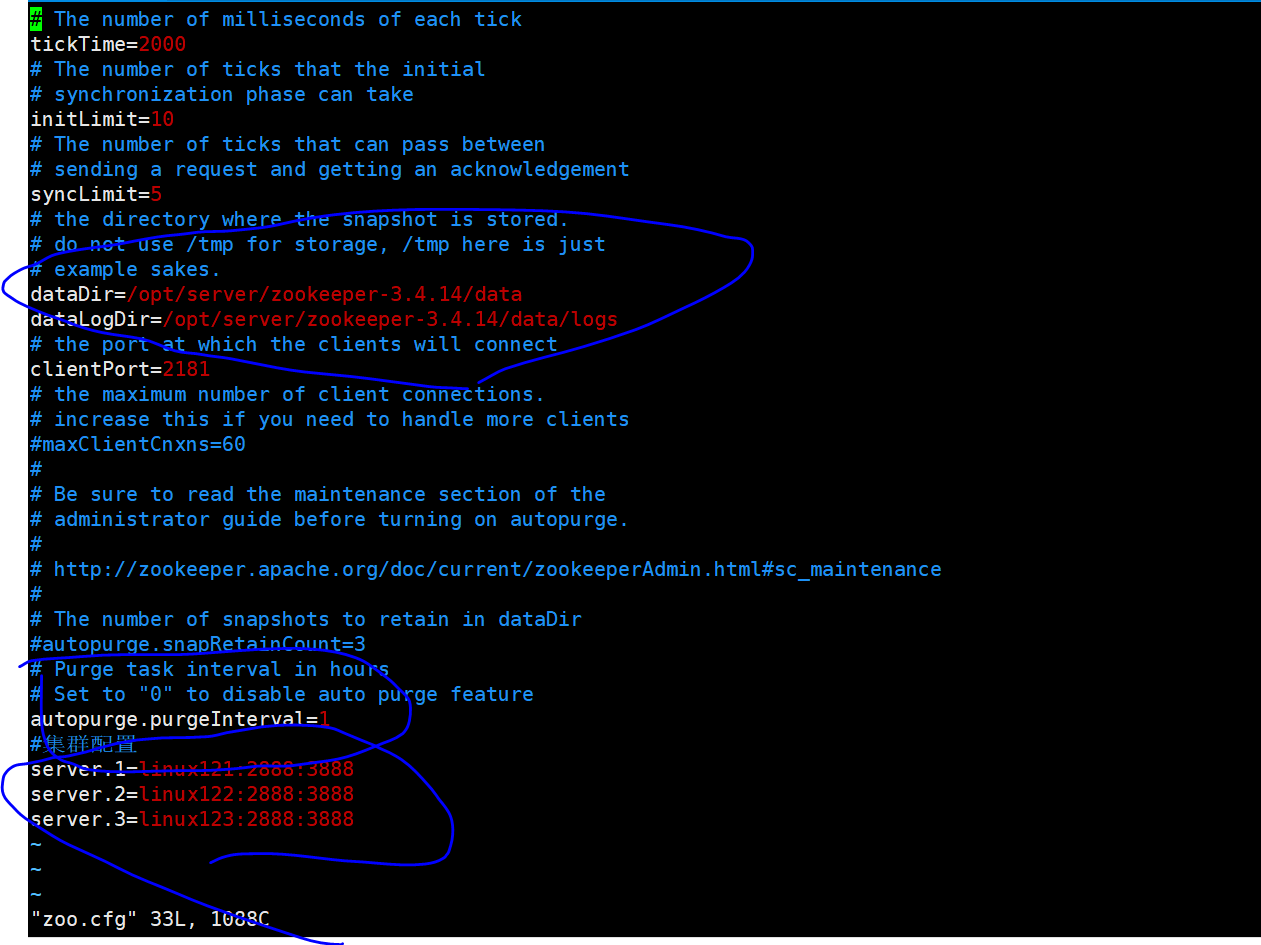
添加myid配置
1.在zk的data目录下创建一个myid文件,内容为1,这个文件就是记录每个服务器的ID
cd /opt/server/zookeeper-3.4.14/dataecho 1 > myid
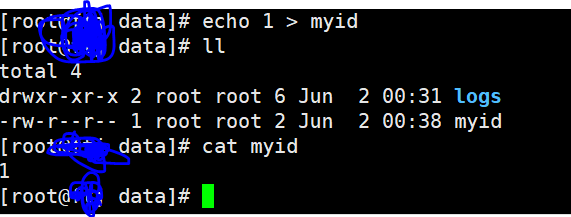
安装包分发并修改myid的值
#这里同步命令没有需要自己安装下:yum install rsync -yrsync-script /opt/server/zookeeper-3.4.14
修改myid值linux122
echo 2 >/opt/server/zookeeper-3.4.14/data/myid
修改myid值linux123
echo 3 >/opt/server/zookeeper-3.4.14/data/myid
3. Zookeeper监听机制
Zookeeper数据模型Znode
在Zk中,数据信息保存在一个个数据节点上,这些节点被称为znode。ZNode是Zk中最小数据单位,在ZNode下面又可以再挂ZNode,这样一层层下去就形成了一个层次化命名空间ZNode树,我们称为ZNode树(ZNode Tree),它采用了类似文件系统的层级树状结构进行管理。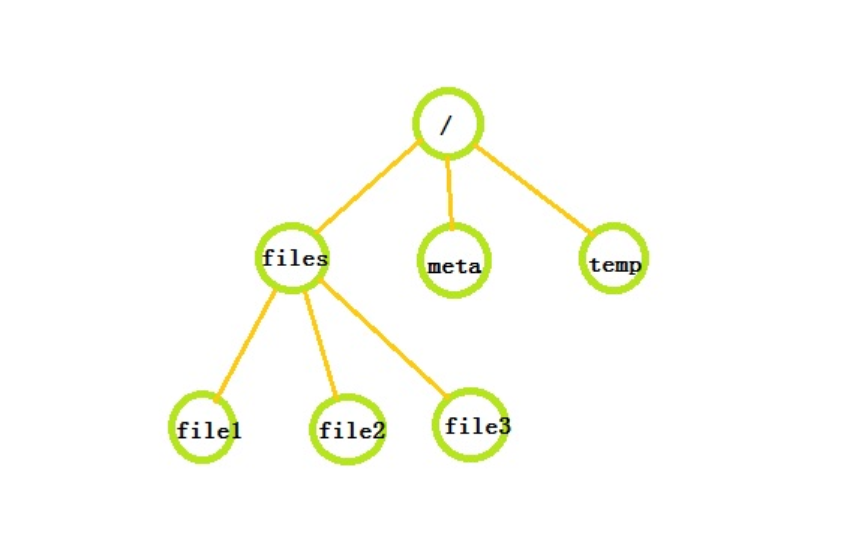
在Zk中,每个数据节点就是一个ZNode,上图根目录下有三个节点,其中files下面又有三个子节点,所有ZNode按层次进行阻止,形成这么一棵树,ZNode的节点路径标识方式和Unix文件系统路径非常相似,第都是由(/)进行分割的路径表示,开发人员可以向这个节点写入数据,也可以在这个节点下面创建子节点。
3.1 ZNode的类型
Zk节点类型可以分为三大类:
- 持久性节点(Persistent)
- 临时性节点(Ephemeral)
- 顺序性节点(Sequential)
在开发中在创建节点的时候通过组合可以生产一下四种节点类型:持久节点、持久顺序节点、临时节点、临时顺序节点。不同类型的节点有不同的生命周期
持久节点:是Zk中最常见的一种节点类型,所谓持久节点,就是指节点被创建后会一直存在服务器,直到删除操作主动清除。
持节顺序节点:就是有顺序的持久节点,节点特性和持久节点是一样的,只是额外特性表现在顺序上,顺序特定实质是在创建节点的时候,会在节点名后面加上一个数字后缀,来表示其顺序。
临时节点:就是会被自动清理掉的节点,它的生命周期和客户端会话绑定在一起,客户端会话结束,节点会被删除掉。与持久性节点不同的是,临时节点不能创建子节点。
临时顺序节点:就是有顺序的临时节点,和持节顺序节点相同,在其创建的时候会在名字后面加上数字后缀。
事务ID
首先,事务是对物理和抽象的应用状态上的操作集合。往往在现在的概念中,狭义上的事务通常指的是数据库事务,一般包含了一系列对数据库有序的读写操作,这些事务具有所谓的ACID特性,即原子性(Atomic)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
而在ZK中,事务是能够改变ZK服务器状态的操作,我们称之为事务操作或者更新操作,一般包含数据节点创建于删除、数据节点内容更新等操作。对于每一个事务请求,ZK都会为其分配一个全局唯一的事务ID,用ZXID来表示,通常是一个64位的数字,每一个ZXID对应一次更新操作,从这些ZXID中可以间接地识别出ZK处理这些更新操作请求的全局顺序。
zk中地事务指的是对zk服务器状态改变的操作(create/update data,更新子节点);zk对这些事务操作都会编号,这个编号是自增长的被称为ZXID。
3.2 ZNode的状态信息
cZxid 就是Create ZXID,表示节点被创建时的事务IDctime 就是Create Time,表示节点创建时间mZxid 就是Modified ZKID,表示节点最后一次被修改时的事务IDmtime 就是Modified Time,表示节点最后一次被修改的时间pZxid 表示该节点的子节点列表最后一次被修改时的事务ID。只有子节点列表变更才会更新pZxid,子节点内容变更不会更新。cversion 表示子节点的版本号

若有收获,就点个赞吧
0 人点赞
