人类语言 & 单词含义
如何表示一个单词的含义?
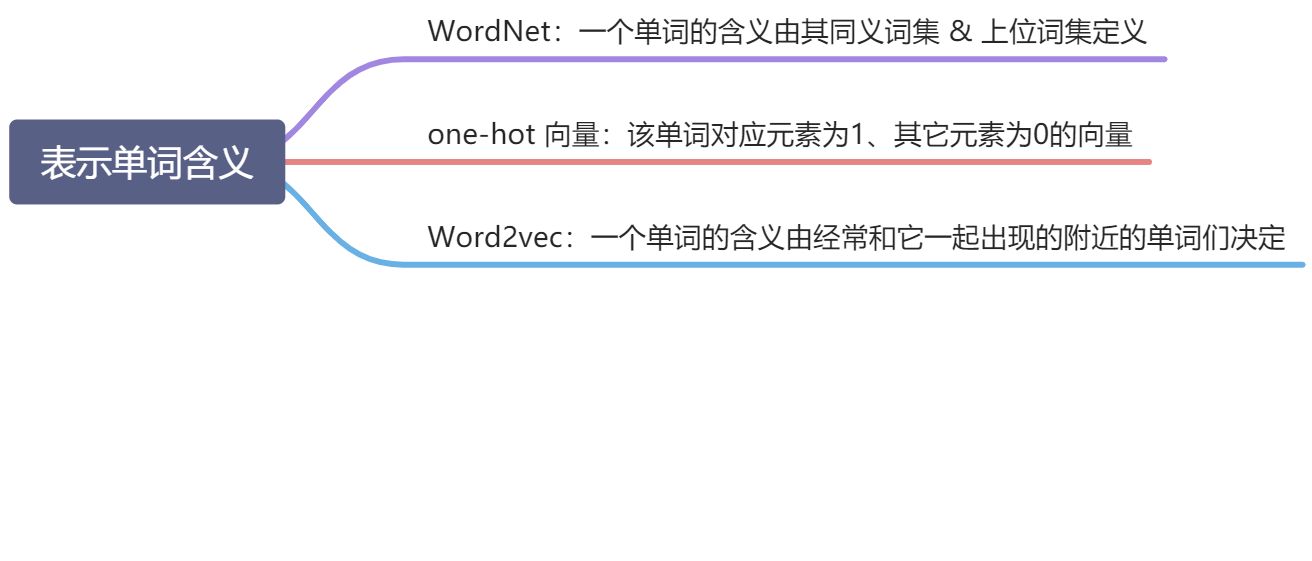
WordNet:一个单词的含义有它的同义词集合和上位词集合定义
- 缺点:
- 忽略了细微差别,eg. 两个单词可能只在某些语境下才是同义词
- 词库很难持续更新单词的新含义
- 定义比较主观
- 需要人工创造并调整词库
- 无法量化单词之间的相似度
- 缺点:
one-hot 向量表示:用一个单词对应元素为1、其余元素都为0的稀疏向量表示一个单词
- eg. motel = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0], hotel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
- 缺点:
- 所有向量都相互正交,即无法有效表示两个单词之间的相似度
- 向量维度过大:向量维度 = 词库中单词总数
Word2vec:通过一个单词的上下文来表示这个单词
- 思想:一个单词的意思通常是由出现在它附近的单词们给出的
- 上下文 contex:对于一个单词 w,定义一个以 w 为中心的固定大小的窗口,窗口中的其他词就是单词 w 的上下文

Word2vec
单词向量 Word Vector:也称为 词嵌入 word embedding、词表示 word representation ,是一种分布式的表示,
- 上一节提到的 one-hot 向量就是单词向量,但是是稀疏向量,而我们希望为单词构建的是稠密向量(大多数元素不为0,且维度较小,并且希望出现在相似上下文下的单词向量相似)
- eg.

Word2vec:Mikolov et al. 2013
- 想法:
- 已知我们有语料库,包含大量文本
- 给语料库中的每个单词一个向量表示
- 用固定窗口不断扫描语料库的文本,对于每次(每个时间点 t 的)扫描(即每个窗口位置),有一个中心词 c 以及其上下文单词 o(也称外部单词)
- c 和 o 的词向量的相似性可以用来计算给定 c 的情况下条件 o 的概率

- 不断迭代调整词向量使得这个条件概率最大化
- 例子:窗口大小=2,中心词分别为 into 和 banking 时上下文单词的条件概率计算过程:

- 每个单词 w 可以用两个向量表示
- 作为中心词时的向量

- 作为上下文时的向量

- 作为中心词时的向量
- 已知中心词 c 时上下文单词 o 的条件概率:
 ,即 softmax
,即 softmax - 整体的似然率

- m 是窗口大小,t 是当前中心词位置
- 目标函数

- 可以使用梯度下降法,逐步求得是目标函数最小化的词向量形式

若有收获,就点个赞吧
0 人点赞
