前言
随机裁剪函数,具体的解释可以读一读英文的官方api,
共有5个参数,
size
padding
pad_id_needed
fill
padding_mode
官方Api介绍
_Crop the given image at a random location.
If the image is torch Tensor, it is expected
to have […, H, W] shape, where … means an arbitrary number of leading dimensions,
but if non-constant padding is used, the input is expected to have at most 2 leading dimensions
Args:
size (sequence or int): Desired output size of the crop. If size is an
int instead of sequence like (h, w), a square crop (size, size) is
made. If provided a sequence of length 1, it will be interpreted as (size[0], size[0]).
padding (int or sequence, optional): Optional padding on each border
of the image. Default is None. If a single int is provided this
is used to pad all borders. If sequence of length 2 is provided this is the padding
on left/right and top/bottom respectively. If a sequence of length 4 is provided
this is the padding for the left, top, right and bottom borders respectively.
.. note::<br /> In torchscript mode padding as single int is not supported, use a sequence of<br /> length 1: ``[padding, ]``.<br /> pad_if_needed (boolean): It will pad the image if smaller than the<br /> desired size to avoid raising an exception. Since cropping is done<br /> after padding, the padding seems to be done at a random offset.<br /> fill (number or str or tuple): Pixel fill value for constant fill. Default is 0. If a tuple of<br /> length 3, it is used to fill R, G, B channels respectively.<br /> This value is only used when the padding_mode is constant.<br /> Only number is supported for torch Tensor.<br /> Only int or str or tuple value is supported for PIL Image.<br /> padding_mode (str): Type of padding. Should be: constant, edge, reflect or symmetric.<br /> Default is constant.- constant: pads with a constant value, this value is specified with fill- edge: pads with the last value at the edge of the image.<br /> If input a 5D torch Tensor, the last 3 dimensions will be padded instead of the last 2- reflect: pads with reflection of image without repeating the last value on the edge.<br /> For example, padding [1, 2, 3, 4] with 2 elements on both sides in reflect mode<br /> will result in [3, 2, 1, 2, 3, 4, 3, 2]- symmetric: pads with reflection of image repeating the last value on the edge.<br /> For example, padding [1, 2, 3, 4] with 2 elements on both sides in symmetric mode<br /> will result in [2, 1, 1, 2, 3, 4, 4, 3]_
需准备的东西
演示代码
# 导入库import torchvision.transforms as transformsimport torchvision as tvimport matplotlib.pyplot as pltimport matplotlib# 设置字体 这两行需要手动设置matplotlib.rcParams['font.sans-serif'] = ['SimHei']matplotlib.rcParams['axes.unicode_minus'] = False# 1. 中心裁剪transform = transforms.Compose([transforms.RandomCrop(size=(2100, 3174), padding=700, pad_if_needed=True, fill=180, padding_mode='constant')])# 读取图片picTensor = tv.io.read_image('testpic.png')# 转换图片picTransformed = transform(picTensor)# 显示print('图像处理之前的图片大小:', picTensor.shape)print('图像之后的图片大小:', picTransformed.shape)picNumpy = picTensor.permute(1, 2, 0).numpy()plt.imshow(picNumpy)plt.title('图像处理之前的图片')plt.show()picNumpy = picTransformed.permute(1, 2, 0).numpy()plt.imshow(picNumpy)plt.title('图像处理之后的图片')plt.show()
图像处理之前的图片大小: torch.Size([3, 2100, 3174]) 图像之后的图片大小: torch.Size([3, 2100, 3174])
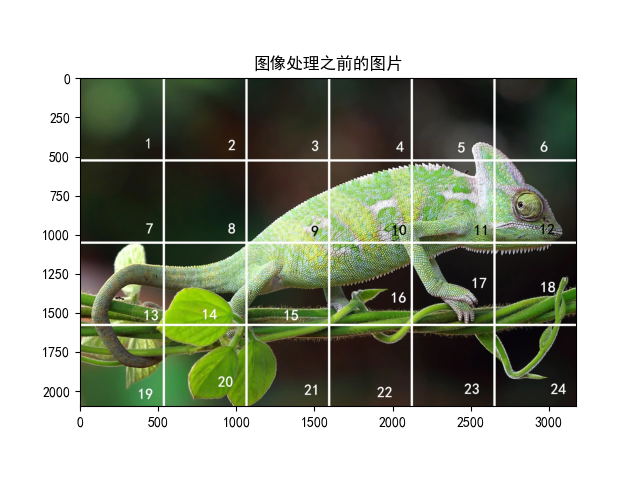
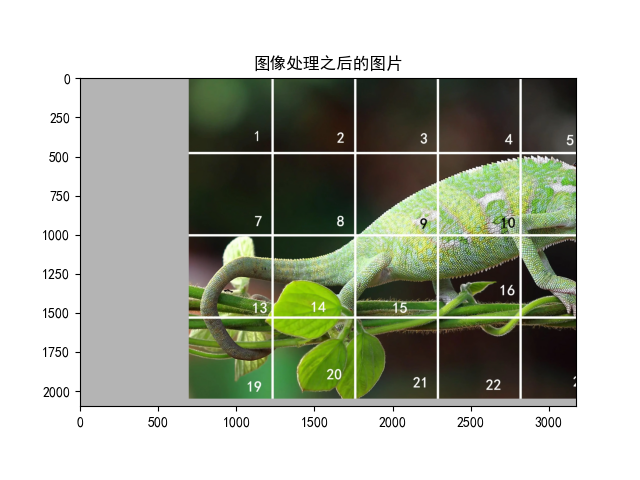

若有收获,就点个赞吧
0 人点赞
