面向对象三大基本特征
我们说面向对象的开发范式,其实是对现实世界的理解和抽象的方法.面向对象的三大特性,分别是封装性、继承性和多态性.
封装
封装指的是将客观的事物抽象化为类,并且使类中的数据和方法针对操作对象进行管理.
继承
继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展.
通过继承创造的新类被称为”子类”或者”派生类”,被继承的类称为”基类””超类”或者”父类”.继承实际上就是将一般变为特殊的过程.
多态
多态指的是一个类实例的相同方法在不同情况下有不同的表现形式。多态为不同的数据类型的实体提供了统一的接口。
基本数据类型
Java 中有 8 种基本数据类型,分别为:
| 基本类型 | 位数 | 默认值 |
|---|---|---|
| int | 32 | 0 |
| short | 16 | 0 |
| long | 64 | 0L |
| byte | 8 | 0 |
| char | 16 | ‘u0000’ |
| float | 32 | 0f |
| double | 64 | 0d |
| boolean | 1 | false |
注意:
- Java里使用long类型的数据一定要在数值后面加上L,否则将作为整型解析。
- char a = ‘h’char : 单引号,String a = “hello” : 双引号。
这八种基本类型都有对应的包装类分别为:Byte、Short、Integer、Long、Float、Double、Character、Boolean
包装类型不赋值就是Null,而基本类型有默认值且不是Null。
包装类型的常量池技术
首先是JVM的虚拟内存分布: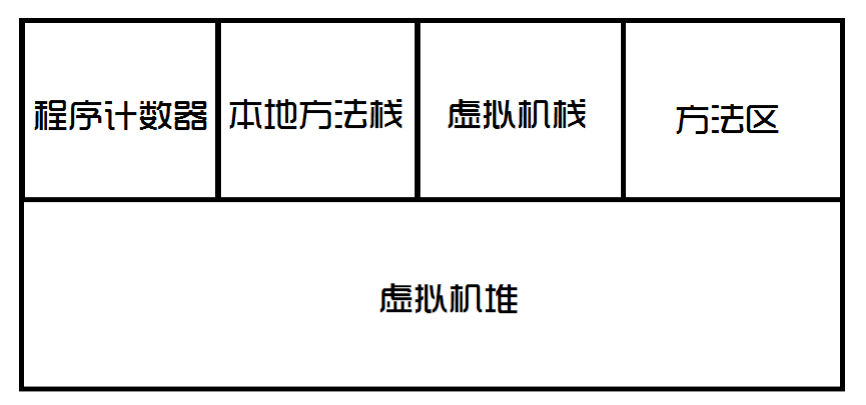
- 程序计数器是jvm执行程序的流水线,存放一些跳转指令。
- 本地方法栈是jvm调用操作系统方法所使用的栈。
- 虚拟机栈是jvm执行java代码所使用的栈。
- 方法区存放了一些常量、静态变量、类信息等,可以理解成class文件在内存中的存放位置。
- 虚拟机堆是jvm执行java代码所使用的堆。
Java中的常量池,实际上分为两种形态:静态常量池和运行时常量池。
静态常量池主要存放字面量和符号引用量。
而我们常说的常量池就是运行时常量池。其将class文件内的常量池加载到内存中,保存在方法区里。运行时常量池的一大特点就是具有动态性,运行期间产生的常量也可以加入常量池中。
常量池的好处主要是节省内存空间和运行时间,避免大量重复的创建和销毁对象。
自动装箱与拆箱
- 装箱:将基本类型用它们对应的引用类型包装起来。
- 拆箱:将包装类型转换为基本数据类型。
装箱实际上就是调用了包装类的Integer i = 10; //装箱int n = i; //拆箱
valueOf方法,拆箱则是调用了xxValue的方法。由此上述代码等价于:
需要注意的是,如果频繁的拆装箱,会严重影响系统性能,一般需要避免。Integer i = Integer.valueOf(10); //装箱int n = i.intValue(); //拆箱
静态方法和实例方法
在Java中,方法可以是静态的也可以是实例方法。其最大的不同在于是否需要在使用方法时进行对象的实例化。
当然,在外部调用静态方法的时候,也可以使用// 静态方法的创建public class Person{public void method(){//}public static void staticMethod(){//}public static void main(){//示例化对象personPerson person = new Person();//调用实例方法person.method();//调用静态方法Person.staticMethod();}
对象.方法名的方式,但是我们一般不这样使用以避免造成混淆。
静态方法在访问类成员的时候也存在限制, 只允许访问静态成员(即静态成员变量和静态方法),不允许访问实例成员(即实例成员变量和实例方法),而实例方法不存在这个限制。 其原因在于静态方法在类加载时就会分配内存,可以通过类名直接访问,而非静态成员需要对象实例化后才存在,属于非法访问。重载和重写
重载和重写的区别
重载就是同样的一个方法能够根据输入数据的不同,做出不同的处理
重写就是当子类继承自父类的相同方法,输入数据一样,但要做出有别于父类的响应时,你就要覆盖父类方法
重载
发生在同一个类中(或者父类和子类之间),方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。
重写
重写发生在运行期,是子类对父类的允许访问的方法的实现过程进行重新编写。
- 方法名、参数列表必须相同,子类方法返回值类型应比父类方法返回值类型更小或相等,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。
- 如果父类方法访问修饰符为
private/final/static则子类就不能重写该方法,但是被 static 修饰的方法能够被再次声明。 - 构造方法无法被重写。
重写和重载的区别特征其实就是,重写是内部逻辑变,外部名称和参数都不变;而重载则是同名不同参数。
hashCode() 与 equals()
首先要注意的是==和equals()的区别
对于基本数据类型来说,==比较的是值,而对于引用数据类型来说则是对象的地址。因此如果使用其来比较诸如String这样的数据类型就会出现一些问题。因此我们要使用equals()equals() 方法存在两种使用情况:
- 类没有覆盖
**equals()**方法 :通过equals()比较该类的两个对象时,等价于通过==比较这两个对象,使用的默认是 Object类equals()方法。 - 类覆盖了
**equals()**方法 :一般我们都覆盖equals()方法来比较两个对象中的属性是否相等;若它们的属性相等,则返回true.
当我们需要使用equals()去比较两个引用数据类型的值是否相同时,我们会在设计该类时重写该方法以达到目的。
为什么要有 hashCode?
hashCode()的作用是获取哈希码(int 整数),也称为散列码。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode()定义在 JDK 的 Object 类中,这就意味着 Java 中的任何类都包含有hashCode()函数。另外需要注意的是: Object 的 hashCode()方法是本地方法,也就是用 C 语言或 C++ 实现的,该方法通常用来将对象的内存地址转换为整数之后返回。
引入hashCode()的目的是为了比较对象是否重复出现,这点就和我们使用hashset去存储是一样的,通过键值对来快速查找是否存在。
为什么还要有equals?
原因是哪怕再好的hash算法,也会存在碰撞的现象。因此要针对碰撞的情况再判断两个对象是否相等。判断的大致流程如下:

若有收获,就点个赞吧
0 人点赞
