shuffle机制在MapReduce整个过程中非常重要,试想如果没有shuffle机制,以wordCount为例,相同的key就没法落在同一个数据分区中,自然不能被同一个ReduceTask处理。
shuffle核心机制: 数据分区,排序,分组,combine,合并等。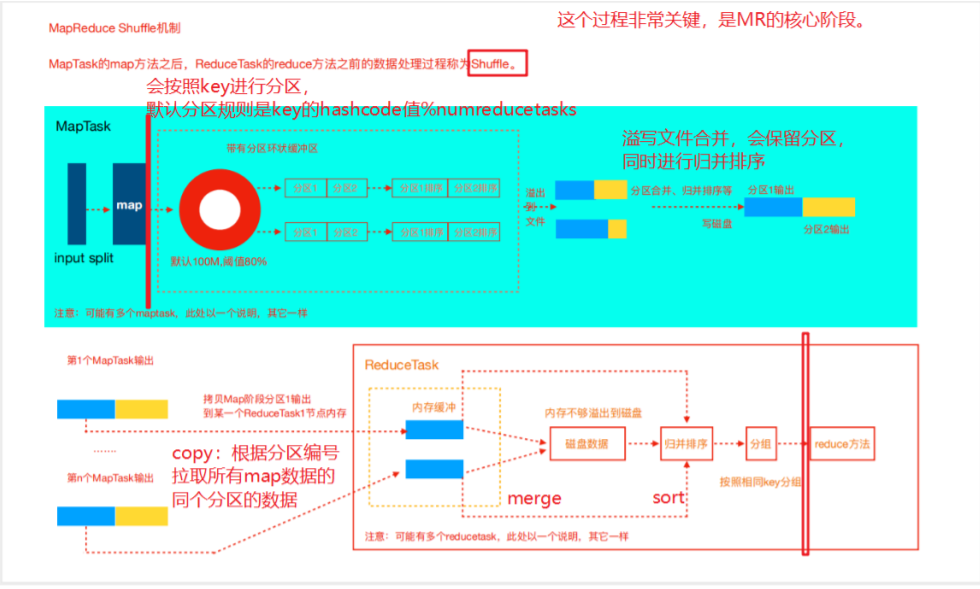
- 从map完成开始,shuffle阶段正式开始。首先map阶段的数据都会先进入一个缓冲区,缓冲区的默认大小是100M,当缓冲区的数据达到80%,就会将这80%的数据溢写到磁盘中作为一个分区文件,剩下的20%空间继续做缓存的工作。
- 溢写到磁盘中的数据分区会进行一个Sort,Sort是hadoop默认的机制,这里不深入讨论。
- 排好序的分区会合并、然后再进行总体归并排序,由多个分区文件变为一个文件的过程,其目的是减少网络IO的传输。
- 然后再Reduce之前,MapTask会将数据输出到Reduce的节点上。这其中是由ReduceTask向MapTask发起HTTP请求,ReduceTask会请求属于自己的数据,这其中是Partitioner起了作用,Partitioner会筛选key到分区,以此将MapTask的满足同一个筛选条件的数据拉取到ReduceTask的节点上,进行Reduce工作。
- ReduceTask接收到数据后,也是会先放到内存缓存中,当内存缓存不够也是将数据溢出到磁盘中,接下来类似地将数据进行归并排序,最后按照相同的key进行分组。如果只有一种key,那就是分一个组,如果有多个key,则是在一个文件中,相同的key的数据分开放。
- 分组后,shuffle阶段就结束了,接下来就是执行Reduce方法了。

若有收获,就点个赞吧
0 人点赞
