HDFS的简介
- HDFS (全称:Hadoop Distribute File System,Hadoop 分布式⽂件系统)是 Hadoop 核⼼组成,是其分布式存储服务。
- 分布式⽂件系统横跨多台计算机,在⼤数据时代有着⼴泛的应⽤前景,它们为存储和处理超⼤规模数据
提供所需的扩展能⼒。 - HDFS是分布式⽂件系统中的⼀种。
核心概念
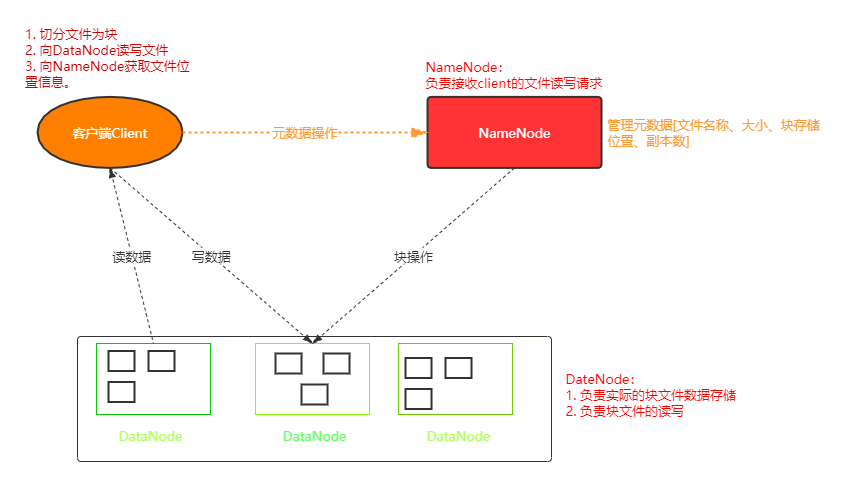
- Master/Slave架构
HDFS是典型的Master/Slave结构,其中NameNode为主节点,DataNode为从节点,HA架构通常都是配置额外的热备份NameNode(联邦机制)。 - 分块存储(block机制)
HDFS在物理存储上,是以块文件形式存储的,默认的块大小是128M。小于128M的文件,分配128M的块进行存储,大于128M的文件则切分为多个128M的文件进行存储。其中文件的切分存储并不是严格按照128M,而是有一个10%的上限差,例如129M的文件也会单独分块存储(129 < 128 * 1.1)。 - 命名空间(NameSpace)
HDFS ⽀持传统的层次型⽂件组织结构。⽤户或者应⽤程序可以创建⽬录,然后将⽂件保存在这些
⽬录⾥。⽂件系统名字空间的层次结构和⼤多数现有的⽂件系统类似:⽤户可以创建、删除、移动
或重命名⽂件。
Namenode 负责维护⽂件系统的名字空间,任何对⽂件系统名字空间或属性的修改都将被Namenode 记录下来。 - NameNode元数据管理
元数据:文件的目录结构以及文件分块位置信息。
NameNode的元数据记录每⼀个⽂件所对应的block信息(block的id,以及所在的DataNode节点的信息) - DataNode数据存储
具体的数据块block都存储在DataNode节点上,一个block默认会存储三份在不同的DataNode上。
DataNode会定时向NameNode汇报自己的状态,包括持有的block信息。 - 副本机制
为了容错,⽂件的所有 block 都会有副本。每个⽂件的 block ⼤⼩和副本系数都是可配置的。应⽤
程序可以指定某个⽂件的副本数⽬。副本系数可以在⽂件创建的时候指定,也可以在之后改变。
副本数量默认是3个。 - ⼀次写⼊,多次读出
HDFS 是设计成适应⼀次写⼊,多次读出的场景,且不⽀持⽂件的随机修改。 (⽀持追加写⼊,不
只⽀持随机更新)
正因为如此,HDFS 适合⽤来做⼤数据分析的底层存储服务,并不适合⽤来做⽹盘等应⽤(修改不
⽅便,延迟⼤,⽹络开销⼤,成本太⾼)
HDFS架构
HDFS读写解析
HDFS读数据流程
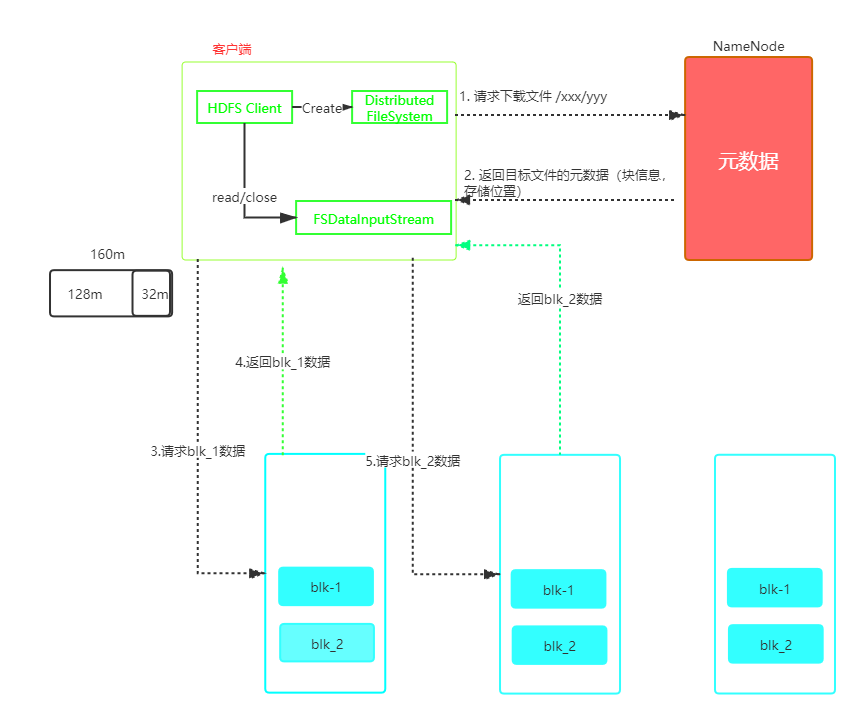
- 客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode读取元数据,找到文件的块信息返回给客户端。
- 就近原则寻找一台DataNode服务器,请求读取数据。
- DataNode传输文件数据给客户端,以Packet为单位传输校验,Packet的大小为64kb。
- 客户端接收Packet,先缓存在本地,然后写入目标文件。
HDFS写数据流程
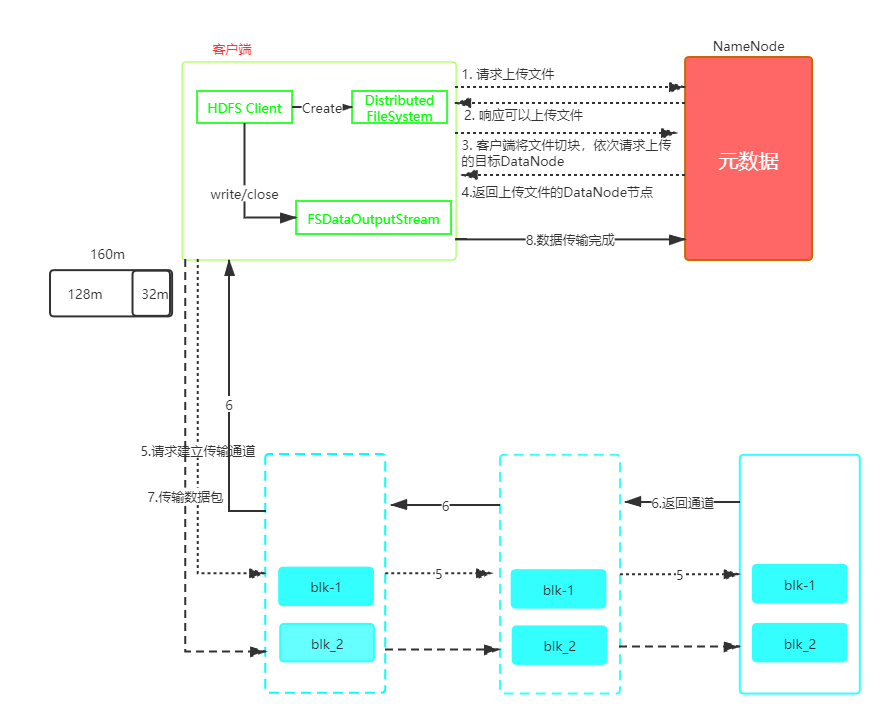
- 客户端通过Distributed FileSystem 向NameNode请求上传文件,NameNode判断上传路径是否合法,且集群有足够的空间。
- 若满足条件1,返回客户端可以上传文件。
- 客户端将文件切分为Block块,分别请求Block要上传到哪几个DataNode节点上。
- NameNode根据集群节点情况,选择存储压力较小的几个节点信息给客户端。
- DataNode请求就近的DataNode上传数据,DataNode根据客户端的请求信息,去打通整个传输数据的通道。
- DataNode逐级应答,然后返回信息给客户端。
- 客户端开始上传Block(先从本地将数据读取到缓存),以Packet数据包为单位,上传到DataNode,然后依次传输到下一个DataNode,没传输一个Packet都会进入确认队列等待确认。
- 当一个Block传输完成,依次传输下一个Block。
HDFS元数据管理机制
- HDFS管理和存储元数据是通过内存和磁盘共同作用的。
- 内存将日志滚动到edit文件中,磁盘存储的是FsImage文件,两者的内容合并才是完成的元数据。
- 合并edit和FsImage两个文件的工作在SecondaryNameNode上完成。
元数据管理流程图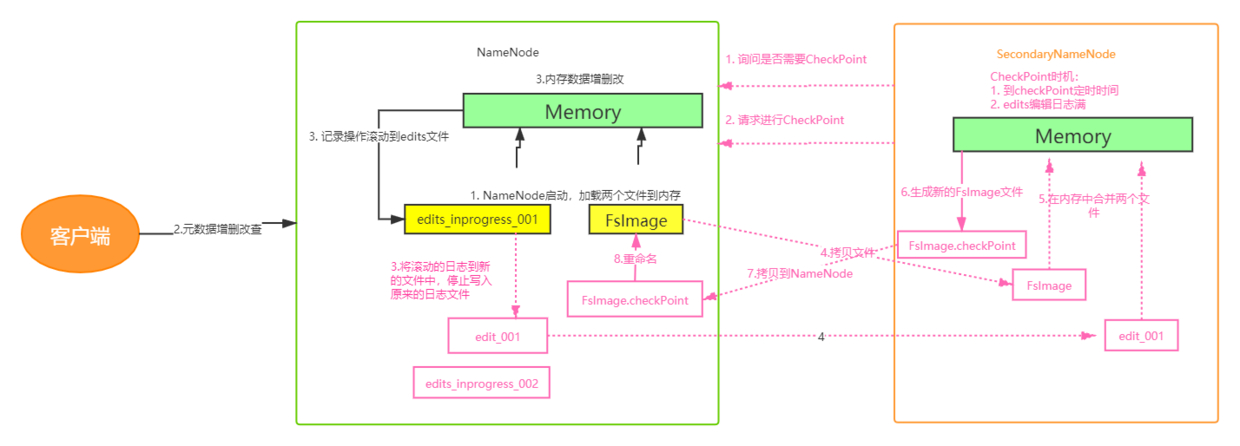
FsImage和edits文件解析

- fsImage文件:是NameNode中关于元数据的镜像文件,一般称为检查点,这⾥包含了HDFS⽂件系统
所有⽬录以及⽂件相关信息(Block数量,副本数量,权限等信息) - Edits⽂件 :存储了客户端对HDFS⽂件系统所有的更新操作记录,Client对HDFS⽂件系统所有的更新操作都会被记录到Edits⽂件中(不包括查询操作)
- seen_txid:该⽂件是保存了⼀个数字,数字对应着最后⼀个Edits⽂件名的数字
- VERSION:该⽂件记录namenode的⼀些版本号信息,⽐如:CusterId,namespaceID等
查询fsImage和edits文件的内容
基本语法
- 查看fsImage文件
hdfs oiv -p ⽂件类型 -i 镜像⽂件 -o 转换后⽂件输出路径
hdfs oiv -p XML -i fsimage_0000000000000000265 -o /opt/lagou/servers/fsimage.xml
- 查看edits文件
hdfs oev -p ⽂件类型 -i编辑⽇志 -o 转换后⽂件输出路径
hdfs oev -p XML -i edits_0000000000000000266-0000000000000000267 -o /opt/lagou/servers/hadoop-2.9.2/edits.xml
CheckPoint周期
[hdfs-default.xml]
<!-- 定时⼀⼩时 --><property><name>dfs.namenode.checkpoint.period</name><value>3600</value></property><!-- ⼀分钟检查⼀次操作次数,3当操作次数达到1百万时,SecondaryNameNode执⾏⼀次 --><property><name>dfs.namenode.checkpoint.txns</name><value>1000000</value><description>操作动作次数</description></property><property><name>dfs.namenode.checkpoint.check.period</name><value>60</value><description> 1分钟检查⼀次操作次数</description></property >
Hadoop的限额与归档以及集群安全模式
- HDFS⽂件限额配置
HDFS⽂件的限额配置允许我们以⽂件⼤⼩或者⽂件个数来限制我们在某个⽬录下上传的⽂件数量或者
⽂件内容总量,以便达到我们类似百度⽹盘⽹盘等限制每个⽤户允许上传的最⼤的⽂件的量。
- 数量限额
hdfs dfs -mkdir -p /user/root/lagou #创建hdfs⽂件夹
hdfs dfsadmin -setQuota 2 /user/root/lagou # 给该⽂件夹下⾯设置最多上传两个⽂件,上传⽂件,发现只能上传⼀个⽂件
hdfs dfsadmin -clrQuota /user/root/lagou # 清除⽂件数量限制
- 空间⼤⼩限额
hdfs dfsadmin -setSpaceQuota 4k /user/root/lagou # 限制空间⼤⼩4KB
#上传超过4Kb的⽂件⼤⼩上去提示⽂件超过限额
hdfs dfs -put /export/softwares/xxx.tar.gz /user/root/lagou
hdfs dfsadmin -clrSpaceQuota /user/root/lagou #清除空间限额
#查看hdfs⽂件限额数量
hdfs dfs -count -q -h /user/root/lagou
- HDFS的安全模式
- 安全模式是HDFS所处的⼀种特殊状态,在这种状态下,⽂件系统只接受读数据请求,⽽不接受删
除、修改等变更请求。 - 在NameNode主节点启动时,HDFS⾸先进⼊安全模式,DataNode在启动
的时候会向NameNode汇报可⽤的block等状态,当整个系统达到安全标准时,HDFS⾃动离开安
全模式。 - 如果HDFS出于安全模式下,则⽂件block不能进⾏任何的副本复制操作,因此达到最⼩的
副本数量要求是基于DataNode启动时的状态来判定的,启动时不会再做任何复制(从⽽达到最⼩
副本数量要求),HDFS集群刚启动的时候,默认30S钟的时间是出于安全期的,只有过了30S之
后,集群脱离了安全期,然后才可以对集群进⾏操作。
- 安全模式是HDFS所处的⼀种特殊状态,在这种状态下,⽂件系统只接受读数据请求,⽽不接受删
hdfs dfsadmin -safemode
- Hadoop归档技术
主要解决HDFS集群存在⼤量⼩⽂件的问题!!
由于⼤量⼩⽂件会占⽤NameNode的内存,因此对于HDFS来说存储⼤量⼩⽂件造成NameNode
内存资源的浪费!
Hadoop存档⽂件HAR⽂件,是⼀个更⾼效的⽂件存档⼯具,HAR⽂件是由⼀组⽂件通过archive⼯
具创建⽽来,在减少了NameNode的内存使⽤的同时,可以对⽂件进⾏透明的访问,通俗来说就
是HAR⽂件对NameNode来说是⼀个⽂件减少了内存的浪费,对于实际操作处理⽂件依然是⼀个
⼀个独立的⽂件。
案例
- 启动YARN集群
start-yarn.sh
- 归档⽂件
# 将/user/root/input下的文件归档成input.har放在/user/root/output中。
bin/hadoop archive -archiveName input.har –p /user/root/input /user/root/output
- 查看归档
hadoop fs -ls -R har:///user/root/output/input.har
- 解归档⽂件
hadoop fs -cp har:///user/root/output/input.har/* /user/root

若有收获,就点个赞吧
0 人点赞
