一、哈希表理论基础
哈希表
首先什么是哈希表,哈希表(英文名为 Hash Table,国内也有一些算法书籍翻译为散列表,看到这两个名称知道都是指hash table 就可以了)。
哈希表是根据关键码的值而直接进行访问的数据结构。
这么官方的解释可能有点懵,其实直白来讲,其实数组就是一张哈希表。
哈希表中关键码就是数组的索引下标,然后通过下标直接访问数组中的元素,如下图所示: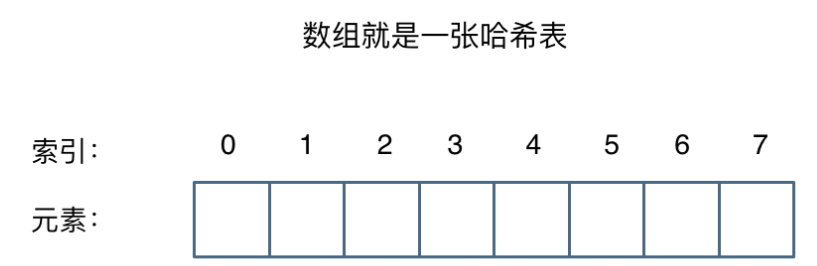
那么哈希表能解决什么问题呢?一般哈希表都是用来快速判断一个元素是否出现集合里。
例如要查询一个名字是否在这所学校里。
要枚举的话时间复杂度是O(n),但如果使用哈希表的话,只需要O(1)就可以做到。
我们只需要初始化把这所学校里学生的名字都存在哈希表里,在查询的时候通过索引直接就可以知道这位同学在不在这所学校里了。
将学生姓名映射到哈希表上就涉及到了 hash function,也就是哈希函数。
哈希函数
哈希函数,把学生的姓名直接映射为哈希表上的索引,然后就可以通过查询索引下标快速知道这位同学是否在这所学校里了。
哈希函数如下图所示,通过hashCode把名字转化为数值,一般hashcode是通过特定编码方式,可以将其他数据格式转化为不同的数值,这样就把学生名字映射为哈希表上的索引数字了。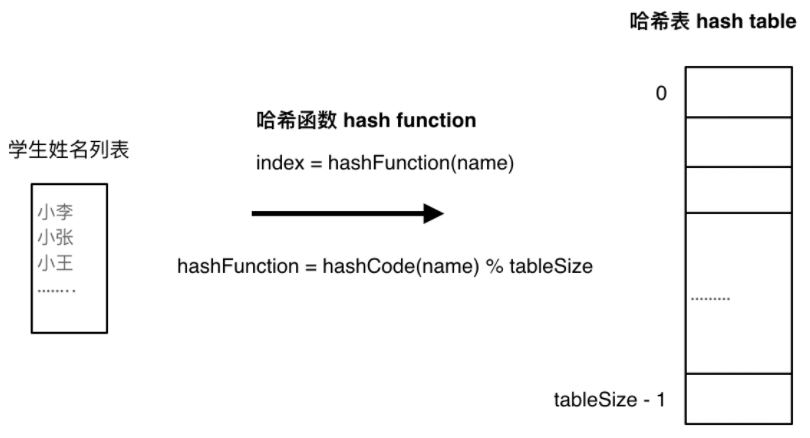
如果hashCode得到的数值大于哈希表的大小了,也就是大于 tableSize 了,怎么办呢?
此时为了保证映射出来的索引数值都落在哈希表上,我们会在此对数值做一个取模的操作,这样我们就保证了学生姓名一定可以映射到哈希表上了。
此时问题又来了,我们刚刚说过,哈希表就是一个数组。
如果学生的数量大于哈希表的大小怎么办?此时就算哈希函数计算的再均匀,也避免不了会有几位学生的名字同时映射到哈希表同一个索引下标的位置。
接下来哈希碰撞登场。
哈希碰撞
如图所示,小李和小王都映射到了索引下标1的位置,这一现象叫做哈希碰撞。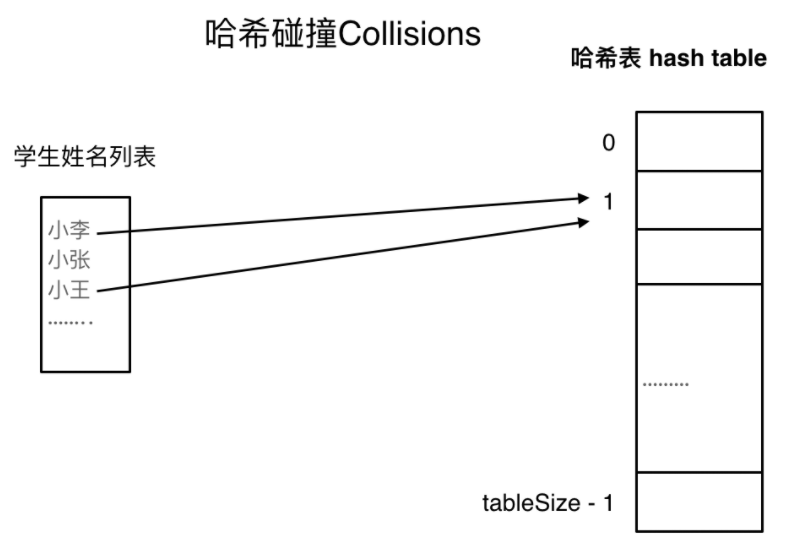
拉链法
刚刚小李和小王在索引1的位置发生了冲突,发生冲突的元素都被存储再链表中。这样我们就可以通过索引找到小李和小王了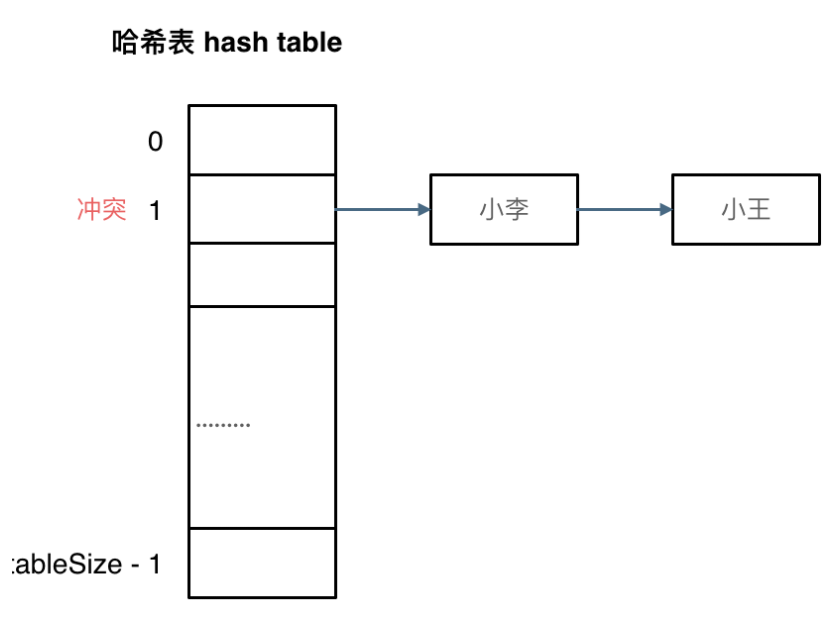
(数据规模是 dataSize,哈希表的大小为 tableSize)
其实拉链法就是要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。
线性探测法
使用线性探测法,一定要保证 tableSize 大于 dataSize。我们需要依靠哈希表中的空位来解决碰撞问题。
例如冲突的位置,放了小李,那么就向下找一个空位放置小王的信息。所以要求 tableSize 一定要大于 dataSize,要不然哈希表上就没有空置的位置来存放冲突的数据了。如图所示: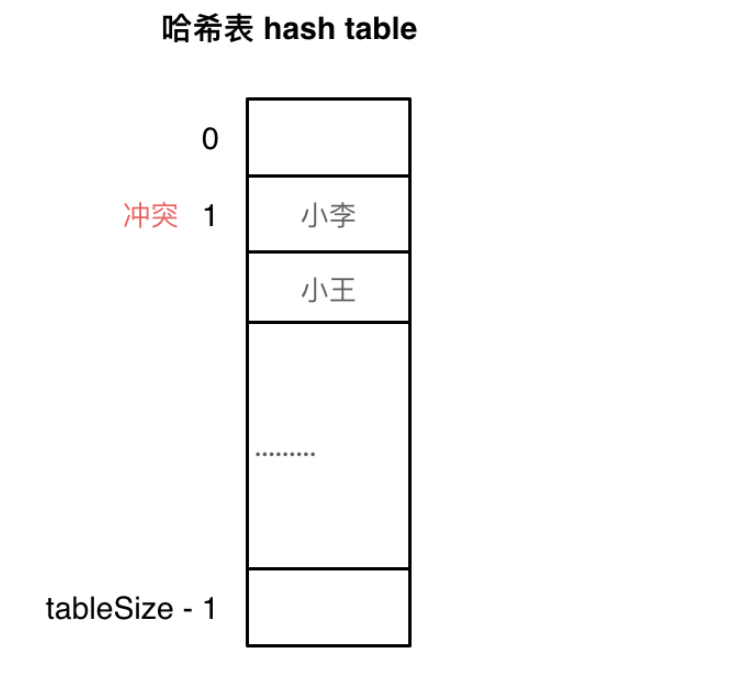
其实关于哈希碰撞还有非常多的细节,感兴趣的同学可以再好好研究一下,这里我就不再赘述了。
常见的三种哈希结构
当我们想使用哈希法来解决问题的时候,我们一般会选择如下三种数据结构。
- 数组
- set(集合)
- map(映射)
这里数组就没啥可说的了,我们来看一下set。
在 C++ 中,set 和 map 分别提供以下三种数据结构,其底层实现以及优劣如下表所示:
| 集合 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::set | 红黑树 | 有序 | 否 | 否 | $O(\log n)$ | $O(\log n)$ |
| std::multiset | 红黑树 | 有序 | 是 | 否 | $O(\log n)$ | $O(\log n)$ |
| std::unordered_set | 哈希表 | 无序 | 否 | 否 | $O(1)$ | $O(1)$ |
std::unordered_set底层实现为哈希表,std::set 和std::multiset 的底层实现是红黑树,红黑树是一种平衡二叉搜索树,所以key值是有序的,但key不可以修改,改动key值会导致整棵树的错乱,所以只能删除和增加。
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | key不可修改 | $O(\log n)$ | $O(\log n)$ |
| std::multimap | 红黑树 | key有序 | key可重复 | key不可修改 | $O(\log n)$ | $O(\log n)$ |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | key不可修改 | $O(1)$ | $O(1)$ |
std::unordered_map 底层实现为哈希表,std::map 和std::multimap 的底层实现是红黑树。同理,std::map 和std::multimap 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解)。
当我们要使用集合来解决哈希问题的时候,优先使用unordered_set,因为它的查询和增删效率是最优的,如果需要集合是有序的,那么就用set,如果要求不仅有序还要有重复数据的话,那么就用multiset。
那么再来看一下 map,在 map 是一个 key value 的数据结构,在 map 中,对 key 是有限制,对 value 没有限制的,因为 key 的存储方式使用红黑树实现的。
其他语言例如:java里的HashMap ,TreeMap 都是一样的原理。可以灵活贯通。
虽然std::set、std::multiset 的底层实现是红黑树,不是哈希表,但是std::set、std::multiset 依然使用哈希函数来做映射,只不过底层的符号表使用了红黑树来存储数据,所以使用这些数据结构来解决映射问题的方法,我们依然称之为哈希法。 map也是一样的道理。
这里在说一下,一些C++的经典书籍上 例如STL源码剖析,说到了hash_set hash_map,这个与unordered_set,unordered_map又有什么关系呢?
实际上功能都是一样一样的, 但是unordered_set在C++11的时候被引入标准库了,而hash_set并没有,所以建议还是使用unordered_set比较好,这就好比一个是官方认证的,hash_set,hash_map 是C++11标准之前民间高手自发造的轮子。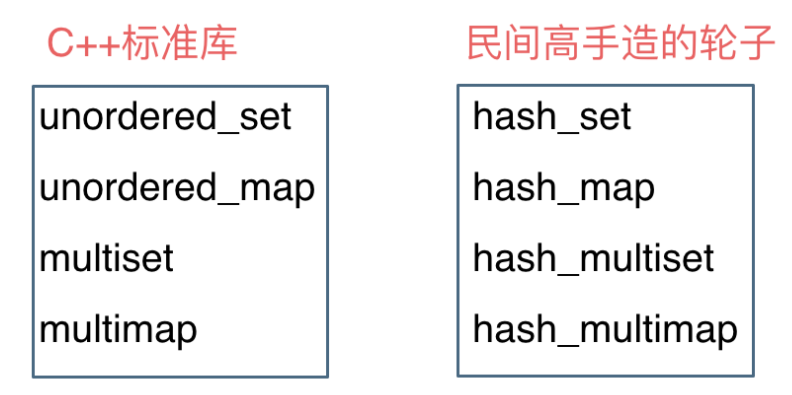
总结
总结一下,当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。
但是哈希法也是牺牲了空间换取了时间,因为我们要使用额外的数组,set 或者是 map 来存放数据,才能实现快速的查找。
如果在做面试题目的时候,遇到需要判断一个元素是否出现过的场景也应该第一时间想到哈希法!
二、有效的字母异位词
1. 有效的字母异位词
思路:
数组其实就是一个简单的哈希表,而且这道题目中字符串只有小写字符,那么就可以定义一个数组,来记录字符串里字符出现的次数。
需要定义一个多大的数组呢?定义一个叫做num的数组,大小为26就可以了,但是要初始化为0,因为字符a到字符z的ASCII是26位个连续的数值。
操作如下:
复杂度分析:
时间复杂度:O(n)
空间复杂度:O(1)
class Solution {public:bool isAnagram(string s, string t) {if(s.length() == t.length()){ // 只有s和t的长度一样,它们的字母异位词的有效性才有判断的必要int num[26] = {0}; // 因为a-z一共有26位,所以开一个26位的数组就行了,且需要初始化为0for(int i = 0; i < s.length(); i++){num[s[i] - 'a']++;}for(int i = 0; i < t.length(); i++){num[t[i] - 'a']--;}for(int i = 0; i < 26; i++){if(num[i] != 0){return false;}}return true;}return false;}};
2. 两个数组的交集
哈希集合
思路:
我一开始想到的是用哈希集合来做,因为我觉得要判断数组的交集,起码也要遍历一遍数组吧,所以最优的时间复杂度应该是O(n) 才对,然后因为使用了哈希集合,所以空间复杂度是O(n),n是数组的长度。
class Solution {public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {unordered_set<int> set1;vector<int> result; // 存储结果for(int i = 0; i < nums1.size(); i++){set1.insert(nums1[i]);}for(int i = 0; i < nums2.size(); i++){if(set1.count(nums2[i])){ // 如果 set1 中存在num2的元素,说明这个元素就num1和num2的交集set1.erase(nums2[i]); // 为了防止多次输出交集的元素,所以一旦判定某个元素是交集元素,就丢弃它result.push_back(nums2[i]);}}return result;}};
代码随想录中的思想和我大致一样,但是写法有一点不同,可以看一下
3. 两个数组的交集
但官方有另一种解法,我觉得很垃圾:
排序 + 双指针
思路:
如果两个数组是有序的,则可以使用双指针的方法得到两个数组的交集。
首先对两个数组进行排序,然后使用两个指针遍历两个数组。可以预见的是加入答案的数组的元素一定是递增的,为了保证加入元素的唯一性,我们需要额外记录变量 pre 表示上一次加入答案数组的元素。
初始时,两个指针分别指向两个数组的头部。每次比较两个指针指向的两个数组中的数组,如果两个数组不相等,则将指向较小的数组的指针右移一位。当至少有一个指针超出数组范围时,遍历结束。
class Solution {public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {sort(nums1.begin(), nums1.end());sort(nums2.begin(), nums2.end());int length1 = nums1.size(), length2 = nums2.size();int index1 = 0, index2 = 0;vector<int> intersection;while (index1 < length1 && index2 < length2) {int num1 = nums1[index1], num2 = nums2[index2];if (num1 == num2) {// 保证加入元素的唯一性if (!intersection.size() || num1 != intersection.back()) {intersection.push_back(num1);}index1++;index2++;} else if (num1 < num2) {index1++;} else {index2++;}}return intersection;}};
3. 快乐数
思路
这道题看上去貌似是一道数学题,其实并不是!
题目中说了会无限循环,那么也就是说求和的过程中,sum会重复出现,这对解题很重要!
当我们遇到了要快速判断一个元素是否出现在集合里的时候,就要考虑哈希法了。
所以这道题目使用哈希法来判断这个sum是否重复出现,如果重复了就是 return false,否则一直找到 sum 为 1 为止。
判断 sum 是否重复出现就可以使用 unordered_set。
但是我觉得随想录这里说的并不好理解,力扣官方解释比较有说服力
快乐数 - 用哈希集合检测循环(官方)
class Solution {public:// 时间复杂度O(n^2)int getSum(int n){int sum = 0;while(n > 0){int temp = n % 10;sum += temp * temp;n /= 10;}return sum;}bool isHappy(int n) {unordered_set<int> set;while(1){int num = getSum(n);if(num == 1){return true;}if(set.find(num) != set.end()){ // 如果find的值不为空,说明前面出现过了,表明陷入了循环return false;}else{set.insert(num);}n = num;}}};
4. 两数之和
class Solution{public:vector<int> twoSum(vector<int> nums, int target){unordered_map<int, int> map;for(int i = 0; i < nums.size(); i++){// 这里有个细节,一开始数组第一个下标肯定是不等于target的,所以第一次循环肯定不会return// 所以下面的map中的键值永远比nums[i]少一位,所以只需要判断target减去当前的元素的结果是否在map即可。auto iter = map.find(target - nums[i]);if(iter != map.end()){return {iter->first, i};}map.insert(pair<int, int>(num[i], i));}return {};}};
5. 四数相加 II
思路
这道题放在这里很妙,它需要一点思维的变通,上一道是两数相加,现在是四数相加,思想就是把四数相加化成两数相加,如何化解呢?就是把四个数分成两组,A、B组的和为一组,C、D组的和为一组。
步骤:
- 首先定义一个 unordered_map,key放 a 和 b 两数之和,value放 a 和 b 两数之和出现的次数。
- 遍历大 A 和 大 B 数组,统计两个数组元素之和,和出现的次数,放到 map 中。
- 定义 int 变量 count,用来统计 a+b+c+d = 0 出现的次数。
- 在遍历大C和大D数组,找到如果 0 - (c + d) 在map中出现过的话,就用count把 map 中 key 对应的 value 也就是出现次数统计出来。
- 最后返回统计值 count 就可以了。
复杂度分析:
- 时间复杂度O(n^2)
- 空间复杂度O(n^2)
class Solution {public:int fourSumCount(vector<int>& nums1, vector<int>& nums2, vector<int>& nums3, vector<int>& nums4) {unordered_map<int, int> twoSum_map; // key:a+b的值,value:a+b出现的次数// 遍历大A和大B的数组,统计两个数组元素之和,和出现的次数,放到map中for(int a : nums1){for(int b : nums2){twoSum_map[a + b]++; // a+b的和作为key,并记录它们出现的次数value}}int count = 0; // 记录元组a+b+c+d = 0的个数int target = 0; // 题目条件目标值0// 在遍历大C和大D数组,找到如果 0-(c+d)在map中出现过的话,就把map中key对应的value,也就是出现的次数统计出来for(int c : nums3){for(int d : nums4){int sum = c + d;if(twoSum_map.find(target - sum) != twoSum_map.end()){count += twoSum_map[target - sum]; // 这里很容易陷入一个误区,就是count++,然后twoSum_map[target-sum]--,这样是不对的} // 因为在后续的sum中,有可能再出现和当前的sum相等的值,如果把出现的次数减掉了,后面的元组数就加不到了。}}return count;}};
6. 赎金信
我的哈希解法:
class Solution {public:bool canConstruct(string ransomNote, string magazine) {unordered_map<char, int> magazine_map;for(int i = 0; i < magazine.size(); i++){magazine_map[magazine[i]]++; // 记录magazine各个字符出现的次数}for(int i = 0; i < ransomNote.size(); i++){auto iter = magazine_map.find(ransomNote[i]);if(iter != magazine_map.end() && magazine_map[ransomNote[i]] >= 0){magazine_map[ransomNote[i]]--;}if(iter == magazine_map.end() || magazine_map[ransomNote[i]] < 0){ // 如果在map中找不到ransomNote的元素或者map中元素出现的次数少于ransomNotereturn false;}}return true;}};
代码录的解法:
哈希解法
因为题目只有小写字母,那可以采用空间换取时间的哈希策略,用一个长度为26的数组来记录 magazine 里字母出现的次数。
然后再用 ransomNote 去验证这个数组是否包含了 ransomNote 所需要的所有字母。
依然是数组再哈希法中的应用。
一些同学可能想,用数组干啥,都用map完事了,其实在本题的情况下,使用map的空间消耗要比数组大一些的,因为map要维护红黑树或者哈希表,而且还要做哈希函数,是费事的!数据量大的话就能体现出来差别了。所以数组更加简单直接有效!
// 时间复杂度O(n)// 空间复杂度O(1)class Solution {public:bool canConstruct(string ransomNote, string magazine) {int record[26] = {0}; // 题目只有小写字符for(int i = 0; i < magazine.size(); i++){// magazine-'a'的值刚好是0-26,用来当作索引,magazine中字符出现的次数作为数组的值record[magazine[i] - 'a']++;}for(int i = 0; i < ransomNote.size(); i++){record[ransomNote[i] - 'a']--; // 遍历ransomNote,在record里对应的字符个数做--操作if(record[ransomNote[i] - 'a'] < 0){ // 如果小于0说明ransomNote里出现的字符,magazine没有return false;}}return true;}};
7. 三数之和
(1)哈希法
哈希法解这道题目我目前还搞不明白,回头再看,代码随想录 - 哈希表 - 8. 三数之和
(2)双指针
其实这道题目使用哈希法并不十分合适,因为在去重的操作中有很多细节需要注意,在面试中很难直接写出没有bug的代码。
而且使用哈希法在使用两层for循环的时候,能做的剪枝操作很有限,虽然时间复杂度是 O(n),也是可以在 leetCode 上通过,但是程序执行实际按依然比较长。
接下来演示双指针法:
拿这个nums数组来举例,首先将数组排序,然后有一层for循环,i从下标0的地方开始,同时定一个下标left 定义在i+1的位置上,定义下标right 在数组结尾的位置上。
依然还是在数组中找到 abc 使得a + b +c =0,我们这里相当于 a = nums[i] b = nums[left] c = nums[right]。
接下来如何移动left 和right呢, 如果nums[i] + nums[left] + nums[right] > 0 就说明 此时三数之和大了,因为数组是排序后了,所以right下标就应该向左移动,这样才能让三数之和小一些。
如果 nums[i] + nums[left] + nums[right] < 0 说明 此时 三数之和小了,left 就向右移动,才能让三数之和大一些,直到left与right相遇为止。
时间复杂度:$O(n^2)$。
class Solution{public:vector<vector<int>> threeSum(vector<int>& nums){// 先对数组进行排序,数组从小到大排序sort(nums.begin(), nums.end());vector<vector<int>> result; // 存放结果// 枚举afor(int a = 0; a < nums.size(); a++){if(nums[a] > 0){ // 如果nums[a]大于0,那么a+b+c=0,在后面肯定不存在return result;}if(a > 0 && nums[a] == nums[a - 1]){ // 需要和上一次枚举的数不同continue;}int c = nums.size() - 1; // c指向数组最后一个位置int target = 0 - nums[a]; // target = b + c// 枚举bfor(int b = a + 1; b < nums.size(); b++){ // b需要在a的下一个位置if(b > a + 1 && nums[b] == nums[b - 1]){ // 需要和桑一次枚举的数不同continue;}// 需要保证b的指针在c的指针的左侧while(c > b && nums[b] + nums[c] > target){ // 如果大于target,那么说明nums[c]偏大,需要左移c--;}if(b == c){ // 如果b==c,说明当前枚举b这一层已经不存在满足条件的了,退出当前循环break;}if(nums[b] + nums[c] == target){result.push_back({nums[a], nums[b], nums[c]});}}}return result;}};
8. 四数之和
18. 四数之和 - 力扣(LeetCode)
思路
本题的思路继承了上面的三树之和,也是通过双指针来求,不同点就是四数之和需要在外面再套一层for循环,但是本题不用再判断 nums[a] > 0 就退出循环了,因为这道题的目标值是不确定的target,所以不能再这样判断。
有一点需要注意:三数之和的时间复杂度是O(n^2),四数之和的时间复杂度是O(n^3),所以说,双指针的使用只能降低一个级别的复杂度,即将问题简化一个 O(n) 复杂度。
class Solution {public:vector<vector<int>> fourSum(vector<int>& nums, int target) {vector<vector<int>> result; // 存储最终结果sort(nums.begin(), nums.end()); // 先排序,顺序从小到大int length = nums.size();// 枚举afor(int a = 0; a < length; a++){// 枚举的数需要和上一次不相同if(a > 0 && nums[a] == nums[a - 1]){continue;}// 枚举bfor(int b = a + 1; b < length; b++){// 枚举的数需要和上一次不相同if(b > a + 1 && nums[b] == nums[b - 1]){continue;}int d = length - 1; // d指向数组的最后一个位置int sumCD = target - nums[a] - nums[b];// 枚举cfor(int c = b + 1; c < length; c++){// 枚举的数需要和上一次不同if(c > b + 1 && nums[c] == nums[c - 1]){continue;}// 保证d在c的右侧,如果nums[c]+nums[d] > sumCD,说明d偏大,需要左移while(d > c && nums[c] + nums[d] > sumCD){d--;}if(c == d){ // 如果c==d,说明当前枚举c这一循环已经没有满足a+b+c+d的条件,退出这层循环break;}if(nums[c] + nums[d] == sumCD){result.push_back({nums[a], nums[b], nums[c], nums[d]});}}}}return result;}};

若有收获,就点个赞吧
0 人点赞
