16、左子叶之和
计算给定二叉树的所有左叶子之和。
示例:
思路
首先要注意是判断左叶子,不是二叉树左侧节点,所以不要上来想着层序遍历。
因为题目中其实没有说清楚左叶子究竟是什么节点,那么我来给出左叶子的明确定义:如果左节点不为空,且左节点没有左右孩子,那么这个节点就是左叶子
大家思考一下如下图中二叉树,左叶子之和究竟是多少?
其实是0,因为这棵树根本没有左叶子!
那么判断当前节点是不是左叶子是无法判断的,必须要通过节点的父节点来判断其左孩子是不是左叶子。
如果该节点的左节点不为空,该节点的左节点的左节点为空,该节点的左节点的右节点为空,则找到了一个左叶子。
递归法
整体代码如下:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution{public:int sumOfLeftLeaves(TreeNode* root){if(root == nullptr) return 0;int leftValue = sumOfLeftLeaves(root->left); // 左int rightValue = sumOfLeftLeaves(root->right); // 右int midValue = 0; // 中if(root->left != NULL && root->left->left == NULL && root->right->left == NULL){midValue = root->left->val;}int sum = midValue + leftValue + rightValue;return sum;}};
我自己写的递归
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:int getLeft(TreeNode* node, int flag, int val, int& result){if(flag == 1 && node->left == nullptr && node->right == nullptr){result += val;}if(node->left) getLeft(node->left, 1, node->left->val, result);if(node->right) getLeft(node->right, 0, node->right->val, result);return result;}int sumOfLeftLeaves(TreeNode* root) {if(root == nullptr) return 0;int flag = 0; // 标志位,如果当前是左节点,flag = 1,否则为0int result = 0;return getLeft(root, flag, root->val, result);}};
迭代法
class Solution {public:int sumOfLeftLeaves(TreeNode* root) {stack<TreeNode*> st;if (root == NULL) return 0;st.push(root);int result = 0;while (!st.empty()) {TreeNode* node = st.top();st.pop();if (node->left != NULL && node->left->left == NULL && node->left->right == NULL) {result += node->left->val;}if (node->right) st.push(node->right);if (node->left) st.push(node->left);}return result;}};
17、找树左下角的值
具体的解析看代码随想录,我这里就不copy了。代码随想录 - 二叉树 - 17、找树左下角的值
递归法:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*//*思路:使用递归的思想,当遇到叶子节点的时候,需要判断是否需要更新最大深度和最左边的值*/class Solution {public:int curDepth = INT_MIN; // 当前节点的深度int maxLeftValue = 0;void traversal(TreeNode* node, int leftLen){if(node->left == nullptr && node->right == nullptr){if(leftLen > curDepth){curDepth = leftLen;maxLeftValue = node->val;}return;}if(node->left) traversal(node->left, leftLen + 1);if(node->right) traversal(node->right, leftLen + 1);return;}int findBottomLeftValue(TreeNode* root) {traversal(root, 1); // 本来这里是traversal(root, 0)的,但是力扣默认1个节点就是1个深度,所以用1比较符合规范,但在这道题其实都不影响return maxLeftValue;}};
迭代法:
class Solution {public:int findBottomLeftValue(TreeNode* root) {queue<TreeNode*> que;if (root != NULL) que.push(root);int result = 0;while (!que.empty()) {int size = que.size();for (int i = 0; i < size; i++) {TreeNode* node = que.front();que.pop();if (i == 0) result = node->val; // 记录最后一行第一个元素 (注意!我就是这里没想到才导致多写了很多代码)if (node->left) que.push(node->left);if (node->right) que.push(node->right);}}return result;}};
看了卡尔的代码,再看我的简直就是垃圾
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*//*思路:用层序遍历取最后一层的第一个节点,就是我们要的最底层的最左边节点*/class Solution {public:int getDepth(TreeNode* root, int& depth){queue<TreeNode*> que;que.push(root);while(!que.empty()){int size = que.size();for(int i = 0; i < size; i++){TreeNode* node = que.front();que.pop();if(node->left) que.push(node->left);if(node->right) que.push(node->right);}depth++;}return depth;}int findBottomLeftValue(TreeNode* root) {int depth = 0; // 二叉树深度depth = getDepth(root, depth);queue<TreeNode*> que;int preDepth = 0; // 倒数第二层int result = 0;que.push(root);while(!que.empty()){int size = que.size();for(int i = 0; i < size; i++){TreeNode* node = que.front();que.pop();if(node->left) que.push(node->left);if(node->right) que.push(node->right);if(preDepth == depth - 1){ // 如果当前是最底层,那么preDepth == depth - 1result = node->val;break;}}preDepth++;}return result;}};
18、路径总和
18.1、路径总和
递归:
可以使用深度优先遍历的方式(本题前中后序都可以,无所谓,因为中节点也没有处理逻辑)来遍历二叉树
- 确定递归函数的参数和返回类型
参数:需要二叉树的根节点,还需要一个计数器,这个计数器用来计算二叉树的一条边之和是否正好是目标和,计数器为int型。
再来看返回值,递归函数什么时候需要返回值?什么时候不需要返回值?这里总结如下三点:
- 如果需要搜索整棵二叉树且不用处理递归返回值,递归函数就不要返回值。(这种情况就是本文下半部分介绍的113.路径总和ii)
- 如果需要搜索整棵二叉树且需要处理递归返回值,递归函数就需要返回值。 (这种情况我们在236. 二叉树的最近公共祖先(opens new window)中介绍)
- 如果要搜索其中一条符合条件的路径,那么递归一定需要返回值,因为遇到符合条件的路径了就要及时返回。(本题的情况)
而本题我们要找一条符合条件的路径,所以递归函数需要返回值,及时返回,那么返回类型是什么呢?
如图所示: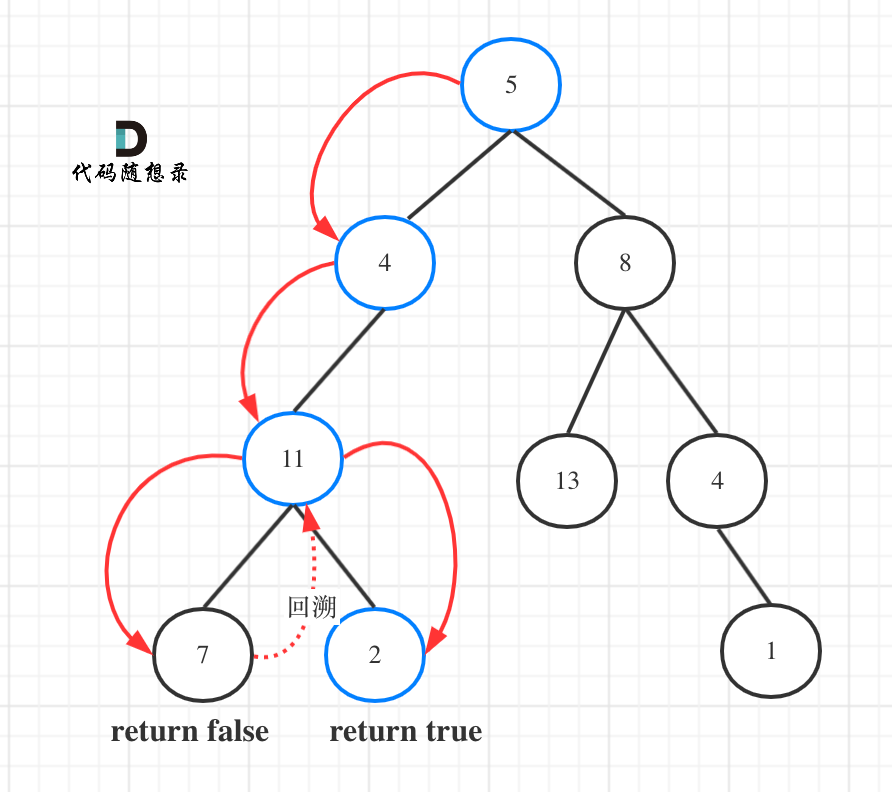
图中可以看出,遍历的路线,并不要遍历整棵树,所以递归函数需要返回值,可以用bool类型表示。
所以代码如下:
bool traversal(TreeNode* cur, int count); // 注意函数的返回类型
- 确定终止条件
首先计数器如何统计这一条路径的和呢?
不要去累加然后判断是否等于目标和,那么代码比较麻烦,可以用递减,让计数器count初始为目标和,然后每次减去遍历路径节点上的数值。
如果最后count == 0,同时到了叶子节点的话,说明找到了目标和。
如果遍历到了叶子节点,count不为0,就是没找到。
递归终止条件代码如下:
if(!cur->left && !cur->right && count == 0) return true; // 遇到叶子节点,并且计数为0if(!cur->left && !cur->right) return false; // 遇到叶子节点而没有找到合适的边,直接返回
- 确定单层递归的逻辑
因为终止条件是判断叶子节点,所以递归的过程中就不要让空节点进入递归了。
递归函数是有返回值的,如果递归函数返回true,说明找到了合适的路径,应该立刻返回。
代码如下:
if(cur->left){ // 左(空节点不遍历)// 遇到叶子节点返回true,则直接返回trueif(traversal(cur->left, count - cur->left->val)) return true; // 注意这里有回溯的逻辑}if(cur->right){ // 右(空节点不遍历)// 遇到叶子节点返回true,则直接返回trueif(traversal(cur->right, count - cur->right->val)) return true; // 注意这里有回溯的逻辑}return false;
以上代码中是包含着回溯的,没有回溯,如何后撤重新找另一条路径呢。
回溯隐藏在traversal(cur->left, count - cur->left->val)这里, 因为把count - cur->left->val 直接作为参数传进去,函数结束,count的数值没有改变。
整体代码如下:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution{public:bool traversal(TreeNode* cur, int count){if(!cur->left && !cur->right && count == 0) return true;if(!cur->left && !cur->right) return false;if(cur->left){if(traversal(cur->left, count - cur->left->val)) return true;}if(cur->right){if(traversal(cur->right, count - cur->right->val)) return true;}return false;}bool hasPathSum(TreeNode* root, int sum){if(root == nullptr) return false;return traversal(root, sum - root->val);}};
而我写的垃圾回溯,其实需要遍历整棵树,效率太低了
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:int sumPath = 0; // 根节点到叶子节点的路径的和int flag = 0; // 作为判断是否存在根节点到叶子节点的路径,1表示存在,0表示不存在int traversal(TreeNode* node, int targetSum){if(node == nullptr) return 0;if(node->left == nullptr && node->right == nullptr){sumPath += node->val;if(sumPath == targetSum) flag = 1;return sumPath;}sumPath += node->val;if(node->left){traversal(node->left, targetSum);sumPath -= node->left->val;}if(node->right){traversal(node->right, targetSum);sumPath -= node->right->val;}return sumPath;}bool hasPathSum(TreeNode* root, int targetSum) {traversal(root, targetSum);return flag;}};
递归:
如果使用栈模拟递归的话,那么如何做到回溯呢?
此时栈里一个元素不仅要记录该节点指针,还要记录从头结点到该节点的路径数值总和。
c++就我们用pair结构来存放这个栈里的元素。
定义为:pair
这个为栈里的一个元素。
如下代码是使用栈模拟的前序遍历,如下:(详细注释)
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution{public:bool hasPathSum(TreeNode* root, int targetSum){if(root == nullptr) return false;stack<pair<TreeNode*, int>> st;st.push(pair<TreeNode*, int>(root, root->val));while(!st.empty()){pair<TreeNode*, int> node = st.top();st.pop();// 如果该节点是叶子节点了,同时该节点的路径数量等于targetSum,就返回trueif(!node.first->left && !node.first->right && targetSum == node.second){return true;}// 右节点,压进去一个节点的时候,将该节点的路径数值也记录下来if(node.first->right){st.push(pair<TreeNode*, int>(node.first->right, node.second + node.first->right->val));}// 左节点,她进去一个节点的时候,将该节点的路径值也记录下来if(node.first->left){st.push(pair<TreeNode*, int>(node.first->left, node.second + node.first->left->val));}}return false;}};
18.2、路径总和II
递归法
by jungle
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:vector<vector<int>> allPath;void traversal(TreeNode* node, int targetSum, vector<int> curPath, bool isRoot){// 如果是头节点,需要将头节点pushif(isRoot) curPath.push_back(node->val);isRoot = false;// 如果是叶子节点且targetSum == 0,满足条件if(!node->left && !node->right && targetSum == 0){allPath.push_back(curPath);return;}if(node->left){curPath.push_back(node->left->val);traversal(node->left, targetSum - node->left->val, curPath, isRoot);curPath.pop_back();}if(node->right){curPath.push_back(node->right->val);traversal(node->right, targetSum - node->right->val, curPath, isRoot);curPath.pop_back();}return;}vector<vector<int>> pathSum(TreeNode* root, int targetSum) {if(root == nullptr) return allPath;vector<int> curPath;bool isRoot = true;traversal(root, targetSum - root->val, curPath, isRoot);return allPath;}};
能用递归肯定也是能用迭代法的,只是这道题用迭代法比较麻烦,也没有必要,使用递归深度回溯,更加符合这道题的解题逻辑。
19、构造二叉树
19.1、从中序与后序遍历序列构造二叉树
思路
首先回忆一下如何根据两个顺序构造一个唯一的二叉树,相信理论知识大家应该都清楚,就是以 后序数组的最后一个元素为切割点,先切中序数组,根据中序数组,反过来在切后序数组。一层一层切下去,每次后序数组最后一个元素就是节点元素。
为什么可以这样呢?
- 因为后序数组最后一个元素肯定就是根节点元素,我们只需要在中序数组中找到与这个根节点相同的元素,这个元素就是中序数组的根节点,
- 由中序遍历的特性可知,数组的存放形式是这样的:
[左子树,根节点,右子树],且此时左子树的长度肯定等于后序遍历中左子树的长度,即 [ 8, 9, 6] —> [ 8, 6, 9],右子树也是如此。 - 递归步骤1和2。
如果让我们肉眼看两个序列,画一棵二叉树的话,应该分分钟都可以画出来。
流程如图: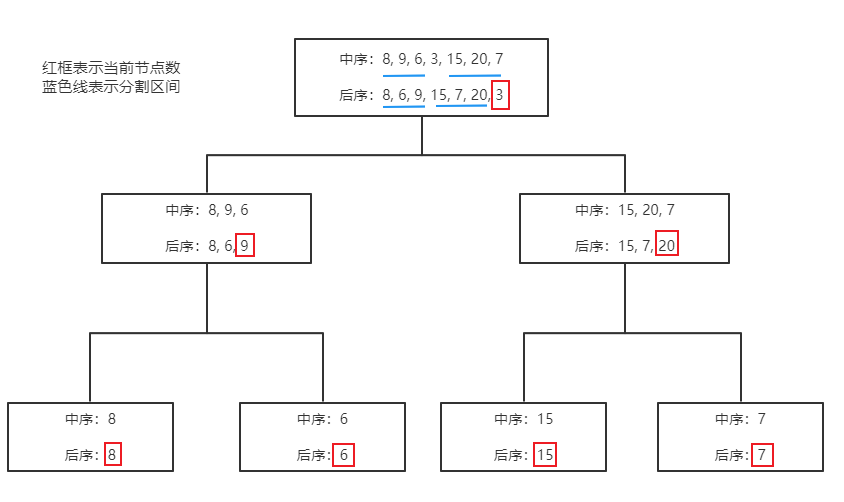
那么代码应该怎么写呢?
说到一层一层切割,就应该想到了递归。
来看一下一共分几步:
- 第一步:如果数组大小为零的话,说明是空节点了。
- 第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
- 第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
- 第四步:切割中序数组,切成中序左数组和中序右数组 (顺序别搞反了,一定是先切中序数组)
- 第五步:切割后序数组,切成后序左数组和后序右数组
- 第六步:递归处理左区间和右区间
不难写出如下代码:(先把框架写出来)
TreeNode* traversal (vector<int>& inorder, vector<int>& postorder) {// 第一步if (postorder.size() == 0) return NULL;// 第二步:后序遍历数组最后一个元素,就是当前的中间节点int rootValue = postorder[postorder.size() - 1];TreeNode* root = new TreeNode(rootValue);// 叶子节点if (postorder.size() == 1) return root;// 第三步:找切割点int delimiterIndex;for (delimiterIndex = 0; delimiterIndex < inorder.size(); delimiterIndex++) {if (inorder[delimiterIndex] == rootValue) break;}// 第四步:切割中序数组,得到 中序左数组和中序右数组// 第五步:切割后序数组,得到 后序左数组和后序右数组// 第六步root->left = traversal(中序左数组, 后序左数组);root->right = traversal(中序右数组, 后序右数组);return root;}
难点大家应该发现了,就是如何切割,以及边界值找不好很容易乱套。
此时应该注意确定切割的标准,是左闭右开,还有左开又闭,还是左闭又闭,这个就是不变量,要在递归中保持这个不变量。
在切割的过程中会产生四个区间,把握不好不变量的话,一会左闭右开,一会左闭又闭,必然乱套!
我在数组:每次遇到二分法,都是一看就会,一写就废(opens new window)和数组:这个循环可以转懵很多人!(opens new window)中都强调过循环不变量的重要性,在二分查找以及螺旋矩阵的求解中,坚持循环不变量非常重要,本题也是。
首先要切割中序数组,为什么先切割中序数组呢?
切割点在后序数组的最后一个元素,就是用这个元素来切割中序数组的,所以必要先切割中序数组。
中序数组相对比较好切,找到切割点(后序数组的最后一个元素)在中序数组的位置,然后切割,如下代码中我坚持左闭右开的原则:
// 找到中序遍历的切割点int delimiterIndex;for (delimiterIndex = 0; delimiterIndex < inorder.size(); delimiterIndex++) {if (inorder[delimiterIndex] == rootValue) break;}// 左闭右开区间:[0, delimiterIndex)vector<int> leftInorder(inorder.begin(), inorder.begin() + delimiterIndex);// [delimiterIndex + 1, end)vector<int> rightInorder(inorder.begin() + delimiterIndex + 1, inorder.end() );
接下来就要切割后序数组了。
首先后序数组的最后一个元素指定不能要了,这是切割点 也是 当前二叉树中间节点的元素,已经用了。
后序数组的切割点怎么找?
后序数组没有明确的切割元素来进行左右切割,不像中序数组有明确的切割点,切割点左右分开就可以了。
此时有一个很重的点,就是中序数组大小一定是和后序数组的大小相同的(这是必然)。
中序数组我们都切成了左中序数组和右中序数组了,那么后序数组就可以按照左中序数组的大小来切割,切成左后序数组和右后序数组。
代码如下:
// postorder 舍弃末尾元素,因为这个元素就是中间节点,已经用过了postorder.resize(postorder.size() - 1);// 左闭右开,注意这里使用了左中序数组大小作为切割点:[0, leftInorder.size)vector<int> leftPostorder(postorder.begin(), postorder.begin() + leftInorder.size());// [leftInorder.size(), end)vector<int> rightPostorder(postorder.begin() + leftInorder.size(), postorder.end());
此时,中序数组切成了左中序数组和右中序数组,后序数组切割成左后序数组和右后序数组。
接下来可以递归了,代码如下:
root->left = traversal(leftInorder, leftPostorder);root->right = traversal(rightInorder, rightPostorder);
完整代码如下:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:TreeNode* traversal(vector<int>& inorder, vector<int>& postorder) {// 第一步,如果数组大小为0的话,说明是空节点了if(postorder.size() == 0) return nullptr;// 第二步,如果不为空,那么取后序数组最后一个元素作为节点元素int rootVal = postorder[postorder.size() - 1];TreeNode* root = new TreeNode(rootVal);// 叶子节点if(postorder.size() == 1) return root;// 第三步,找到后序数组最后一个元素在中序数组的位置,作为切割点int delimiterIndex = 0; // 切割点的索引for(delimiterIndex; delimiterIndex < inorder.size(); delimiterIndex++){if(inorder[delimiterIndex] == rootVal){break;}}// 第四步,切割中序数组,切成中序左数组和中序右数组(顺序别搞反了,一定是先切中序数组)// 左闭右开区间vector<int> leftInorder(inorder.begin(), inorder.begin() + delimiterIndex); // [0, delimiterIndex)vector<int> rightInorder(inorder.begin() + delimiterIndex + 1, inorder.end()); // [delimiterIndex + 1, end)// 第五步,切割后序数组,切成后序左数组和后序右数组postorder.resize(postorder.size() - 1);vector<int> leftPostorder(postorder.begin(), postorder.begin() + leftInorder.size()); // [0, inorder.size())vector<int> rightpostorder(postorder.begin() + leftInorder.size(), postorder.end()); // [inorder.size(), end)// 第六步,递归处理左区间和右区间root->left = buildTree(leftInorder, leftPostorder);root->right = buildTree(rightInorder, rightpostorder);return root;}TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder){if (inorder.size() == 0 || postorder.size() == 0) return nullptr;return traversal(inorder, postorder);}};
此时应该发现了,如上的代码性能并不好,应为每层递归定定义了新的vector(就是数组),既耗时又耗空间,但上面的代码是最好理解的,为了方便读者理解,所以用如上的代码来讲解。
下面给出用下标索引写出的代码版本:(思路是一样的,只不过不用重复定义vector了,每次用下标索引来分割,因为我们并没有去改动 vector
C++优化版本:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:// 中序区间:[inorderBegin, inorderEnd), 后序区间: [postorderBegin, postorderEnd)TreeNode* traversal(vector<int>& inorder, int inorderBegin, int inorderEnd, vector<int>& postorder, int postorderBegin, int postorderEnd) {// 第一步,如果数组大小为0的话,说明是空节点了if(postorderBegin == postorderEnd) return nullptr;// 第二步, 如果不为空,那么取后序数组最后一个元素作为节点元素int rootValue = postorder[postorderEnd - 1];TreeNode* root = new TreeNode(rootValue);if(postorderEnd - postorderBegin == 1) return root;// 第三步, 确定分割点int delimiterIndex = 0;for(delimiterIndex; delimiterIndex < inorderEnd; delimiterIndex++){if(inorder[delimiterIndex] == rootValue) break;}// 第四步, 切割中序数组// 左中序区间,左闭右开 [leftInorderBegin, leftInorderEnd)int leftInorderBegin = inorderBegin;int leftInorderEnd = delimiterIndex;// 右中序区间,左闭右开 [rightInorderBegin, rightInorderEnd)int rightInorderBegin = delimiterIndex + 1;int rightInorderEnd = inorderEnd;// 第五步,切割后序数组// 左后序区间,左闭右开[leftPostorderBegin, leftPostorderEnd)int leftPostorderBegin = postorderBegin;int leftPostorderEnd = postorderBegin + (delimiterIndex - inorderBegin);// 右后序区间,左闭右开[rightPostorderBegin, rightPostorderEnd)int rightPostorderBegin = postorderBegin + (delimiterIndex - inorderBegin);int rightPostorderEnd = postorderEnd - 1;// 第六步,递归操作root->left = traversal(inorder, leftInorderBegin, leftInorderEnd, postorder, leftPostorderBegin, leftPostorderEnd);root->right = traversal(inorder, rightInorderBegin, rightInorderEnd, postorder, rightPostorderBegin, rightPostorderEnd);return root;}TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder){if (inorder.size() == 0 || postorder.size() == 0) return nullptr;return traversal(inorder, 0, inorder.size(), postorder, 0, postorder.size());}};
19.2、从前序与中序遍历序列构造二叉树
105. 从前序与中序遍历序列中构造二叉树 - 力扣(LeetCode)
本题和106是一样的道理。
我就直接给出代码了。
带日志的版本C++代码如下: (带日志的版本仅用于调试,不要在leetcode上提交,会超时)
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:TreeNode* tarversal(vector<int>& preorder, int preorderBegin, int preorderEnd, vector<int>& inorder, int inorderBegin, int inorderEnd){// 第一步,如果数组大小为空,说明是空节点了if(preorderBegin == preorderEnd) return nullptr;// 第二步,找到前序中的根节点int rootValue = preorder[preorderBegin]; // 注意用preorderBegin 不要用0TreeNode* root = new TreeNode(rootValue);// 如果是叶子节点if(preorderEnd - preorderBegin == 1) return root;// 第三步,找到中序数组中的当前根节点,即分割点int delimiterIndex = inorderBegin;for(delimiterIndex; delimiterIndex < inorderEnd; delimiterIndex++){if(inorder[delimiterIndex] == rootValue) break;}// 第四步,切割中序数组// 左中序区间,左闭右开 [leftInorderBegin, leftInorderEnd)int leftInorderBegin = inorderBegin;int leftInorderEnd = delimiterIndex;// 右中序区间,左闭右开 [)int rightInorderBegin = delimiterIndex + 1;int rightInorderEnd = inorderEnd;// 第五步,切割前序数组// 左前序区间,左闭右开 [)int leftPreorderBegin = preorderBegin + 1;int leftPreorderEnd = preorderBegin + 1 + (delimiterIndex - inorderBegin);// 右前序区间,左闭右开 [)int rightPreorderBegin = leftPreorderEnd;int rightPreorderEnd = preorderEnd;// ------------------日志调试--------------------cout << "----------" << endl;cout << "leftInorder :";for (int i = leftInorderBegin; i < leftInorderEnd; i++) {cout << inorder[i] << " ";}cout << endl;cout << "rightInorder :";for (int i = rightInorderBegin; i < rightInorderEnd; i++) {cout << inorder[i] << " ";}cout << endl;cout << "leftPreorder :";for (int i = leftPreorderBegin; i < leftPreorderEnd; i++) {cout << preorder[i] << " ";}cout << endl;cout << "rightPreorder :";for (int i = rightPreorderBegin; i < rightPreorderEnd; i++) {cout << preorder[i] << " ";}cout << endl;// ------------------日志调试--------------------// 第六步,递归处理root->left = tarversal(preorder, leftPreorderBegin, leftPreorderEnd, inorder, leftInorderBegin, leftInorderEnd);root->right = tarversal(preorder, rightPreorderBegin, rightPreorderEnd, inorder, rightInorderBegin, rightInorderEnd);return root;}TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {if(preorder.size() == 0 || inorder.size() == 0) return nullptr;return tarversal(preorder, 0, preorder.size(), inorder, 0, inorder.size());}};
20、最大二叉树
思路:
这道题目其实和 二叉树:构造二叉树登场!(opens new window)是一个思路,比二叉树:构造二叉树登场!(opens new window)还简单一些。
注意类似用数组构造二叉树的题目,每次分隔尽量不要定义新的数组,而是通过下标索引直接在原数组上操作,这样可以节约时间和空间上的开销。
一些同学也会疑惑,什么时候递归函数前面加if,什么时候不加if,这个问题我在最后也给出了解释。
其实就是不同代码风格的实现,一般情况来说:如果让空节点(空指针)进入递归,就不加if,如果不让空节点进入递归,就加if限制一下, 终止条件也会相应的调整。
代码优化前:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:TreeNode* traversal(vector<int> nums){// 1.如果数组大小为0,说明数组为空if(nums.size() == 0) return nullptr;// 2. 获取根节点和数组分割点int rootVal = INT_MIN; // 数组中的最大值即为根节点的值int delimiterIndex = 0; // 当前根节点对应的索引,作为数组的分割点for(int i = 0; i < nums.size(); i++){if(nums[i] > rootVal){rootVal = nums[i];delimiterIndex = i;}}TreeNode* root = new TreeNode(rootVal);// 3.将数组分割成左子树区域和右子树区域,区间遵循左闭右开原则vector<int> leftNums(nums.begin(), nums.begin() + delimiterIndex);vector<int> rightNums(nums.begin() + delimiterIndex + 1, nums.end());// 4.递归处理root->left = traversal(leftNums);root->right = traversal(rightNums);return root;}TreeNode* constructMaximumBinaryTree(vector<int>& nums) {if(nums.size() == 0) return nullptr;return traversal(nums);}};
代码优化后:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:TreeNode* traversal(vector<int>& nums, int begin, int end){// 1.如果begin >= end 说明这个nums为空(其实==就可以判断了,但是为了程序的健壮性,还是用>=)if(begin >= end) return nullptr;// 2. 获取根节点和数组分割点int delimiterIndex = begin; // 当前根节点对应的索引,作为数组的分割点for(int i = begin + 1; i < end; i++){if(nums[i] > nums[delimiterIndex]){delimiterIndex = i;}}TreeNode* root = new TreeNode(nums[delimiterIndex]);// 3.将数组分割成左子树区域和右子树区域,区间遵循左闭右开原则// 左子树区间int leftBegin = begin;int leftEnd = begin + (delimiterIndex - begin);// 右子树区间int rightBegin = begin + 1 + (delimiterIndex - begin);int rightEnd = end;// 4.递归处理root->left = traversal(nums, leftBegin, leftEnd);root->right = traversal(nums, rightBegin, rightEnd);return root;}TreeNode* constructMaximumBinaryTree(vector<int>& nums) {return traversal(nums, 0, nums.size());}};
21、二叉树周末总结
本周小结!(二叉树系列三)
周一
在二叉树:以为使用了递归,其实还隐藏着回溯(opens new window)中,通过leetcode 257.二叉树的所有路径这道题目(opens new window),讲解了递归如何隐藏着回溯,一些代码会把回溯的过程都隐藏了起来了,甚至刷过这道题的同学可能都不知道自己用了回溯。
文章中第一版代码把每一个细节都展示了输出来了,大家可以清晰的看到回溯的过程。
然后给出了第二版优化后的代码,分析了其回溯隐藏在了哪里,如果要把这个回溯扣出来的话,在第二版的基础上应该怎么改。
主要需要理解:回溯隐藏在traversal(cur->left, path + “->”, result);中的 path + “->”。 每次函数调用完,path依然是没有加上”->” 的,这就是回溯了。
周二
在文章二叉树:做了这么多题目了,我的左叶子之和是多少?(opens new window)中提供了另一个判断节点属性的思路,平时我们习惯了使用通过节点的左右孩子判断本节点的属性,但发现使用这个思路无法判断左叶子。
此时需要相连的三层之间构成的约束条件,也就是要通过节点的父节点以及孩子节点来判断本节点的属性。
这道题目可以扩展大家对二叉树的解题思路。
周三
在二叉树:我的左下角的值是多少?(opens new window)中的题目如果使用递归的写法还是有点难度的,层次遍历反而很简单。
题目其实就是要在树的最后一行找到最左边的值。
如何判断是最后一行呢,其实就是深度最大的叶子节点一定是最后一行。
在这篇文章中,我们使用递归算法实实在在的求了一次深度,然后使用靠左的遍历,保证求得靠左的最大深度,而且又一次使用了回溯。
如果对二叉树的高度与深度又有点模糊了,在看这里二叉树:我平衡么?(opens new window),回忆一下吧。
二叉树:我的左下角的值是多少?(opens new window)中把我们之前讲过的内容都过了一遍,此外,还用前序遍历的技巧求得了靠左的最大深度。
求二叉树的各种最值,就想应该采用什么样的遍历顺序,确定了遍历循序,其实就和数组求最值一样容易了。
周四
在二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?(opens new window)中通过两道题目,彻底说清楚递归函数的返回值问题。
一般情况下:如果需要搜索整棵二叉树,那么递归函数就不要返回值,如果要搜索其中一条符合条件的路径,递归函数就需要返回值,因为遇到符合条件的路径了就要及时返回。
特别是有些时候 递归函数的返回值是bool类型,一些同学会疑惑为啥要加这个,其实就是为了找到一条边立刻返回。
其实还有一种就是后序遍历需要根据左右递归的返回值推出中间节点的状态,这种需要有返回值,例如222.完全二叉树(opens new window),110.平衡二叉树(opens new window),这几道我们之前也讲过。
周五
之前都是讲解遍历二叉树,这次该构造二叉树了,在二叉树:构造二叉树登场!(opens new window)中,我们通过前序和中序,后序和中序,构造了唯一的一棵二叉树。
构造二叉树有三个注意的点:
- 分割时候,坚持区间不变量原则,左闭右开,或者左闭又闭。
- 分割的时候,注意后序 或者 前序已经有一个节点作为中间节点了,不能继续使用了。
- 如何使用切割后的后序数组来切合中序数组?利用中序数组大小一定是和后序数组的大小相同这一特点来进行切割。
这道题目代码实现并不简单,大家啃下来之后,二叉树的构造应该不是问题了。
最后我还给出了为什么前序和后序不能唯一构成一棵二叉树,因为没有中序遍历就无法确定左右部分,也就无法分割。
周六
知道了如何构造二叉树,那么使用一个套路就可以解决文章二叉树:构造一棵最大的二叉树(opens new window)中的问题。
注意类似用数组构造二叉树的题目,每次分隔尽量不要定义新的数组,而是通过下标索引直接在原数组上操作,这样可以节约时间和空间上的开销。
文章中我还给出了递归函数什么时候加if,什么时候不加if,其实就是控制空节点(空指针)是否进入递归,是不同的代码实现方式,都是可以的。
一般情况来说:如果让空节点(空指针)进入递归,就不加if,如果不让空节点进入递归,就加if限制一下, 终止条件也会相应的调整。
总结
本周我们深度讲解了如下知识点:
- 递归中如何隐藏着回溯(opens new window)
- 如何通过三层关系确定左叶子(opens new window)
- 如何通过二叉树深度来判断左下角的值(opens new window)
- 递归函数究竟什么时候需要返回值,什么时候不要返回值?(opens new window)
- 前序和中序,后序和中序构造唯一二叉树(opens new window)
- 使用数组构造某一特性的二叉树
22、合并二叉树
617. 合并二叉树 - 力扣(LeetCode)
太懒了,不写思路了,具体看:代码随想录 - 二叉树 - 22. 合并二叉树
递归法:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:TreeNode* combine(TreeNode* root1, TreeNode* root2){// 递归出口if(root1 == nullptr) return root2;if(root2 == nullptr) return root1;// 单层递归逻辑if(root1 != nullptr && root2 != nullptr) root1->val = root1->val + root2->val;root1->left = combine(root1->left, root2->left);root1->right = combine(root1->right, root2->right);return root1;}TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {return combine(root1, root2);}};
迭代法:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:// 迭代法:使用前序遍历TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {if(root1 == nullptr) return root2;if(root2 == nullptr) return root1;queue<TreeNode*> que;que.push(root1);que.push(root2);while(!que.empty()){TreeNode* node1 = que.front(); que.pop();TreeNode* node2 = que.front(); que.pop();// 此时queRoot1和queRoot2一定不为空node1->val = node1->val + node2->val;// 如果node1->left和node2->left都不为空,那么一起入队if(node1->left && node2->left){que.push(node1->left);que.push(node2->left);}// 如果node1->right和node2->right都不为空,那么一起入队if(node1->right && node2->right){que.push(node1->right);que.push(node2->right);}// 如果node1->left为空,node2->left不为空,将node2->right赋给node1->leftif(!node1->left && node2->left){node1->left = node2->left;}// 如果node1->right为空,node2->right不为空,将node2->right赋给node1->rightif(!node1->right && node2->right){node1->right = node2->right;}}return root1;}};
23、二叉搜索树中的搜索
思路
之前我们讲了都是普通二叉树,那么接下来看看二叉搜索树。
在关于二叉树,你该了解这些!(opens new window)中,我们已经讲过了二叉搜索树。
二叉搜索树是一个有序树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉搜索树
这就决定了,二叉搜索树,递归遍历和迭代遍历和普通二叉树都不一样。
本题,其实就是在二叉搜索树中搜索一个节点。那么我们来看看应该如何遍历。
递归法
- 确定递归函数的参数和返回值
递归函数的参数传入的就是根节点和要搜索的数值,返回的就是以这个搜索数值所在的节点。
代码如下:
TreeNode* searchBST(TreeNode* root, int val)
- 确定终止条件
如果root为空,或者找到这个数值了,就返回root节点。
if (root == NULL || root->val == val) return root;
- 确定单层递归的逻辑
看看二叉搜索树的单层递归逻辑有何不同。
因为二叉搜索树的节点是有序的,所以可以有方向的去搜索。
如果root->val > val,搜索左子树,如果root->val < val,就搜索右子树,最后如果都没有搜索到,就返回NULL。
代码如下:
if (root->val > val) return searchBST(root->left, val); // 注意这里加了returnif (root->val < val) return searchBST(root->right, val);return NULL;
这里可能会疑惑,在递归遍历的时候,什么时候直接return 递归函数的返回值,什么时候不用加这个 return呢。
我们在二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?(opens new window)中讲了,如果要搜索一条边,递归函数就要加返回值,这里也是一样的道理。
因为搜索到目标节点了,就要立即return了,这样才是找到节点就返回(搜索某一条边),如果不加return,就是遍历整棵树了。
整体代码如下:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:TreeNode* searchBST(TreeNode* root, int val) {if(root == nullptr || root->val == val) return root;if(root->val > val) return searchBST(root->left, val);if(root->val < val) return searchBST(root->right, val);return nullptr;}};
迭代法
一提到二叉树遍历的迭代法,可能立刻想起使用栈来模拟深度遍历,使用队列来模拟广度遍历。
对于二叉搜索树可就不一样了,因为二叉搜索树的特殊性,也就是节点的有序性,可以不使用辅助栈或者队列就可以写出迭代法。
对于一般二叉树,递归过程中还有回溯的过程,例如走一个左方向的分支走到头了,那么要调头,在走右分支。
而对于二叉搜索树,不需要回溯的过程,因为节点的有序性就帮我们确定了搜索的方向。
例如要搜索元素为3的节点,我们不需要搜索其他节点,也不需要做回溯,查找的路径已经规划好了。
中间节点如果大于3就向左走,如果小于3就向右走,如图: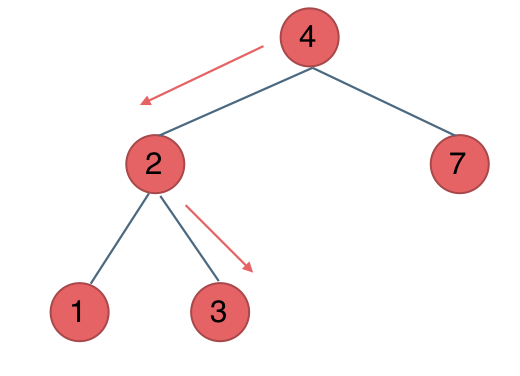
所以迭代法代码如下:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:TreeNode* searchBST(TreeNode* root, int val) {while(root != nullptr){if(root->val > val) root = root->left;else if(root->val < val) root = root->right;else return root;}return nullptr;}};
24、验证二叉搜索树
思路
要知道中序遍历下,输出的二叉搜索树节点的数值是有序序列。
有了这个特性,验证二叉搜索树,就相当于变成了判断一个序列是不是递增的了。
递归法
可以递归中序遍历将二叉搜索树转变成一个数组,代码如下:
vector<int> vec;void traversal(TreeNode* root) {if (root == NULL) return;traversal(root->left);vec.push_back(root->val); // 将二叉搜索树转换为有序数组traversal(root->right);}
然后只要比较一下,这个数组是否是有序的,注意二叉搜索树中不能有重复元素。
traversal(root);for (int i = 1; i < vec.size(); i++) {// 注意要小于等于,搜索树里不能有相同元素if (vec[i] <= vec[i - 1]) return false;}return true;
整体代码如下:
class Solution {private:vector<int> vec;void traversal(TreeNode* root) {if (root == NULL) return;traversal(root->left);vec.push_back(root->val); // 将二叉搜索树转换为有序数组traversal(root->right);}public:bool isValidBST(TreeNode* root) {vec.clear(); // 不加这句在leetcode上也可以过,但最好加上traversal(root);for (int i = 1; i < vec.size(); i++) {// 注意要小于等于,搜索树里不能有相同元素if (vec[i] <= vec[i - 1]) return false;}return true;}};
以上代码中,我们把二叉树转变为数组来判断,是最直观的,但其实不用转变成数组,可以在递归遍历的过程中直接判断是否有序。
这道题目比较容易陷入两个陷阱:
- 陷阱1
不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了。
写出了类似这样的代码:
if (root->val > root->left->val && root->val < root->right->val) {return true;} else {return false;}
我们要比较的是 左子树所有节点小于中间节点,右子树所有节点大于中间节点。所以以上代码的判断逻辑是错误的。
例如: [10,5,15,null,null,6,20] 这个case: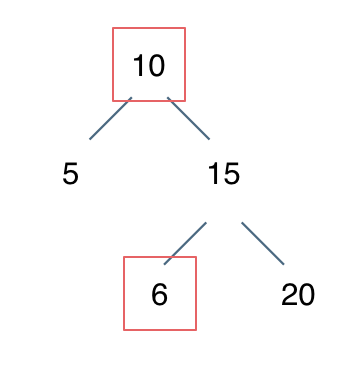
节点10大于左节点5,小于右节点15,但右子树里出现了一个6 这就不符合了!
- 陷阱2
样例中最小节点 可能是int的最小值,如果这样使用最小的int来比较也是不行的。
此时可以初始化比较元素为longlong的最小值。
问题可以进一步演进:如果样例中根节点的val 可能是longlong的最小值 又要怎么办呢?文中会解答。
了解这些陷阱之后我们来看一下代码应该怎么写:
递归三部曲:
- 确定递归函数,返回值以及参数
要定义一个longlong的全局变量,用来比较遍历的节点是否有序,因为后台测试数据中有int最小值,所以定义为longlong的类型,初始化为longlong最小值。
注意递归函数要有bool类型的返回值, 我们在二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?(opens new window)中讲了,只有寻找某一条边(或者一个节点)的时候,递归函数会有bool类型的返回值。
其实本题是同样的道理,我们在寻找一个不符合条件的节点,如果没有找到这个节点就遍历了整个树,如果找到不符合的节点了,立刻返回。
代码如下:
long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值bool isValidBST(TreeNode* root)
- 确定终止条件
如果是空节点 是不是二叉搜索树呢?
是的,二叉搜索树也可以为空!
代码如下:
if (root == NULL) return true;
- 确定单层递归的逻辑
中序遍历,一直更新maxVal,一旦发现maxVal >= root->val,就返回false,注意元素相同时候也要返回false。
代码如下:
bool left = isValidBST(root->left); // 左// 中序遍历,验证遍历的元素是不是从小到大if (maxVal < root->val) maxVal = root->val; // 中else return false;bool right = isValidBST(root->right); // 右return left && right;
整体代码如下:
class Solution {public:long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值bool isValidBST(TreeNode* root) {if (root == NULL) return true;bool left = isValidBST(root->left);// 中序遍历,验证遍历的元素是不是从小到大if (maxVal < root->val) maxVal = root->val;else return false;bool right = isValidBST(root->right);return left && right;}};
以上代码是因为后台数据有int最小值测试用例,所以都把maxVal改成了longlong最小值。
如果测试数据中有 longlong的最小值,怎么办?
不可能在初始化一个更小的值了吧。 建议避免 初始化最小值,如下方法取到最左面节点的数值来比较。
代码如下:
class Solution {public:TreeNode* pre = NULL; // 用来记录前一个节点bool isValidBST(TreeNode* root) {if (root == NULL) return true;bool left = isValidBST(root->left);if (pre != NULL && pre->val >= root->val) return false;pre = root; // 记录前一个节点bool right = isValidBST(root->right);return left && right;}};
最后这份代码看上去整洁一些,思路也清晰。
迭代法
可以用迭代法模拟二叉树中序遍历,对前中后序迭代法生疏的同学可以看这两篇二叉树:听说递归能做的,栈也能做!(opens new window),二叉树:前中后序迭代方式统一写法(opens new window)
迭代法中序遍历稍加改动就可以了,代码如下:
class Solution {public:bool isValidBST(TreeNode* root) {stack<TreeNode*> st;TreeNode* cur = root;TreeNode* pre = nullptr; // 记录前一个结点while(cur != nullptr || !st.empty()){if(cur != nullptr){st.push(cur);cur = cur->left; // 左}else{cur = st.top(); // 中st.pop();if(pre != nullptr && cur->val <= pre->val){return false;}pre = cur; // 保存前一个访问的节点cur = cur->right; // 右}}return true;}};
在二叉树:二叉搜索树登场!(opens new window)中我们分明写出了痛哭流涕的简洁迭代法,怎么在这里不行了呢,因为本题是要验证二叉搜索树啊。
总结
这道题目是一个简单题,但对于没接触过的同学还是有难度的。
所以初学者刚开始学习算法的时候,看到简单题目没有思路很正常,千万别怀疑自己智商,学习过程都是这样的,大家智商都差不多,哈哈。
只要把基本类型的题目都做过,总结过之后,思路自然就开阔了。
25、二叉搜索树的最小绝对差
530. 二叉搜索树的最小绝对差 - 力扣(LeetCode)
思路:
题目中要求再二叉搜索树上任意两个节点的差的绝对值的最小值。
注意是二叉搜索树,二叉搜索树是有序的。
遇到在二叉搜索树上求什么最值啊,差值之类的,就把它想成在一个有序数组上求最值,求差值,这样就简单多了。
领用辅助空间vector来解题的代码几乎和上面24题一模一样。所以直接上利用两个指针来求解。
递归法:
class Solution {private:int result = INT_MAX;TreeNode* pre;void traversal(TreeNode* cur) {if (cur == NULL) return;traversal(cur->left); // 左if (pre != NULL){ // 中result = min(result, cur->val - pre->val);}pre = cur; // 记录前一个traversal(cur->right); // 右}public:int getMinimumDifference(TreeNode* root) {traversal(root);return result;}};
迭代法:
class Solution {public:int getMinimumDifference(TreeNode* root) {stack<TreeNode*> st;TreeNode* cur = root;TreeNode* pre = NULL;int result = INT_MAX;while (cur != NULL || !st.empty()) {if (cur != NULL) { // 指针来访问节点,访问到最底层st.push(cur); // 将访问的节点放进栈cur = cur->left; // 左} else {cur = st.top();st.pop();if (pre != NULL) { // 中result = min(result, cur->val - pre->val);}pre = cur;cur = cur->right; // 右}}return result;}};
总结
遇到在二叉搜索树上求什么最值,求差值之类的,都要思考一下二叉搜索树可是有序的,要利用好这一特点。
同时要学会在递归遍历的过程中如何记录前后两个指针,这也是一个小技巧,学会了还是很受用的。
后面我将继续介绍一系列利用二叉搜索树特性的题目。
26、二叉搜索树中的众数
思路
这道题目呢,递归法我从两个维度来讲。
首先如果不是二叉搜索树的话,应该怎么解题,是二叉搜索树,又应该如何解题,两种方式做一个比较,可以加深大家对二叉树的理解。
递归法
如果不是二叉搜索树
如果不是二叉搜索树,最直观的方法一定是把这个树都遍历了,用map统计频率,把频率排个序,最后取前面高频的元素的集合。
具体步骤如下:
- 这个树都遍历了,用map统计频率
至于用前中后序那种遍历也不重要,因为就是要全遍历一遍,怎么个遍历法都行,层序遍历都没毛病!
这里采用前序遍历,代码如下:
// map<int, int> key:元素,value:出现频率void searchBST(TreeNode* cur, unordered_map<int, int>& map) { // 前序遍历if (cur == NULL) return ;map[cur->val]++; // 统计元素频率searchBST(cur->left, map);searchBST(cur->right, map);return ;}
- 把统计的出来的出现频率(即map中的value)排个序
有的同学可能可以想直接对map中的value排序,还真做不到,C++中如果使用std::map或者std::multimap可以对key排序,但不能对value排序。
所以要把map转化数组即vector,再进行排序,当然vector里面放的也是pair
bool static cmp (const pair<int, int>& a, const pair<int, int>& b) {return a.second > b.second; // 按照频率从大到小排序}vector<pair<int, int>> vec(map.begin(), map.end());sort(vec.begin(), vec.end(), cmp); // 给频率排个序
- 取前面高频的元素
此时数组vector中已经是存放着按照频率排好序的pair,那么把前面高频的元素取出来就可以了。
代码如下:
result.push_back(vec[0].first);for (int i = 1; i < vec.size(); i++) {// 取最高的放到result数组中if (vec[i].second == vec[0].second) result.push_back(vec[i].first);else break;}return result;
整体C++代码如下:
class Solution{private:// 前序遍历void searchBST(TreeNode* cur, unordered_map<int, int>& map){if(cur == nullptr) return;map[cur->val]++; // 统计元素频率searchBST(cur->left, map);searchBST(cur->right, map);return;}// 自定义比较函数bool static cmp(const pair<int, int>& a, const pair<int, int>& b){return a.second > b.second;}public:vector<int> findMode(TreeNode* root){unordered_map<int, int> map; // key: 元素,value:出现频率vector<int> result;if(root == nullptr) return result;searchBST(root, map);vector<pair<int, int>> vec(map.begin(), map.end());sort(vec.begin(), vec.end(), cmp); // 给频率排个序result.push_back(vec[0].first);for(int i = 1; i < vec.size(); i++){// 取出现频率最高的放入result数组中if(vec[i].second == vec[0].second){result.push_back(vec[i].first);}else break;}return result;}};
是二叉搜索树
既然是搜索树,它中序遍历就是有序的。
递归法
中序遍历代码如下:
void searchBST(TreeNode* cur) {if (cur == NULL) return ;searchBST(cur->left); // 左(处理节点) // 中searchBST(cur->right); // 右return ;}
遍历有序数组的元素出现频率,从头遍历,那么一定是相邻两个元素作比较,然后就把出现频率最高的元素输出就可以了。
关键是在有序数组上的话,好搞,在树上怎么搞呢?
这就考察对树的操作了。
在二叉树:搜索树的最小绝对差(opens new window)中我们就使用了pre指针和cur指针的技巧,这次又用上了。
弄一个指针指向前一个节点,这样每次cur(当前节点)才能和pre(前一个节点)作比较。
而且初始化的时候pre = NULL,这样当pre为NULL时候,我们就知道这是比较的第一个元素。
代码如下:
if (pre == NULL) { // 第一个节点count = 1; // 频率为1} else if (pre->val == cur->val) { // 与前一个节点数值相同count++;} else { // 与前一个节点数值不同count = 1;}pre = cur; // 更新上一个节点
此时又有问题了,因为要求最大频率的元素集合(注意是集合,不是一个元素,可以有多个众数),如果是数组上大家一般怎么办?
应该是先遍历一遍数组,找出最大频率(maxCount),然后再重新遍历一遍数组把出现频率为maxCount的元素放进集合。(因为众数有多个)
这种方式遍历了两遍数组。
那么我们遍历两遍二叉搜索树,把众数集合算出来也是可以的。
但这里其实只需要遍历一次就可以找到所有的众数。
那么如何只遍历一遍呢?
如果 频率count 等于 maxCount(最大频率),当然要把这个元素加入到结果集中(以下代码为result数组),代码如下:
if (count == maxCount) { // 如果和最大值相同,放进result中result.push_back(cur->val);}
是不是感觉这里有问题,result怎么能轻易就把元素放进去了呢,万一,这个maxCount此时还不是真正最大频率呢。
所以下面要做如下操作:
频率count 大于 maxCount的时候,不仅要更新maxCount,而且要清空结果集(以下代码为result数组),因为结果集之前的元素都失效了。
if (count > maxCount) { // 如果计数大于最大值maxCount = count; // 更新最大频率result.clear(); // 很关键的一步,不要忘记清空result,之前result里的元素都失效了result.push_back(cur->val);}
关键代码都讲完了,完整代码如下:(只需要遍历一遍二叉搜索树,就求出了众数的集合)
class Solution {private:int maxCount; // 最大频率int count; // 统计频率TreeNode* pre;vector<int> result;void searchBST(TreeNode* cur) {if (cur == NULL) return ;searchBST(cur->left); // 左// 中if (pre == NULL) { // 第一个节点count = 1;} else if (pre->val == cur->val) { // 与前一个节点数值相同count++;} else { // 与前一个节点数值不同count = 1;}pre = cur; // 更新上一个节点if (count == maxCount) { // 如果和最大值相同,放进result中result.push_back(cur->val);}if (count > maxCount) { // 如果计数大于最大值频率maxCount = count; // 更新最大频率result.clear(); // 很关键的一步,不要忘记清空result,之前result里的元素都失效了result.push_back(cur->val);}searchBST(cur->right); // 右return ;}public:vector<int> findMode(TreeNode* root) {count = 0;maxCount = 0;TreeNode* pre = NULL; // 记录前一个节点result.clear();searchBST(root);return result;}};
下面的递归法是我自己写的,大同小异
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:vector<int> vec;TreeNode* pre = nullptr;int curCount = 1; // 计算当前连续相等节点的个数int maxCount = INT_MIN; // 记录历史上连续相等节点的个数的最大值void traversal(TreeNode* root){if(root == nullptr) return;if(root->left) traversal(root->left); // 左// 中if(pre != nullptr && pre->val == root->val){curCount++;}// 如果相当的元素断开了,需要让curCount置1else if(pre != nullptr && pre->val != root->val){curCount = 1;}if(curCount == maxCount){vec.push_back(root->val);}// 如果当前连续相等的个数超过了maxCount,需要更新maxCount,并且要给root重新赋值// 此时不仅要更新maxCount,而且要清空结果集if(maxCount < curCount){maxCount = curCount;vec.clear(); // 很关键的一步,让之前存储的结果失效vec.push_back(root->val);}pre = root; // 记录前一个结点if(root->right) traversal(root->right); // 右}vector<int> findMode(TreeNode* root) {vec.clear(); // 不加不会错,加上更好traversal(root);return vec;}};
迭代法
只要把中序遍历转成迭代,中间节点的处理逻辑完全一样。
二叉树前中后序转迭代,传送门:
下面我给出其中的一种中序遍历的迭代法,其中间处理逻辑一点都没有变(我从递归法直接粘过来的代码,连注释都没改,哈哈)
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:vector<int> findMode(TreeNode* root) {stack<TreeNode*> st;vector<int> result; // 存储结果int curCount = 1; // 计算当前连续相等节点的个数int maxCount = INT_MIN; // 记录历史上连续相等节点的个数的最大值TreeNode* pre = nullptr;TreeNode* cur = root;while(cur != nullptr || !st.empty()){if(cur != nullptr){st.push(cur);cur = cur->left; // 左}else{cur = st.top(); // 中st.pop();// --------------单层逻辑判断-----------------------------------if(pre != nullptr && pre->val == cur->val){curCount++;}// 如果相等的元素断开了,curCount需要重新计数else if(pre != nullptr && pre->val != cur->val){curCount = 1;}if(maxCount == curCount){result.push_back(cur->val);}// 如果当前连续相等的个数超过了maxCount,需要更新maxCount,并且要给root重新赋值// 此时不仅要更新maxCount,而且要清空结果集if(maxCount < curCount){maxCount = curCount;result.clear();result.push_back(cur->val);}pre = cur; // 获取上次的结点// --------------单层逻辑判断-----------------------------------cur = cur->right;}}return result;}};
总结
本题在递归法中,我给出了如果是普通二叉树,应该怎么求众数。
知道了普通二叉树的做法时候,我再进一步给出二叉搜索树又应该怎么求众数,这样鲜明的对比,相信会对二叉树又有更深层次的理解了。
在递归遍历二叉搜索树的过程中,我还介绍了一个统计最高出现频率元素集合的技巧, 要不然就要遍历两次二叉搜索树才能把这个最高出现频率元素的集合求出来。
为什么没有这个技巧一定要遍历两次呢? 因为要求的是集合,会有多个众数,如果规定只有一个众数,那么就遍历一次稳稳的了。
最后我依然给出对应的迭代法,其实就是迭代法中序遍历的模板加上递归法中中间节点的处理逻辑,分分钟就可以写出来,中间逻辑的代码我都是从递归法中直接粘过来的。
求二叉搜索树中的众数其实是一道简单题,但大家可以发现我写了这么一大篇幅的文章来讲解,主要是为了尽量从各个角度对本题进剖析,帮助大家更快更深入理解二叉树。
需要强调的是 leetcode上的耗时统计是非常不准确的,看个大概就行,一样的代码耗时可以差百分之50以上,所以leetcode的耗时统计别太当回事,知道理论上的效率优劣就行了。
27、二叉树的最近公共祖先
236. 二叉树的最近公共祖先 - 力扣(LeetCode)
思路:
遇到这个题目首先想的是要是能自底向上查询就好了,这样就可以找到公共祖先了。
那么二叉树如何可以自底向上查找呢?
回溯!二叉树回溯的过程就是自底向上的。
后序遍历就是天然的回溯过程,最想处理的一定是叶子节点。
接下来就看如何判断一个节点是节点q和节点p的公共祖先了。
如果找到了一个节点,发现左子树出现节点p,右子树出现节点q,或者左子树出现节点q,右子树出现节点p,那么该节点就是节点p和q的最近公共祖先。
使用后序遍历,模拟回溯的过程,就是从底向上遍历节点,一旦发现符合这个条件的节点,就是最近公共节点。
思考:
- 如何自底向上遍历?
- 为什么要全局搜索这棵二叉树?如果像以下这种情况直接返回不好吗?
- 如何把结果传到根节点的?
为什么使用递归法不适用迭代法?
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode(int x) : val(x), left(NULL), right(NULL) {}* };*/class Solution {public:TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {// 递归出口if(root == p || root == q || root == NULL) return root;TreeNode* left = lowestCommonAncestor(root->left, p, q); // 左TreeNode* right = lowestCommonAncestor(root->right, p, q); // 右// 中if(left != NULL && right != NULL) return root;else if(left != NULL && right == NULL) return left;else if(left == NULL && right != NULL) return right;else{ // if(left == NULL && right == NULL)return NULL;}}};
如果分析完上面的代码还想不出来的话就看:代码随想录 - 二叉树 - 27. 二叉树的最近公共祖先
总结
这道题目刷过的同学未必真正了解这里面回溯的过程,以及结果是如何一层一层传上去的。
那么我给大家归纳如下三点:
- 求最小公共祖先,需要从底向上遍历,那么二叉树,只能通过后序遍历(即:回溯)实现从低向上的遍历方式。
- 在回溯的过程中,必然要遍历整棵二叉树,即使已经找到结果了,依然要把其他节点遍历完,因为要使用递归函数的返回值(也就是代码中的left和right)做逻辑判断。
- 要理解如果返回值left为空,right不为空为什么要返回right,为什么可以用返回right传给上一层结果。
可以说这里每一步,都是有难度的,都需要对二叉树,递归和回溯有一定的理解。
本题没有给出迭代法,因为迭代法不适合模拟回溯的过程。理解递归的解法就够了。
28、二叉树的周末总结
本周小结!(二叉树系列四)
这已经是二叉树的第四周总结了,二叉树是非常重要的数据结构,也是面试中的常客,所以有必要一步一步帮助大家彻底掌握二叉树!
周一
在二叉树:合并两个二叉树(opens new window)中讲解了如何合并两个二叉树,平时我们都习惯了操作一个二叉树,一起操作两个树可能还有点陌生。
其实套路是一样,只不过一起操作两个树的指针,我们之前讲过求 二叉树:我对称么?(opens new window)的时候,已经初步涉及到了 一起遍历两棵二叉树了。
迭代法中,一般一起操作两个树都是使用队列模拟类似层序遍历,同时处理两个树的节点,这种方式最好理解,如果用模拟递归的思路的话,要复杂一些。
周二
周二开始讲解一个新的树,二叉搜索树,开始要换一个思路了,如果没有利用好二叉搜索树的特性,就容易把简单题做成了难题了。
学习二叉搜索树的特性(opens new window),还是比较容易的。
大多是二叉搜索树的题目,其实都离不开中序遍历,因为这样就是有序的。
至于迭代法,相信大家看到文章中如此简单的迭代法的时候,都会感动的痛哭流涕。
周三
了解了二搜索树的特性之后, 开始验证一棵二叉树是不是二叉搜索树(opens new window)。
首先在此强调一下二叉搜索树的特性:
- 节点的左子树只包含小于当前节点的数。
- 节点的右子树只包含大于当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
那么我们在验证二叉搜索树的时候,有两个陷阱:
- 陷阱一
不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了,而是左子树都小于中间节点,右子树都大于中间节点。
- 陷阱二
在一个有序序列求最值的时候,不要定义一个全局遍历,然后遍历序列更新全局变量求最值。因为最值可能就是int 或者 longlong的最小值。
推荐要通过前一个数值(pre)和后一个数值比较(cur),得出最值。
在二叉树中通过两个前后指针作比较,会经常用到。
本文二叉树:我是不是一棵二叉搜索树(opens new window)中迭代法中为什么没有周一那篇那么简洁了呢,因为本篇是验证二叉搜索树,前提默认它是一棵普通二叉树,所以还是要回归之前老办法。
周四
了解了二叉搜索树(opens new window),并且知道如何判断二叉搜索树(opens new window),本篇就很简单了。
要知道二叉搜索树和中序遍历是好朋友!
在二叉树:搜索树的最小绝对差(opens new window)中强调了要利用搜索树的特性,把这道题目想象成在一个有序数组上求两个数最小差值,这就是一道送分题了。
需要明确:在有序数组求任意两数最小值差等价于相邻两数的最小值差。
同样本题也需要用pre节点记录cur节点的前一个节点。(这种写法一定要掌握)
周五
此时大家应该知道遇到二叉搜索树,就想是有序数组,那么在二叉搜索树中求二叉搜索树众数就很简单了。
在二叉树:我的众数是多少?(opens new window)中我给出了如果是普通二叉树,应该如何求众数的集合,然后进一步讲解了二叉搜索树应该如何求众数集合。
在求众数集合的时候有一个技巧,因为题目中众数是可以有多个的,所以一般的方法需要遍历两遍才能求出众数的集合。
但可以遍历一遍就可以求众数集合,使用了适时清空结果集的方法,这个方法还是很巧妙的。相信仔细读了文章的同学会惊呼其巧妙!
所以大家不要看题目简单了,就不动手做了,我选的题目,一般不会简单到不用动手的程度,哈哈。
周六
在二叉树:公共祖先问题(opens new window)中,我们开始讲解如何在二叉树中求公共祖先的问题,本来是打算和二叉搜索树一起讲的,但发现篇幅过长,所以先讲二叉树的公共祖先问题。
如果找到一个节点,发现左子树出现结点p,右子树出现节点q,或者 左子树出现结点q,右子树出现节点p,那么该节点就是节点p和q的最近公共祖先。
这道题目的看代码比较简单,而且好像也挺好理解的,但是如果把每一个细节理解到位,还是不容易的。
主要思考如下几点:
- 如何从底向上遍历?
- 遍历整棵树,还是遍历局部树?
- 如何把结果传到根节点的?
这些问题都需要弄清楚,上来直接看代码的话,是可能想不到这些细节的。
公共祖先问题,还是有难度的,初学者还是需要慢慢消化!
总结
本周我们讲了如何合并两个二叉树(opens new window),了解了如何操作两个二叉树。
然后开始另一种树:二叉搜索树,了解二叉搜索树的特性(opens new window),然后判断一棵二叉树是不是二叉搜索树(opens new window)。
了解以上知识之后,就开始利用其特性,做一些二叉搜索树上的题目,求最小绝对差(opens new window),求众数集合(opens new window)。
接下来,开始求二叉树与二叉搜索树的公共祖先问题,单篇篇幅原因,先单独介绍普通二叉树如何求最近公共祖先(opens new window)。
现在已经讲过了几种二叉树了,二叉树,二叉平衡树,完全二叉树,二叉搜索树,后面还会有平衡二叉搜索树。 那么一些同学难免会有混乱了,我针对如下三个问题,帮大家在捋顺一遍:
- 平衡二叉搜索数是不是二叉搜索树和平衡二叉树的结合?
是的,是二叉搜索树和平衡二叉树的结合。
- 平衡二叉树与完全二叉树的区别在于底层节点的位置?
是的,完全二叉树底层必须是从左到右连续的,且次底层是满的。
- 堆是完全二叉树和排序的结合,而不是平衡二叉搜索树?
堆是一棵完全二叉树,同时保证父子节点的顺序关系(有序)。 但完全二叉树一定是平衡二叉树,堆的排序是父节点大于子节点,而搜索树是父节点大于左孩子,小于右孩子,所以堆不是平衡二叉搜索树。
大家如果每天坚持跟下来,会发现又是充实的一周![机智]
29、二叉搜索树的最近公共祖先
235. 二叉搜索树的最近公共祖先 - 力扣(LeetCode)
思路
做了上面二叉树的最近公共祖先,再做二叉搜索树的最近公共祖先,可以很好的对比求解这两种树的最近公共祖先的异动点,首先,用解普通二叉树的解法肯定是能够解出二叉搜索树的,但是需要注意,普通二叉树的解法是去遍历一整棵树,但是通过二叉搜素树的性质可以优化这一解法。
- 如果找到最近公共祖先,可以直接返回,不需要再去遍历剩下没有遍历的节点,原因是在二叉树那里,我们采用的是后序遍历模拟回溯的方法,我们需要将回溯回去的
left和right做一个逻辑运算,以此来判断符合条件的节点是否全部找出。如果找到最近公共祖先就直接返回是无法确认找到一个还是两个都找到的,所以需要遍历整棵树。但是二叉搜索树就不用了,根据它的特性,我们可以直接返回(具体见代码) - 如何判断一个节点的左子树里有p,右子树里有q呢?其实只要从上到下遍历的时候,cur节点的数值在
[p, q]区间中就说明该节点cur就是最近公共祖先了。
递归法
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode(int x) : val(x), left(NULL), right(NULL) {}* };*/class Solution {public:TreeNode* lowestCommonAncestor(TreeNode* cur, TreeNode* p, TreeNode* q) {if(cur == NULL) return cur;if(cur->val > p->val && cur->val > q->val){TreeNode* left = lowestCommonAncestor(cur->left, p, q); // 左if(left != NULL){return left;}}if(cur->val < p->val && cur->val < q->val){TreeNode* right = lowestCommonAncestor(cur->right, p, q); // 右if(right != NULL){return right;}}return cur;}};
迭代法
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode(int x) : val(x), left(NULL), right(NULL) {}* };*/class Solution {public:TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {while(root) {if (root->val > p->val && root->val > q->val) {root = root->left;} else if (root->val < p->val && root->val < q->val) {root = root->right;} else return root;}return NULL;}};
总结
对于二叉搜索树的最近祖先问题,其实要比普通二叉树公共祖先问题(opens new window)简单的多。
不用使用回溯,二叉搜索树自带方向性,可以方便的从上向下查找目标区间,遇到目标区间内的节点,直接返回。
最后给出了对应的迭代法,二叉搜索树的迭代法甚至比递归更容易理解,也是因为其有序性(自带方向性),按照目标区间找就行了。
30、二叉搜索树中的插入操作
701. 二叉搜索树的插入操作 - 力扣(LeetCode)
思路
其实这是一道简单的题目,但是题目中的提示:有多种有效的插入方式,还可以重构二叉搜索树,一下子把我吓住了,瞬间感觉题目难了许多!
但是别慌,只要不考虑题目的中改变树的结构的插入方式,那么只需要找到一个统一的插入方法,这道题就一下子简单起来了,甚至还能写出多种解。哈哈哈!
最简单的方式,应该是遇到空节点就插入节点这一种了。
递归法
没有返回值的递归解法,代码比较复杂,但是确实真正的解题逻辑
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:void traversal(TreeNode* cur, int val){if(cur == nullptr) return;if(cur->val > val){if(cur->left == nullptr){cur->left = new TreeNode(val);return;}traversal(cur->left, val);}else if(cur->val < val){if(cur->right == nullptr){cur->right = new TreeNode(val);return;}traversal(cur->right, val);}return;}TreeNode* insertIntoBST(TreeNode* root, int val) {if(root == nullptr){return new TreeNode(val);}TreeNode* copyRoot = root;traversal(copyRoot, val);return root;}};
有返回值的递归(用root->left 和 root->right 来接住返回值)
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:TreeNode* insertIntoBST(TreeNode* root, int val) {if(root == nullptr){root = new TreeNode(val);}if(root->val > val) root->left = insertIntoBST(root->left, val);else if(root->val < val) root->right = insertIntoBST(root->right, val);return root;}};
可以看出没有返回值的递归还是麻烦一些的。
我之所以举这个例子,是想说明通过递归函数的返回值完成父子节点的赋值是可以带来便利的。
网上千变一律的代码,可能会误导大家认为通过递归函数返回节点 这样的写法是天经地义,其实这里是有优化的!
迭代法
注意,迭代法就需要用一个parent节点来记录上一次访问过的节点了。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:TreeNode* insertIntoBST(TreeNode* root, int val) {if(root == nullptr) return new TreeNode(val);TreeNode* cur = root;TreeNode* parent = root;while(cur){parent = cur;if(cur->val > val) cur = cur->left;else if(cur->val < val) cur = cur->right;}TreeNode* node = new TreeNode(val);if(parent->val > val) parent->left = node;else parent->right = node;return root;}};
31、删除二叉搜索树中的节点
450. 删除二叉搜索树中的节点 - 力扣(LeetCode)
思路见代码随想录代码随想录 - 二叉树 - 31. 删除二叉搜索树中的节点
二叉搜索树的递归法
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:TreeNode* deleteNode(TreeNode* root, int key) {// 第一种情况:没找到删除的节点,遍历到空节点直接返回了if(root == nullptr) return root;// 递归单层逻辑if(root->val == key){// 第二种情况,当前节点的左右节点都为空,直接删除当前节点,并返回nullptrif(root->left == nullptr && root->right == nullptr){delete root; // 内存释放return nullptr;}// 第三种情况,当前节点的左节点不为空,右节点为空,删除当前节点,左节点补上else if(root->left != nullptr && root->right == nullptr){auto resNode = root->left;delete root; // 内存释放return resNode;}// 第四种情况,当前节点的左节点为空,右节点不为空,删除当前节点,右节点补上else if(root->left == nullptr && root->right != nullptr){auto resNode = root->right;delete root; // 内存释放return resNode;}// 第五种情况,当前节点的左右节点都不为空,将以左节点为跟节点的左子树续在以右节点为右子树的最下面的最左边的节点上// 并返回删除节点的右节点为新的根节点else{auto resNode = root->right;auto cur = root->right;while(cur->left){ // 获取最下边最左边的节点cur = cur->left;}cur->left = root->left;delete root; // 释放内存节点,这里可以不写,但C++最好还是手动释放return resNode;}}if(root->val > key) root->left = deleteNode(root->left, key);if(root->val < key) root->right = deleteNode(root->right, key);return root;}};
普通二叉树的删除节点的递归法我没看懂,回头再看。
迭代法
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {private:// 将目标节点(删除节点)的左子树放到 目标节点的右子树的最左面节点的左孩子位置上// 并返回目标节点右孩子为新的根节点// 是动画里模拟的过程TreeNode* deleteOneNode(TreeNode* target) {if (target == nullptr) return target;if (target->right == nullptr) return target->left;TreeNode* cur = target->right;while (cur->left) {cur = cur->left;}cur->left = target->left;return target->right;}public:TreeNode* deleteNode(TreeNode* root, int key) {if (root == nullptr) return root;TreeNode* cur = root;TreeNode* pre = nullptr; // 记录cur的父节点,用来删除curwhile (cur) {if (cur->val == key) break;pre = cur;if (cur->val > key) cur = cur->left;else cur = cur->right;}if (pre == nullptr) { // 如果搜索树只有头结点return deleteOneNode(cur);}// pre 要知道是删左孩子还是右孩子if (pre->left && pre->left->val == key) {pre->left = deleteOneNode(cur);}if (pre->right && pre->right->val == key) {pre->right = deleteOneNode(cur);}return root;}};
32、修剪二叉搜索树
递归法
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:TreeNode* trimBST(TreeNode* root, int low, int high) {if(root == nullptr) return nullptr;// 如果当前节点小于low,还需要判断root->right跟low的关系if(root->val < low){TreeNode* right = trimBST(root->right, low, high); // 直到right在区间[low, high]里面return right;}else if(root->val > high){TreeNode* left = trimBST(root->left, low, high); // 直到left在区间[low, high]里面return left;}root->left = trimBST(root->left, low, high); // root->left接入符合条件的左孩子root->right = trimBST(root->right, low, high); // root->right接入符合条件的右孩子return root;}};
迭代法
因为二叉搜索树的有序性,不需要使用栈模拟递归的过程。
在剪枝的时候,可以分为三步:
- 将root移动到[L, R] 范围内,注意是左闭右闭区间
- 剪枝左子树
- 剪枝右子树
代码如下:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:TreeNode* trimBST(TreeNode* root, int low, int high) {if(root == nullptr) return nullptr;// 处理头节点,让root移动到[L, R]范围内,注意是左闭右闭while(root != nullptr && (root->val < low || root->val > high)){if(root->val < low) root = root->right; // 小于low往右走else root = root->left; // 大于high往左走}TreeNode* cur = root;// 此时root已经在[low, high]范围内,处理左孩子元素小于low的情况while(cur != nullptr){while(cur->left && cur->left->val < low){cur->left = cur->left->right;}cur = cur->left;}cur = root;// 此时root已经在[low, high]范围内,处理右孩子元素大于high的情况while(cur != nullptr){while(cur->right && cur->right->val > high){cur->right = cur->right->left;}cur = cur->right;}return root;}};
33、将有序数组转换为二叉搜索树
108. 将有序数组转换为二叉搜索树 - 力扣(LeetCode)
偷个懒,解题思路见代码随想录,这道题有分治思想,好好看一看
代码随想录 - 二叉树 - 33. 将有序数组转换为二叉搜索树
递归法
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:TreeNode* buildBBST(vector<int>& nums, int left, int right){if(left > right) return nullptr;int mid = left + (right - left) / 2; // 防止越界的写法TreeNode* cur = new TreeNode(nums[mid]);cur->left = buildBBST(nums, left, mid - 1);cur->right = buildBBST(nums, mid + 1, right);return cur;}TreeNode* sortedArrayToBST(vector<int>& nums) {return buildBBST(nums, 0, nums.size() - 1);}};
迭代法
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:TreeNode* sortedArrayToBST(vector<int>& nums) {if(nums.size() == 0) return nullptr;TreeNode* root = new TreeNode(0); // 初始化根节点queue<TreeNode*> nodeQue; // 放遍历的节点queue<int> leftQue; // 保存左区间下标queue<int> rightQue; // 保存右区间下标nodeQue.push(root); // 根节点入队列leftQue.push(0); // 0为左区间下标的初始位置rightQue.push(nums.size() - 1); // 右区间的初始位置while(!nodeQue.empty()){TreeNode* curNode = nodeQue.front();nodeQue.pop();int left = leftQue.front(); leftQue.pop();int right = rightQue.front(); rightQue.pop();int mid = left + ((right - left) >> 1); // 防止数组越界curNode->val = nums[mid]; // 将mid对应的元素给中间节点// 处理左区间if(left <= mid - 1){curNode->left = new TreeNode(0);nodeQue.push(curNode->left);leftQue.push(left);rightQue.push(mid - 1);}// 处理右区间if(right >= mid + 1){curNode->right = new TreeNode(0);nodeQue.push(curNode->right);leftQue.push(mid + 1);rightQue.push(right);}}return root;}};
34、把二叉搜索树转换为累加树
538. 把二叉搜索树转换为累加树 - 力扣(LeetCode)
思路
一看到累加树,相信很多小伙伴都会疑惑:如何累加?遇到一个节点,然后在遍历其他节点累加?怎么一想这么麻烦呢。
然后再发现这是一棵二叉搜索树,二叉搜索树啊,这是有序的啊。
那么有序的元素如果求累加呢?
其实这就是一棵树,大家可能看起来有点别扭,换一个角度来看,这就是一个有序数组[2, 5, 13],求从后到前的累加数组,也就是[20, 18, 13],是不是感觉这就简单了。
为什么变成数组就是感觉简单了呢?
因为数组大家都知道怎么遍历啊,从后向前,挨个累加就完事了,这换成了二叉搜索树,看起来就别扭了一些是不是。
那么知道如何遍历这个二叉树,也就迎刃而解了,从树中可以看出累加的顺序是右中左,所以我们需要反中序遍历这个二叉树,然后顺序累加就可以了。
递归法
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:TreeNode* pre = new TreeNode(0); // 记录前一个结点void traversal(TreeNode* node){if(node == nullptr) return;traversal(node->right);node->val += pre->val;pre = node;traversal(node->left);return;}TreeNode* convertBST(TreeNode* root) {if(root == nullptr) return nullptr;traversal(root);return root;}};
迭代法
迭代法其实就是中序模板题了,在二叉树:前中后序迭代法(opens new window)和二叉树:前中后序统一方式迭代法(opens new window)可以选一种自己习惯的写法。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/class Solution {public:TreeNode* convertBST(TreeNode* root) {if(root == nullptr) return nullptr;TreeNode* pre = new TreeNode(0); // 记录前一个结点TreeNode* cur = root;stack<TreeNode*> st;while(!st.empty() || cur != nullptr){if(cur != nullptr){st.push(cur);cur = cur->right; // 右}else{cur = st.top();st.pop();cur->val += pre->val; // 中pre = cur; // 获得上一次访问的结点cur = cur->left; // 左}}return root;}};
35、二叉树总结篇
一刷之后回来自己总结,现在先用卡哥的代码随想录 - 二叉树 - 35. 二叉树总结篇

若有收获,就点个赞吧
0 人点赞
