CRUD
新增(Create)
INSERT [INTO]
全列插入
指定列插入INSERT INTO books (name,price)values('白给',30);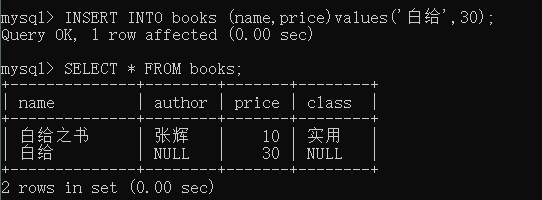
注意:
基本的字符模式设置
https://www.cnblogs.com/yangmingxianshen/p/7999428.html
中文插入 show variables like '%character%';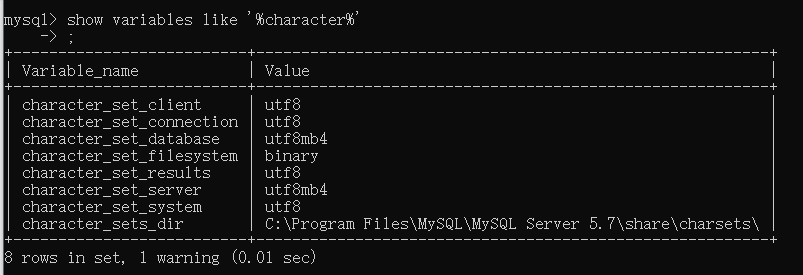
指定列插入的时候,需要保证values后面()中的值的类型
如果插入很多条数据
可以构造一个inset语句,依次插入一定的次数,然后循环执行n次
查找
全列查找select * from [表名];*叫作通配符,表示所有的列
部分查找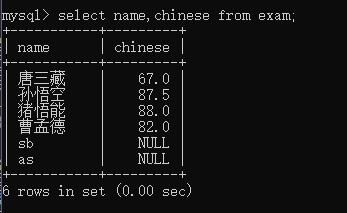
查和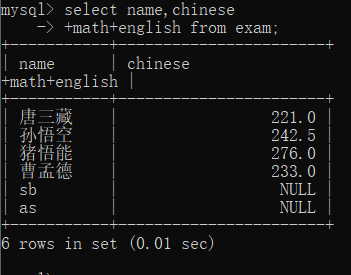
注意:
- 使用表达是查询的时候,计算结果的列的类型可能是和原来的列类型不相同会尽可能的保证数据的结果是正确的
- 有的表列数可能很多,客户端输入得查查询语句,都是交给服务器进行执行的,服务器再把执行结果返回给客户端,通过网络进行传输
计算机的资源
- CPU
- 内存
- 磁盘
- 带宽资源(带宽往往是成本最高的)
指定别名查找
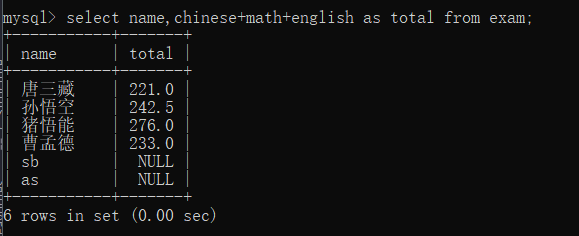
在这里total就是别名,用于表头显示
注意:
使用as total,as的作用是容易误把此处看作,把total当作一个列,所以建议加上as
select执行的结果是一个‘临时表’,并不会修改磁盘上的数据
去重 DISTINCT
根据查询结果中某一列或者某几列的值进行去重select distinct [列名]from [表名];
注意:
select查询结果,去重后的行顺序,与原来的顺序是大概率不一样的,甭管
-- 表达式不包含字段SELECT id, name, 10 FROM exam_result;-- 表达式包含一个字段SELECT id, name, english + 10 FROM exam_result;-- 表达式包含多个字段SELECT id, name, chinese + math + english FROM exam_result
排序 ORDER BY
数据结构中的排序算法——>针对内存排序
数据库的排序操作是在select中进行的,先把数据读入内存中,再进行排序
select理论上不会修改,但是如果查询结果比较大,此时存储临时表可能也会用到一定的磁盘空间(不会修改原始数据)
所以针对查询结果临时表排序,可能是针对内存的数据排序,也可能是针对外存的数据排序
单列排序
order by [列名] asc/desc
asc升序,desc降序,默认不加 升序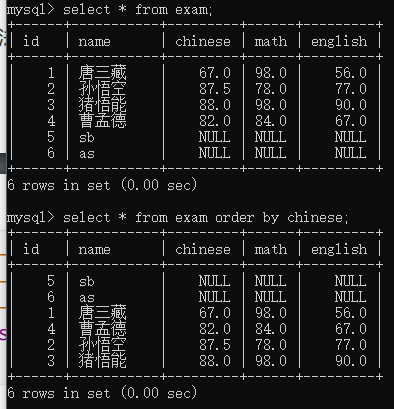
升序降序,同时可以指定多个列
当排序的时候可能会遇到某两行数据相等,针对这种情况,没有明确约定谁先谁后——>因此多列排序就有了存在意义
多列排序
先按照第一列排序,在第一列相同的情况下,再看第二列
同理,三列排序,第一二列都相同再看第三列select * from exam order by math , chinese;
注意:
多列排序的时候针对每一列都可以指定升序降序
条件查询(核心用法) WHERE
数据量一旦规模级增长,查询语句不带条件,查询开销可能会非常大(动辄几秒甚至几分钟)
| 运算符 | 说明 |
|---|---|
| >,>=,<,<= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL不安全,例如NULL = NULL的结果是NULL |
| <=> | 等于,NULL安全,例如NULL <=> NULL的结果是TRUE(1) |
| !=,<> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0,a1],如果a0 <= valus=e <= a1,返回TRUE(1) |
| IN(option, …) | 如果是option中的任意一个,返回TRUE(1) |
| IS NULL | 是NULL |
| IS NOT NULL | 不是NULL |
| LIKE | 模糊匹配,%表示任意多个(包括0个)认意字符;_表示任意一个字符 |
逻辑运算符
| 运算符 | 说明 | Java对应符号 |
|---|---|---|
| AND | 多个条件必须都为TRUE(1),结果才是TRUE(1) | && |
| OR | 任意一个条件为true(1),结果为TRUE(1) | || |
| NOT | 条件为TRUE(1),结果为FALSE(0) | ! |
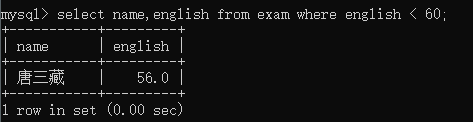
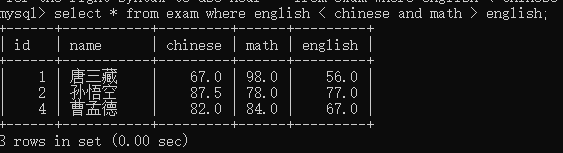
Chinese between 58 and 91;

select name, math from exam where math in (58,59,98,99);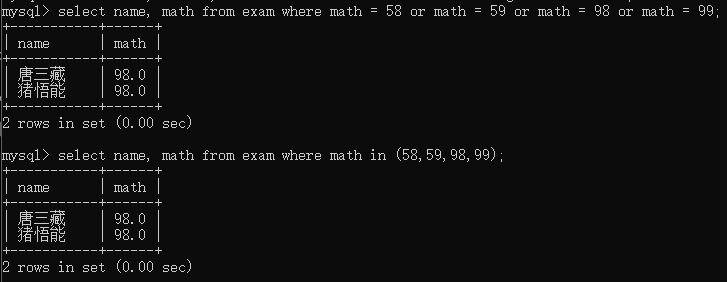
select name from exam where name like '孙%';
姓名中以孙开头的select name from exam where name like '%孙';
姓名中以孙结尾的select name from exam where name like '孙_';
姓名叫孙某的,'孙__'姓名叫孙某某的
关于SQL中与NULL的判断
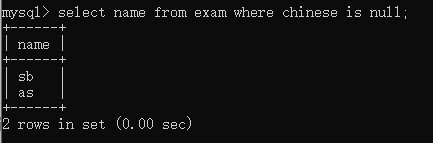
查找语文缺考的同学select name from exam where chinese = null;
NULL = NULL —>false
因为NULL 在SQL中相当于FALSEselect name from exam where chinese <=> null;
NULL <=> NULL —>trueselect name from exam where chinese is null;
is NULL
分页查询 limit 目的和条件查询类似
如果数据库表里的面的数据非常多,一个不加限制的查找,可能会非常久,甚至会大致数据库被卡死
实际开发里面一般都会对这些操作会做出限制
条件是一种限制
limit也是一种限制(分页查找)
很多的网站很多的场景都会用到分页,目的都是为了避免数据库压力过大select * from exam limit 3;
限制结果最多不超过3条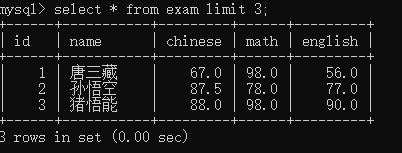
查找总成绩前三名的同学select name,chinese+math+english as total from exam order by chinese+math+english desc limit 3;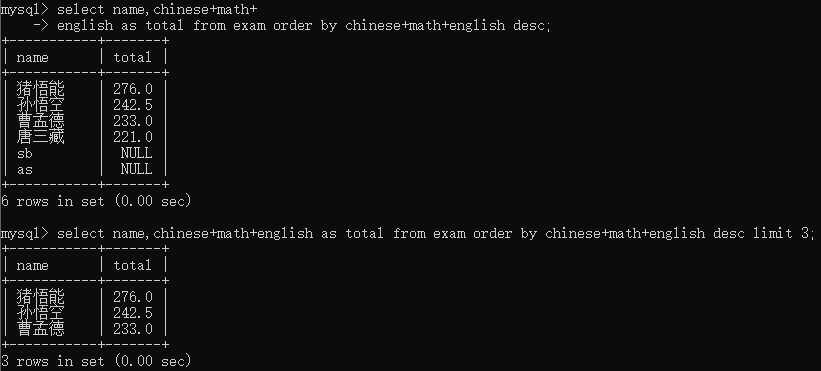
limit可以搭配select的任意功能使用
查找总成绩4~6名的同学——>在limit的基础上加上offset
offset就表示从哪个位置开始选取数据(从0开始计数)
select name,chinese+math+english as total from exam order by chinese+math+english desc limit 3 offset 3;
也可以limit1,3,但是并不常用
注意
- WHERE条件可以使用表达式,但不能使用别名
- AND的优先级高于OR,在同时使用时,需要使用小括号
()包裹优先执行的部分 - where子句不能使用别名(如果自己实现一个数据库,让他的where子句能支持别名,理论上也是可以的)
- COLLATE:指定数据库字符集的校验规则,也就是标定了varchar类型之间
>或<的规则 - AND 和 OR 的优先级:针对SQL来讲,AND优先于OR,但是尽量加括号视觉上会比较明显
- 如果需要在数据库中表示时间日期,最好还是使用datetime类型,不要用timestamp,更不要用字符串类型
修改 Update
UPDATE TABLE_name SET column = expr[, column = expr ``...][WHERE ...] [ORFER BY ...] [LIMIT ...]
-- 将孙悟空同学的数学成绩变更为 80 分UPDATE exam_result SET math = 80 WHERE name = '孙悟空';-- 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分UPDATE exam_result SET math = 60, chinese = 70 WHERE name = '曹孟德';-- 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分UPDATE exam_result SET math = math + 30 ORDER BY chinese + math + english LIMIT 3;-- 将所有同学的语文成绩更新为原来的 2 倍UPDATE exam_result SET chinese = chinese * 2;
注意:
- 对null进行修改操作,不会报错,也不会对null有所影响
- 注意是否超出界限
- update一样是很危险的,要注意!一旦改错了,很难被发现
删除 Delete
delete from exam;
删除该表内所有数据,表本身还在
区别于drop table;——>直接删除表
表的设计:
- 找出实体
- 分析实体间的关系
一对一
一对多
多对多
没关系
命令行客户端,输入sql语句理论上一定要带上
;否则在客户端,容易无法判定是否已经结束该行的输入 但是针对某些已经没啥好有后续的语句,就可以没有;也可以结束输入

若有收获,就点个赞吧
0 人点赞
