Bit-map法,又称为位图法。
基本原理:使用位数组来表示某些元素是否存在。
举例
具体而言,位图排序以一个N位长的串,每位上以“1”或“0”表示需要排序的集合(后简称“集合”)中的数。
例如,集合为{2,7,4,9,1,10},则生成一个10位的串,将第2、7、4、9、1、10位置为“1”,其余位置为“0”,这样当把串中所有位都置完后,排序也自动完成了(因为字符串的下标是有序的):1101001011。
要排序0~15内的以下元素序列{5,8,1,12,6,2},那么首先开辟两个字节的空间,也就是16位,分别对应0~15这16个数。首先,将这16位置为0。遍历序列,在出现的数字的对应位置上置1,也就是将每个元素对应到了位图的相应位置。再遍历这16位,就完成了对元素的排序,过程如图所示。
位图排序的时间复杂度是O(n)的,比一般的排序都快,但它是以空间换时间(需要一个N位的串)的,而且有一些限制,即数据状态不是很多。例如,排序前集合大小最好已知,而且集合中元素的最大重复次数必须已知(不然空间浪费很大)。
利用位图判断重复
位图法首先扫描一遍集合,找出集合中的最大元素,然后按照集合中最大元素max创建一个长度为max+1的新数组。
接着再次扫描原数组,每遇到一个元素,就将新数组中下标为元素值的位上置1。例如,如果遇到元素5,就将新数组的第6个元素置为1,如此下去。
当下次再遇到元素5想置位时,发现新数组的第6个元素已经被置为1了,则说明这次的数据肯定和以前的数据存在着重复。
该算法的运算次数最坏的情况为2N,但如果能够事先知道集合的最大元素的值,那么效率还可以提高一倍。
布隆过滤器Bloom filter法
问题描述
日常生活中很多地方都会遇到类似这样的问题:
设计计算机软件系统时,在程序中经常需要判断一个元素是否在一个集合中;
在字处理软件中,需要检查一个英语单词是否拼写正确;
在FBI,一个嫌疑人的名字是否已经在嫌疑名单上。
最直接的解决方法:将集合中全部元素都存储在计算机中,每当遇到一个新元素时,将它和集合中的元素直接进行比较。
当数据量巨大时,存储和查找的效率低下。
解决问题
使用布隆过滤器开解决这类问题:检测一个元素是否属于一个集合。
基本原理
概述:位数组和Hash函数的联合使用。
布隆过滤器:组成(位数组和Hash函数) + 数据插入 + 判断
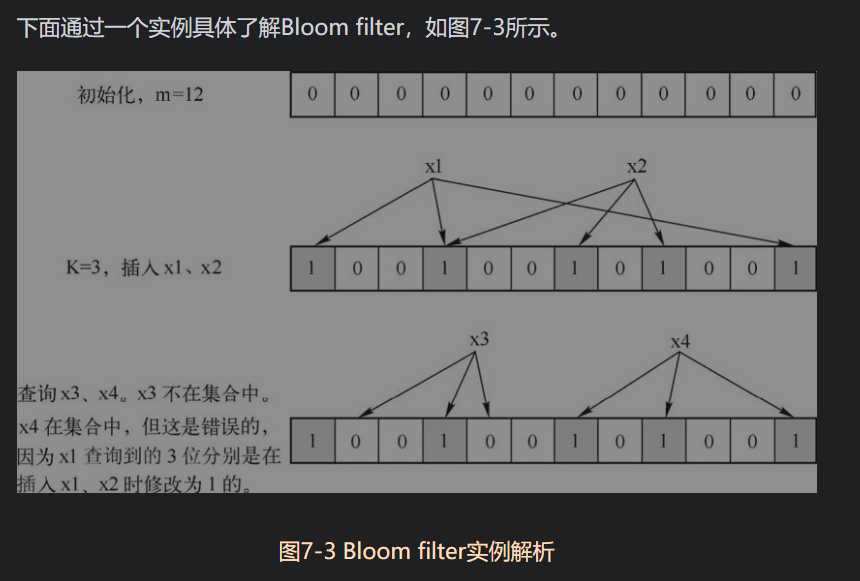
- Bloom filter是一个包含了m位的位数组,数组的每一位都初始化为0。
- 数组的每一位都初始化为0,然后定义k个不同的Hash函数,每个函数都可以将集合中的元素映射到位数组的某一位,将这些位设置为1。
- 如果查询某个元素是否属于集合,那么根据k个Hash函数可以得到位数组中的k个位,查看这k个位中的值,
- 如果有的位不为1,那么该元素肯定不在此集合中。
- 如果这k个位全部为1,那么该元素可能在此集合中。(原因是在进行映射的时候,k个哈希函数计算出的位置上都为1,然而这些1都不是待查询本身产生的,而是其他元素产生的,也就是说这个数并没有真正在集合中,就误判了)
布隆过滤器总结
Bloom filter的优点是具有很好的空间效率和时间效率。它的插入和查询时间都是常数,另外它不保存元素本身,具有良好的安全性。然而,这些优点都是以牺牲正确率为代价的。当插入的元素越多,错判“元素属于这个集合”的概率就越大。另外,Bloom filter只能插入元素,却不能删除元素,因为多个元素的哈希结果可能共用了Bloom filter结构中的同一个位,如果删除元素,就可能会影响多个元素的检测。所以,Bloom filter可以用来实现数据字典、进行数据的判重或者集合求交集。
- 暂时没理解下面这段话
所以,使用Bloom filter的难点是如何根据输入元素个数n,来确定位数组m的大小以及Hash函数。当Hash函数个数k=(ln2)×(m/n)时错误率最小,在错误率不大于E的情况下,m至少要等于n×lg(1/E)才能表示任意n个元素的集合。但m还应该更大些,因为还要保证位数组里至少一半为0,则m应该≥nlg(1/E)×lge,大概就是nlg(1/E)的1.44倍(lg表示以2为底的对数)。

若有收获,就点个赞吧
0 人点赞
