默认从小到大排序,以这样的既定规则去分析排序算法
冒泡排序
每次循环将次大的数选出来,排好
原理:
- 比较每对相邻的元素,如果顺序错误,交换它们;
- 每次循环将最大的元素放到末端合适位置;
- 重复列表直到不需要交换,表明已被排序
属性:
- O(1)的额外空间
- O(n^2)的比较和交换
- 稳定(因为相邻两个元素如果相同,不需要进行交换位置,因此相同元素的相对位置不会改变)
代码:
def _bubble_sort(nums:list, reverse=False):length = len(nums)for i in range(length):is_sorted = True # 如果没有交换过,说明已经排序好for j in range(length - i - 1):if nums[j] > nums[j+1]:nums[j], nums[j+1] = nums[j+1], nums[j]is_sorted = Falseif (is_sorted):breakif reverse:nums.reverse()return nums
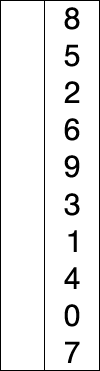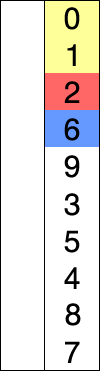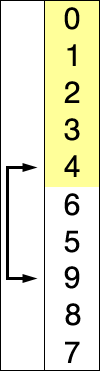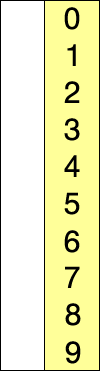
选择排序
每次选择次小放在已排序的末端
原理:
- 在未排序的序列中找到最大的元素,存放到序列末端(已排序的序列起士位置);
- 在未排序的序列中,找到最大的元素,放到已排序序列起始位置;
- 重复第2步,所有序列都已排序
属性:
- O(1)的额外空间
- O(n^2)对比,O(n)的交换
- 不稳定
(举个例子,序列5 8 5 2 9,我们知道第一遍选择第1个元素5会和2交换,那么原序列中2个5的相对前后顺序就被破坏了,所以选择排序不是一个稳定的排序算法。)
代码:
- 找到最小的点,放在序列首端
- 在剩下未排序的元素中,找到次小的点,接在后面
- 继续这样做,直至所有元素排序完成
class Solution:def sortArray(self, nums: List[int]) -> List[int]:# selection sortlength = len(nums)for i in range(length):pos_min = ifor j in range(i + 1, length):if nums[j] < nums[pos_min]:pos_min = jnums[i], nums[pos_min] = nums[pos_min], nums[i]return nums
插入排序
插入到已排序的序列中
原理:
- 从第一个元素开始,该元素认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一个位置
- 重复步骤3,找到新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5
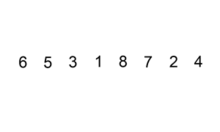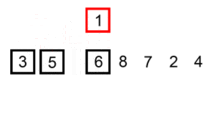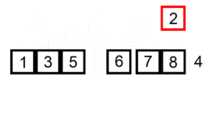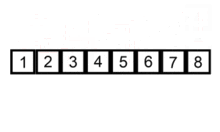
属性:
- 时间复杂度O(n^2)
- 额外空间O(n)
- 稳定的
代码:
class Solution:def sortArray(self, nums: List[int]) -> List[int]:# insert sortlength = len(nums)for i in range(1, length):for j in range(i, 0, -1):if nums[j] < nums[j - 1]:nums[j], nums[j - 1] = nums[j - 1], nums[ j]else:breakreturn nums
希尔排序
- 不熟悉
原理:
代码:
def shell_sort(list):
n = len(list)
# 初始步長
gap = n // 2
while gap > 0:
for i in range(gap, n):
# 每个步長進行插入排序
temp = list[i]
j = i
# 插入排序
while j >= 0 and list[j - gap] > temp:
list[j] = list[j - gap]
j -= gap
list[j] = temp
# 得到新的步長
gap = gap // 2
return list
计数排序(桶排序)
原理:
- 找出待排序数组nums中最大和最大和最小的元素
- 统计数组中每个值为i的元素出现的次数,存入数组counts的第i项
- 在nums上按照正确的索引填充值
属性:
- 时间复杂度:O(n+k),n个数据范围为k的数
- 不稳定
- 空间复杂度:O(k),k表示最小值到最大值范围,需要开辟一个大小为k的counts数组用于计数
- 适用情况:范围小、重复元素比较多的序列
代码:
class Solution:def sortArray(self, nums: List[int]) -> List[int]:# count sortmmax, mmin = max(nums), min(nums)counts = [0] * (mmax - mmin + 1)# 计算每个val出现的次数for i, val in enumerate(nums):counts[val - mmin] += 1 # 索引从0开始,右移mminpos = 0for i in range(mmax - mmin + 1):for j in range(counts[i]):nums[pos] = i + mmin # 左移mmin,恢复原本值pos += 1return nums
归并排序(merge sort)
分而治之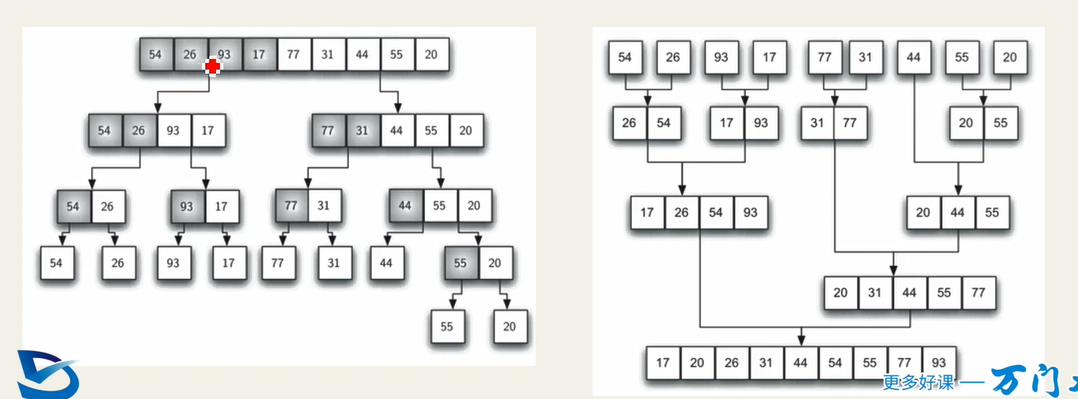
- 拆分
- 排序
- 合并
merge的时候时间复杂度是O(n),
属性:
- 时间复杂度O(nlogn)
- 空间复杂度O(n)
- 稳定的
改进:
- 对小型自阵列使用插入排序
- 测试两个需要merge的序列是否不需要merge,可以直接相加
python3中的sort和sorted函数使用的是:归并排序+插入排序的算法
用递归来写
def mergeSort(arr):import mathif(len(arr)<2):return arrmiddle = math.floor(len(arr)/2)left, right = arr[0:middle], arr[middle:]return merge(mergeSort(left), mergeSort(right))def merge(left,right):result = []while left and right:if left[0] <= right[0]:result.append(left.pop(0))else:result.append(right.pop(0));while left:result.append(left.pop(0))while right:result.append(right.pop(0));return result
⭐⭐快速排序
属于分治法(三大算法:分治法、动态规划、贪婪算法)
待排序的数列中,我们首先要找一个数字作为基准数(pivot,直译是中心枢纽, 这只是个专用名词)。为了方便,我们一般选择第 1 个数字作为基准数(其实选择第几个并没有关系)。接下来我们需要把这个待排序的数列中小于基准数的元素移动到待排序的数列的左边,把大于基准数的元素移动到待排序的数列的右边。这时,左右两个分区的元素就相对有序了;接着把两个分区的元素分别按照上面两种方法继续对每个分区(partition)找出基准数,然后移动,直到各个分区只有一个数时为止。
属性:
- 时间复杂度:nlog(n)
- 不稳定
代码:
跟思路有一些不一样,用递归实现(用到递归,就想到数学归纳法,n=1的时候成立,n=2成立,假设当n=k-1也成立,推导出n=k成立)
def _quick_sorted(nums:list) -> list:
pivot = nums[0]
left_nums = _quick_sorted([num for num in nums[1:] if num < pivot])
right_nums = _quick_sorted([num for num in nums[::-1] if num >= pivot])
return left_nums+ [pivot] + right_nums
改进:
时间复杂度分析,T(n)代表解决这个问题所需要的问题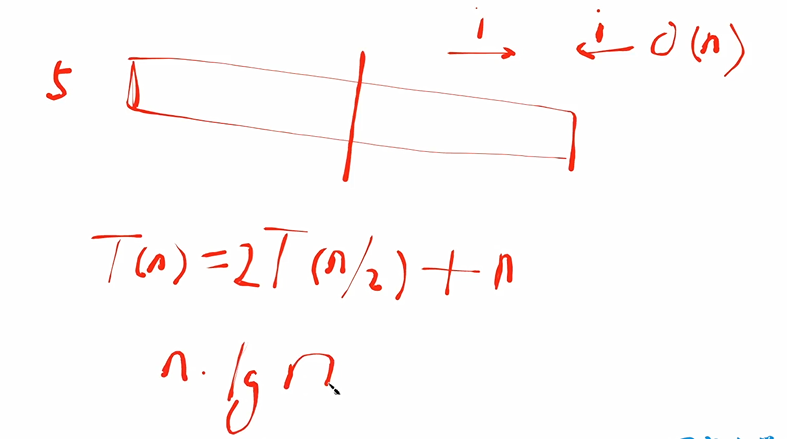
选择pivot跟算法复杂度息息相关,选择pivot为中位数是最好的(涉及中位数算法)。
一般工作中,选择第0个、中间的、最后的,在3个数中选择中间数,称为三点中值算法。
使用中位数算法,能保证算法复杂度(不管如何选择pivot)都是nlogn。
最好的一个排序算法,时间复杂度O(nlgn),空间复杂度O(n),不需要额外的空间。

若有收获,就点个赞吧
0 人点赞
