物联网技术让万物互联的同时,也为我们带来海量的数据,但是,如何对这些海量数据进行整理、分析,使数据切实产生价值,就成了迫切需要解决的问题。海量数据可以为用户带来的益处包括提高效率、降低成本、提高安全性等等,但这些益处都需要通过数据科学和人工智能技术进行发掘,才能进行应用。本文以一套应用于城市能源监控的物联网系统数据为例,通过python数据分析平台对数据进行基础的分析与预测。

1. 软硬件系统
出于快速开发考虑,本项目物联网系统使用了树莓派硬件及阿里云边缘计算技术,通过modbus驱动进行数据采集与上传,参见《利用阿里云物联网边缘计算功能,快速实现智慧能源监控系统设备接入》。上传到物联网平台的数据通过数据转化存入RDS数据库(也可直接通过api从物联网平台读取,本文为提高数据采集效率,采取从数据库读入的方式实现。
本文采用了python的数据科学发行版Anaconda,利用Jupyter notebook进行数据分析。这也是数据分析中常用的组合形式。由于数据库采用了MS SQL Server,因此需要安装pymssql包进行数据采集。
待采集的数据主要为现场的能源数据,除了总能耗外,分别针对风机、照明、水泵等子系统用能情况进行监控,并对环境的温湿度等参数进行实时监控与采集。本文仅对各子系统数据进行汇总与简化分析,以供示范。

2. 数据采集与处理
2.1 数据导入
**
首先导入python针对ms sql server的pymysql包以及数据处理的pandas数据包,按照常规使用pd作为pandas别名。由于物联网系统采用13位数字的时间戳来进行数据时间标示传输,因此需要导入time模块进行数据转换。
import pymssqlimport pandas as pdimport pandas as pdimport timeconn = pymssql.connect(host=’****.aliyuncs.com:3433′,user=’****’,password=’****’,database=’***’,charset=’utf8′)powersql=’SELECT * FROM ***.dbo.***;’ powerdata = pd.read_sql_query(powersql, conn)#读取能耗数据thsql=’SELECT * FROM ***.dbo.***;’ thdata = pd.read_sql_query(thsql, conn)#读取环境数据
2.2 时间戳转换及数据本地保存
要将13位时间戳数据转换为date time的数据格式,需要使用python time库中几个函数,需要注意的是,这里转换的时间格式,对pandas来说仍然只是时间形式的字符串,要真正当作日期时间使用,在后续需要再处理加工一次。
- time.localtime(x*0.001) 将13位数据时间戳(除以1000以转换为以秒为单位)转换为本地时间。
- 通过time.strftime(“%Y-%m-%d %H:%M:%S”, x)将时间格式化为易读的格式
- 在本例子中,使用了python中的lambda匿名函数用于数据的快速处理
- 为了对整列数据进行处理,使用了python中的map函数,针对pandas整列数据进行处理。
- 由于部分原始数据缺失,使用了fillna函数进行了简单的补0处理,当然也可以采用弃用或者其他形式。
- 使用了pandas的 to_csv函数进行了数据的本地化保存,以免每次处理都需要进行数据库读取。
powerdata[‘gmtCreate’] = powerdata[‘gmtCreate’].\map(lambda x: time.strftime(“%Y-%m-%d %H:%M:%S”,time.localtime(x*0.001)))thdata[‘gmtCreate’] = thdata[‘gmtCreate’].map(lambda x: time.strftime(“%Y-%m-%d %H:%M:%S”,time.localtime(x*0.001)))powerdata.fillna(0, inplace=True) #将缺值替换为0,以供数据处理thdata.fillna(0,inplace=True) #将缺值替换为0,以供数据处理powerdata.to_csv(“powerdata.csv”) thdata.to_csv(“thdata.csv”)
2.3 数据处理与汇总
#与数据计算相关常量参数voltage=0.23phases=3dayscycle=7
为了简化处理,本案例读取本日之前7天(一周)能耗进行分析,并简化针对每个设备的分析,而是将数据分类汇总。
- 采用df.loc[filter]结合过滤器的方式对数据进行切片
- 过滤器为(powerdata[‘gmtCreate’]>=startday) & (powerdata[‘gmtCreate’]<=today)
#取得今天的时间today=time.strftime(“%Y-%m-%d 00:00:00”,time.localtime(time.time()))#取得七天前的时间startday=time.strftime(“%Y-%m-%d 00:00:00”,time.localtime(time.time()-dayscycle*3600*24))#截取前后段之间的数据 powerdata=powerdata.loc[(powerdata[‘gmtCreate’]>=startday) & (powerdata[‘gmtCreate’]<=today)]thdata=thdata.loc[(thdata[‘gmtCreate’]>=startday) & (thdata[‘gmtCreate’]<=today)]
上述采取的方法比较简单粗糙,主要用于说明,在后文中会采用一种更优雅的方式处理数据。即先将时间字符串转换为pandas的dataframe中日期时间然后之间选择操作。在时间截取后对数据进行汇总和整理。
- 利用了列直接相加的方式生成新的列
- 利用drop方法弃用废弃列以优化数据
- 利用pandas的to_datetime方法将时间字符串转换为日期时间格式
- 利用set_index方法将默认的数字编号索引修改为以日期时间为索引
powerdata[‘totalpower’]=(powerdata[‘h47’]+powerdata[‘h48’]+powerdata[‘h49’])*voltage #实时总功率powerdata[‘maintain’]=(powerdata[‘h35’]+powerdata[‘h36’]+powerdata[‘h37’])*voltage*phases #检修系统实时功率#…省略其他类似内容powerdata=powerdata.drop([‘iotId’,’h32′,’h33′,’h34′,’h35′, ‘h36′,’h37′,’h38′,’h39’, ‘h3A’,’h3B’,’h3C’,’h3D’,’h3E’,’h3F’,’h40′,’h41′,’h42′,‘h43′,’h44′,’h45′,’h46’, ‘h47′,’h48′,’h49’], axis=1)powerdata[‘gmtCreate’] = pd.to_datetime(powerdata[‘gmtCreate’])thdata[‘gmtCreate’] = pd.to_datetime(thdata[‘gmtCreate’])powerdata.set_index(“gmtCreate”, inplace=True)thdata.set_index(“gmtCreate”, inplace=True)
整理后的数据示意如下: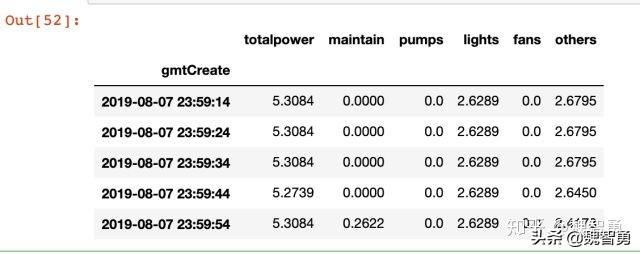
3. 数据分析与可视化
在整理之后对数据进行简单的分析与可视化。
- 采用matplotlib的pyplot来画图
- 采用Jupyter notebook的魔术方法%matplotlib inline 在文件内画图
- 在将日期时间格式化后,采用了powerdata.index.floor(‘H’)方法快速按照小时取平均值,将H改为M,D等可以切换单位
- 采用groupby方式分类汇总并通过mean快速取每小时平均值,进一步简化数据,如果要求和则用sum
import matplotlib.pyplot as plt%matplotlib inline powerdata=powerdata.groupby(powerdata.index.floor(‘H’)).mean()thdata=thdata.groupby(thdata.index.floor(‘H’)).mean()
实时能耗图说明。可以看出,用户用能具备明显规律性,出现显著的典型用能尖峰,这是由于用户目前各子系统运行为人工开启,运维人员同时开启各个子系统导致的用能尖峰。
- – totalpower 实时总功耗
- – maintain 检修系统功耗
- – pumps 水泵系统功耗
- – lights 照明系统功耗
- – fans 排风系统功耗
- – others 其他(消防,控制等系统功耗)
powerdata.plot.line(figsize=(16,12),title=’Real Time Energy Cost’)plt.show()
通过figsize参数指定画布大小,通过title指定表名。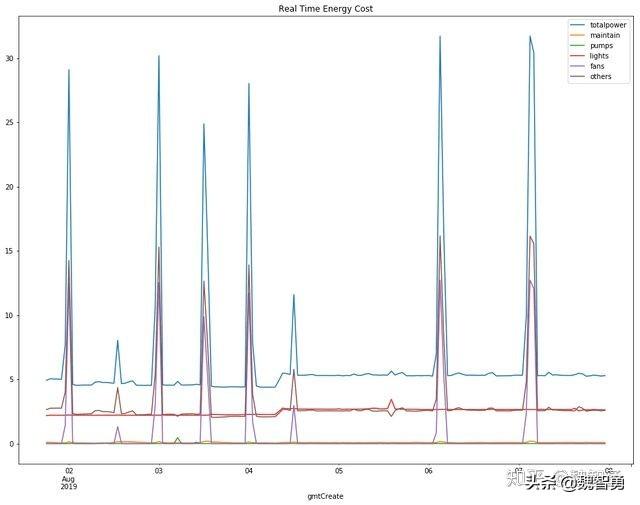
作为补充,截取一天的用能数据生成典型日用能详图。powerdata.loc[(powerdata.index>=’2019-08-06 00:00:00′)&(powerdata.\index<=’2019-08-06 23:59:59′)].plot.line(figsize=(16,12),title=’Typical Day’)plt.show()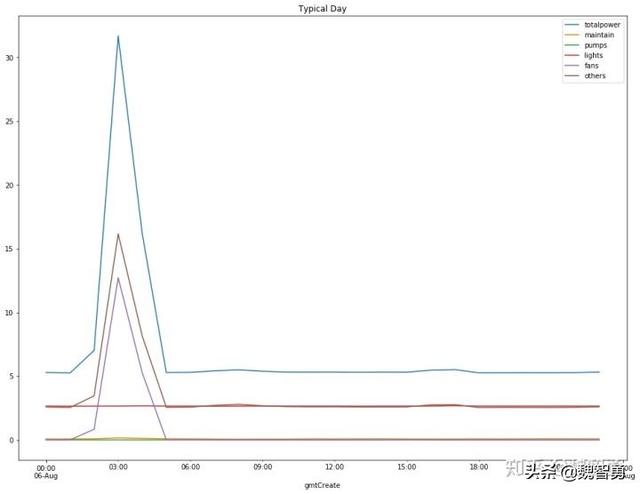
常用的曲线除了曲线图外,还有柱状图,以下两张分别为按日和汇总的用能分类图。powerdata.groupby(powerdata.index.floor(‘D’)).sum().plot.bar(figsize=(16,12),title=’Daily Energy Cost’) plt.show()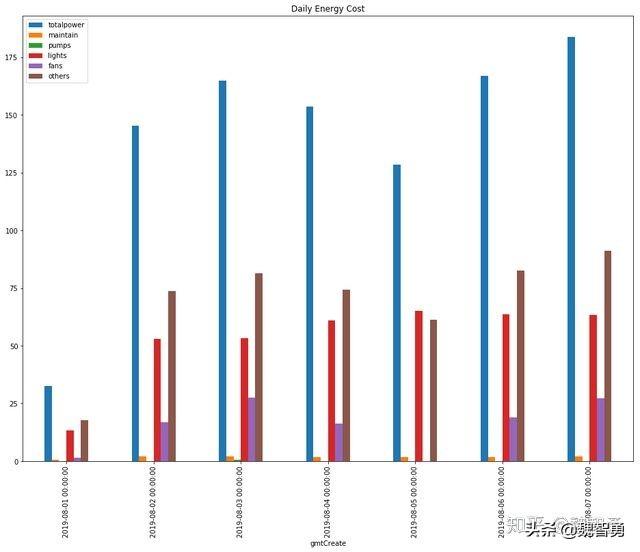
powerdata.sum().plot.bar(figsize=(16,12),title=’Total Energy Cost’) plt.show()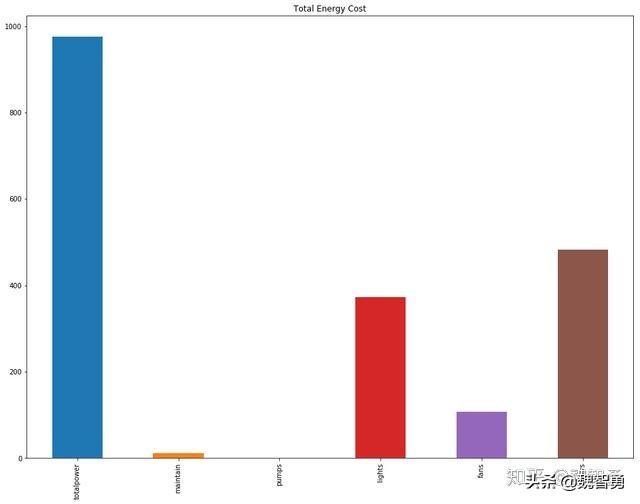
最后,对用户用能的具体数据进行简单汇总。print(‘上周总用能约为 %.2f kWh.’%powerdata[‘totalpower’].sum())print(‘其中:’) print(‘检修子系统用能约 %.2f kWh,’%powerdata[‘maintain’].sum())print(‘水泵子系统用能约 %.2f kWh,’%powerdata[‘pumps’].sum())print(‘照明子系统用能约 %.2f kWh,’%powerdata[‘lights’].sum())print(‘通风子系统用能约 %.2f kWh,’%powerdata[‘fans’].sum())print(‘消防等其他用能约 %.2f kWh,’%powerdata[‘others’].sum())此外,pandas也内置了简单方便而全面的统计函数describe。powerdata.describe()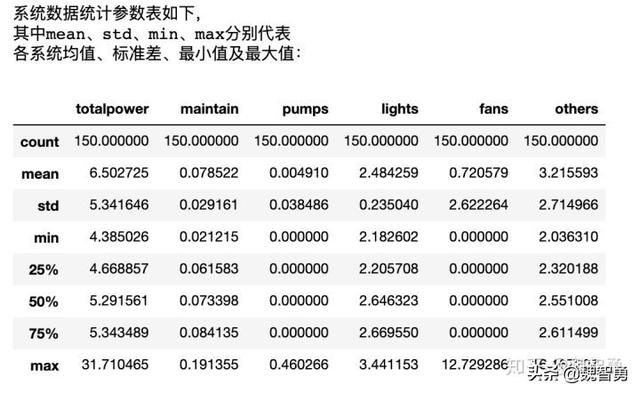
4. 结论与展望
从上述案例可以看出python在数据科学中的一些使用。本案例中使用了约25万条记录的数据量。但对pandas来说,无论是读取、写入和分析都是相当迅速的,最长在几秒钟内即可完成工作,这是使用传统的office套件等完全无法实现的,对海量数据的分析与处理,只能通过数据分析工具才更有效率。
当然,为了简化分析过程,本案例对数据进行了大量的归集与简化,和大部分数据科学工作相似,大部分工作都用于数据的获取、清洗和处理,而在数据规范后可快速进行可视化与进一步处理。当然,本案例的大量简化,在相当程度上导致数据价值的缺失,如果只是做简单的数据可视化处理,更稀疏的数据即可满足使用要求。但如果要进行深度学习与更详细的应用,就需要对数据进行更细致精确的分析与处理,而不止本文的汇总与归集。
本案例可为后续进行机器学习的工作提供基础的数据,通过机器学习的方式,本案例中的数据至少可以起到几方面的作用:
- 结合环境参数,实时能源价格等为系统提供更优化更节约费用的运行方案
- 通过模式学习,自动识别系统中无法通过人工手段发现的隐患与事故并及时报警
- 通过时间序列,对未来的用能情况,系统安全等状况进行预测
- 通过不断的优化,为类似项目建立可供参考的成熟模型
- ……

若有收获,就点个赞吧
0 人点赞
