任务介绍:爬取豆瓣电影TOP250的基本信息,包括名称、评分、评价数、链接、简介等。
基本流程:
- 准备工作
- 获取数据
- 解析内容
- 保存数据
1. 准备工作:
step1.对豆瓣网址URL进行分析。
- 豆瓣电影一共分为10页,每页25条;
- URL的不同之处在于 最后start=(页数-1)*25,如从第二页开始的话,start=25
step2.在Python中引入爬虫常用模组。
from bs4 import BeautifulSoup # 网页解析获取数据import re # 正则表达式,文字匹配import urllib.request,urllib.error # 制定URL,获取网页数据import xlwt # 进行Excel操作
2. 获取数据。
step1:主程序
主程序相关函数分为两部分 ①定义 ②执行(如图所示)
主程序即为语句执行时的大框架(提纲),需要对其中的函数进行定义
就本例而言,需要拓展定义的函数有
①askURL-访问网址获取 ②getdata(askURL)-解析数据 ③savedata(datalist,savepath)-保存数据
# 对主程序的定义def main(): # 主程序运行print("开始爬取……")baseurl = "https://movie.douban.com/top250?start=" # 基础网址# 1.爬取网页datalist = getdata(baseurl) #(执行定义的getdata函数)savepath = "豆瓣电影TOP250.xls"# 2.解析数据# 3.保存数据savedata(datalist,savepath) # 把数据保存到路径# ……中间部分为主程序中涉及的其他函数的定义……# 主程序调用——执行if __name__ == '__main__': # 当程序执行时main() # 调用函数print("爬取完毕")
step2:访问申请
Python一般使用urllib2库获取数据
打开开发者模式(键盘按下F12)点击 Network (网络),然后刷新界面。点击第一条,在消息头最后一行为用户代理信息。(如图)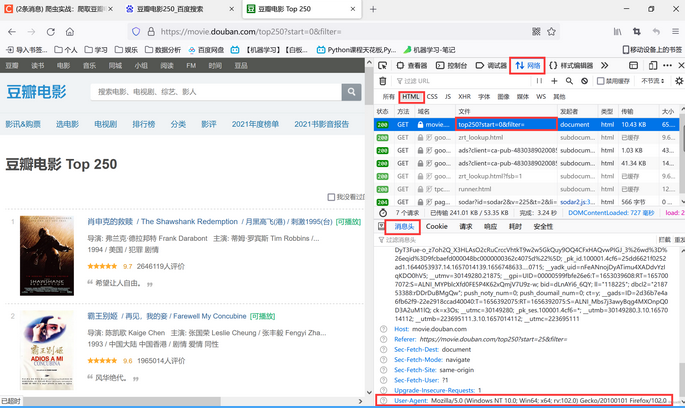
代码实现:
对于每一个页面,调用askURL函数获取页面内容。
- 定义获取页面的函数askURL,传入URL参数:”https://movie.douban.com/top250?start=“
- urllib2.Request生成请求;urllib2.urlopen发送请求获取响应;urllib2.read获取页面内容
- 在访问页面经常会出现错误,未来程序正常运行,加入异常捕获 try…except…语句
主要包括:①模拟头部信息 ②发送请求 ③异常捕获 try…except…
def askurl(url):head = { # 模拟浏览器头部信息,向豆瓣服务器发送消息"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0"}# 用户代理:告诉豆瓣服务器我们是什么类型的机器·浏览器(本质上我们可以接受什么水平的内容)request = urllib.request.Request(url,headers=head) # request:发送请求html = ""try:response = urllib.request.urlopen(request) # urlopen:发送请求,取得响应html = response.read().decode("utf-8") # read:获取网页内容;UTF-8是一种编码格式,一个字节包含8个比特。#print(html)except urllib.error.URLError as e:if hasattr(e,"code"):print(e.code)if hasattr(e,"reason"):print(e.reason)return html #
step3. 爬取网页
在主程序中已经定义基础网址baseURL,通过for循环,在baseURL上加码,可重复执行askURL函数(不断进行访问申请以及保存网页编码-html)
def getdata(baseurl):datalist = []for i in range(0,10): # 调用获取页面信息的函数.10次url = baseurl + str(i*25)html = askurl(url) # 保存获取到的网页编码(执行定义的askURL函数)# ……中间一系列数据解析……print(datalist) # 测试查看电影提取信息-OKreturn datalist
3.数据解析
在上文2.3提及的for循环内部,对获取的每个网页逐一解析。
step1. 逐一爬取网页存档soup,使用BeautifulSoup定位特定的标签位置
通过 BeautifulSoup(html, ‘html.parser’) 函数完成。
注意:前一个参数html是被解析的网页对象,后一个参数是解析器名称,我们用 html.parser 这个解析器进行解析,并将解析结果赋值给 soup 对象。此时 soup 存放的是一整个网页的内容,里面有25个电影的信息。所以我们还需要再嵌套一个循环,将25个电影逐一进行爬取。
# 2.逐一解析数据soup = BeautifulSoup(html, "html.parser")for item in soup.find_all('div', class_="item"): # 查找符合要求的字符串(每一个影片),形成列表(注意class下面下划线)#print(item) # 测试查看电影全部信息-OKdata = [] # 保存一部电影的全部信息item = str(item)
BeautifulSoup 模块就是将 html 网页内容转化成一个复杂的树形结构。主要有以下四种: Tag 标签及其内容 Navigablestring #标签里的内容,字符串 BeautifulSoup #输出整个文档 comment #特殊的Navigablestring,输出的内容不包含注释符号
step2. 逐一获取想要的标签,使用正则表达式找到具体的内容
当你打开浏览器的开发者模式后,点击小箭头,然后点击你想定位的内容,就能定位到相关标签。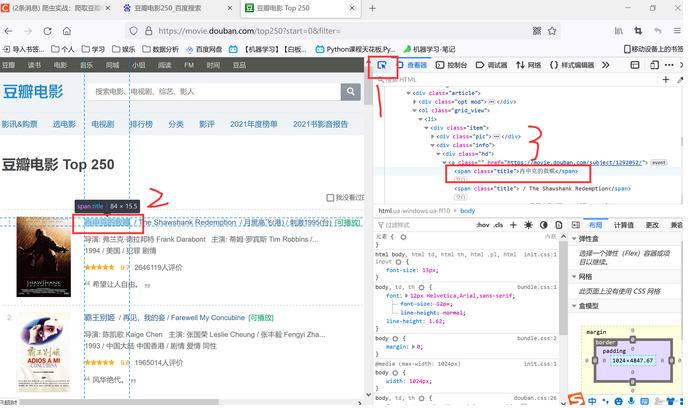
使用正则表达式找到具体的内容
①在主函数定义下,创建正则表达式对象表示规则:
# 影片详情链接的规则findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,表示规则(字符串的形式);r表示忽视所有的特殊符号# 影片图片 # (.*?)表示引号里面任意形式findImgSrc = re.compile(r'<img.*src="(.*?)"',re.S) # re.s让换行符包含在字符中findTitle = re.compile(r'<span class="title">(.*?)</span>') # 影片片名findRating = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>') # 影片评分findJudge = re.compile(r'<span>(\d*)(.*?)</span>') # 评价人数findInq = re.compile(r'<span class="inq">(.*?)</span>') # 一句话评价findBd = re.compile(r'<p class="">(.*?)</p>',re.S) # 简介-忽视换行符
② 在3.1的soup后的for循环下,给data列表逐一赋值
——获取影片详情的链接
#名字Titles = re.findall(findTitle, item) # 片名可能只有一个中文名了,没有外文名if(len(Titles) == 2 ):ctitle = Titles[0]data.append(ctitle) # 添加中文名otitle = Titles[1].replace("/","") # 去掉无关的负号otitle = Titles[1].replace('\xa0/\xa0', '')data.append(otitle) # 添加外国名else:data.append(Titles[0])data.append(" ") # 外国名字留空
——影片评分
Rating = re.findall(findRating, item)[0]data.append(Rating)JudgeNum = re.findall(findJudge, item)[0]data.append(JudgeNum)
——影片一句话评价
Rating = re.findall(findRating, item)[0]data.append(Rating)JudgeNum = re.findall(findJudge, item)[0]data.append(JudgeNum)
——影片简介
Bd = re.findall(findBd, item)[0]Bd = re.sub('<br(\s+)?/>(\s+)?'," ",Bd) # 去掉<br/>:了解正则表达式的含义Bd = re.sub('/', " ", Bd) # 去掉/线Bd = re.sub('\xa0', " ", Bd)data.append(Bd.strip()) # 去掉前后的空格
③ 将处理好的一部电影信息输入datalist
datalist.append(data) #将处理好的一部电影信息输入datalist
- 保存数据到Excel
step1. 创建Excel
def savedata(datalist,savepath):print("save……")book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象sheet = book.add_sheet('豆瓣电影250',cell_overwrite_ok = True) # 创建表单
step2. 在表中输入标题
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")for i in range(0,8):sheet.write(0,i,col[i]) # 列名
step3. 在表中输入之前爬取的数据(for循环)
for i in range(0,250):print("第%d条" %i) #放入打印的条数data = datalist[i]for j in range(0,8):sheet.write(i+1,j,data[j]) # 数据
step4. 保存文件
book.save('豆瓣电影TOP250.xls') # 保存数据表
5.完整代码复现
from bs4 import BeautifulSoup # 网页解析获取数据import re # 正则表达式,文字匹配import urllib.request,urllib.error # 制定URL,获取网页数据import xlwt # 进行Excel操作import sqlite3 # 进行sqlite操作def main(): # 主程序运行print("开始爬取……")baseurl = "https://movie.douban.com/top250?start=" # 基础网址# 1.爬取网页datalist = getdata(baseurl) #(执行定义的getdata函数)savepath = "豆瓣电影TOP250.xls"# 2.解析数据# 3.保存数据savedata(datalist,savepath) # 把数据保存到路径#askurl("https://movie.douban.com/top250?start=") # 测试爬取第一页数据# 影片详情链接的规则findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,表示规则(字符串的形式);r表示忽视所有的特殊符号# 影片图片 # (.*?)表示引号里面任意形式findImgSrc = re.compile(r'<img.*src="(.*?)"',re.S) # re.s让换行符包含在字符中findTitle = re.compile(r'<span class="title">(.*?)</span>') # 影片片名findRating = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>') # 影片评分findJudge = re.compile(r'<span>(\d*)(.*?)</span>') # 评价人数findInq = re.compile(r'<span class="inq">(.*?)</span>') # 一句话评价findBd = re.compile(r'<p class="">(.*?)</p>',re.S) # 简介-忽视换行符# 1.爬取网页def getdata(baseurl):datalist = []for i in range(0,10): # 调用获取页面信息的函数.10次url = baseurl + str(i*25)html = askurl(url) # 保存获取到的网页编码(执行定义的askURL函数)# 2.逐一解析数据soup = BeautifulSoup(html, "html.parser")for item in soup.find_all('div', class_="item"): # 查找符合要求的字符串(每一个影片),形成列表(注意class下面下划线)#print(item) # 测试查看电影全部信息-OKdata = [] # 保存一部电影的全部信息item = str(item)# 获取影片详情的连接link = re.findall(findLink,item)[0] # re库用来通过正则表达式查找指定的字符data.append(link)imgSrc = re.findall(findImgSrc,item)[0] # 图片链接data.append(imgSrc)#名字Titles = re.findall(findTitle, item) # 片名可能只有一个中文名了,没有外文名if(len(Titles) == 2 ):ctitle = Titles[0]data.append(ctitle) # 添加中文名otitle = Titles[1].replace("/","") # 去掉无关的负号otitle = Titles[1].replace('\xa0/\xa0', '')data.append(otitle) # 添加外国名else:data.append(Titles[0])data.append(" ") # 外国名字留空Rating = re.findall(findRating, item)[0]data.append(Rating)JudgeNum = re.findall(findJudge, item)[0]data.append(JudgeNum)Inq = re.findall(findInq, item)if len(Inq) != 0 :Inq = Inq[0].replace(".","") # 去掉句号data.append(Inq)else:data.append(" ")Bd = re.findall(findBd, item)[0]Bd = re.sub('<br(\s+)?/>(\s+)?'," ",Bd) # 去掉<br/>:了解正则表达式的含义Bd = re.sub('/', " ", Bd) # 去掉/线Bd = re.sub('\xa0', " ", Bd)data.append(Bd.strip()) # 去掉前后的空格datalist.append(data) #将处理好的一部电影信息输入datalistprint(datalist) # 测试查看电影提取信息-OKreturn datalist# 得到指定一个URL的网页内容;利用askURL函数调取网页内容def askurl(url):head = { # 模拟浏览器头部信息,向豆瓣服务器发送消息"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0"}# 用户代理:告诉豆瓣服务器我们是什么类型的机器·浏览器(本质上我们可以接受什么水平的内容)request = urllib.request.Request(url,headers=head) # request:发送请求html = ""try:response = urllib.request.urlopen(request) # urlopen:发送请求,取得响应html = response.read().decode("utf-8") # read:获取网页内容;UTF-8是一种编码格式,一个字节包含8个比特。#print(html)except urllib.error.URLError as e:if hasattr(e,"code"):print(e.code)if hasattr(e,"reason"):print(e.reason)return html ## 3.保存数据def savedata(datalist,savepath):print("save……")book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象sheet = book.add_sheet('豆瓣电影250',cell_overwrite_ok = True) # 创建表单col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")for i in range(0,8):sheet.write(0,i,col[i]) # 列名for i in range(0,250):print("第%d条" %i) #放入打印的条数data = datalist[i]for j in range(0,8):sheet.write(i+1,j,data[j]) # 数据book.save('豆瓣电影TOP250.xls') # 保存数据表if __name__ == '__main__': # 当程序执行时# 调用函数main()print("爬取完毕")

若有收获,就点个赞吧
0 人点赞
