
typora-copy-images-to: 大数据技术栈实践私教级教程-13.Flink typora-root-url: 大数据技术栈实践私教级教程-13.Flink
Flink概述
Flink是什么
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。
国内使用Flink的企业

为什么选择Flink
- 流数据更真实的反应了我们的生活方式
- 传统的数据架构是基于有限数据集的
我们的数据
电商和市场营销
- 数据报表、广告投放、业务流程需要
- 物联网
- 传感器实时数据的采集和显示、实时报警
- 电信
- 基站流量调配
银行金融
事务处理架构
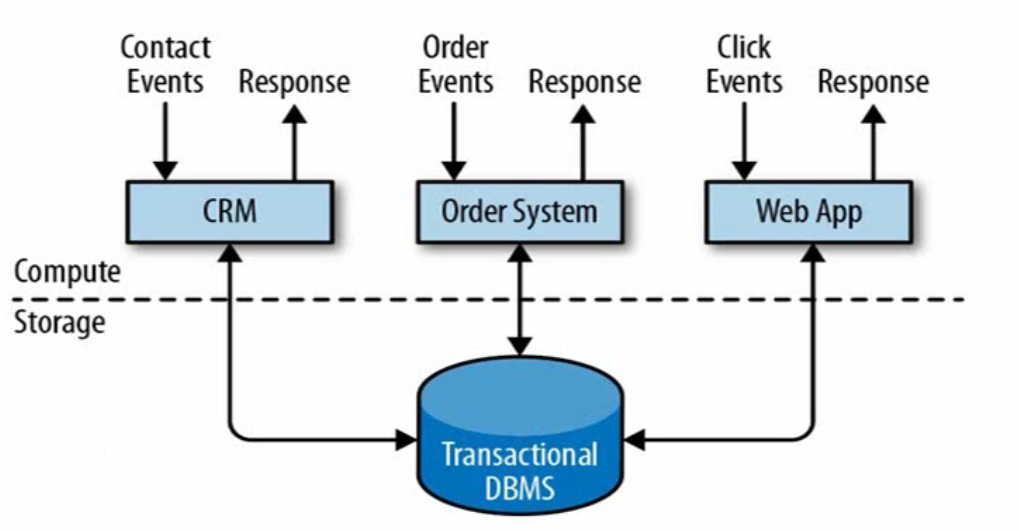
特点是:实时性很好,但是能够同时处理的数据有限
- 分析处理架构

将数据从业务数据库复制到数仓,再进行分析和查询
特点:从不同地方提取数据,处理海量数据。过程很慢。
第一代流处理器(Strom)
将事务处理架构和分析处理架构进行结合,事务数据不需要放在关系型数据库放在本地内存里面,把数据保存为本地状态,结合状态做计算,状态自身根据需要进行更新。对本地内存进行周期性检查存储在硬盘。这样可以做到低延迟高吞吐还具有良好的可扩展性。
第一代流处理器就是这么设计的,但是有个问题就是不能满足数据的有序性。
第二代流处理器Lambda架构
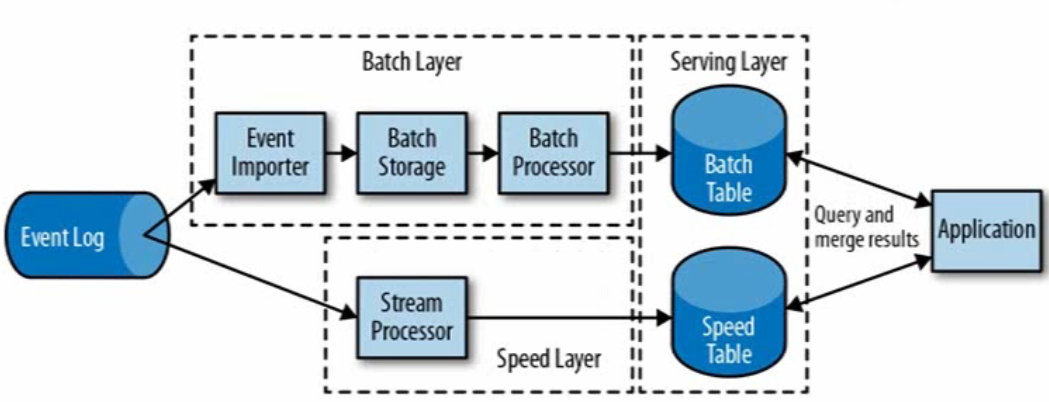
用两套系统(流处理、批处理),同时保证低延迟和结果准确。先快速得到一个近似结果(流处理),最后给出一个精准结果(批处理)。
问题是实现一个需求就需要实现和维护两个系统。
第三代流处理器架构
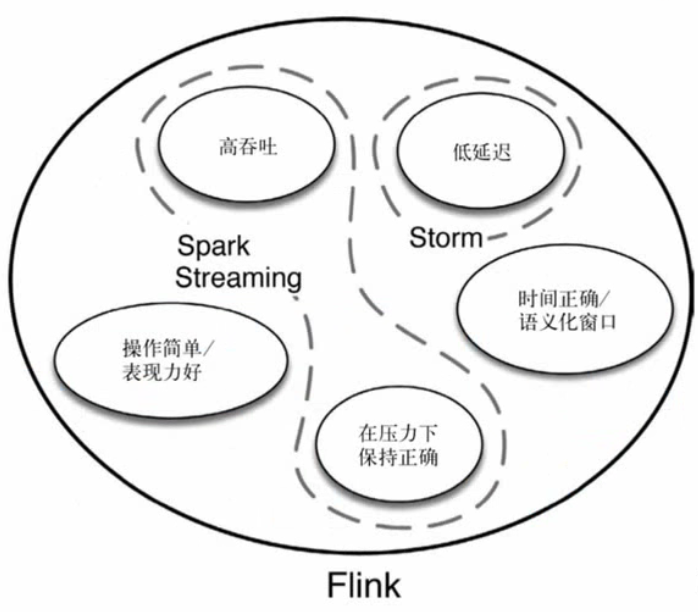
Flink的主要特点
事件驱动
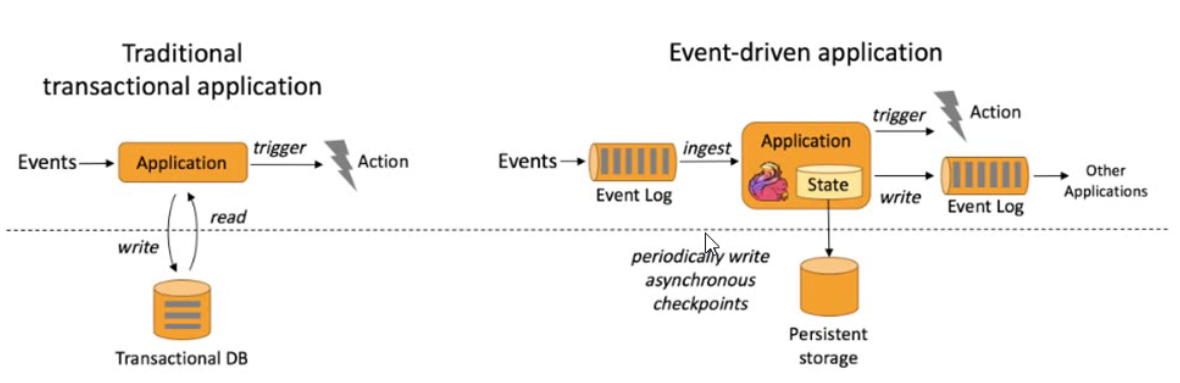
基于流的世界观
在Flink的世界中,一切都是由流组成的,离线数据是有界流,实时数据是无界流。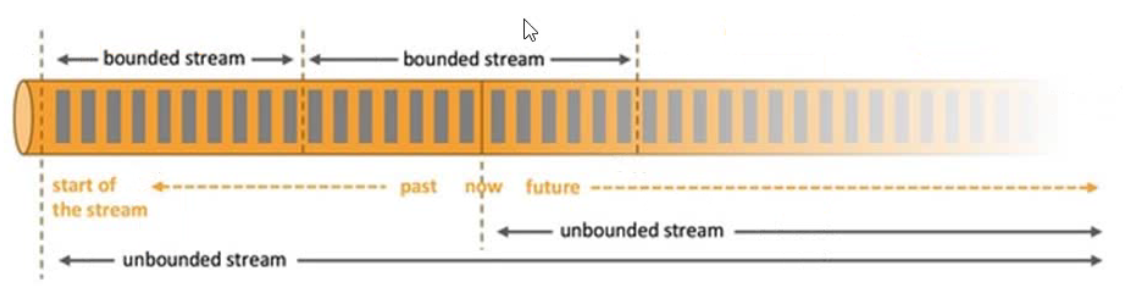
分层API
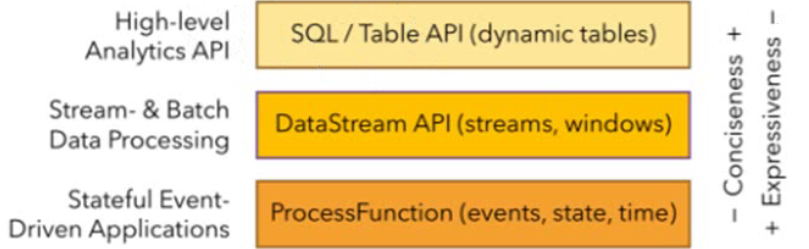
- 越顶层越抽象,表达含义越简明,使用越方便
-
其他特点
支持事件时间(event-time)和处理时间(processing-time)语义
- 精确一次(exactly-once)的状态一致性保证
- 低延迟,每秒处理数百万个事件,毫秒级延迟
- 与众多常用存储系统的连接
-
Flink VS SparkStreaming
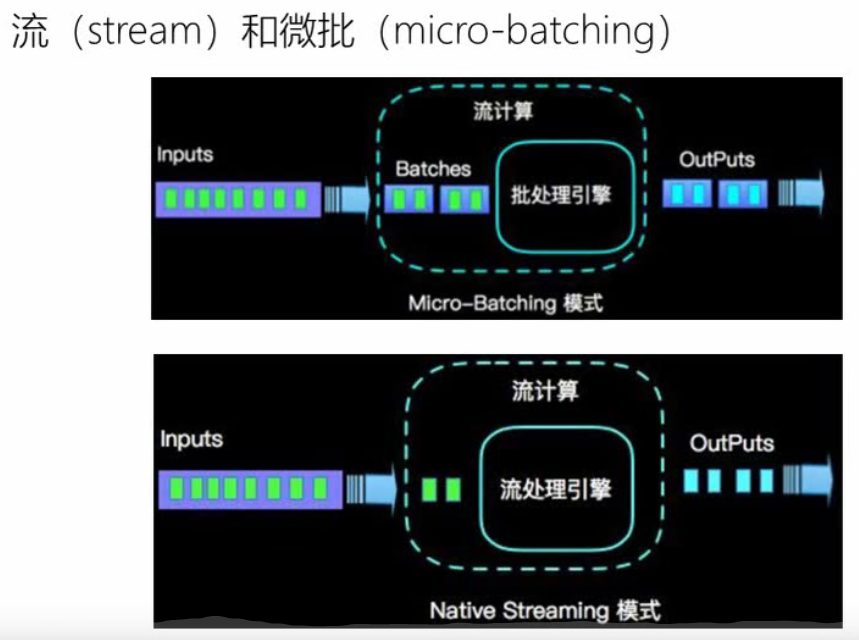
数据模型
- spark采用RDD模型,spark streaming的DStream实际上也就是一组组小批数据RDD的集合
- flink基本数据模型是数据流,以及事件(Event)序列
运行架构
pom文件
<dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.10.1</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.12</artifactId><version>1.10.1</version></dependency></dependencies>
WordCount
public class WordCount { public static void main(String[] args) throws Exception { // 创建执行环境 ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); // 从文件读取数据 String inputPath = "E:\\坚果云同步\\我的坚果云\\大数据\\尚硅谷系列博客\\代码\\flink\\src\\main\\resources\\hello.txt"; DataSource<String> inputDataSet = env.readTextFile(inputPath); // 对数据集进行处理,按照空格隔开 AggregateOperator<Tuple2<String, Integer>> result = inputDataSet.flatMap(new MyFlatMapper()) // 按照第一个位置的word分组 .groupBy(0) // 按照第二个位置上的数据求和 .sum(1); result.print(); } public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception { // 按空格分词 String[] words = s.split(" "); for (String word : words) { collector.collect(new Tuple2<>(word, 1)); } } } }hello.txt
hello 1 hello 2 hello 3 hello 4 hello 5 hello 6 hello 7 hello 8执行结果

流处理开发(有界)
pom
<dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.10.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.12</artifactId> <version>1.10.1</version> </dependency> </dependencies>StreamWordCount ```java public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 创建流处理执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 设置并行数 env.setParallelism(1); // 从文件读取数据 String inputPath = "E:\\坚果云同步\\我的坚果云\\大数据\\尚硅谷系列博客\\代码\\flink\\src\\main\\resources\\hello.txt"; DataStreamSource<String> inputDataSet = env.readTextFile(inputPath); // 从socket读取文本流数据 //DataStreamSource<String> inputDataSet = env.socketTextStream("127.0.0.1", 7777); // 基于数据流进行转换计算 SingleOutputStreamOperator<Tuple2<String, Integer>> result = inputDataSet.flatMap(new MyFlatMapper()) // 按照第一个位置的word分组 .keyBy(0) // 按照第二个位置上的数据求和 .sum(1); result.print(); // 执行任务 env.execute("开始执行");}
public static class MyFlatMapper implements FlatMapFunction
@Override public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception { // 按空格分词 String[] words = s.split(" "); for (String word : words) { collector.collect(new Tuple2<>(word, 1)); } }}
}
- 执行结果
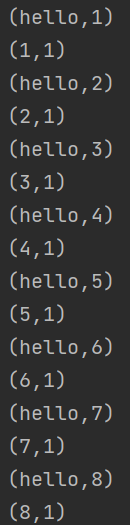
<a name="lteT0"></a>
## 流处理开发(无界)
连接127.0.0.1的7777端口获取数据。
```java
final ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
int port = parameterTool.getInt("port");
DataStreamSource<String> inputDataSet = env.socketTextStream(host,port);
Flink部署
下载地址:Index of /dist/flink/flink-1.10.1 (apache.org)
版本选择:1.10.1
tar -xvzf flink-1.10.1-bin-scala_2.12.tgz -C /opt/module/
Standalone模式
- 配置flink-conf.yaml ```java jobmanager.rpc.address: localhost
jobmanager.rpc.port: 6123
jobmanager.heap.size: 1024m
taskmanager.memory.process.size: 1728m
表示1个TaskManager节点只有1个槽位,只有1个线程池。代表了并行最大的能力
taskmanager.numberOfTaskSlots: 1
默认并行度,真实执行时候执行的线程数量
parallelism.default: 1
- 修改flink-conf.yaml
`jobmanager.rpc.address: hadoop102 `
- 修改slaves文件
`hadoop103 hadoop104`
- 分发到hadoop103、hadoop104
`xsync /opt/module/flink-1.10.1/`
- 启动集群
`. /opt/module/flink-1.10.1/bin/start-cluster.sh`
- 查看进程
- 查看web
访问hadoop102:8081
<a name="Be5Qj"></a>
## Web提交任务
```java
com.example.wordcount.StreamWordCount
--host hadoop102 --port 7777
hadoop102启动7777端口:nc -l 7777
输入你好 Flink回车
命令行提交任务
- 提交命令 ```cpp ./bin/flink run -c com.example.wordcount.StreamWordCount -p 3 /opt/module/flink-1.10.1/data/flink-1.0-SNAPSHOT.jar —host hadoop102 —port 7777
- 查看job
```java
./bin/flink list ============================ Waiting for response... ------------------ Running/Restarting Jobs ------------------- 04.01.2022 15:39:44 : d9001f548a0bc25fb7201c184cc6e749 : 开始执行 (RUNNING) -------------------------------------------------------------- No scheduled jobs.
- 停止job
./bin/flink cancel d9001f548a0bc25fb7201c184cc6e749 =========================== Cancelling job d9001f548a0bc25fb7201c184cc6e749. Cancelled job d9001f548a0bc25fb7201c184cc6e749.
Slot分配不够处理方式
- 调大集群资源
taskmanager.numberOfTaskSlots = 4
-
Yarn模式
以Yarn模式部署Flink时候,要求Flink是由Hadoop支持的版本,Hadoop环境要求保证版本在2.2以上,并且集群中安装由HDFS服务。
Flink提供了两种yarn上运行的模式,分别为Session-Cluster和Per-Job-Cluster模式。Session-Cluster模式
Session-Cluster模式需要先启动集群,然后再提交作业,接着会向yarn申请一些空间后,资源保持不变。如果资源满了,写一个作业无法提交,只能等到yarn中其中一个作业执行完毕后,释放资源,下个作业才能正常提交。所有作业共享Dispatcher和ResourceManager;共享资源;适合规模小执行时间短的作业。
在yarn中初始化一个flink集群,开辟指定的资源,以后提交任务都是向这里提交,这个flink集群会常驻在yarn集群中,除非手动停止。创建Session
启动Hadoop集群
- 启动yarn-session
./yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
-n(—container): TaskManager的数量,不指定的话,动态分配,根据yarn的资源决定上限。
-s(—slot):每个TaskManager的slot数量,默认一个slot一个core,默认每个taskManager的slot个数为1,有时可以多一些taskManager,做冗余。
-jm:JobManager的内存
-tm:TaskManager的内存
-nm:yarn的appManager(yarn的ui上的名字)
执行任务
Flink创建了yarn的Session,提交的任务默认在Session上执行。没有yarn的Session,找Standalone默认的集群。
./bin/flink run -c com.example.wordcount.StreamWordCount -p 3 /opt/module/flink-1.10.1/data/flink-1.0-SNAPSHOT.jar —host hadoop102 —port 7777
取消Session
yarn application —kill application_1212313123123121_0001
Per-Job-Cluster模式
一个Job会对应一个集群,每提交一个作业会根据自身情况,都会单独向yarn申请资源,申请作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和ResourceManager;按需要接收资源申请;适合规模大长时间运行的作业。
每次提交都会创建一个新的Flink集群,任务之间相互独立,互补影响,方便管理。任务执行完成之后创建的集群也会消失。
启动Hadoop集群
不启动Session,直接执行job(添加-m yarm-cluster)
./bin/flink run -m yarm-cluster -c com.example.wordcount.StreamWordCount -p 3 /opt/module/flink-1.10.1/data/flink-1.0-SNAPSHOT.jar —host hadoop102 —port 7777
Flink架构
Flink运行时组件
- JobManager作业管理器
- 控制一个应用程序的主进程,每一个应用程序都被不同的JobManager所控制执行
- 会先接收要执行的应用程序,这个应用程序包括:作业图JobGraph,逻辑数据流图logical dataflow graph和打包了多有类、库和其他资源的jar包
- JobManager会把所有的JobGraph转换成一个物理层面的数据流图,这个图被叫做“执行图”,包含了所有可以并发执行的任务
- JobManager会向ResourceManager请求执行任务需要的资源,也就是任务管理器上的slot,一旦获取到了足够的slot,就会将执行图分发到真正运行他们的TaskManager上。运行过程中,JobManager会负责所有需要中央协调的操作,比如 检查点的协调
- TaskManager任务管理器
- Flink的工作进程,通常在Flink中会有多个TaskManager的运行,每一个TaskManager都包含了一定数量的Slot。Slot的数量限制了TaskManager能够执行的任务数量。
- 启动之后,TaskManager会将资源管理器注册到他的插槽,收到资源管理器的指令后,TaskManager会将一个或者多个插槽提供给JobManager调用。JobManager就可以向插槽分配任务来执行。
- 在执行过程中,一个TaskManager可以根据其他运行同一应用程序的TaskManager交换数据。
- ResourceManager资源管理器
- 主要负责管理任务管理器的slot,TaskManager插槽是Flink中定义的处理资源单元
- Flink为不同环境和资源管理工具提供了不同的资源管理器,比如yarn、Mesos、K8s以及Standalone部署
- 当JobManager申请插槽资源时,ResourceManager会将由空闲的插槽的TaskManager分配给JobManager。如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。
Dispacher分发器
怎么实现并行计算
- 设置并行度,拆成几个并行的Task,分配到不同的slot上,多线程执行
- 并行的任务,需要占用多少slot
- 在代码中和提交任务-p参数时候都可以设置并行度。
- 并行度:当前算子的子任务的个数被称为并行度。
- 一个stream的并行度取决于所有算子中最大的并行度。
- 一个流处理程序,到底包含多少个任务
- Flink中每一个TaskManager都是一个JVM进程,独立运行一个或多个子任务
- 为了控制一个TaskManager能够接收多少个Task,TaskManager通过task slot来进行控制。
- 默认情况下,Flink允许子任务共享slot,即便他们是不同任务的子任务,这样的结果是一个slot可以保存作业的整个管道。可以通过.slotSharingGroup(“2”);配置不同的共享组,不同的共享组一定占用不同的slot。
- Task slot是静态的概念,是指TaskManager具有的并发执行能力。

若有收获,就点个赞吧
0 人点赞
