1. 文件存储格式
- hive支持的存储数据的格式主要有:TEXTFILE、SEQUENCEFILE、ORC、PARQUET
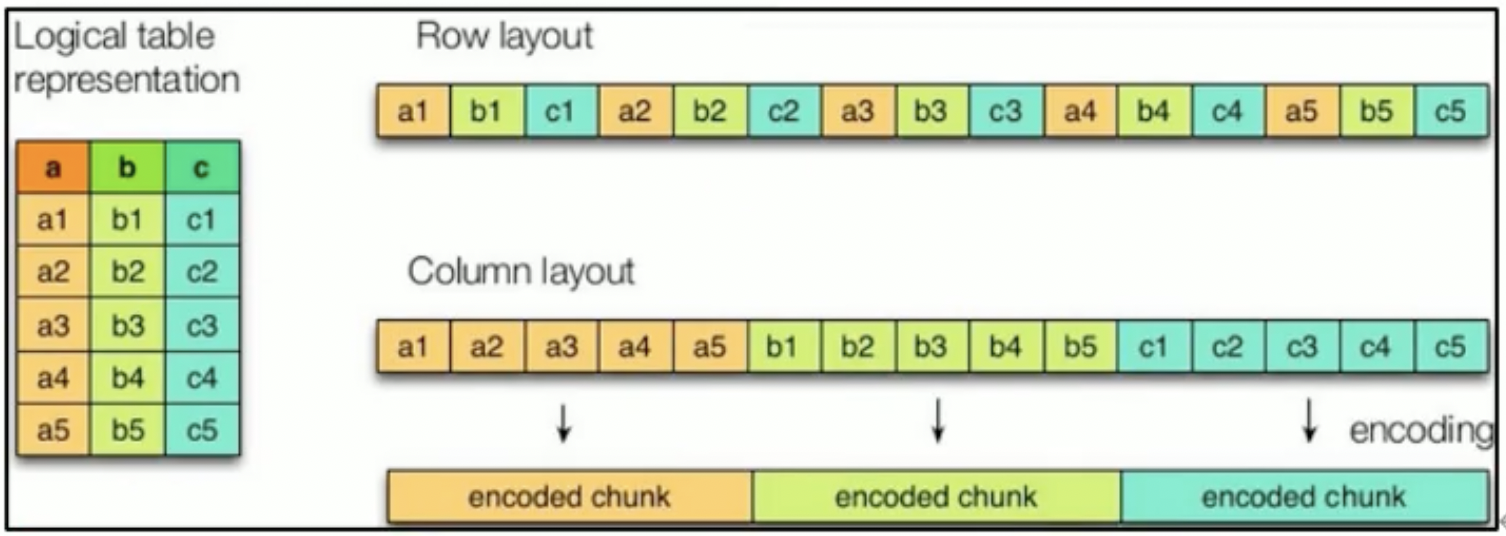
- 基于行存储原理:TEXTFILE、SEQUENCEFILE
- 基于列存储原理:ORC、PARQUET
2. 设置压缩为 Snappy
2.1 执行 task 过程中使用压缩
进入到 hive 客户端就可以操作了。
- 开启 hive 中间传输数据压缩功能
set hive.exec.compress.intermediate=true;
- 开启 mapreduce 中 map 输出压缩功能
set mapreduce.map.output.compress=true;
- 设置 mapreduce 中 map 输出数据的压缩方式
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
- 执行 mr 查询任务
比如:select count(*) from emp;
通过查看历史服务器日志,就能看到启用了压缩,是 [snappy].
2.2 Reduce 输出阶段压缩
进入到 hive 客户端就可以操作了。
- 开启 hive 最终输出数据压缩功能
set hive.exec.compress.output=true;
- 开启 mapreduce 最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
- 设置 mapreduce 最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
- 执行 mr 任务
insert overwrite local directory '/usr/local/hive-3.1.2/dokshare/test/' select * from business;
3. 主流文件存储格式
- hive 默认使用
TEXTFILE格式来存储 - 建表语句中可以加入
sorted as textfile / orc / parquet来指定需要的存储格式 TEXTFILE直接load data的方式就可以导入数据orc和parquet不可以直接 load 数据,因为文件格式与表格式不一致,可以通过insert into ***的方式- 查看表中数据大小:
dfs -du -h /usr/hive/warehourse/***; - 文件存储空间效率:
orc > parquet > textfile -
4. 存储与压缩
指定 orc.compress 可以指定压缩算法(orc + snappy 是主流选择)
create table log_orc_zlib (id int,***) row format delimited fields teminated by ';'sorted by orctblproperties("orc.compress"="ZLIB");

若有收获,就点个赞吧
0 人点赞
