1. 分区
1.1 分区作用
— 导入数据 load data local inpath ‘/usr/local/hive-3.1.2/dokshare/partition1/dept1.data’ into table dept_partition1 partition(day=’2022-04-18’); load data local inpath ‘/usr/local/hive-3.1.2/dokshare/partition1/dept2.data’ into table dept_partition1 partition(day=’2022-04-19’); load data local inpath ‘/usr/local/hive-3.1.2/dokshare/partition1/dept3.data’ into table dept_partition1 partition(day=’2022-04-20’);
<a name="ySab7"></a>### 1.3.2 二级分区```sqlcreate table dept_partition2(deptno int,dname string,loc string)partitioned by (day string, hour string)row format delimited fields terminated by ';';-- 导入数据load data local inpath '/usr/local/hive-3.1.2/dokshare/partition1/dept1.data' into table dept_partition2 partition(day='2022-04-18', hour='11');load data local inpath '/usr/local/hive-3.1.2/dokshare/partition1/dept2.data' into table dept_partition2 partition(day='2022-04-19', hour='11');load data local inpath '/usr/local/hive-3.1.2/dokshare/partition1/dept3.data' into table dept_partition2 partition(day='2022-04-28', hour='12');
1.4 分区表对应的hadoop目录
各分区为一个指定的目录,目录下才是文件
/user/hive/warehouse/dept_partition1/ day=2022-04-18/ dept1.data day=2022-04-19/ dept2.data day=2022-04-20/ dept3.data1.5 HQL
1.5.1 查询
查询上没有区别,但是表中多了一个day字段,用起来和一般字段相同,但是过滤时加入day字段可以过滤出指定分区,不需要全表扫描(很好理解吧) ```sql — 如下两查询结果一样,但是: — 上面的sql只扫描分区 2022-04-18 — 下面的sql会全表扫描 select * from dept_partition1 where day=’2022-04-18’;

select * from dept_partition1 where deptno in (10,20);
<a name="hQfHM"></a>
### 1.5.2 分区操作
<a name="yMq3Q"></a>
#### 1 基本操作
```sql
-- 查看分区表结构
desc formatted dept_partition1;
-- 展示分区
show partitions dept_partition1;
-- 添加分区
alter table dept_partition1
add partition(day='2022-04-21') partition(day='2022-04-22') partition(day='2022-04-23');
-- 删除分区
alter table dept_partition1
drop partition(day='2022-04-22'), partition(day='2022-04-23');
2. 关联分区与目录数据
手动创建目录与文件 /day=2022-04-25/dept1.data 并不能使 hive 添加一个分区和导入数据,这时要产生关联关系,有如下几种做法:
- 修复表
- 添加分区
- load 数据到目录里面(不要先put数据到目录)
```sql
创建目录与文件
hadoop fs -mkdir /user/hive/warehouse/dept_partition1/day=2022-04-25
hadoop fs -put /usr/local/hive-3.1.2/dokshare/partition1/dept1.data /user/hive/warehouse/dept_partition1/day=2022-04-25
— 修复 msck repair table dept_partition1;
— 添加分区 alter table dept_partition1 add partition(day=’2022-04-25’)
— load 数据 load data local inpath ‘/usr/local/hive-3.1.2/dokshare/partition1/dept1.data’ into table dept_partition1 partition(day=’2022-04-25’)
<a name="HGE7Q"></a>
#### 3. 创建动态分区
分区的创建通过导入的数据自动识别。
- insert into 的方式中,分区列在 select 字段的最后
```sql
-- 普通分区表建表语句
create table dept_no_par(dname string, loc string)
partitioned by (deptno int)
row format delimited fields terminated by ';';
-- 设置非严格模式执行动态分区模式
set hive.exec.dynamic.partition.mode=nonstrict;
-- 导入数据
insert into table dept_no_par partition(deptno)
select dnmae,loc,deptno from dept;
-- 导入数据(hive 3.* 不需要指定 “分区” 和 “非严格模式”)
insert into table dept_no_par
select dnmae,loc,deptno from dept;
2. 分桶
2.1 分桶作用
load data local inpath ‘/usr/local/hive-3.1.2/dokshare/stu_buck/stu_buck.data’ into table stu_buck;
```sql
10001;weghp01
10002;weghp02
10003;weghp03
10004;weghp04
10005;weghp05
10006;weghp06
10007;weghp07
10008;weghp08
10009;weghp09
10010;weghp10
10011;weghp11
10012;weghp12
10013;weghp13
10014;weghp14
10015;weghp15
10016;weghp16
2.4 分桶表对应的hadoop目录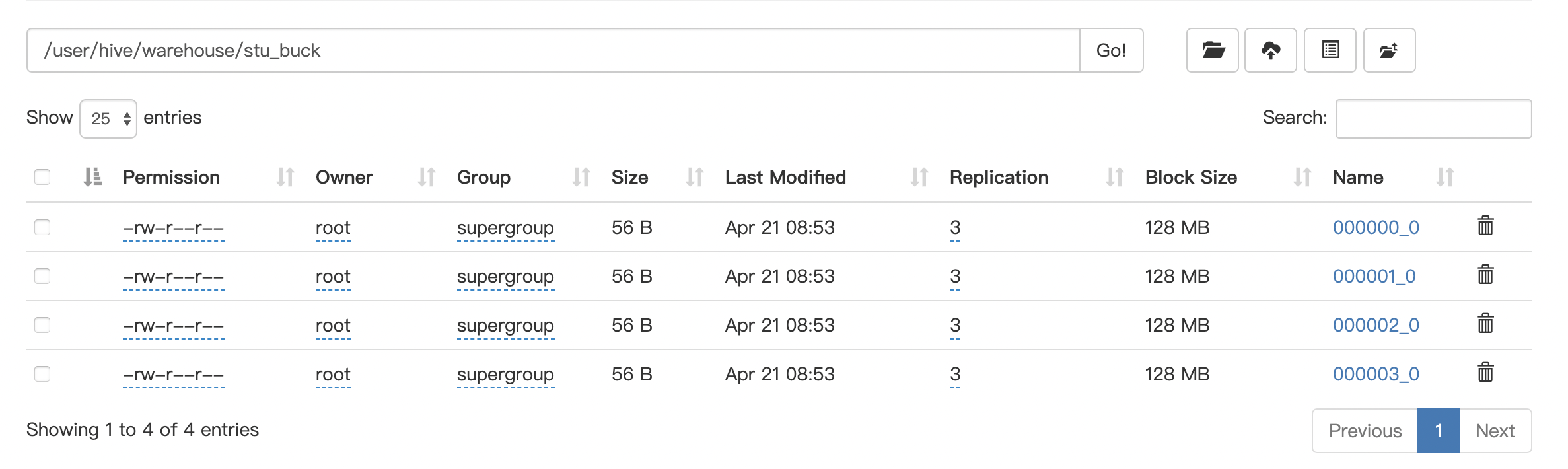

若有收获,就点个赞吧
0 人点赞
