一、正则表达式是用于匹配字符串中字符组合的模式。
二、JavaScript中,正则表达式也是对象。
三、这些模式被用于RegExp的exec和test方法,以及String的match、matchAll、replace、search和split方法。
创建一个正则表达式
一、创建正则表达式的方法:正则表达式字面量、调用RegExp对象的构造函数
正则表达式字面量
一、使用一个正则表达式字面量,其由包含在斜杠之间的模式组成。
var re = /ab+c/
1、脚本加载后,正则表达式字面量就会被编译。
2、当正则表达式保持不变时,使用此方法可获得更好的性能。
调用RegExp对象的构造函数
一、调用RegExp对象的构造函数
var re = new RegExp('ab_c')
1、在脚本运行过程中,用构造函数创建的正则表达式会被编译。
2、如果正则表达式将会改变,或者它将会从用户输入等来源中动态地产生,就需要使用构造函数来创建正则表达式。
编写一个正则表达式的模式
一、一个正则表达式模式是由简单的字符所构成的,比如/abc/,或者是简单和特殊字符的组合,比如/abc/或/Chapter(\d+).\d/。
二、括号()在正则表达式中常用作记忆设备。
使用简单模式
一、简单模式是你想直接找到的字符构成。
二、/abc/这个模式就能且仅能匹配”abc”字符按照顺序同时出现的情况。
【实例1】”Hi, do you know your abc’s” 和”The latest airplane designs evolved from slabcraft”中会匹配成功,匹配的子字符串是”abc”
【实例2】在”Grab crab”中会匹配失败,因为它虽然包含子字符串”ab c”,但并不是准确的”abc”
使用特殊字符
一、当你需要匹配一个不确定的字符串时,比如寻找一个或多个”b”,或者寻找空格,可以再模式中使用特殊字符。
二、可以使用/abc/去匹配一个单独的”a”后面跟了零个或者多个”b”,同时后面跟着”c”的字符串:的意思是前一项出现零次或多次。
【实例1】在字符串”cbbabbbbcdebc”中,这个模式匹配了子字符串”abbbbc”
三、正则表达式中可以利用的特殊字符
| 描述 | |
|---|---|
| 断言(Assertions) | 表示一个匹配在某些条件下发生。 断言包含先行断言、后行断言和条件表达式 |
| 字符串(Character Classes) | 区分不同类型的字符,例如区分字母和数字 |
| 组和范围(Groups and Ranges) | 表示表达式字符的分组和范围 |
| 量词(Quantifiers) | 表示匹配的字符或表达式的数量 |
| Unicode属性转义(Unicode Property Escapes) | 基于unicode字符属性区分字符。例如大写和小写字母、数学符号和标点。 |
三、正则表达式中的特殊字符
| 字符 | 含义 | 实例 | 备注 |
|---|---|---|---|
| \ | 依照下列规则匹配: 一、在非特殊字符之前的反斜杠表示下一个字符是特殊字符,不能按照字面理解。 二、在特殊字符之前的反斜杠表示下一个字符不是特殊字符,应该按照字面理解。 1、如果你想将字符串传递给 RegExp 构造函数,不要忘记在字符串字面量中反斜杠是转义字符。所以为了在模式中添加一个反斜杠,你需要在字符串字面量中转义它。 |
【实例1】 前面没有 “\“ 的 “b” 通常匹配小写字母 “b”,即字符会被作为字面理解,无论它出现在哪里。但如果前面加了 “\“,它将不再匹配任何字符,而是表示一个字符边界 【实例2】 /[a-z]\s/i 和 new RegExp(“[a-z]\\s”, “i”) 创建了相同的正则表达式:一个用于搜索后面紧跟着空白字符(\s 可看后文)并且在 a-z 范围内的任意字符的表达式。为了通过字符串字面量给 RegExp 构造函数创建包含反斜杠的表达式,你需要在字符串级别和正则表达式级别都对它进行转义。例如 /[a-z]:\\/i 和 new RegExp(“[a-z]:\\\\“,”i”) 会创建相同的表达式,即匹配类似 “C:\“ 字符串。 |
详情请参阅下文中的 “转义(Escaping)” 部分 |
| ^ | 一、匹配输入的开始。 二、如果多行标志被设置为 true,那么也匹配换行符后紧跟的位置。 三、当 ‘^’ 作为第一个字符出现在一个字符集合模式时,它将会有不同的含义。 |
【实例1】 /^A/ 并不会匹配 “an A” 中的 ‘A’,但是会匹配 “An E” 中的 ‘A’ |
反向字符集合 一节有详细介绍和示例。 |
| $ | 一、匹配输入的结束。 二、如果多行标志被设置为 true,那么也匹配换行符前的位置。 |
【实例1】 /t$/ 并不会匹配 “eater” 中的 ‘t’,但是会匹配 “eat” 中的 ‘t’ |
|
| * | 匹配前一个表达式 0 次或多次。等价于 {0,}。 | /bo*/ 会匹配 “A ghost boooooed” 中的 ‘booooo’ 和 “A bird warbled” 中的 ‘b’,但是在 “A goat grunted” 中不会匹配任何内容。 | |
| + | 匹配前面一个表达式 1 次或者多次。等价于 {1,}。 | /a+/ 会匹配 “candy” 中的 ‘a’ 和 “caaaaaaandy” 中所有的 ‘a’,但是在 “cndy” 中不会匹配任何内容。 | |
| ? | 一、匹配前面一个表达式 0 次或者 1 次。等价于 {0,1}。 二、如果紧跟在任何量词 *、 +、? 或 {} 的后面,将会使量词变为非贪婪(匹配尽量少的字符),和缺省使用的贪婪模式(匹配尽可能多的字符)正好相反。 |
【实例1】 /e?le?/ 匹配 “angel” 中的 ‘el’、”angle” 中的 ‘le’ 以及 “oslo’ 中的 ‘l’。 【实例2】 对 “123abc” 使用 /\d+/ 将会匹配 “123”,而使用 /\d+?/ 则只会匹配到 “1”。 还用于先行断言中,如本表的 x(?=y) 和 x(?!y) 条目所述。 |
|
| . | 一、(小数点)默认匹配除换行符之外的任何单个字符。 二、如果 s (“dotAll”) 标志位被设为 true,它也会匹配换行符。 |
【实例1】 /.n/ 将会匹配 “nay, an apple is on the tree” 中的 ‘an’ 和 ‘on’,但是不会匹配 ‘nay’ |
|
| (x) | 匹配 ‘x’ 并且记住匹配项。其中括号被称为捕获括号。 在正则表达式的替换环节,则要使用像 $1、$2、…、$n 这样的语法。 |
【实例1】 模式 /(foo) (bar) \1 \2/ 中的 ‘(foo)’ 和 ‘(bar)’ 匹配并记住字符串 “foo bar foo bar” 中前两个单词。模式中的 \1 和 \2 表示第一个和第二个被捕获括号匹配的子字符串,即 foo和 bar,匹配了原字符串中的后两个单词。注意 \1、\2、…、\n 是用在正则表达式的匹配环节 【实例2】 ‘bar foo’.replace(/(…) (…)/, ‘$2 $1’)。$& 表示整个用于匹配的原字符串 |
详情可以参阅后文的 \n 条目 |
| (?:x) | 这种括号叫非捕获括号。 非获取匹配 (?:pattern) :匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分是很有用。 |
【示例】 /(?:foo){1,2}/。 如果表达式是 /foo{1,2}/,{1,2} 将只应用于 ‘foo’ 的最后一个字符 ‘o’。 如果使用非捕获括号,则 {1,2} 会应用于整个 ‘foo’ 单词。 【示例】 “industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。 |
更多信息,可以参阅下文的 Using parentheses 条目 |
| x(?=y) | 非获取匹配,先行断言/正向肯定查找。 匹配’x’仅仅当’x’后面跟着’y’。该匹配不需要获取供以后使用。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
【实例1】 /Jack(?=Sprat)/会匹配到’Jack’仅当它后面跟着’Sprat’ 【实例2】 /Jack(?=Sprat|Frost)/匹配‘Jack’仅当它后面跟着’Sprat’或者是‘Frost’。但是‘Sprat’和‘Frost’都不是匹配结果的一部分 【示例】 例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。 |
|
| (?<=y) x |
非获取匹配,后行断言/反向肯定查找 匹配’x’仅当’x’前面是’y’。 |
【实例1】 /(?<=Jack)Sprat/会匹配到’ Sprat ‘仅仅当它前面是’ Jack ‘。/(?<=Jack|Tom)Sprat/匹配‘ Sprat ’仅仅当它前面是’Jack’或者是‘Tom’。但是‘Jack’和‘Tom’都不是匹配结果的一部分。 |
|
| x(?!y) | 非获取匹配,正向否定查找。 (?!pattern):在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。 |
【示例】 仅仅当这个数字后面没有跟小数点的时候,/\d+(?!\.)/ 匹配一个数字。正则表达式/\d+(?!\.)/.exec(“3.141”)匹配‘141’而不是‘3.141’ 【示例】 例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。 |
|
| (?<!y)x | 非获取匹配,反向否定查找。 仅仅当’x’前面不是’y’时匹配’x’。 |
【实例1】 仅仅当这个数字前面没有负号的时候,/(?<!-)\d+/ 匹配一个数字。 /(?<!-)\d+/.exec(‘3’) 匹配到 “3”. /(?<!-)\d+/.exec(‘-3’) 因为这个数字前有负号,所以没有匹配到。 |
|
| x|y | 匹配‘x’或者‘y’。 | 【实例1】 /green|red/匹配“green apple”中的‘green’和“red apple”中的‘red’ |
|
| {n} | n 是一个正整数,匹配了前面一个字符刚好出现了 n 次。 |
| 【实例1】
/a{2}/ 不会匹配“candy”中的’a’,但是会匹配“caandy”中所有的 a,以及“caaandy”中的前两个’a’ | |
| {n,} | n是一个正整数,匹配前一个字符至少出现了n次。 | 【实例1】
/a{2,}/ 匹配 “aa”, “aaaa” 和 “aaaaa” 但是不匹配 “a” | |
| {n,m} | n 和 m 都是整数。匹配前面的字符至少n次,最多m次。如果 n 或者 m 的值是0, 这个值被忽略。 | 【实例1】
/a{1, 3}/ 并不匹配“cndy”中的任意字符,匹配“candy”中的a,匹配“caandy”中的前两个a,也匹配“caaaaaaandy”中的前三个a。注意,当匹配”caaaaaaandy“时,匹配的值是“aaa”,即使原始的字符串中有更多的a。 | |
| [xyz] | 一个字符集合。匹配方括号中的任意字符,包括转义序列
。你可以使用破折号(-)来指定一个字符范围。对于点(.)和星号(*)这样的特殊符号在一个字符集中没有特殊的意义。他们不必进行转义,不过转义也是起作用的。
| 【实例1】
[abcd] 和[a-d]是一样的。他们都匹配”brisket”中的‘b’,也都匹配“city”中的‘c’。/[a-z.]+/ 和/[\w.]+/与字符串“test.i.ng”匹配 | |
| [^xyz] | 一个反向字符集。也就是说, 它匹配任何没有包含在方括号中的字符。你可以使用破折号(-)来指定一个字符范围。任何普通字符在这里都是起作用的。 | 【示例】
[^abc] 和 [^a-c] 是一样的。他们匹配”brisket”中的‘r’,也匹配“chop”中的‘h’ | |
| [\b] | 匹配一个退格(U+0008)。(不要和\b混淆了。) | | |
| \b | 匹配一个词的边界。一个词的边界就是一个词不被另外一个“字”字符跟随的位置或者前面跟其他“字”字符的位置,例如在字母和空格之间。注意,匹配中不包括匹配的字边界。换句话说,一个匹配的词的边界的内容的长度是0。(不要和[\b]混淆了)
注意: JavaScript的正则表达式引擎将特定的字符集定义为“字”字符。不在该集合中的任何字符都被认为是一个断词。这组字符相当有限:它只包括大写和小写的罗马字母,十进制数字和下划线字符。不幸的是,重要的字符,例如“é”或“ü”,被视为断词。 | 【实例1】
使用”moon”举例:
/\bm/匹配“moon”中的‘m’;
/oo\b/并不匹配”moon”中的’oo’,因为’oo’被一个“字”字符’n’紧跟着。
/oon\b/匹配”moon”中的’oon’,因为’oon’是这个字符串的结束部分。这样他没有被一个“字”字符紧跟着。
/\w\b\w/将不能匹配任何字符串,因为在一个单词中间的字符永远也不可能同时满足没有“字”字符跟随和有“字”字符跟随两种情况。 | |
| \B | 匹配一个非单词边界。匹配如下几种情况:
- 字符串第一个字符为非“字”字符
- 字符串最后一个字符为非“字”字符
- 两个单词字符之间
- 两个非单词字符之间
- 空字符串
| 【实例1】
/\B../匹配”noonday”中的’oo’, 而/y\B../匹配”possibly yesterday”中的’yes‘ | |
| \cX | 当X是处于A到Z之间的字符的时候,匹配字符串中的一个控制符。 | 【实例1】
/\cM/ 匹配字符串中的 control-M (U+000D) | |
| \d | 匹配一个数字。等价于[0-9]。 | 【实例1】
/\d/ 或者 /[0-9]/ 匹配”B2 is the suite number.”中的’2’ | |
| \D | 匹配一个非数字字符。等价于[^0-9]。 | /\D/ 或者 /[^0-9]/ 匹配”B2 is the suite number.”中的’B’ | |
| \f | 匹配一个换页符 (U+000C)。 | | |
| \n | 匹配一个换行符 (U+000A)。 | | |
| \r | 匹配一个回车符 (U+000D)。 | | |
| \s | 匹配一个空白字符,包括空格、制表符、换页符和换行符。等价于[ \f\n\r\t\v\u00a0\u1680\u180e\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]。 | 【实例1】
/\s\w/ 匹配”foo bar.”中的’ bar’。
经测试,\s不匹配”\u180e“,在当前版本Chrome(v80.0.3987.122)和Firefox(76.0.1)控制台输入/\s/.test(“\u180e”)均返回false | |
| \S | 匹配一个非空白字符。等价于 [^ \f\n\r\t\v\u00a0\u1680\u180e\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]。 | 【实例1】
/\S\w/ 匹配”foo bar.”中的’foo’ | |
| \t | 匹配一个水平制表符 (U+0009)。 | | |
| \v | 匹配一个垂直制表符 (U+000B)。 | | |
| \w | 匹配一个单字字符(字母、数字或者下划线)。等价于 [A-Za-z0-9]。 | /\w/ 匹配 “apple,” 中的 ‘a’,”$5.28,”中的 ‘5’ 和 “3D.” 中的 ‘3’ | |
| \W | 匹配一个非单字字符。等价于 [^A-Za-z0-9]。 | /\W/ 或者 /[^A-Za-z0-9_]/ 匹配 “50%.” 中的 ‘%’ | |
| \n | 在正则表达式中,它返回最后的第n个子捕获匹配的子字符串(捕获的数目以左括号计数)。 | /apple(,)\sorange\1/ 匹配”apple, orange, cherry, peach.”中的’apple, orange,’ | |
| \0 | 匹配 NULL(U+0000)字符, 不要在这后面跟其它小数,因为 \0
| 【示例】下哪些正则表达式满足regexp.test(‘abc’) === true? A. /^abc$/ B. /…(?=.)/ C. /[ab]{2}[^defgh]/ D. /[defgh]*/ 答案:A C D |
|---|
Escaping
一、如果需要使用任何特殊字符的字面值(如搜索字符’‘),你必须通过在它前面放一个反斜杠来转义它。
【实例1】要搜索’a’后跟’b’,应该使用/a\b/-反斜杠“转义”字符,使其成为文字而非特殊符号。
二、如果将RegExp构造函数与字符串文字一起使用,反斜杠是字符串文字中的转义。
1、要在正则表达式中使用它,需要在字符串文字级别转义它。
【实例1】/a*b/和new RegExp(“a\b”)创建的表达式是相同的,搜索”a”后跟文字”“后跟”b”
2、将用户输入转义为正则表达式中的一个字面字符串,可以通过简单的替换来实现
function escapeRegExp(string) {return string.replace(/[.*+?^${}()|[\]\\]/g, '\\$&')// $&表示整个被匹配的字符串}
三、正则表达式后的”g”是一个表示全局搜索选项或标记,将在整个字符串查找并返回所有匹配结果。
使用插入语
一、任何正则表达式的插入语都会使这部分匹配的副字符串被记忆。一旦被记忆,这个副字符串就可以被调用于其他用途,如同 使用括号的子字符串匹配中所述。
【实例1】/Chapter (\d+).\d/解释了额外转义和特殊的字符,并说明了这部分pattern应该被记忆。它精确地匹配后面跟着一个以上数字字符的字符 ‘Chapter ‘ (\d 意为任何数字字符,+ 意为1次以上),跟着一个小数点(在这个字符中本身也是一个特殊字符;小数点前的 \ 意味着这个pattern必须寻找字面字符 ‘.’),跟着任何数字字符0次以上。 (\d 意为数字字符, 意为0次以上)
1、插入语也用来记忆第一个匹配的数字字符。此模式可以匹配字符串”Open Chapter 4.3, paragraph 6”,并且’4’将会被记住。此模式并不能匹配”Chapter 3 and 4”,因为在这个字符串中’3’的后面没有点号’.’。
2、括号中的”?:”,这种模式匹配的子字符串将不会被记住。比如,(?:\d+)匹配一次或多次数字字符,但是不能记住匹配的字符。
使用正则表达式
一、正则表达式可以被用于 RegExp 的 exec 和 test 方法以及 String 的 match、replace、search 和 split 方法。
二、使用正则表达式的方法
| 方法 | 描述 | |
|---|---|---|
| RegExp | exec | 一个在字符串中执行查找匹配的RegExp方法,它返回一个数组(未匹配到则返回 null)。 |
| test | 一个在字符串中测试是否匹配的RegExp方法,它返回 true 或 false。 | |
| String | match | 一个在字符串中执行查找匹配的String方法,它返回一个数组,在未匹配到时会返回 null。 |
| matchAll | 一个在字符串中执行查找所有匹配的String方法,它返回一个迭代器(iterator)。 | |
| search | 一个在字符串中测试匹配的String方法,它返回匹配到的位置索引,或者在失败时返回-1。 | |
| replace | 一个在字符串中执行查找匹配的String方法,并且使用替换字符串替换掉匹配到的子字符串。 | |
| split | 一个使用正则表达式或者一个固定字符串分隔一个字符串,并将分隔后的子字符串存储到数组中的 String 方法。 |
1、如果要想知道一个字符串中的一个匹配是否被找到,可以使用test或search方法。
2、想得到更多信息,可以使用exec或match方法,但是比较慢。
3、如果使用exec或match方法并且匹配成功了,那么这些方法将返回一个数组并且更新相关的正则表达式对象的属性和预定义的正则表达式对象。如果匹配失败,那么exec方法返回null(也就是false)
| 【示例】不能从字符串 const str = ‘qwbewrbbeqqbbbweebbbbqee’;中能得到结果 [“b”, “bb”, “bbb”, “bbbb”]的语句是? A. str.match(/b+/g) B. str.match(/b*/g) C. str.match(/b{1,4}/g) D. str.match(/b{1,5}/g) 答案:B 解析:B的结果是[‘’, ‘’, ‘b’, ‘’, ‘’, ‘’, ‘bb’, ‘’, ‘’, ‘’, ‘bbb’, ‘’, ‘’, ‘’, ‘bbbb’, ‘’, ‘’, ‘’, ‘’] |
|---|
三、脚本创建myArray:
1、脚本创建
(1)将使用exec方法在一个字符串中查找一个匹配
var myRe = /d(b+)d/gvar myArray = myRe.exec('cdbbdbsbz')
(2)如果不需要访问正则表达式的属性,这个脚本通过另一个方法来创建myArray
var myArray = /d(b+)d/g.exec('cdbbdbsbz') // 输出数组 [ "dbbd" ]// 和"cdbbdbsbz".match(/d(b+)d)/g)相似 // 输出数组 [ "dbbd", "bb", index: 1, input: "cdbbdbsbz" ]
(3)如果想通过一个字符串创建正则表达式,那么这个脚本还有另一种方法
var myRe = new RegExp('d(b+)d', 'g')var myArray = myRe.exec('cdbbdbsbz')
2、通过这些脚本,匹配成功后将返回一个数组并且更新正则表达式的属性,如下:
正则表达式执行后的返回信息
| 对象 | 属性或索引 | 描述 | 在例子中对应的值 |
|---|---|---|---|
| myArray | 匹配到的字符串和所有被记住的子字符串。 | [“dbbd”, “bb”] | |
| index | 在输入的字符串中匹配到的以0开始的索引值。 | 1 | |
| input | 初始字符串。 | “cdbbdbsbz” | |
| [0] | 最近一个匹配到的字符串。 | “dbbd” | |
| myRe | lastIndex | 开始下一个匹配的起始索引值。(这个属性只有在使用g参数时可用在 通过参数进行高级搜索 一节有详细的描述.) |
5 |
| source | 模式字面文本。在正则表达式创建时更新,不执行。 | “d(b+)d” |
四、可以使用对象初始器创建一个正则表达式实例,但不分配给变量。
1、如果你这样做,那么,每一次使用时都会创建一个新的正则表达式实例。
(1)因此,如果你不把正则表达式实例分配给一个变量,你以后将不能访问这个正则表达式实例的属性。
(2)如果你需要访问一个正则表达式的属性,则需要创建一个对象初始化生成器,你应该首先把它赋值给一个变量。
| 【示例】当发生/d(b+)d/g使用两个不同状态的正则表达式对象,lastIndex属性会得到不同的值。```javascript var myRe = /d(b+)d/g; var myArray = myRe.exec(“cdbbdbsbz”); console.log(“The value of lastIndex is “ + myRe.lastIndex); // The value of lastIndex is 5
<br />```javascriptvar myArray = /d(b+)d/g.exec("cdbbdbsbz");console.log("The value of lastIndex is " + /d(b+)d/g.lastIndex); // The value of lastIndex is 0
1、lodash深拷贝正则表达式时用到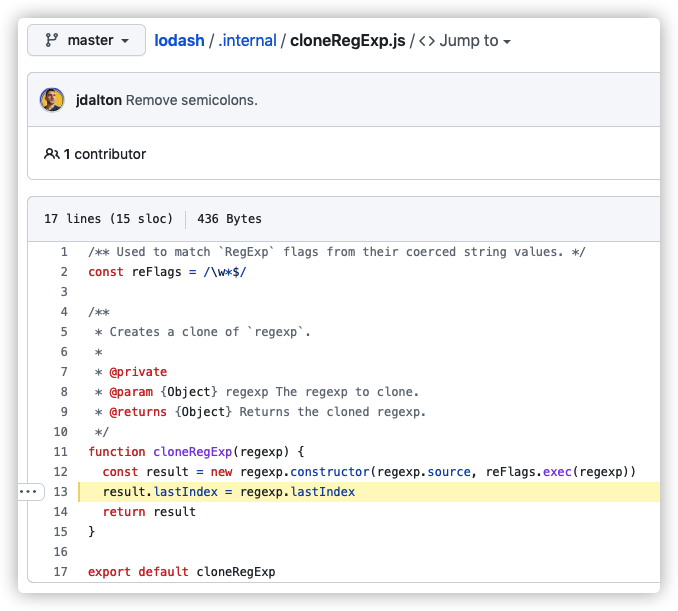
|
| —- |
使用括号的子字符串匹配
一、一个正则表达式模式使用括号,将导致相应的子匹配被记住。
【实例1】/a(b)c /可以匹配字符串“abc”,并且记得“b”。
1、回调这些括号中匹配的子串,使用数组元素[1],……[n]。
二、使用括号匹配的子字符串的数量是无限的。返回的数组中保存所有被发现的子匹配。
三、脚本可以使用replace()方法来转换字符串中的单词。
1、在匹配到的替换文本中,脚本使用替代的$ 1,$ 2表示第一个和第二个括号的子字符串匹配。
【实例1】
var re = /(\w+)\s(\w+)/;
var str = "John Smith";
var newstr = str.replace(re, "$2, $1");
console.log(newstr);
// "Smith, John"
| 【示例】以下代码的执行后,str 的值是:```javascript var str = “Hellllo world”; str = str.replace(/(l)\1/g, ‘$1’);
A.Helo world<br />B. Hello world<br />C. Helllo world<br />D. Hellllo world<br />**答案**:B<br />**解析**:<br />1、定义<br />(l)表示第一个分组里有l<br />\\1表示所获取的第1个()匹配的引用<br />/g表示全局匹配<br />$1表示第一个分组里的值l<br />2、所以<br />(l)\\l 表示匹配两个连续字符ll,即ll<br />(l)\\l/g 表示全局匹配两个连续字符ll即llll<br />/(l)\\1/g === /(l)(l)/g<br />str.replace(/(l)\\1/g, '$1') 表示将ll替换成l<br />he(l[$1]l[$2])(l[$1]l[$2])o world<br /> 第一次匹配 第二次匹配<br />hel[$1]l[$1]o world <br />3、最终<br />Hellllo =》 Hello |
| --- |
<a name="q00ZI"></a>
## 通过标志进行高级搜索
一、正则表达式有六个可选参数 (flags) 允许全局和不分大小写搜索等。<br />1、这些参数既可以单独使用也能以任意顺序一起使用, 并且被包含在正则表达式实例中。<br />二、正则表达式标志
| 标志 flags | 描述 |
| --- | --- |
| g | 全局搜索。 |
| i | 不区分大小写搜索。 |
| m | 多行搜索。 |
| s | 允许 . 匹配换行符。 |
| u | 使用unicode码的模式进行匹配。 |
| y | 执行“粘性(sticky)”搜索,匹配从目标字符串的当前位置开始。 |
三、正则表达式中包含标志的语法<br />1、
```javascript
var re = /pattern/flags;
2、
var re = new RegExp("pattern", "flags");
四、标志是一个正则表达式的一部分,它们在接下来的时间将不能添加或删除。
【实例1】re = /\w+\s/g 将创建一个查找一个或多个字符后有一个空格的正则表达式,或者组合起来像此要求的字符串
var re = /\w+\s/g; // 替换成var re = new RegExp("\\w+\\s", "g");也能得到相同的结果
var str = "fee fi fo fum";
var myArray = str.match(re);
console.log(myArray);
// ["fee ", "fi ", "fo "]
五、使用.exec()方法时,与’g’标志关联的行为是不同的。
1、“class”和“argument”的作用相反:
str.match(re):在.match()的情况下,字符串类(或数据类型)拥有该方法,而正则表达式只是一个参数。
re.exec(str):在.exec()的情况下,正则表达式拥有该方法,其中字符串是参数。
2、 ‘g’标志与.exec()方法一起使用获得迭代进展。
【实例1】
var xArray; while(xArray = re.exec(str)) console.log(xArray);
// produces:
// ["fee ", index: 0, input: "fee fi fo fum"]
// ["fi ", index: 4, input: "fee fi fo fum"]
// ["fo ", index: 7, input: "fee fi fo fum"]
六、m标志用于指定多行输入字符串应该被视为多个行。如果使用m标志,^和$匹配的开始或结束输入字符串中的每一行,而不是整个字符串的开始或结束。
正则表达式的用途
特殊需求表达式
- 密码:
- 需包含至少字母+数字在内,长度8-16位:/^(?=.[0-9])(?=.[a-zA-Z])(.{8,16})$/
改变输入字符串的顺序
一、正则表达式的构成、string.split()、string.replace()的用途
【实例1】整理一个只有粗略格式的含有全名(名字首先出现)的输入字符串,这个字符串被空格、换行符和一个分号分隔。最终,它会颠倒名字顺序(姓氏首先出现)和list的类型。 ```javascript // 下面这个姓名字符串包含了多个空格和制表符, // 且在姓和名之间可能有多个空格和制表符。 var names = “Orange Trump ;Fred Barney; Helen Rigby ; Bill Abel ; Chris Hand “;
- 需包含至少字母+数字在内,长度8-16位:/^(?=.[0-9])(?=.[a-zA-Z])(.{8,16})$/
var output = [“————— Original String\n”, names + “\n”];
// 准备两个模式的正则表达式放进数组里。 // 分割该字符串放进数组里。
// 匹配模式:匹配一个分号及紧接其前后所有可能出现的连续的不可见符号。 var pattern = /\s;\s/;
// 把通过上述匹配模式分割的字符串放进一个叫做nameList的数组里面。 var nameList = names.split(pattern);
// 新建一个匹配模式:匹配一个或多个连续的不可见字符及其前后紧接着由 // 一个或多个连续的基本拉丁字母表中的字母、数字和下划线组成的字符串 // 用一对圆括号来捕获该模式中的一部分匹配结果。 // 捕获的结果稍后会用到。 pattern = /(\w+)\s+(\w+)/;
// 新建一个数组 bySurnameList 用来临时存放正在处理的名字。 var bySurnameList = [];
// 输出 nameList 的元素并且把 nameList 里的名字 // 用逗号接空格的模式把姓和名分割开来然后存放进数组 bySurnameList 中。 // // 下面的这个替换方法把 nameList 里的元素用 $2, $1 的模式 // (第二个捕获的匹配结果紧接着一个逗号一个空格然后紧接着第一个捕获的匹配结果)替换了 // 变量 $1 和变量 $2 是上面所捕获的匹配结果。
output.push(“————— After Split by Regular Expression”);
var i, len; for (i = 0, len = nameList.length; i < len; i++) { output.push(nameList[i]); bySurnameList[i] = nameList[i].replace(pattern, “$2, $1”); }
// 输出新的数组 output.push(“————— Names Reversed”); for (i = 0, len = bySurnameList.length; i < len; i++){ output.push(bySurnameList[i]); }
// 根据姓来排序,然后输出排序后的数组。 bySurnameList.sort(); output.push(“————— Sorted”); for (i = 0, len = bySurnameList.length; i < len; i++){ output.push(bySurnameList[i]); }
output.push(“————— End”);
console.log(output.join(“\n”));
```javascript
---------- Original String
Orange Trump ;Fred Barney; Helen Rigby ; Bill Abel ; Chris Hand
---------- After Split by Regular Expression
Orange Trump
Fred Barney
Helen Rigby
Bill Abel
Chris Hand
---------- Names Reversed
Trump, Orange
Barney, Fred
Rigby, Helen
Abel, Bill
Hand, Chris
---------- Sorted
Abel, Bill
Barney, Fred
Hand, Chris
Rigby, Helen
Trump, Orange
---------- End
用特殊字符校验输入
【实例1】我们期望用户输入一个电话号码。当用户点击“Check”按钮,我们的脚本开始检查这些数字是否合法。1、如果数字合法(匹配正则表达式所规定的字符序列),脚本显示一条感谢用户的信息并确认该数字。
如果这串数字不合法,脚本提示用户电话号码不合法。.
2、包含
非捕获括号 (?:
这个正则表达式寻找
三个数字字符\d{3}
或者 |
一个左半括号(
跟着
三位数字\d{3}
, 跟着
一个封闭括号 ),
(结束非捕获括号 )),
后跟着
一个短破折号或正斜杠或小数点,
随后跟随
三个数字字符
,当记忆字符 ([-\/.])捕获并记住,后面跟着
三位小数\d{3}
,再后面跟随记住的破折号、正斜杠或小数点 \1,最后跟着
四位小数 \d{4}。
3、当用户按下 Enter 设置 RegExp.input,这些变化也能被激活。
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<meta http-equiv="Content-Script-Type" content="text/javascript">
<script type="text/javascript">
var re = /(?:\d{3}|\(\d{3}\))([-\/\.])\d{3}\1\d{4}/;
function testInfo(phoneInput) {
var OK = re.exec(phoneInput.value);
if (!OK)
window.alert(phoneInput.value + ' isn\'t a phone number with area code!');
else
window.alert('Thanks, your phone number is ' + OK[0]);
}
</script>
</head>
<body>
<p>Enter your phone number (with area code) and then click "Check".
<br>The expected format is like ###-###-####.</p>
<form action="#">
<input id="phone"><button onclick="testInfo(document.getElementById('phone'));">Check</button>
</form>
</body>
</html>

若有收获,就点个赞吧
0 人点赞
