- 4.5.1 介绍Job资源
- 4.5.2 定义Job资源
- 4.5.3 看Job运行一个pod
- ">kubectl create之后,查看jobs和pod资源

- ">两分钟之后任务完成,pod将处于 Completed 状态:

- ">完成之后pod未被删除的原因是允许你查阅其日志:

- ">pod可以被直接删除,或者在删除创建它的Job时被删除。

- 4.5.4 在Job中运行多个pod实例
Job将一个接一个地运行五个pod。它最初创建一个pod, 当pod的容器运行完成时,它创建第二个pod, 以此类推,直到五个pod成功完成。如果其中一个pod 发生故障,Job会创建一个新的pod, 所以Job总共可能创建超过五个的pod。">设置completions,让Job 运行多次。
Job将一个接一个地运行五个pod。它最初创建一个pod, 当pod的容器运行完成时,它创建第二个pod, 以此类推,直到五个pod成功完成。如果其中一个pod 发生故障,Job会创建一个新的pod, 所以Job总共可能创建超过五个的pod。- 4.5.5 限制Job pod完成任务的时间
你会遇到只想运行一个完成工作(work)后就终止的任务(task)的清况。
4.5.1 介绍Job资源
Job资源允许你运行一种pod,该pod在内部进程成功结束时,不重启容器。一旦任务完成,pod 就被认为处于Completed状态,并退出READY状态。
Job 资源在创建时会立即运行pod。
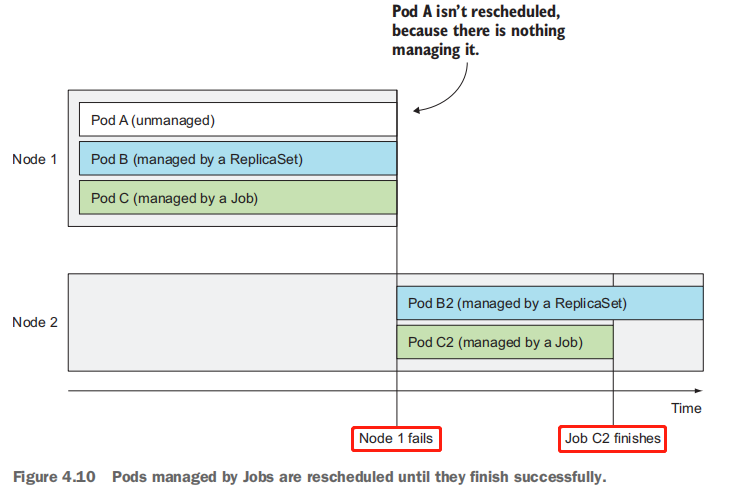
在发生节点故障时,该节点上由Job管理的pod将按照ReplicaSet的pod的方式,被重新调度到其他节点。如果进程本身异常退出(进程返回错误退出码),可以将Job配置为重新启动容器。
图 4.10 显示了如果一个Job 所创建的 pod, 在最初被调度节点上异常退出后,被重新调度到一个新节点上的情况。 该图还显示了托管的 pod (未重新调度)和由ReplicaSet 管理的 pod (被重新调度)。
4.5.2 定义Job资源
实验:YAML定义了 一个Job类型的资源,它将运行luksa/batch-job镜像,该镜像调用一个运行sleep 120秒的进程,然后退出。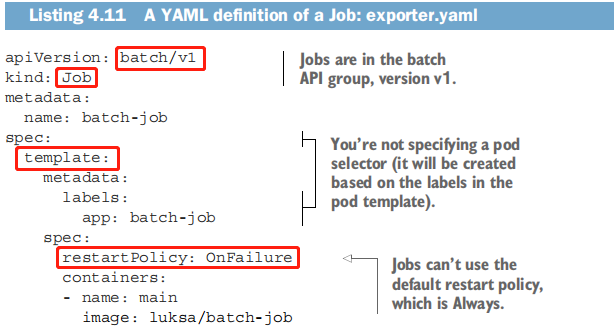
restartPolicy:指定在容器中运行的进程结束时,Kubernetes是否让容器重启。它的值有:
Always:默认值,总是重启容器;(不应该使用)
OnFailure:进程本身异常退出(进程返回错误退出码)时,重启容器;
Never:从不重启容器;
该Job的label selector 与 pod template的关系:(自动创建)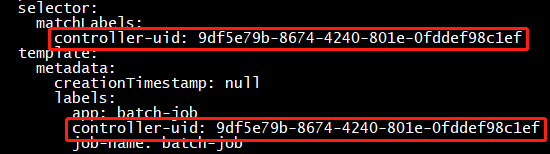
cd /root/k8s/cat >exporter.yaml <<'EOF'apiVersion: batch/v1kind: Jobmetadata:name: batch-jobspec:template:metadata:labels:app: batch-jobspec:restartPolicy: OnFailurecontainers:- name: mainimage: luksa/batch-jobEOFkubectl create -f exporter.yaml
4.5.3 看Job运行一个pod
kubectl create之后,查看jobs和pod资源
两分钟之后任务完成,pod将处于 Completed 状态:
完成之后pod未被删除的原因是允许你查阅其日志:
pod可以被直接删除,或者在删除创建它的Job时被删除。
4.5.4 在Job中运行多个pod实例
作业可以配置为创建多个pod实例, 并以并行或串行方式运行它们 。 这是通过在Job配置中设置 completions 和parallelism 属性来完成的。
顺序运行Job pod
设置completions,让Job 运行多次。
Job将一个接一个地运行五个pod。它最初创建一个pod, 当pod的容器运行完成时,它创建第二个pod, 以此类推,直到五个pod成功完成。如果其中一个pod 发生故障,Job会创建一个新的pod, 所以Job总共可能创建超过五个的pod。
并行运行Job pod
不必一个接一个地运行单个Job pod, 也可以让该Job并行运行多个pod。通过配置completions和parallelism属性。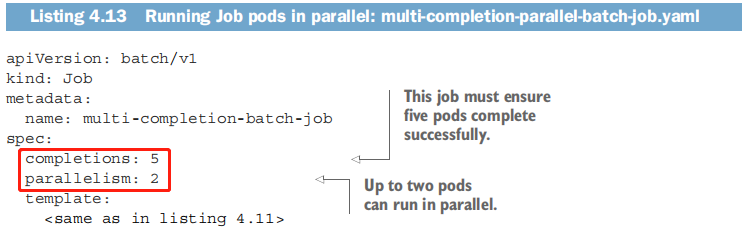
Job的伸缩(scaling)
在 Job 运行时更改 Job 的 parallelism 属性:
#由于你将 parallelism 从 2 增加到 3, 另一个 pod 立即启动, 因此现在有三个 pod 在运行。
4.5.5 限制Job pod完成任务的时间
通过配置pod template 中的 spec.activeDeadlineSeconds 属性,可以限制 pod的时间。如果 pod 运行时间超过此时间, 系统将尝试终止 pod, 并将 Job 标记为失败。
通过配置pod template 中的 spec.backoffLimit 属性,可以设置Job在被标记为失败可以重试的次数。如果没有明确指定,则默认为6.

若有收获,就点个赞吧
0 人点赞
