(技术已过时,仅了解)
9.2.1 运行第一个版本的应用
它就是一个简单的web应用程序,在HTTP响应中返回pod的主机名和版本号。
创建v1版本的应用
镜像:Docker Hub上,luksa/kubia:v1
使用单个YAML文件运行应用并通过Service暴露
使用kubectl create同时创建RC和SVC。YAML manifest可以使用包含 —- 的行来分隔多个对象。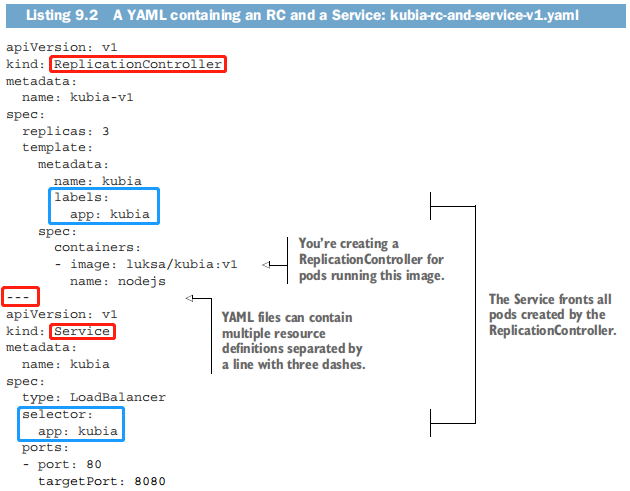
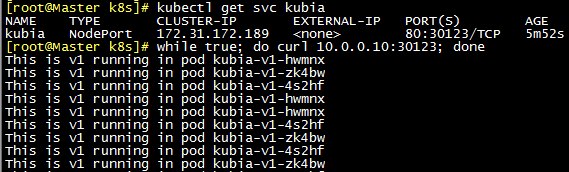
#准备镜像docker pull luksa/kubia:v1docker tag luksa/kubia:v1 10.0.0.10:5000/luksa/kubia:v1docker push 10.0.0.10:5000/luksa/kubia:v1#由于没有云基础设施,我们通过service的NodePort类型来实现cd /root/k8s/cat >kubia-rc-and-service-v1.yaml <<'EOF'apiVersion: v1kind: ReplicationControllermetadata:name: kubia-v1spec:replicas: 3template:metadata:name: kubialabels:app: kubiaspec:containers:- image: 10.0.0.10:5000/luksa/kubia:v1name: nodejs---apiVersion: v1kind: Servicemetadata:name: kubiaspec:type: NodePortselector:app: kubiaports:- port: 80targetPort: 8080nodePort: 30123EOFkubectl create -f kubia-rc-and-service-v1.yaml#检测、测试kubectl get svc kubiawhile true; do curl 10.0.0.10:30123; done
9.2.2 使用kubectl来执行滚动升级
创建v2版本的应用,修改之前的应用程序,使其返回”This is v2”。
镜像:Docker Hub上,luksa/kubia:v2
使用同样的tag推送更新过后的镜像的注意事项
虽然在开发过程中经常推送修改后的应用到同一个镜像tag,但是这种做法并不可取。如果修改了latest的tag的话是可行的,但如果使用一个不同的tag名(比如是v1而不是lastest),等worker node拉取过镜像之后,便会将镜像存储在节点上。如果使用该镜像启动新的pod,便不会重新拉取镜像(至少这是默认的拉取镜像策略)。
这也意味着,如果将对更改过后的镜像推到相同的tag,会导致镜像不被重新拉取。如果一个新的pod被调度到同一个节点上,Kubelet直接使用旧的镜像版本来启动pod。另一方面,没有运行过旧版本的节点将拉取并运行新镜像,因此最后可能有两个不同版本的pod同时运行。
为了确保这种情况不会发生,需要将容器的imagePullPolicy属性设置为Always。
$ kubectl explain pod.spec.containers.imagePullPolicy Defaults to Always if :latest tag is specified, or IfNotPresent otherwise.
默认的imagePullPolicy策略也依赖于镜像的tag。 :latest(显式指定或者不指定)默认为Always, 其他标签,默认为IfNotPresent。
当使用非latest的tag时,如果对镜像进行更改而不更改tag,则需要正确设置imagePullPolicy。当然最好使用一个新的tag来更新镜像。
#准备镜像docker pull luksa/kubia:v2docker tag luksa/kubia:v2 10.0.0.10:5000/luksa/kubia:v2docker push 10.0.0.10:5000/luksa/kubia:v2#保持curl循环运行的状态下打开另一个终端,执行滚动升级命令:kubia-v1是被替换的RC,kubia-v2是新RC的名称。kubectl rolling-update kubia-v1 kubia-v2 --image=10.0.0.10:5000/luksa/kubia:v2 #已弃用
注意:在K8S 1.21版本中,kubectl rolling-update命令已弃用。
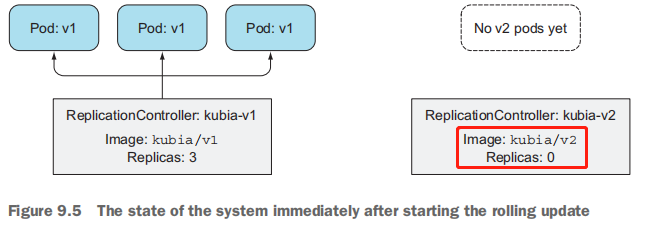
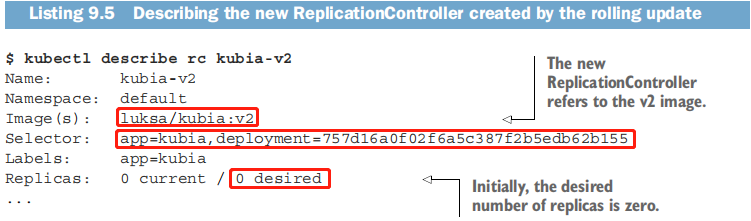
了解滚动升级前 kubectl 所执行的操作
kubectl通过复制kubia-v1 RC并在其pod模板中改变镜像版本来创建kubia-v2 RC。如果仔细观察kubia-v2控制器的标签选择器,会发现它也被做了修改。它不仅包含一个简单的app=kubia标签,而且还包含一个额外的deployment标签,为了由这个kubia-v2 RC管理,pod必须具备这个标签。
在滚动升级过程中,第一个ReplicationController的选择器kubia-v1也会被修改:
在修改ReplicationController kubia-v1的选择器之前,kubectl修改了当前pod的标签:
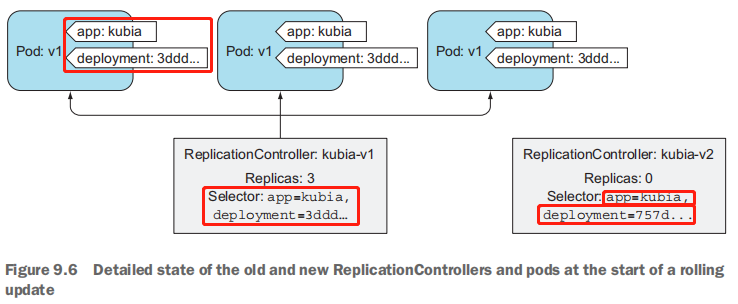
通过伸缩两个ReplicationController将旧pod替换成新的pod
设置完所有这些之后,kubectl开始替换pod。首先将新的Controller扩展为1,新的Controller因此创建第一个v2 pod,然后kubectl将旧的ReplicationConroller缩小1。
此时curl的请求将被重定向到v1或v2的pod上了。
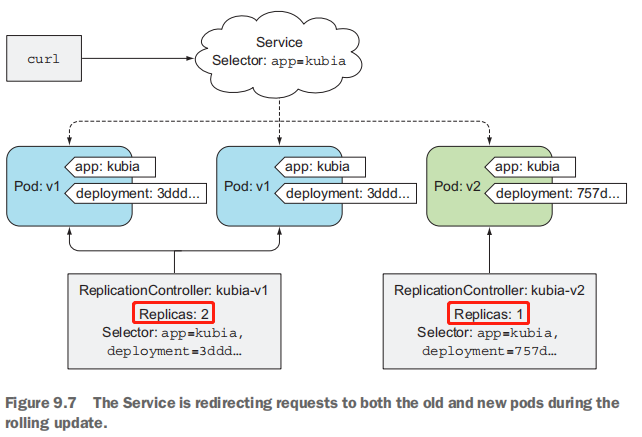
随着kubectl继续滚动升级,v1 pod不断被删除,并被替换为运行新镜像的v2 pod。最终v1的pod全部被删除,并删除旧的RC。只剩下kubia-v2 RC和3个v2pod。
在整个升级过程中,每次发出的请求都有相应的响应,通过一次滚动升级,服务一直保持可用状态。
9.2.3 为什么现在kubectl rolling-update已经弃用
1)首先,这个过程会直接修改创建的对象——直接更改pod的标签和ReplicationController的标签选择器,这并是我们所期望的。
2)还有更重要的一点是,kubectl只是执行滚动升级过程所有这些步骤的客户端。它向API Server发起HTTP PUT请求。伸缩的操作是由kubectl客户端执行的,而不是由master执行的。
为什么由客户端执行升级过程,而不是服务端执行是不好的呢?
1)如果在kubectl执行升级时网络连接中断,升级进程将会中断,这将导致pod和RC最终后处于中间状态,存在两个应用版本。
2)我们应该只声明所期望的系统状态,让Kubernetes自己实现这个状态的。这就是 pod 的部署方式,以及 pod 的伸缩方式。你决不会告诉Kubernetes添加一个额外的pod或删除一个多余的pod,而只需要更改期望的副本数量。同样,只需要在pod定义中更改所期望的镜像tag,并让Kubemetes用运行新镜像的pod替换旧的pod。

若有收获,就点个赞吧
0 人点赞
