客户端嵌入
只有当你的应用已经嵌入 OpenTracing 的客户端 Lib 库之后,调用链追踪数据才会发送到 Jaeger 后端服务。关于 OpenTracing 的 API 以及客户端 Lib 库的初始化、配置以及相关使用,可以参考客户端库的介绍。
All in One 介绍
all-in-one 是一个可执行文件,可以用于快速进行本地测试。
其中,包含了 Jaeger 的 UI、collector 服务、查询服务以及 agent 等,同时使用了在内存存储数据的方案。
运行 all-in-one 程序的最简单的方法是使用一个 Dockerhub 中发布的镜像,只需要如下命令即可启动对应服务:
docker run -d --name jaeger \-e COLLECTOR_ZIPKIN_HOST_PORT=:9411 \-p 5775:5775/udp \-p 6831:6831/udp \-p 6832:6832/udp \-p 5778:5778 \-p 16686:16686 \-p 14268:14268 \-p 14250:14250 \-p 9411:9411 \jaegertracing/all-in-one:1.25
此外,还可以将 jaeger-all-in-one 的可执行程序下载下来,并手动执行:
jaeger-all-in-one --collector.zipkin.host-port=:9411
然后,我们就可以打开浏览器,访问 http://localhost:16686 来进入 Jaeger 的 UI 界面了。
其中,上述罗列出的端口功能如下:
| Port | Protocol | Component | 功能说明 |
|---|---|---|---|
| 5775 | UDP | agent | 接受 zipkin.thrift 协议数据(已作废) |
| 6831 | UDP | agent | 接收 jaeger.thrift 协议数据(基于compact thrift协议) |
| 6832 | UDP | agent | 接收 jaeger.thrift 协议数据(基于binary thrift协议) |
| 5778 | HTTP | agent | 配置服务 |
| 16686 | HTTP | query | 前端服务 |
| 14268 | HTTP | collector | 直接从客户端接收 jaeger.thrift 协议 |
| 14250 | HTTP | collector | 接收 model.proto |
| 9411 | HTTP | collector | Zipkin 协议兼容的接收端点(可选) |
Kubernetes 以及 OpenShift 部署
通过 Kubernetes 以及 OpenShift 可以快速的部署 Jaeger 服务,详情可以参考:
示例应用:HotROD
HotROD 是一个演示的应用程序,由几个微服务组成,并在其中演示了 OpenTracing API 的使用。
关于整体的教程,可以参考博客:在 HotROD ride 上使用 OpenTracing。
这个示例应用可以单独执行,但是如果想要查看 traces 数据,则需要依赖 Jaeger 服务。
功能描述
在这个应用中,我们可以体会到的功能包括:
- 通过数据驱动的依赖关系图了解整个系统的架构。
- 通过查看时间线和错误信息来理解整个应用是如何运行的。
- 定位延迟和并发性不足的根因。
- 高度上下文关联的日志信息。
- 可以使用 baggage 来传递如下信息:
- 定位内部请求内容。
- 服务中的耗时信息。
- 使用开源的 OpenTracing 库进行集成。
准备工作
在开始之前,首先需要做一些前期的准备工作,具体来说,包括:
- 安装 Golang 环境,并安装相关的 go.mod 依赖。
- 搭建完成 Jaeger 后端服务。
运行看看
HotROD 服务提供了多种运行的方式。
源码运行
mkdir -p $GOPATH/src/github.com/jaegertracingcd $GOPATH/src/github.com/jaegertracinggit clone git@github.com:jaegertracing/jaeger.git jaegercd jaegergo run ./examples/hotrod/main.go all
Docker运行
docker run --rm -it \--link jaeger \-p8080-8083:8080-8083 \-e JAEGER_AGENT_HOST="jaeger" \jaegertracing/example-hotrod:1.25 \all
二进制执行
example-hotrod all
其中,二进制的下载地址请点击。
访问看看
无论您是使用哪种方式将服务运行起来的,都可以访问如下地址来访问示例应用的。
http://localhost:8080
StepByStep
上面的运行方式实在太简单了,下面,我们就来以源码为例,详细介绍其中的每一步的工作和原理等内容,希望通过这个示例,你可以初步掌握 Jaeger 相关的功能使用。
Step1: 启动 Jaeger 服务。
如何启动 Jaeger 服务此处就不再赘述了,可以直接参考上述的启动方法。
启动完成后,可以访问 http://127.0.0.1:16686/ 来验证一下 Jaeger 服务是否已经正常启动了。
Jaeger 服务正常启动后,打开浏览器后,应该可以看到如上页面。
因为 Jaeger 服务是刚刚启动的,且使用的是内存存储,因此目前 Jaeger 后台服务中没有任何数据,下面,我们需要来用 HotROD 应用来生成一些trace数据。
Step2: 了解 HotROD 应用
HotROD 是一个共享乘车的应用Demo,我们可以直接从 github 上拉取对应的代码并运行:
git clone git@github.com:jaegertracing/jaeger.git jaegercd jaegergo run ./examples/hotrod/main.go all
其中,all 指令表示在单个二进制程序中运行所有的微服务。
此时,从 log 中,我们其实可以看到,此时已经启动了多个微服务并绑定了不同的端口:
2021-08-18T18:59:12.837+0800 INFO cobra@v1.2.1/command.go:886 Using expvar as metrics backend2021-08-18T18:59:12.837+0800 INFO cobra@v1.2.1/command.go:856 Starting all services2021-08-18T18:59:12.943+0800 INFO tracing/init.go:66 debug logging disabled {"service": "frontend"}2021-08-18T18:59:12.943+0800 INFO tracing/init.go:66 debug logging disabled {"service": "route"}2021-08-18T18:59:12.943+0800 INFO tracing/init.go:66 debug logging disabled {"service": "customer"}2021-08-18T18:59:12.943+0800 INFO tracing/init.go:66 debug logging disabled {"service": "driver"}2021-08-18T18:59:12.944+0800 INFO tracing/init.go:66 debug logging disabled {"service": "customer"}2021-08-18T18:59:12.944+0800 INFO tracing/init.go:66 debug logging disabled {"service": "driver"}2021-08-18T18:59:12.944+0800 INFO tracing/init.go:66 debug logging disabled {"service": "frontend"}2021-08-18T18:59:12.944+0800 INFO tracing/init.go:66 debug logging disabled {"service": "route"}2021-08-18T18:59:12.944+0800 INFO route/server.go:57 Starting {"service": "route", "address": "http://0.0.0.0:8083"}2021-08-18T18:59:12.945+0800 INFO frontend/server.go:74 Starting {"service": "frontend", "address": "http://0.0.0.0:8080"}2021-08-18T18:59:13.050+0800 INFO tracing/init.go:66 debug logging disabled {"service": "customer"}2021-08-18T18:59:13.051+0800 INFO tracing/init.go:66 debug logging disabled {"service": "driver"}2021-08-18T18:59:13.051+0800 INFO tracing/init.go:66 debug logging disabled {"service": "driver"}2021-08-18T18:59:13.051+0800 INFO tracing/init.go:66 debug logging disabled {"service": "customer"}2021-08-18T18:59:13.051+0800 INFO customer/server.go:55 Starting {"service": "customer", "address": "http://0.0.0.0:8081"}
下面,我们可以访问入口服务的地址:http://127.0.0.1:8080/ ,正常情况下,你应该可以看到这样一个页面。
我们有四个客户,通过单击四个按钮中的任意一个,我们就会委派一辆汽车到达该客户所在的位置来接送客户。
当发送一个汽车委派的请求到后端服务时,它会返回汽车的车牌号和预计到达时间作为服务的响应,示例如下: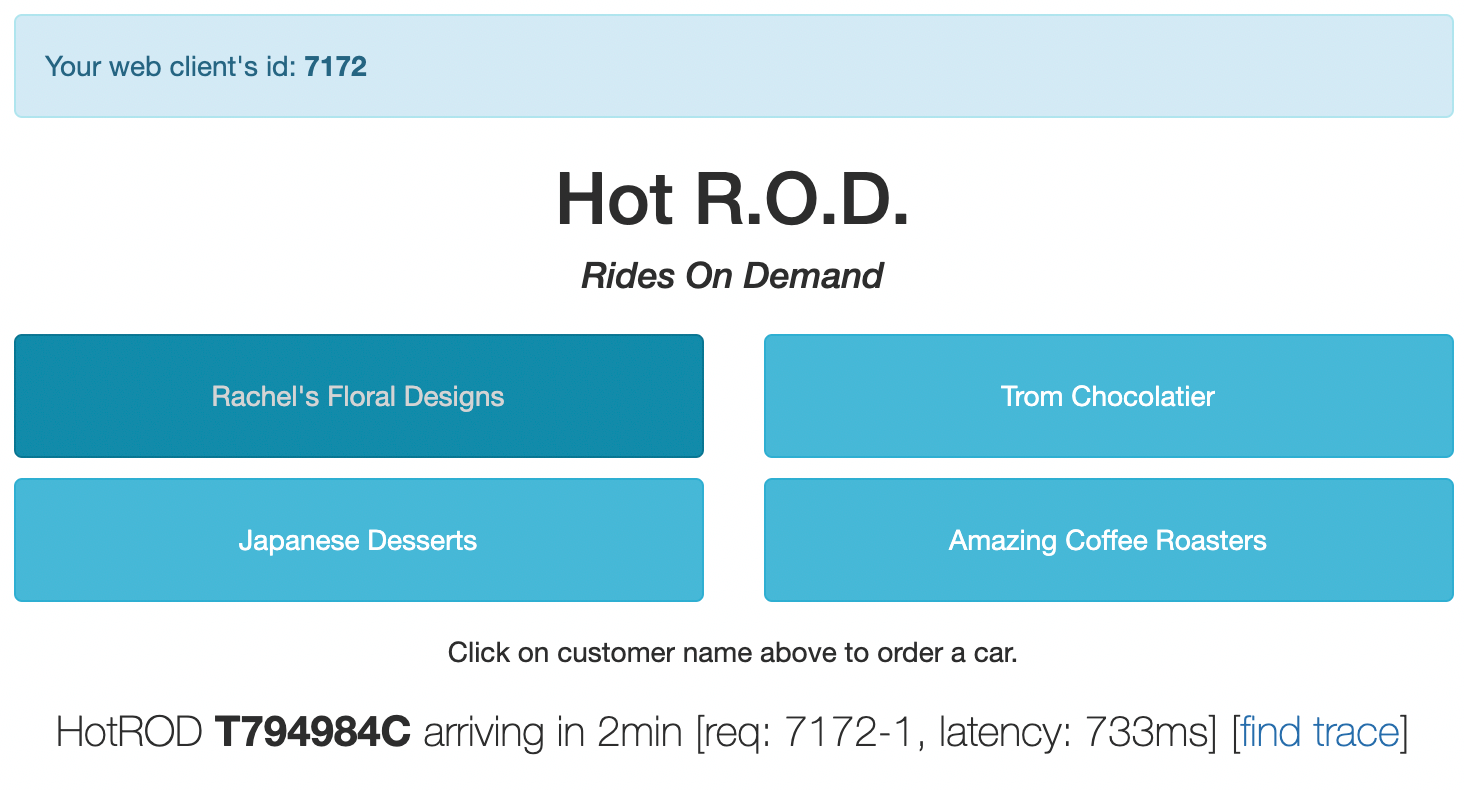
此时,界面中打印出来了一些详细的信息,我们来看看这些信息分别具备什么样的含义:
- 左上角中有一个 web client’s id,它是 JavaScript UI 随机分配的一个会话ID,如果刷新页面的话,你将会看到一个新的ID。
- 在最下方的汽车信息中,我们可以看到一个请求 req 的ID: 7172-1,它表示了一个向后端发送的请求的唯一ID,由上述的会话ID与序列号组成。
- 此外,最后还有一个 latency 的指标,733ms,这个指标表示了后端服务响应该请求耗费的时间。
上述的这些信息其实对于应用程序的功能并没有直接的影响,但是再往后看,我们会发现这些信息对于我们其实也是非常有价值的。
Step3: 看看系统架构
在上一节的内容中,我们已经简单了解了 HotROD 系统的功能,现在,我们就来了解一下整个 HotROD 系统的架构。
那么,怎么能快速的了解到系统的架构呢?传统的方法就是开发人员提供系统的设计文档和架构图,用户根据开发人员提供的相关资料来了解系统的架构。但是Jaeger 提供了一种更加优雅的方法,Jaeger 可以通过记录和分析服务之间的交互来自动构建整个系统的架构图。
回到Jaeger的UI页面,切换到 System Architecture 页面,并切换到 DAG 选项卡: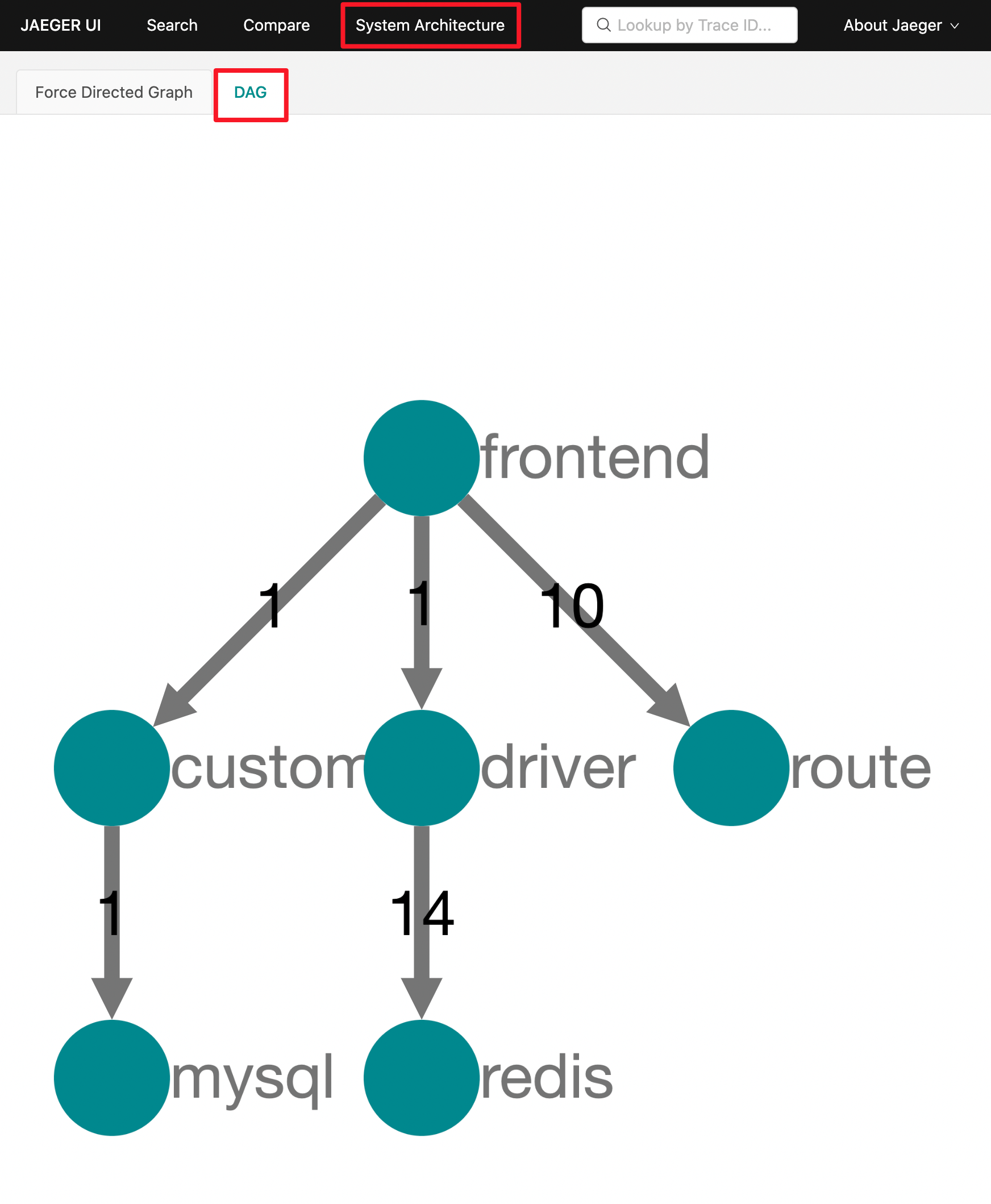
是吧~单个 HotROD 程序实际上的确运行了四个微服务和两个存储后端,不过,这两个存储后端MySQL和Redis其实不是真实部署启动的,而是被应该程序模拟的,但是四个微服务的确是真实部署的。
从上图我们可以了解到,它们记录了服务间网络调用的相关信息。例如 frontend 微服务提供了前端WEB UI页面作为入口,并调用了其他三个微服务。此外,该图还显示了在请求中,互相之间进行的调用次数,例如,frontend 微服务调用了10次 route微服务,而 redis 被 driver 调用了 14次。
step4: 分析数据流
我们已经了解到了 HotROD 系统由四个微服务组成了,下面,我们来看一下在一次调用中,互相之间的调用关系和调用顺序究竟是怎么样的。
切换回到 Jaeger UI 的 Search 页面,我们可以看到右侧有一个 Services 的下拉列表包含了我们在之前架构图中看到的服务的名称。
我们知道 frontend 服务是整个系统的流量入口,因此我们选择该服务并点击 Find Traces 按钮。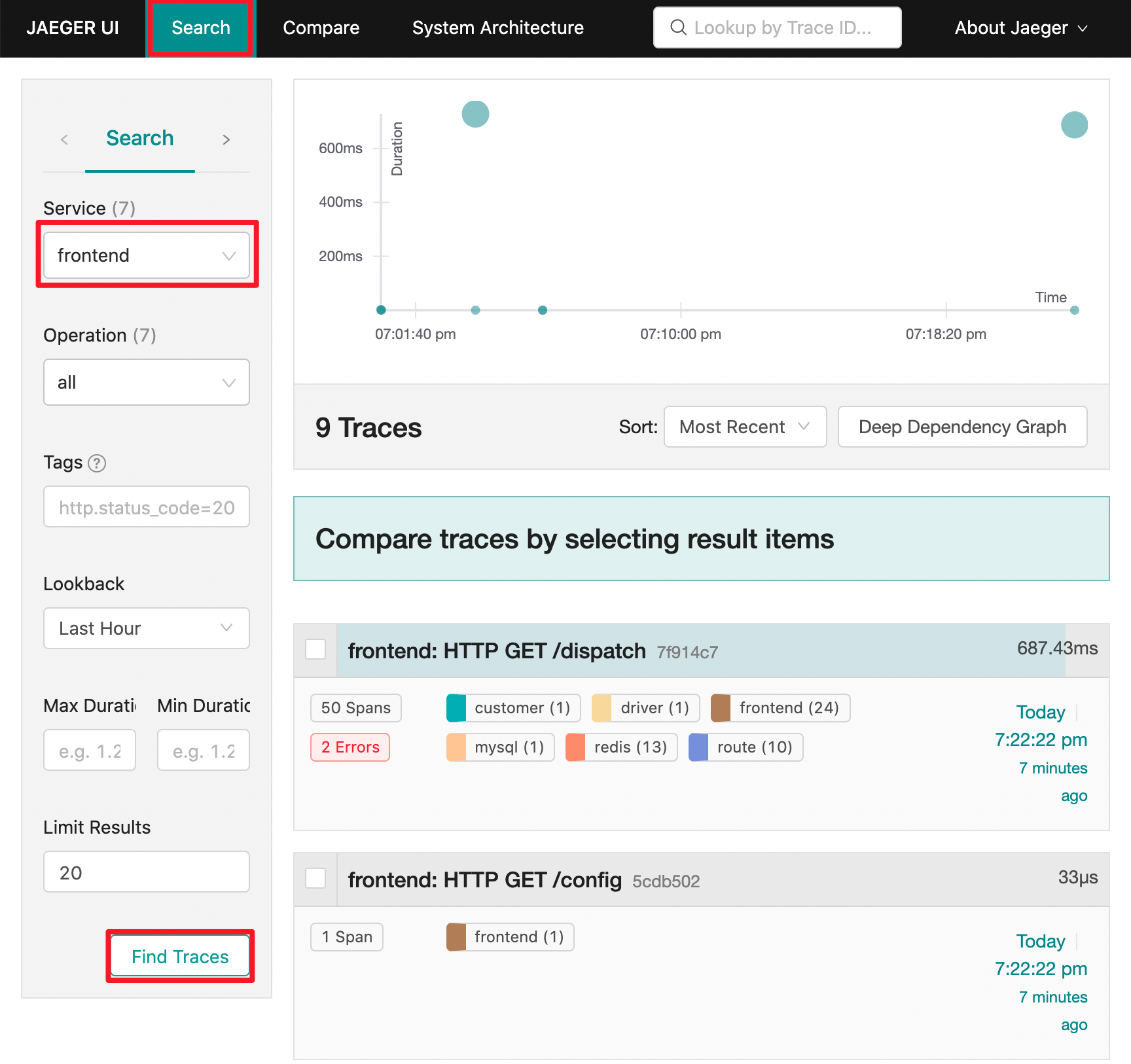
Jaeger 系统找到了一些 trace 并显示了一些关于该 trace 的元数据,包括参与该 trace 的不同服务的名称以及每个服务发送到 Jaeger 的 span 记录数。
其中,url 访问入口信息在标题栏中显示,例如,frontend: HTTP GET /dispatch,在最右侧,我们可以看到该 trace 的总持续时间为 687.43ms。
下面,我们来点击一下标题栏就可以看到 trace 的详细数据了: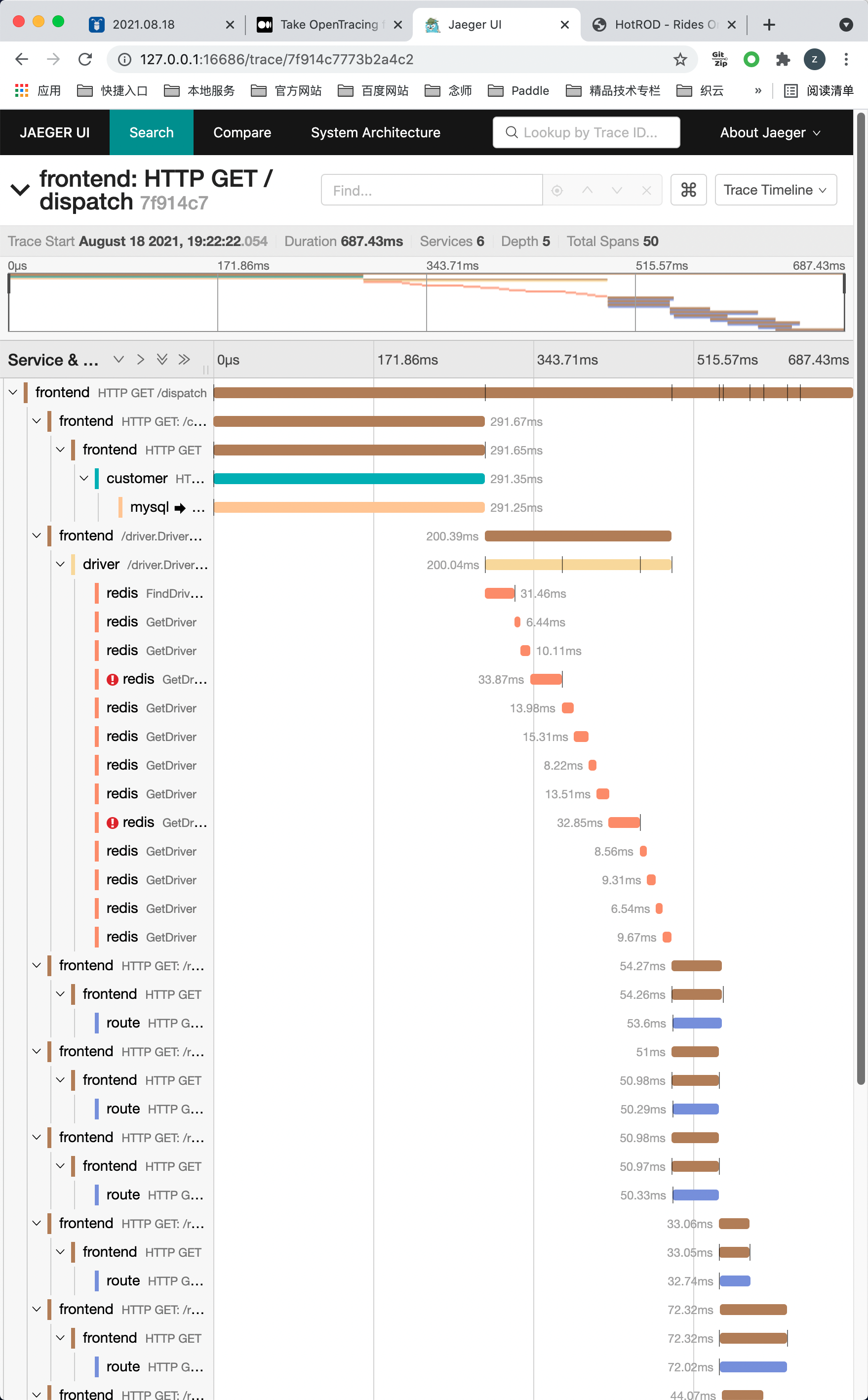
在这个时间线视图中,将 trace 的信息以嵌套的 span 的时间序列的方式显示了出来,其中每个span代表单个服务中一个工作单元。
其中:顶级span也称为根span,代表了从 HTTP 请求从前端UI frontend 服务发起到结束的完整耗时。
span 的宽度与给定的操作耗时成正比,表示在该时间段内,服务正在做一些计算工作或者是等待下游返回响应等。
从这个视图中,我们就可以看到HotROD系统是如何来处理用户请求的:
- frontend 前端服务接收到一个 HTTP GET 请求,访问的是 /dispatch url。
- frontend 前端服务发起了一个 HTTP GET 请求到 customer 服务的 /customer url。
- customer 服务调用 MySQL 执行了一个 SQL 的 Select 命令,该结果返回给了 frontend 服务。
- frontend 服务发起了一个 RPC 请求 Driver::findNearest 到 driver 服务,如果不详细展开 trace 信息,我们无从得知它具体是通过哪种PRC框架来实现的请求发送,但是应该不是HTTP协议。
- driver 服务进行了一系列的 Redis 调用,可以看到一些 Redis 调用旁边有红色的感叹号,表示这次调用其实是失败了。
- 之后,frontend 服务又多次通过 HTTP GET 请求调用了 route 服务的 /route url。
- 最后,frontend 服务返回给外部调用者响应结果。
此时,如果我们点击时间线视图中的任何 span 时,它会展开显示更多的详细信息,包括 span 标记、过程标签以及日志信息,例如,我们可以点击一个 Redis 失败的调用请求 span :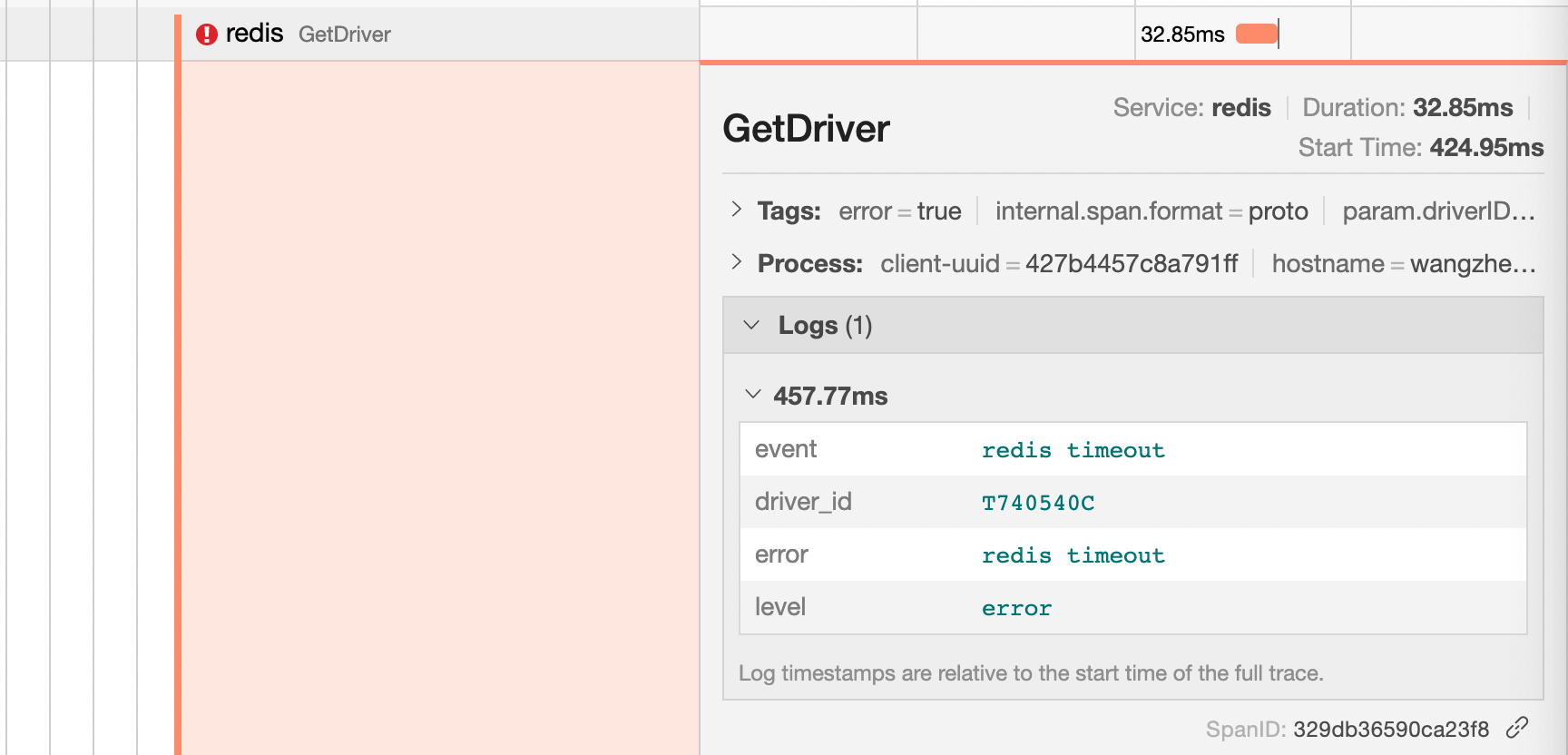
我们可以看到在该 span 上有一个 tag: error=true ,这个tag就是 Jaeger UI 页面上线时失败的原因。
此外,我们还可以看到它的日志信息,其中,错误信息是redis timeout,此外,我们还可以看到还显示出了Redis的driver_id。
step5: 上下文日志
现在,我们已经了解了整个系统的架构、数据调用流等相关的信息,但是对于系统的具体实现逻辑方面其实还没有深入的了解,例如,frontend 服务为什么需要调用 customer 服务?
当前,最基础的方法去了解一个系统的具体的逻辑就是直接去阅读源代码,但是有没有更加简单快捷的方法呢?我们是不是可以从应用监控的信息中来了解相关的信息呢?例如如果我们将应用程序的日志信息标注化打印并记录是不是就可以帮助我们理解系统实现内容了呢?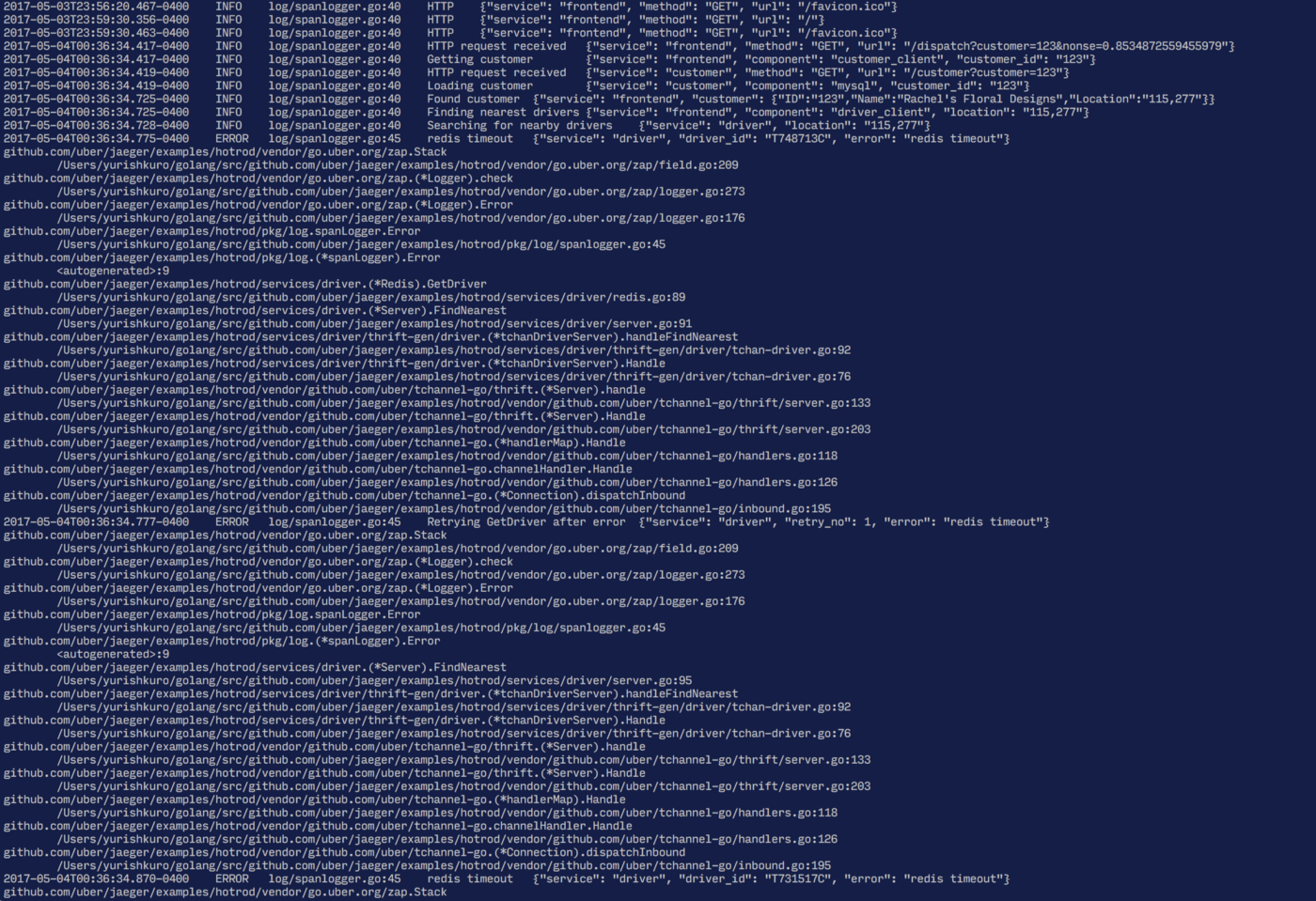
与上述传统的日志输出不同,我们其实仅关注于应用程序在发生请求调用时打印的日志信息。
想象一下,当我们的系统在并发处理很多请求时,日志直接如果没有天生的关联关系时,那么我们想要从日志中找出每一个请求的先后相关日志时,简直是一件不可能的事情。所以为了解决这一问题,我们采取一些解决方法,例如,我们可以将日志分组到span下,点击根span时,展开当前根span下的全部日志信息。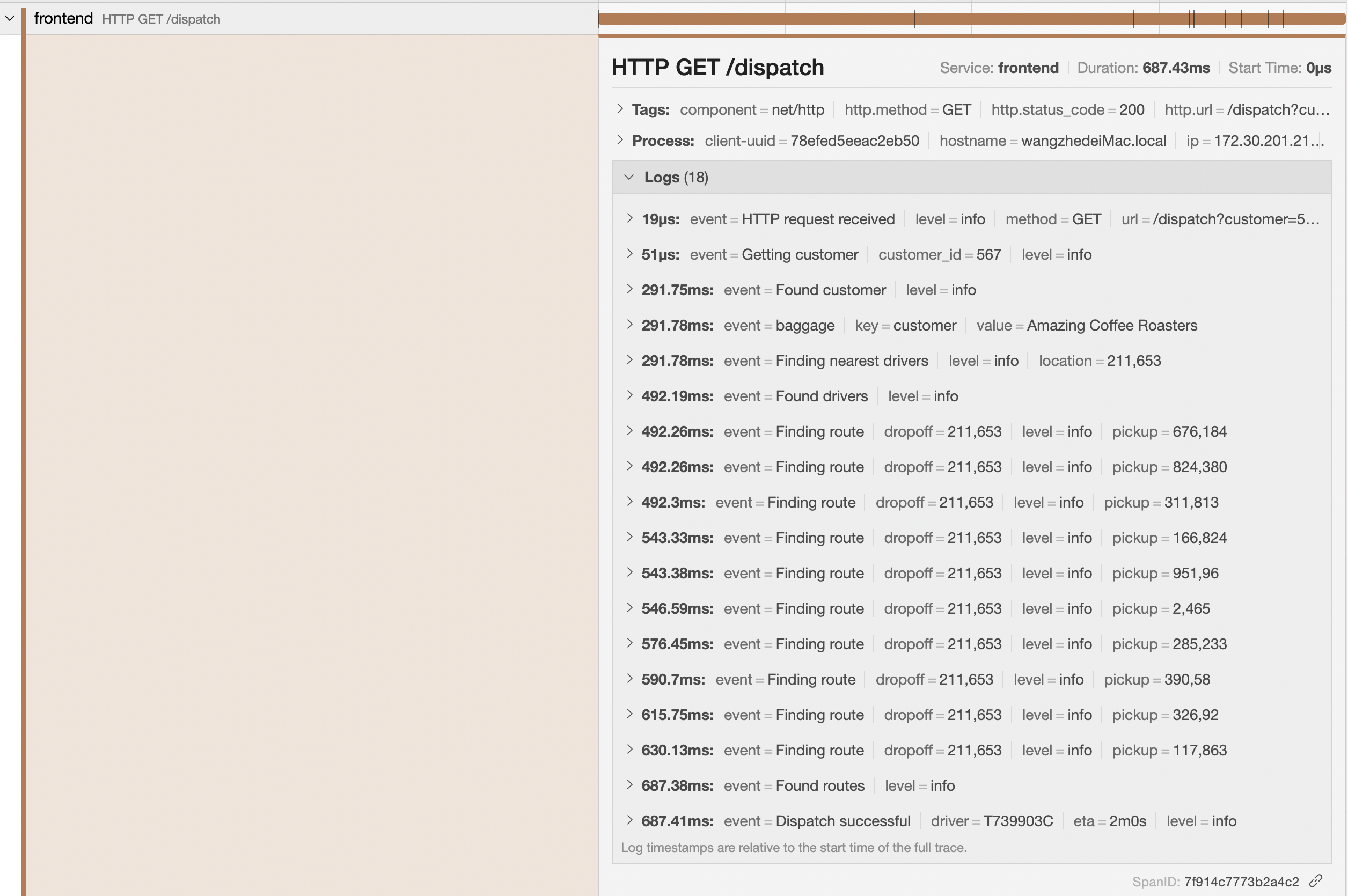
在该页面中,仅仅显示在当前span执行过程中所有打印的日志信息,因为我们是在特性请求的上下文中捕获的,我们称之为上下文日志。内容类似于我们之前已经看到了超时的Redis调用时打印的错误日志。
与传统的标准输出日志不同,上下文日志不会将不相关的请求日志混合在一起,而是根据服务之间的调用信息进行了巧妙的隔离。
上下文日志允许我们深入的分析和了解应用程序在处理某次请求时的行为,而无需受到来自其他并发请求的日志干扰。
step6: 对比span的Tag和日志
下面,我们可以继续展开更多的 span 信息。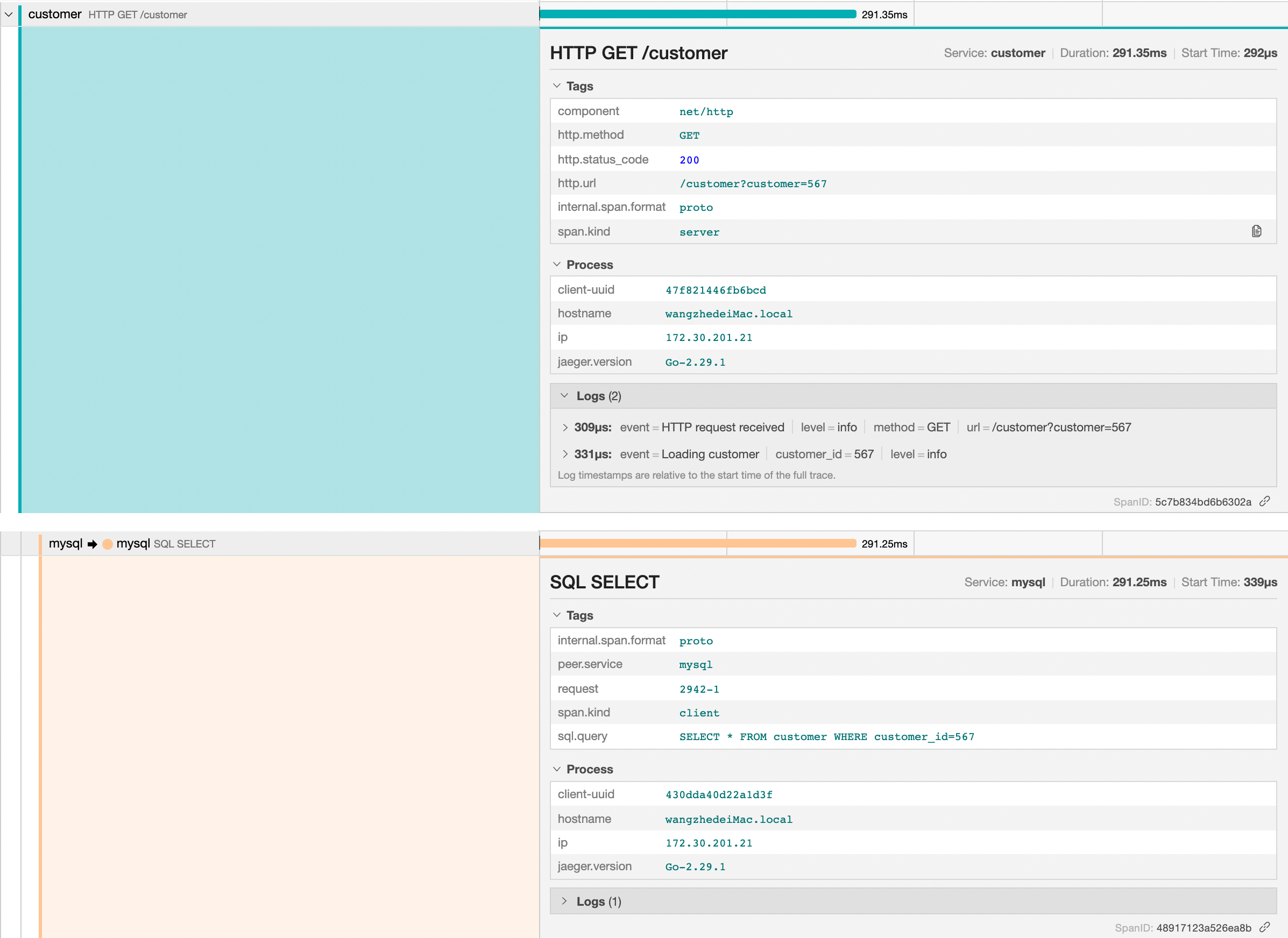
首先先来看一下 customer 的 span,我们可以看到一个 http.url 的 tag,它表示调用的 url 是 /customer,并且传递了 customer=567 的参数。
而在 mysql 的 span 中,我们可以看到 sql.query 的 tag,其中显示了完整执行的SQL查询命令。
这些内容是不是有点儿像日志信息呢?对于一些信息,我们应该如何判断它应该是存储到 span 的 tag 中还是 log 中呢?
在 OpenAPI的规范中,其实并没有给出明确的规范和约束,不过一般的一个通用的原则是适用于整个span的信息应该作为tag来记录,而具有时间戳的相关记录信息应该作为log来记录。
OpenTracing 规范中定义了一些语义数据的约定,这些约定为常见的场景规定了一些常用的标签名称和日志字段。在我们使用的过程中,非常建议可以使用这些字段和名称,从而可以一方面明确相关的数据的语义,另一方面可以在不同的存储后端都能够做到完全兼容。
step7: 分析延迟原因
到此为止,我们其实讨论的都还是 HotROD 系统的功能,还没有讨论相关的性能数据。如果我们翻回去看一下 trace 的截图,我们可以很容易的得到如下的结论:
- 调用 customer 服务是阻塞的,在 customer 服务响应返回之前系统无法做其他事情,包括我们需要派车的位置。
- driver 服务根据customer的位置检索了最近的10个司机,然后按照顺序查询Redis中每个司机的数据,相关的数据可以在 redis GetDriver span中看到。
- 对 route 服务的调用并不是完全顺序执行的,但也不是全并发的。我们可以看出在任一时刻中,最多同时有三个请求同时发送给route服务,当之前的请求结束后,后续的请求就会开始,很显然,这是一种固定大小的执行器池的一种行为表现。
如果我们同时向后端发出多个请求时会出现什么情况呢?让我们回到HotROD页面,并快速单击其中的一个按钮:
正如我们上图中看到的结果,当并发处理的请求越多时,后端处理的响应耗时也就越长。
我们来看看最长耗时的请求对应的trace信息。
Ps: 查询的方法有两种,一是直接根据trace耗时的长度找出其中最大的trace,二是可以直接根据tags进行过滤搜索,例如,我们可以搜索driver=T727568C来进行搜索。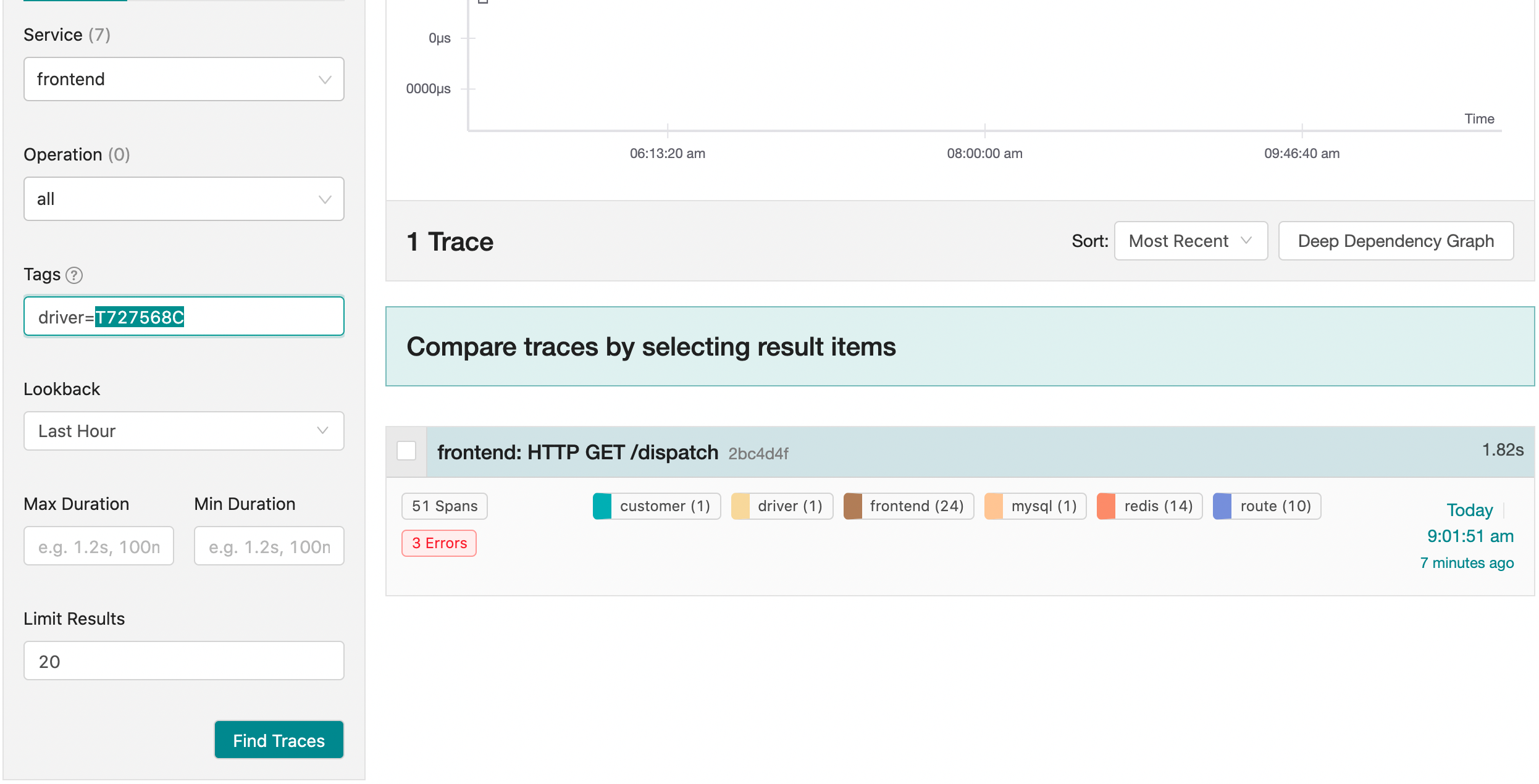
让我们打开这条1.8秒长的trace数据并且与我们之前0.6s左右的trace记录进行比较。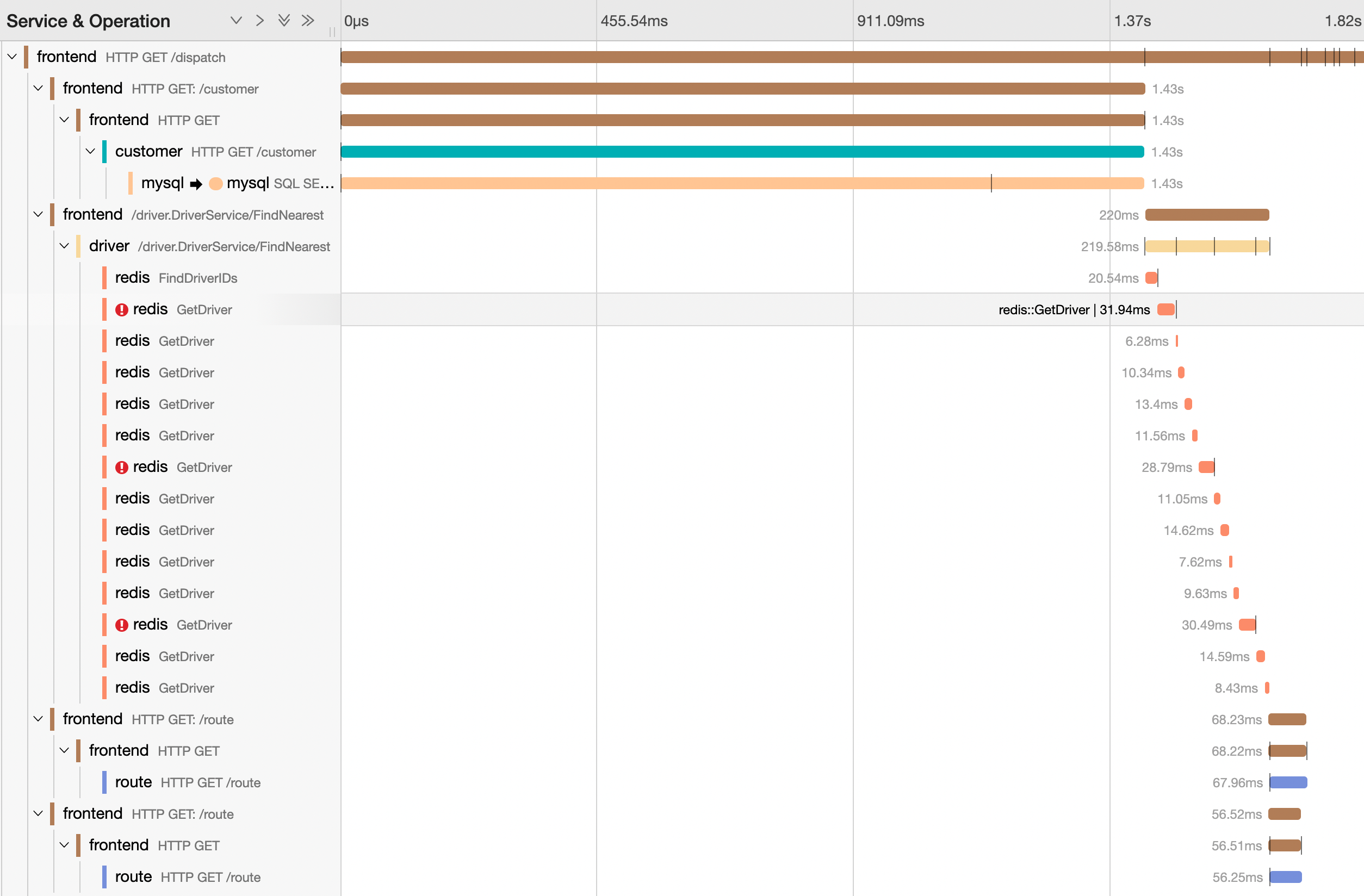
其中,很明显的看到的是mysql 的 span 长度远远比之前的耗时长了很多,从300ms变为了1.43s。下面,我们展开mysql的相关span信息,并尝试来分析一下相关的原因: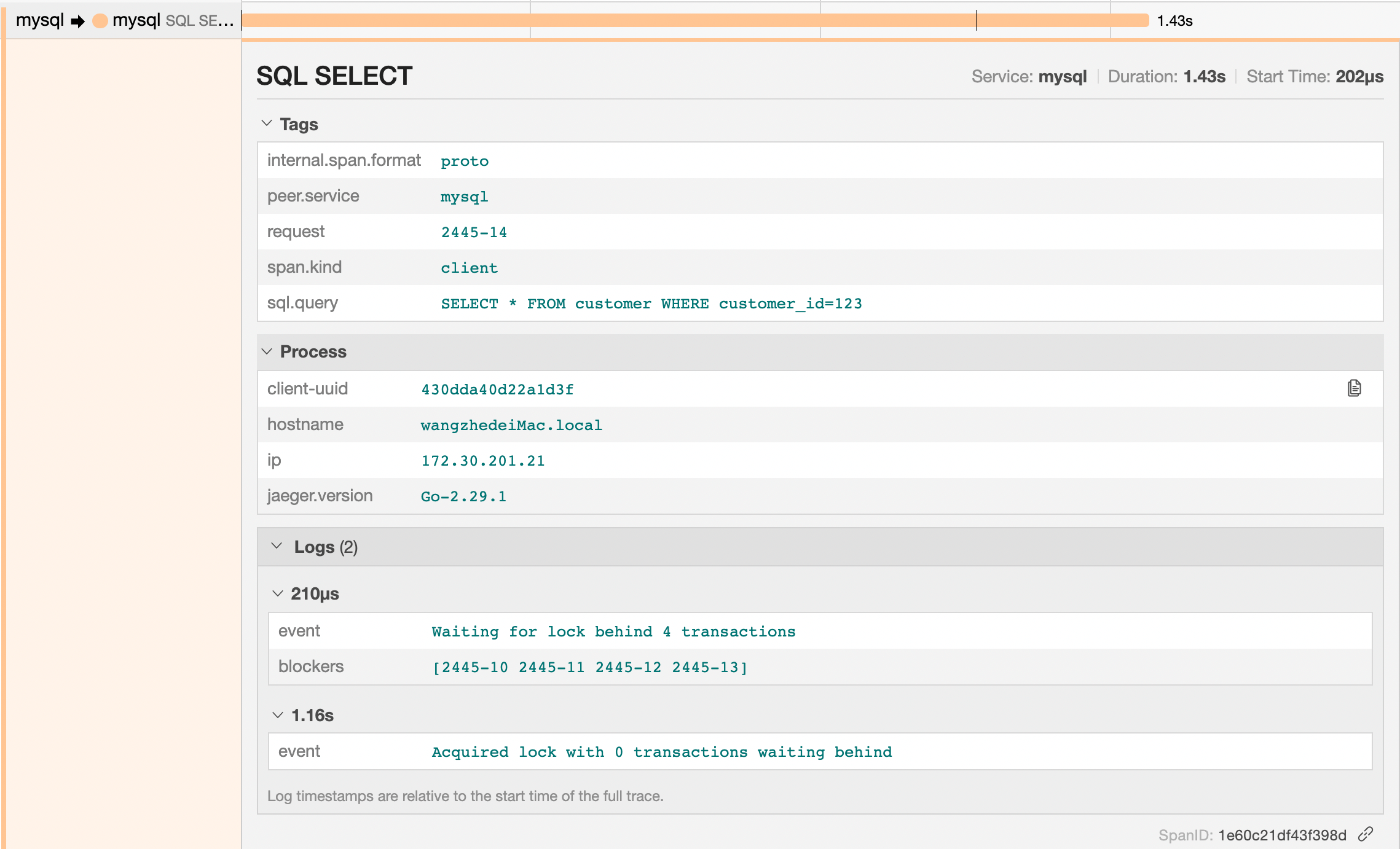
从日志中我们可以看到,当前请求并block了超过1s的时间。这显然是应用程序中目前最大的瓶颈点。在我们深入优化之前,我们先看一下上面210us的log记录,它告诉了我们当前已经有哪些请求在排队等待这个锁了,甚至给出了我们这个锁的身份信息。对于一个锁实现而言,能够知道有多少个gorouting正在排队获取这个锁的信息其实并不难,但是它是怎么知道每个获取该锁的请求的身份信息的呢?如果我们展开之前customer服务的span,我们唯一能够看到的是在这个HTTP请求中传递了一个 consumer id 为123。实际上,即使我们检查整个trace中的每个span,我们也都找不到任何一个请求中有像2445-10这样的请求信息在参数中进行了传递。
这个神奇的能力其实是 OpenTracing 中的 Baggage 特性帮助我们实现的。分布式 trace 之所以有效,其中本质的要求是因为将某些元数据通过 OpenTracing API的 trace 工具进行跨线程和跨进程的边界进行了传播,从而贯穿了整个调用链。此类元数据最典型的就是trace和spanID了,而另外一类数据就是Baggage,它是嵌入在每个进程间请求中的通用键值对存储。
在 HotROD 的 JavaScript UI向后端发出请求之前,就已经将SessionID和RequestID存储在了baggage中,而 baggage 的机制保证了每个服务在请求调用中会将该信息自动发送给调用链的下游服务,而无需业务服务自己显示传递对应的参数。这是一个非常非常强大的技术,它可以帮助我们在整个系统的架构的调用中自动的传递相关的一些有效信息(例如token等),在这个过程中,整个业务服务其实是透明和无感的。
在我们的示例中,在我们分析长尾请求之前,能够知道队列中当前排队的请求的标识可以让我们能够找到这些请求的trace信息并进行相关的分析。在实际生产系统中,我们就可能能通过这一机制发现一些由于一些异常的长时间运行的请求导致阻塞其他一些原本应该非常块的请求被阻塞。
现在,我们已经找到了当前的 mysql 调用的阻塞点其实是卡在了 block 上,下面,我们来修复一下这个问题吧。之前我们其实就提到了,在我们的示例服务中,MySQL其实并不是真实部署的,而是模拟的,并且锁是为了表示多个 gorouting 之间共享的单个数据库链接。我们可以在 examples/hotrod/services/customer/database.go 文件中看到源代码:
// simulate misconfigured connection pool that only gives// one connection at a timed.lock.Lock(ctx)defer d.lock.Unlock()// simulate db query delaydelay.Sleep(config.MySQLGetDelay, config.MySQLGetDelayStdDev)
请注意我们是如何将 ctx 参数传递给 Lock 对象的。
在 Go 语言中,context.Context 是一个标准的方法来在应用内部传递请求的上下文数据的。其中,OpenTracing 的 span 信息也存储在 context 中,它允许 lock 读取对应的上下文信息并从 baggage 中获取 JavaScript 中生成的请求ID。
下面,我们来对源代码进行一些修改。
首先,我们注释掉lock语句来模拟我们修复的代码中的锁问题,从而能够满足并发请求来避免一些不必要的排队机制。
另外,我们将 config.MySQLGetDelay 配置从300ms修改到100ms。
然后,我们来重启 HotROD 应用并重复该实验。
此时,随着我们向系统中添加更多的请求,虽然延迟还是有略微的增加,但是已经不像之前单个MySQL瓶颈导致性能急剧退化的问题出现了。
下面,我们再来选择一个耗时相对较长的请求来进行分析一下: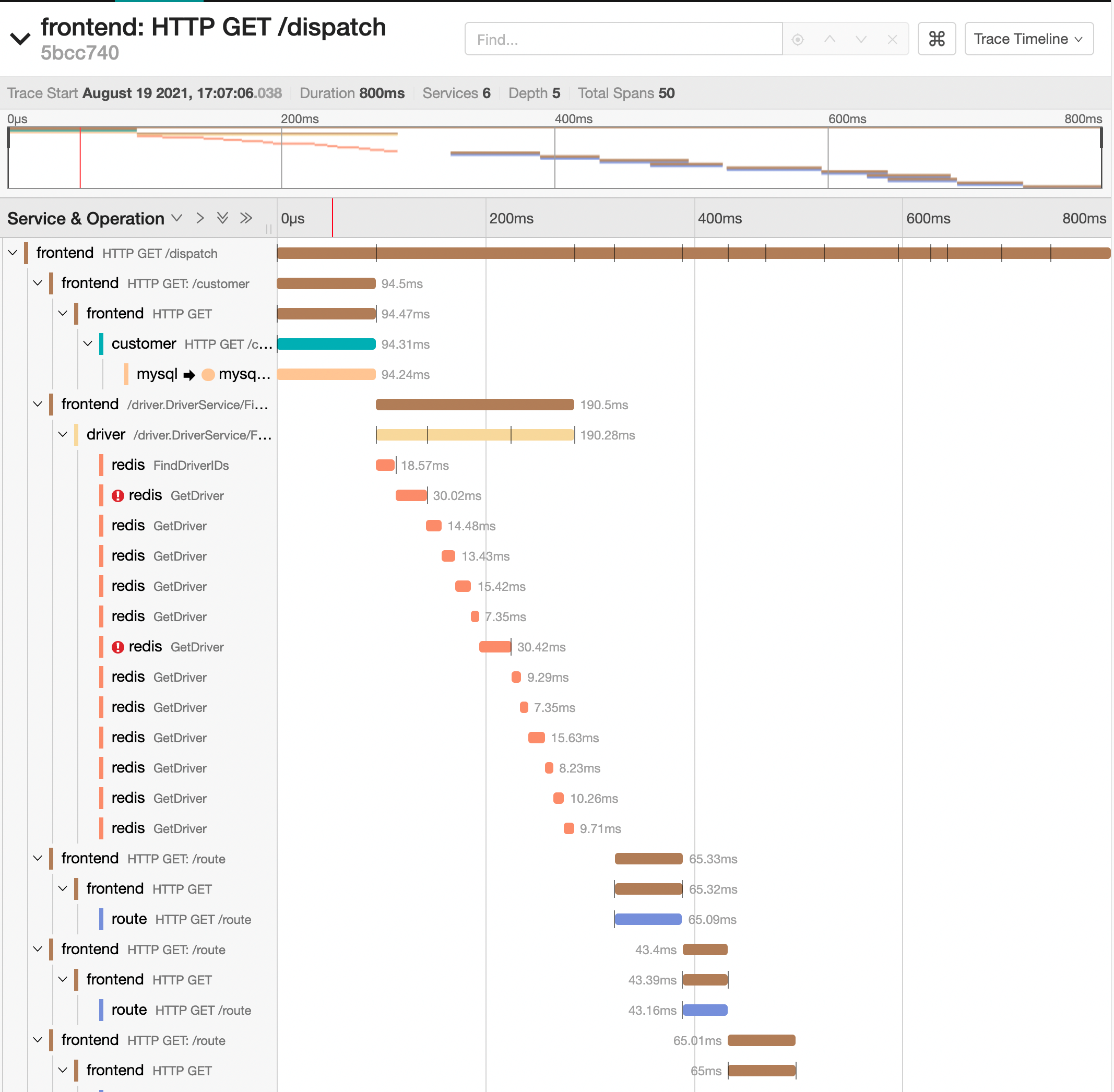
正如我们期望的那样,无论并发有多大,mysql 的 span 耗时都保持在 100ms 左右。
同时,driver 服务调用耗时也没有变大,和之前的情况基本是一样的。
但是对应 route 服务的调用就比较有趣了!它占用了总耗时的一半以上。在之前的场景中,我们看到route的调用的并行度是3,表示3个route服务的调用是同时进行的,但是最新的结果中,route的服务好像又成为了顺序调用了。显然,它是和其他的gorouting发生了竞争导致的。甚至我们还可以看到frontend服务调用route服务时,甚至还存在着空白的等待时间段,这表明目前的瓶颈其实不在route服务,而是在于frontend服务对route服务的调用上。
下面,我们来看一下 services/frontend/best_eta.go 文件中的 getRoutes() 函数:
// getRoutes calls Route service for each (customer, driver) pairfunc (eta *bestETA) getRoutes(ctx context.Context,customer *customer.Customer,drivers []driver.Driver,) []routeResult {results := make([]routeResult, 0, len(drivers))wg := sync.WaitGroup{}routesLock := sync.Mutex{}for _, dd := range drivers {wg.Add(1)driver := dd // capture loop var// Use worker pool to (potentially) execute// requests in paralleleta.pool.Execute(func() {route, err := eta.route.FindRoute(ctx, driver.Location, customer.Location)routesLock.Lock()results = append(results, routeResult{driver: driver.DriverID,route: route,err: err,})routesLock.Unlock()wg.Done()})}wg.Wait()return results}
这个函数接收了客户信息(包括客户位置)和司机列表(包括当前司机的位置),并计算了每个司机预计到达的时间。它使用了一个执行程序池来为每个驱动程序调用路由服务。所以,只要执行池中有足够多的执行器,我们就应该能够并行运行所有的计算。
其中,执行池的大小定义在 services/config/config.go 文件中:
RouteWorkerPoolSize = 3
默认情况下,执行池的大小被设置为了3,这也就解释了为什么单个任务运行时,我们可以看到frontend是3个并发调用route服务的。现在,我们把这个配置修改为100,然后重启 HotROD 服务看看。
页面响应的速度是不是明显快了很多?通过数据我们也可以看到现在的耗时仅仅只有之前的一半左右了。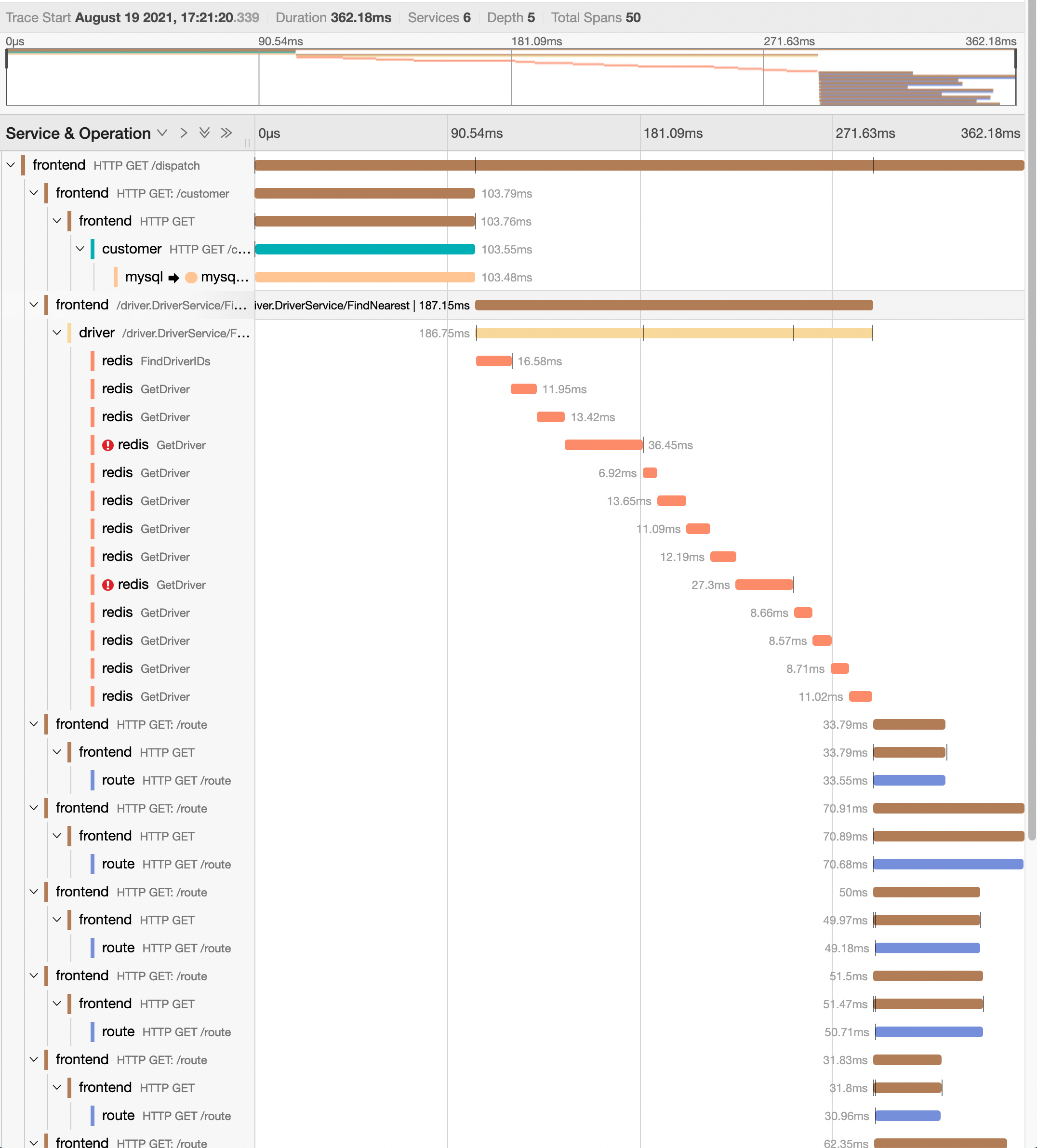
正如我们期待的一样,现在frontend服务对route服务的调用已经变成了全并发了,因此整体的耗时有了明显的减少。
最后,我们再看来一下 driver 对 redis 的调用,是不是也可以改成并发的呢?试着优化一下吧!
step8: 通过baggage机制来收集资源使用率
收集资源使用率的事情听起来好像不太重要,但是当一些大型系统想要优化资源利用情况时,它们总是必不可少的,我们可能需要验证不同业务参数配置的情况下的资源使用情况。
例如,route 服务中计算最短路径的操作可能就是一个 CPU 密集型的操作,如果能够计算出针对每个用户调度请求消耗了多少CPU执行时间,那么对我们来说还是很有用的。
但是,由于 route 服务只是在整个调用链最后被调用的,而对于之前被调用的服务,比如 customer 服务,它其实不需要知道客户订单中的起点和终点的信息。如果单纯为了计算CPU的使用情况,而需要我们将客户的ID信息传递给 route 服务而能将相关的信息关联起来,这其实是一个比较糟糕的设计。
为了不需要额外传入相关的信息,我们就是利用trace和baggage的机制来帮助我们了。在 trace 的上下文中,我们其实是可以知道当前请求中系统正在为哪个客户执行请求的,并且我们可以通过 baggage 机制在整体系统的架构中透明的传递该信息而无需显示的修改所有的服务来明确接受它。而且,即使我们希望修改一种其他的方式(例如SessionID)来聚合CPU使用率的相关数据时,我们也完全不需要修改我们的业务代码。
为了演示这一功能,route 服务需要包含一些代码来从 baggage 中读取 custom 和 sessionID 信息并计算CPU的使用时间。具体的代码在 services/route/server.go 文件中,示例如下:
func computeRoute(ctx context.Context,pickup, dropoff string,) *Route {start := time.Now()defer func() {updateCalcStats(ctx, time.Since(start))}()// actual calculation}
此时,我们不需要传递任何的 customer 或者 SessionID 信息,因为它们其实是可以自动从 baggage 的上下文来读取的。而 updateCalcStats 函数使用了Go的标准库 expvar 包来累加计算和表示结果:
var routeCalcByCustomer = expvar.NewMap("route.calc.by.customer.sec",)var routeCalcBySession = expvar.NewMap("route.calc.by.session.sec",)var stats = []struct {expvar *expvar.Mapbaggage string}{{routeCalcByCustomer, "customer"},{routeCalcBySession, "session"},}func updateCalcStats(ctx context.Context, delay time.Duration) {span := opentracing.SpanFromContext(ctx)if span == nil {return}delaySec := float64(delay/time.Millisecond) / 1000.0for _, s := range stats {key := span.BaggageItem(s.baggage)if key != "" {s.expvar.AddFloat(key, delaySec)}}}
此时,如果我们访问 http://127.0.0.1:8083/debug/vars ,我们可以看到 route.calc.by.* 开头的指标表示了针对不同 customer 和 SessionID 的计算耗费的时间。
"route.calc.by.customer.sec": {"Amazing Coffee Roasters": 0.494, "Rachel's Floral Designs": 0.472},"route.calc.by.session.sec": {"2942": 0.494, "7172": 0.472},
step9: 嵌入OpenTracing
关于 OpenTracing 的嵌入其实是另外一篇文章的主题了。
但是值得提一下的是,HotROD 的源代码中,对 OpenTracing 的注入并不复杂。例如, driver 服务暴露了一个 TChannel 的服务,类似如下:
// NewServer creates a new driver.Serverfunc NewServer(hostPort string,tracer opentracing.Tracer,metricsFactory metrics.Factory,logger log.Factory,) *Server {channelOpts := &tchannel.ChannelOptions{Tracer: tracer,}ch, err := tchannel.NewChannel("driver", channelOpts)if err != nil {logger.Bg().Fatal("Cannot create TChannel", zap.Error(err))}server := thrift.NewServer(ch)
与 OpenTracing 唯一相关的内容其实是在 options 中传入 tracer。
而在业务服务的实现中,其实并没有直接引用 OpenTracing,例如 services/driver/server.go 文件:
// FindNearest implements Thrift interface TChanDriverfunc (s *Server) FindNearest(ctx thrift.Context,location string,) ([]*driver.DriverLocation, error) {s.logger.For(ctx).Info("Searching for nearby drivers",zap.String("location", location))driverIDs := s.redis.FindDriverIDs(ctx, location)
这是因为开源框架 TChannel 以及与 OpenTracing 进行了集成。因此,当我们创建一个应用时,只需要实例化一个具体的 tracer 并将其传入即可。
同样,对于 HTTP 服务而言,我们看到的 OpenTracing 的集成代码其实也很少。事实上,唯一直接调用 OpenTracing 的地方其实就是在模拟Redis和MySQL的函数中,我们在这一过程中,我们实际上没有通过任何框架发出RPC请求。
step10: 关于服务中立
我们一开始其实就提到了,在使用 OpenTracing 来注入应用程序时,可以避免后端服务强制绑定于某一款分布式追踪的后端服务。HotROD 程序其实可以很轻易的将后端分布式Trace存储服务从Jaeger 迁移到Lightstep或者Appdash等。而应用程序中,唯一需要修改的源代码其实就是 pkg/tracing/init.go 文件中的 Init 函数。
// Init creates a new instance of Jaeger tracer.func Init(serviceName string,metricsFactory metrics.Factory,logger log.Factory,) opentracing.Tracer {cfg := config.Configuration{Sampler: &config.SamplerConfig{Type: "const",Param: 1,},Reporter: &config.ReporterConfig{LogSpans: false,BufferFlushInterval: 1 * time.Second,},}tracer, _, err := cfg.New(serviceName,)if err != nil {logger.Bg().Fatal("cannot initialize Jaeger Tracer",zap.Error(err),)}return tracer}
step11: 关于日志记录
在之前的内容中,我们已经看到了 trace 中已经包含了应用的上下文日志信息。那么这些日志信息是如何发送到tracing 后端服务的呢?是我们的代码需要直接调用 OpenTracing Span 相关的方法吗?
在 FindNearest 函数中,我们可以看到类似的日志打印示例:
s.logger.For(ctx).Info("Searching for nearby drivers",zap.String("location", location),)
其中,表达式 zap.String(k, v) 就是 Go 的一个支持结构化日志的日志打印库 zap,因此,其实我们没有针对 OpenTracing 特殊编写任何的内容。
我们在 HotROD 中使用的日志打印技巧其实是关于 Zap 日志打印的一些封装,它提供了两种方法:
For(context.Context)为请求范围的日志返回上下文记录信息。Bg()返回了一个后台记录器,用于记录不在请求范围内的事件,例如应用程序启动过程中打印的相关日志。
调用一个上下文日志器时,总是需要一个 Context 对象。当我们有了上下文 Context 对象后,所有正常打印的日志方法不但会进行正常的日志打印,同时还会转换为对 span 上的日志记录。
相关的源代码可以在 pkg/log/spanlogger.go 文件中看到:
func (sl spanLogger) Info(msg string, fields ...zapcore.Field) {sl.logToSpan("info", msg, fields...)sl.logger.Info(msg, fields...)}
step12: OpenTracing 其实不仅仅用于追踪场景
我们已经了解到了 trace 是如何通过在对应的 trace 上下文中记录和查询日志从而实现日志聚合等相关的功能了。而对于微服务监控的另外一个核心要求,端点的指标收集我们是否可以实现呢?
事实证明,使用 OpenTracing API 的方法往往是通过端点收集监控指标的超集。RPC 服务端点指标中,最常见的指标主要包括请求计数、错误计数和请求延迟分布等。而OpenTracing其实已经采集了所有这些相关的信息,并且可以在没有额外相关工作的情况下能实现相关的功能。
Go 的 Jaeger tracer 提供了一个选项来查询相关的指标,在 HotROD 的demo中,我们已经进行了启用。
如果你访问 http://127.0.0.1:8083/debug/vars 地址,将会看到我们已经为应用程序中的所有端点收集了各种指标。
例如,我们可以看到有 24 个成功的请求到 /customer 端点并且零错误。
expvar 的 /debug/vars 端点是一种显示 RPC 指标的原始方式,下图是 Uber 内部仪表板的另一个示例。 所有这些指标都由 OpenTracing 检测和 Jaeger 跟踪器发出。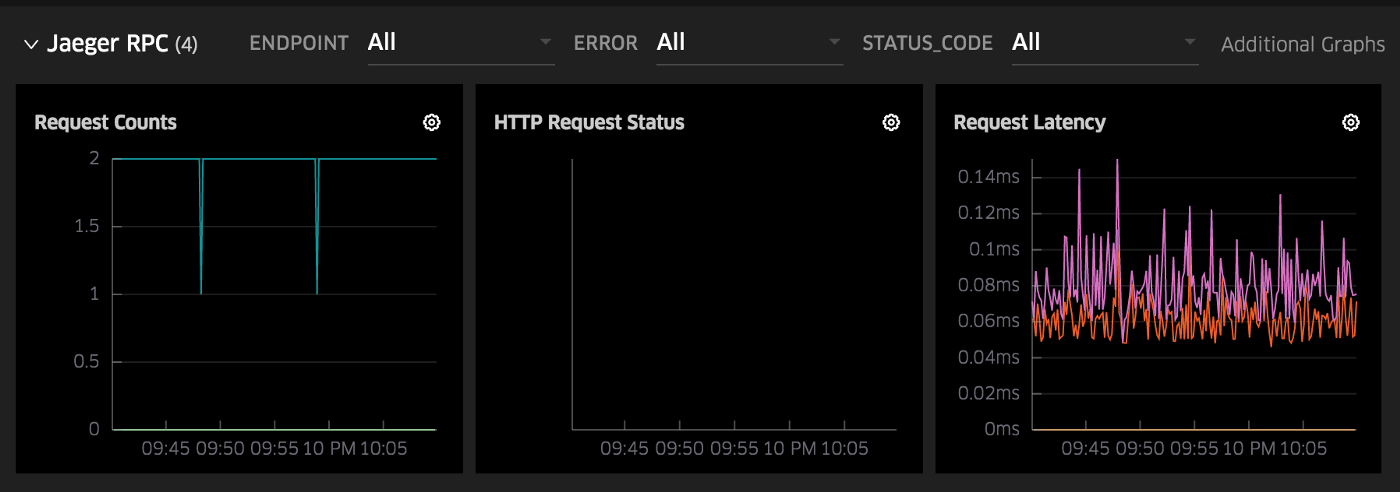
从Zipkin迁移
Collector 服务可以暴露出一个 Zipkin 兼容的 REST API /api/v1/spans 来接收 Thrift 和 JSON 格式的数据,同时,它还提供了 /api/v2/spans 的接口来接收 JSON 和 Proto 数据。
默认情况下,该服务是没有开启的,需要使用 --collector.zipkin.host-port=:9411 参数来启用。
其中,Zipkin 的 Thrift 和 Profo 的数据格式文件可以在 jaegertracing/jaeger-idl 代码库中找到,这个与 zipkin 对外提供的 Thrift 和 Proto 的协议都是兼容的,因此,用户可以轻松的将 Zipkin 的后端迁移到 Jaeger。

若有收获,就点个赞吧
0 人点赞
