说明
Jaeger 的客户端完全遵循 Opentracing 标准中定义的数据模型。
因此,阅读 OpenTracing 的规范可以帮助你更好的理解本文的内容。
术语定义
下面,我们先简单复习一下 OpenTracing 规范中定义的一些术语。
Span
Span 代表 Jaeger 中的逻辑工作单元,它具有操作名称、操作的开始时间和持续时间。
Span 可以嵌套和排序以模拟系统的调用和因果关系。
Trace
一个 trace 表示系统中的一次调用链,它可以被看做是 span 组成的有向无环的图。
系统组件
Jaeger 既可以用一个 all-in-one 的二进制程序来启动,它在一个进程中包含了 Jaeger 所有的后端组件。
同时,Jaeger 还可以使用分布式的方法进行部署,从而可以实现横向扩容,其中可以包含两个部署选项:
- collectors 数据直接写入存储。
- collectors 数据先写入 Kafka 作为初步缓冲。
collector直接写入存储的分布式部署的整体架构图如下: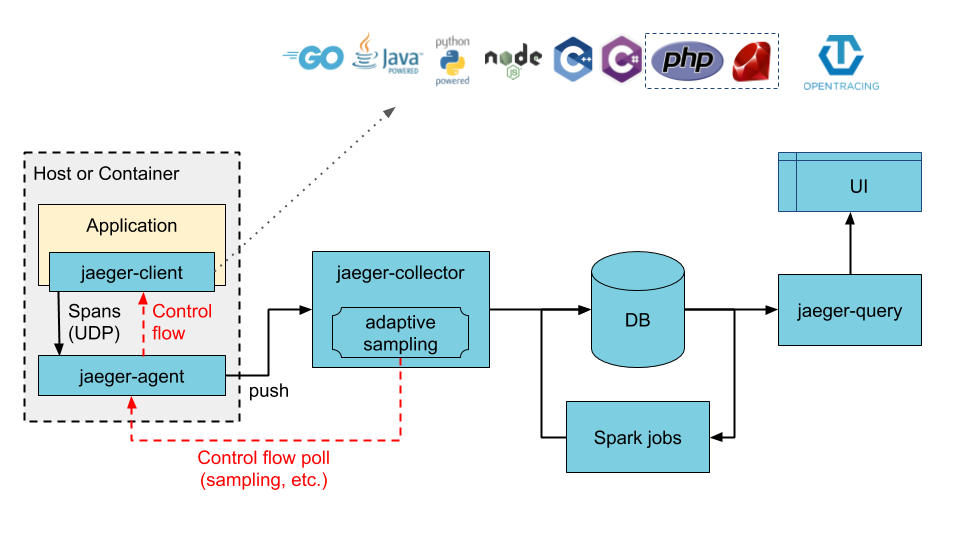
collector 先写入Kafka 的整体架构图如下: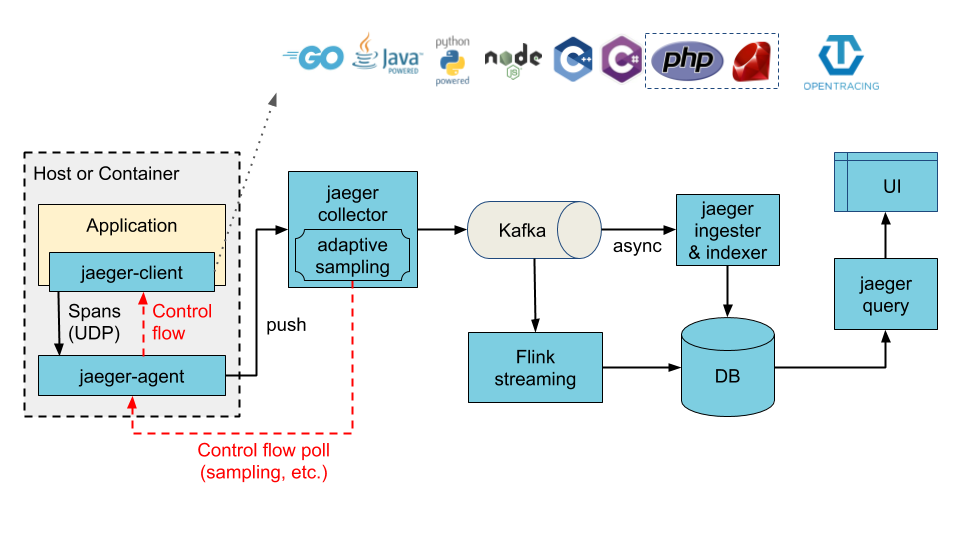
在本文中,我们将会详解介绍 Jaeger 的组成部分以及它们之间的关系。
接下来,我们将会按照 span 数据在整个系统中流动的顺序来依次进行讲解。
Jaeger 客户端库
Jaeger 客户端是 OpenTracing API 的特定语言实现。
它们可用于手动注入或使用各种现有的开源框架(例如 Flask、Dropwizard、gRPC 等,已与 OpenTracing 集成)来应用到分布式跟踪的应用程序中。
Jaeger 客户端在接收新请求时创建跨度,并将上下文信息(trace id、span id 和baggage)附加到调用外部请求。 其中,在调用其他服务是,只有 ID 和 baggage 会随请求一起传播;所有其他分析数据,如操作名称、时间、标签和日志,都不会传播。相反,它在后台异步传输到到 Jaeger 的后端服务。
Jaeger 注入的客户端在生产环境中默认是开启的。为了最大限度的减少资源开销,Jaeger 客户端可以配置各种不同的策略。
当一个 trace 信息被采样时,会分析其中的 span 数据并传输到 Jaeger 的后端;而当一个 trace 信息未被采样时,则会跳过收集和分析数据并跳过对 OpenTracing API 的调用从而降低整体系统的开销。
默认情况下,Jaeger 客户端对0.1%的trace信息进行采样,并且能够从Jaeger后端中查询到当前的采样策略。关于采样更多的信息,可以参考采样一文。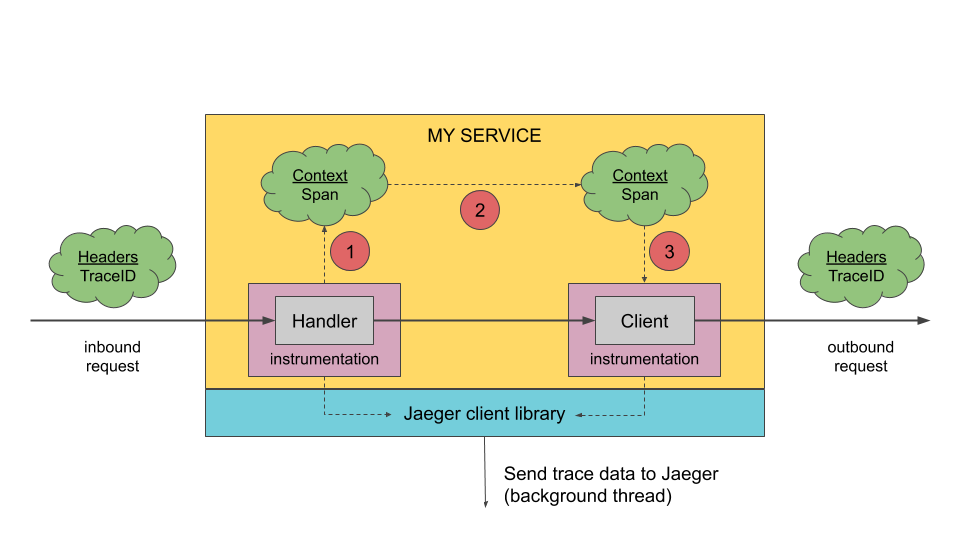
Agent
Jaeger Agent 是一个网络daemon进程,它通过监听UDP协议的span数据并批量发送给给Collector模块。它在设计上被作为基础组件部署到所有的主机上的。通过 Jaeger Agent,可以将 Collectors 的路由和发现机制抽象到 Jaeger Agent 侧,避免在 Client 中绑定。
Collector
Jaeger Collector 从 Jaeger Agent 处接收 span 数据并通过 Pipeline 来处理这些数据。其中,Pipeline 的功能包括 traces 数据的验证、检索、转换以及存储。
另外,Jaeger 的存储是一个可插拔的组件,目前支持 Cassandra, ElasticSearch 和 Kafka等。
Query
Query 服务是用于从存储服务中检索 traces 数据的,它同时提供了一个 UI 页面来友好的显示相关的数据。
Ingester
Ingester 服务主要用于从 Kafka Topic中读取数据并写入存储后端(Cassandra、ElasticSearch)的服务。

若有收获,就点个赞吧
0 人点赞
