概述
现实情况下会有很多类似过滤重复的需求,比如说爬虫爬网站需要过滤已经爬过的URL,自媒体推送新闻需要过滤掉那些已经阅读过的新闻,redis作为缓存时防止击穿也需要对请求过滤,防止大量请求不存在数据造成的冲击。这些情况下,就需要布隆过滤器了,他能够在完成去重的任务下还能节省空间,但是会有一定的误判。
redis中的布隆过滤器
可以简单理解set结构。布隆过滤器判定某个值存在时可能会有误判,但是判定某个值不存在时,一定是精确的。redis在4.0版本提供了插件功能,布隆过滤器作为一个插件加载到redis server中。基本命令如下:
bf.add key valuebf.exists key valuebf.madd key value1 value2bf.mexists key value1 value2
过滤器默认的误判率在1%左右,但是,redis提供了对过滤器基本参数的设置,如下:
key:布隆过滤器的key,每个key低层对应一个具体的数据结构
error_rate:错误率,数值越小,所需空间越大
initial_size:预计放入元素的数量,当数量超过这个值后,错误率会上升
原理
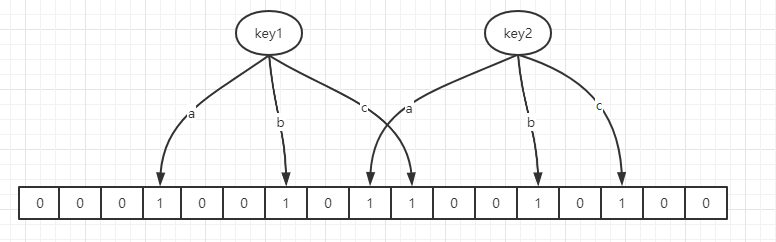
对于添加一个key,通过不同的hash函数进行hash,算的一个整数索引值,然后对数组长度取模得到一个位置,把该位置置为1。同样,在判断一个key是否存在时,也是用不同的hash函数计算得到一个在数组上的位置,看看该位置是否为1,如果所有的hash函数计算得到的位置上都为1,则该元素大概率存在,如果有一个位置不为1,则该元素必然不存在。
使用
由原理可知在使用时,初始化数量一定要大于实际数量,同时,如果实际数量开始超出初始数量,应该新建一个布隆过滤器,重新分配一个size更大的过滤器,再讲所有历史元素批量add进去,所以我们应该有一个地方用来存储原来放入过的元素。
还有一个点需要注意的是,误判率不会在实际元素一超过初始化数量是就急剧变大,而是一个相对缓慢的过程。
redis在4.0版本提供了布隆过滤器插件,如果版本较低,可以采用三方实现,java可以使用orestes-bloomfilter,可以到最大的同性交友网站下载。

若有收获,就点个赞吧
0 人点赞
