做可变剪切分析时,会依次进行基因水平和转录本水平的差异分析,最后通常需要进行ENSEMBL ID和 transcript ID (ENSEMBLTRANS)以及gene symbol对应起来。
ENSEMBL数据框中gene id通常是ENSMUSG开头的编号,而transcript id以ENSMUST开头的编号,这些信息通常在gtf文件以tab键分隔的第9列中。目前org.Mm.eg.db和org.Hs.eg.db也能进行对应查找,但是本人昨天在进行transcript id转gene id时提示82.05% failed to map,最后得到的转录本从4万变成1万,于是决定直接从gtf文件中查找。
首先,我们先来查看下gtf文件
cat Mus_musculus.GRCm39.105.gtf | less -SN
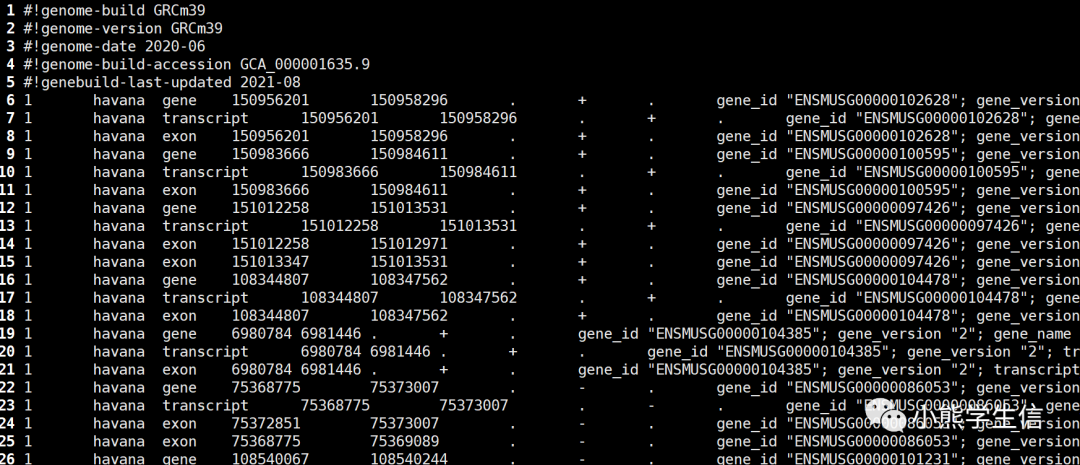
可以看到前面5行时注释信息,gene_id, transcript_id, gene_name信息都在以tab键分隔的第9列中。采用以下代码直接将同时包含ENSMUSG和ENSMUST提取出来。
cat Mus_musculus.GRCm39.105.gtf | awk -F '\t' '{if(NR>5) print$9}' | awk -F ' ' '{print$2,$6}' | sed 's/"//g' | sed 's/;//g' | grep 'ENSMUST' | tr ' ' '\t'>Mus_musculus.GRCm39.105.gene_to_transcript.txt
这个代码去掉了前5行注释行,同时将gtf文件中的”和;符号都去去掉,最后生成以tab键分隔的txt文档。最后得到的Mus_musculus.GRCm39.105.gene_to_transcript.txt文件如下: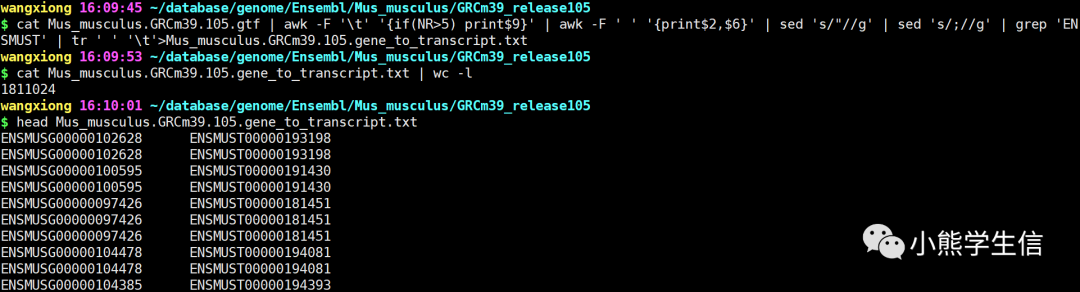
这里可以看到transcript_id有重复的,总共有1811024行,对第二列进行去重。
sort -t $'\t' -k 2 -u Mus_musculus.GRCm39.105.gene_to_transcript.txt -o Mus_musculus.GRCm39.105.gene_to_transcript.txt
最后得到142435行转录本和基因对应关系。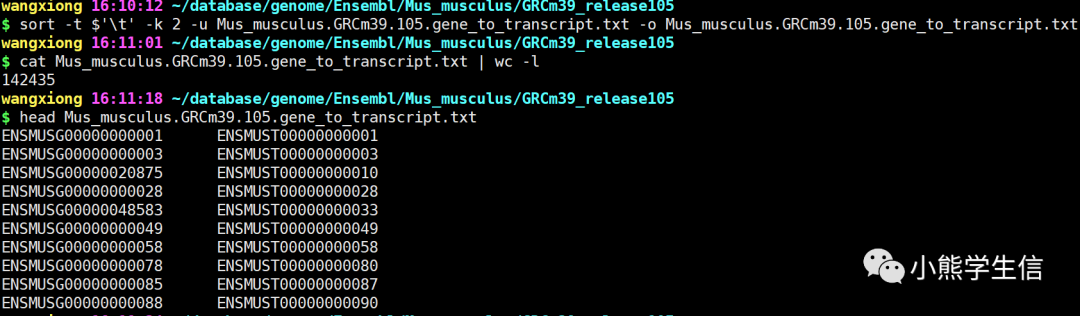
接下来就是提取gene_id和gene_name对应信息了,代码如下:
cat Mus_musculus.GRCm39.105.gtf | awk -F '\t' '{if(NR>5) print$9}' | awk -F ' ' '{print$2,$6}' | sed 's/"//g' | sed 's/;//g' | grep -v 'ENSMUST' | tr ' ' '\t'>Mus_musculus.GRCm39.105.ENSEMBL_to_SYMBOL.txt
生成的Mus_musculus.GRCm39.105.ENSEMBL_to_SYMBOL.txt文件如下,总共包含55414基因: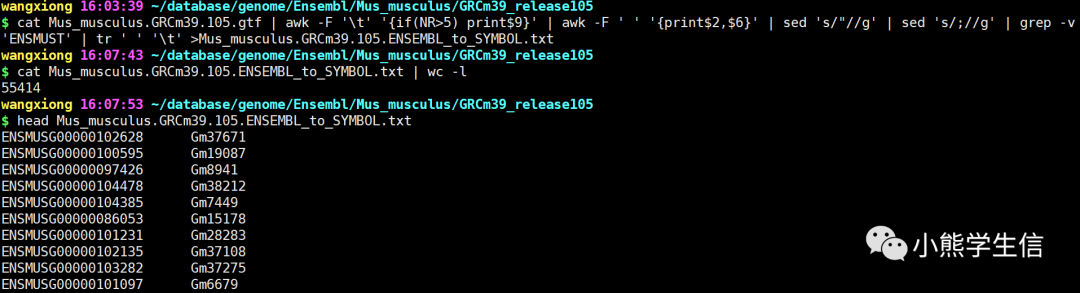
最后把Mus_musculus.GRCm39.105.gene_to_transcript.txt和Mus_musculus.GRCm39.105.ENSEMBL_to_SYMBOL.txt导入到R里面即可进行对应关系查找了。

若有收获,就点个赞吧
0 人点赞
