一、字段的选择
一般情况下,应尽量使用可以正确存储数据的最小数据类型,更小的数据类型通常更快,因为它们占用更少的磁盘、内存和CPU缓存,并且处理时需要的CPU周期也更少 ——《高性能MySQL》
整数类型
字符串类型
日期类型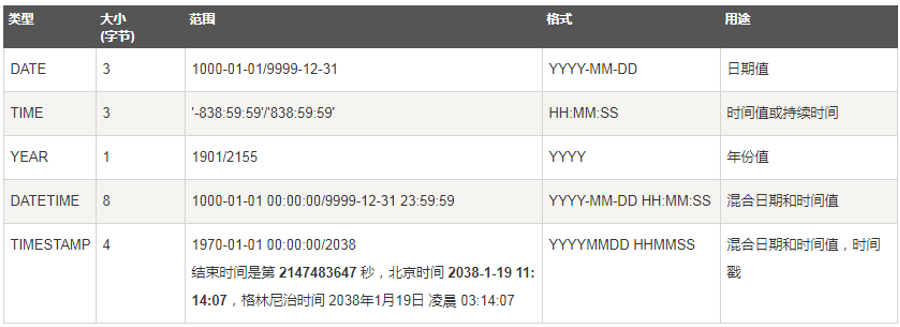
通常情况下,要使用合适的类型,举个例子,以年龄为例,存tinyint unsign 就足够了,占用1字节,没必要再使用int类型去存储;
下面简单介绍下选择类型容易产生误解的字段
位、字节、字符
1、每个二进制数字0或者1就是1个位; 2、8个位构成一个字节。即:1 byte (字节)= 8 bit(位); 3、字符区别于编码: a、b、c 等标识一个字符; 一般 utf-8 编码下,一个汉字 字符 占用 3 个 字节; 一般 gbk 编码下,一个汉字 字符 占用 2 个 字节;
1.1 int(M) M是什么意思
M表示的是显示宽度,不是具体的存储范围,int的范围是2的31次方(4字节*8位-1),即你int (1)和int(10)存的范围都是一样的
1.2 char与varchar的区别
(1)char是固定长度,varchar是可变长度; (2)char (M)不管你存的长度是否小于M,都会分配M空间大小 (3)varchar(M) 存多大,分配多大的空间 (4)如果超出M,会自动截取长度
1.3 varchar(20)能存多少汉字?
(1)在4.0以下,varchar(20),指的是20个字节,即存放的是UTF8汉字时,只能存6个(每个汉字3字节) (2)在5.0及最新的版本下,指的是20个字符,即,无论你存汉字,字母还是数字,都是20个;
注意:
(1)除此之外,建立字段的时候,还应该尽量设置为 not null,并给出相应的默认值
(2)选择存储引擎时,如无特殊需求,尽量选择innodb引擎;
(3)innodb支持事物而myisam不支持,当 innodb与myisam表联表查询时,将导致innodb的表事物回滚失败
(4)注意int存储时间戳和timestamp存储的时间,存在2038陷阱问题;
二、系统层面的优化
- 读写分离
- 分库分表
- 水平拆分:有按照时间拆分,按照id范围拆分,按照字段hash拆分等等
- 垂直拆分:将热点数据列和非热点数据字段拆分开
- 分区分表(不建议使用)
- 建立索引
- 做数据库集群
三、SQL语句的优化
3.1 常见优化方式
- select 所查必所得
- 查询一个时,加limit 1 ,能够直接返回数据,避免查找浪费(事实上,通常所有的SQL都要尽量加上 limit)
- limit 和order by的优化,利用延迟关联和范围查找进行优化
- join连接表的两个字段都要建立索引,并且字段类型要保持一致
- 连续的in 查询用between and来进行替换
- 尽量使用inner join代替left/right join
- 建立适当的索引
3.2 limit 的优化
select * from user limit 5000,10
该条SQL会先查询出5010条,并且抛弃掉前面5000条保留10条,造成查询的浪费,优化方式有两种
方法一,利用范围查找,进行分页
select * from user where id >5000 limit 10;
方法二,利用延迟关联的方式
select * from user INNER JOIN (SELECT id from user limit 5000,10) as u using(id);
四、建立索引
4.1 索引建立规则
(1)通常在辨识度比较高的字段建立索引(重复性低的字段)
(2)在where 以及 order by 和 group by 和 join 字段建立索引
(3)辨识度不高的诸如,type类型上,不建议使用索引(成千上万行重复三、四个值,建立索引并不会提升速度)
(4)索引建立通常不要超过5个(更新和插入通常需要去维护索引,如果建立索引过多,造成更新和插入较慢)
(5)重要SQL上,考虑覆盖索引,能够避免回表查询
4.2 无法使用索引的情况
(1)应尽量避免在where子句中进行null值判断,否则导致引擎放弃使用索引,而进行全表扫描
(2)不要再where子句中进行函数操作,这也将导致引擎全表扫描
(3)or连接的子句中,如果一个有字段,一个没有字段,将导致无法使用引擎放弃使用索引而进行全表扫描
(4)隐式类型转换也导致无法使用索引(如int类型的num,num=10可以使用索引,num=”10”无法使用索引)
(5)like的全匹配无法使用索引,但是左前缀可以使用(like ‘%hello%’ 无法使用索引,但是 like ‘hello%’可以使用)
(6)组合索引,范围查询后的字段无法使用索引(例如a,b,c组合索引,a=1 and b>2 and c=3,a,b能使用索引而c不能使用,type 为range)
(7)组合索引,如果跳过其中一个字段,则后面的字段也是无法使用索引的(例如组合索引a,b,c,查询时a=1,c=2,则导致c=2无法使用索引)
(7)组合索引 ,in和between and是可以使用组合索引的,因为in类似多个等值查询(例如a,b,c组合索引,a=1 and b in (2,3,4,6,8) and c=3 ,则a,b,c都能使用索引的)
(8)多数的否定语句是无法使用索引的:not in、 not null 、!= 、<>
(9)对字符串使用前缀索引,前缀索引长度不超过8个字符,建议优先考虑前缀索引,必要时可添加伪列并建立索引。
(10)不要索引blob/text等字段,不要索引大型字 段,这样做会让索引占用太多的存储空间;
(11)in 在条件足够多的时候会走全表扫描;另外当数据量不多,或者查询的数据量很大的时候,会走全表扫描,因为走索引会更慢
4.3 字段的可辨识度
计算公式为 count(distinct col) / count(*)
采用 show index from table_name 看Cardinality区分度,区分度越大越好。
4.4 查询执行计划信息

若有收获,就点个赞吧
0 人点赞
