13. 计算机中数的表示
13.1 不同进制的转换
数字电路只有 1 和 0,所以计算机用二进制计数。
二进制最左边称为最高位(MSB),最右边称为最低位(LSB)。
按惯例,LSB 称为第 0 位,一个 32 位数,MSB 则称为第 31 位。
二进制到十进制:
1011 = 1x2^3 + 0x2^2 + 1x2^1 + 1x2^0,位数少的记口诀就行了,8 4 2 1。
十进制到二进制:
反复对十进制数除 2 取余即可,最后一次的余数即是二进制的最高位。
计算机是用二进制表示数字,但二进制书写太啰嗦。
所以程序员可以把二进制分成三位一组,成为八进制(0~7)。把二进制四位一组,成为十六进制 0~9A~F。
所以八进制、十六进制仅仅是为了书写方便而已,如同草书和正楷的关系。
13.2 整数的加减运算
数学上的数字至少是有正负之分的,所以对于一个数字,想要体现出是正负之分,那么就要在一串二进制数 11010101… 数中体现出正负含义。
i. Sign and Magnitude 表示法
比如要用 8 个 bit位表示整数和负数,一种简单的想法是把最高位规定为符号位。0 表示正 1 表示负,剩余 7 位表示绝对值大小。-1 为 10000001,+1 为 00000001,8位的取值范围则是 -(2^7-1) ~ 2^7-1。
思路是简单了,但物理电路会比较复杂,要考虑较多的电路逻辑,可能要考虑:比较符号位、比较绝对值、加法改减法、减法改加法、小数减大数改成大数减小数…..
电路复杂,效率也就低下了。
ii. 1’s Complement 表示法
介绍二进制补码表示法前,先了解下十进制的。假设用三位十进制数表示正数和负数,负数有补码,正数的补码就还是正数,因为要区分补码形式的整数和负数,所以正负的取值范围,差不多一半一半(-499 ~ 499)。
假如要计算 167 - 59:
-59 负数用 9 的补码表示,就是用 999 减去 59。
167 + (999-59) - 1000 + 1 = 108
本来是 167 - 59 的,现在变成了 167 + 940,为了抵消取补码时的 999,所以 167 + 940 之后 - 1000 + 1。
规则:负数用 9 的补码表示,减法转换成加法,计算结果的最高位如果有进位则要加回到最低位上去。
上述规则也适用于二进制数:负数用 1 的补码(1’s Complement)表示,减法转换成加法,计算结果的最高位如果有进位则要加回到最低位上去。
取 1 的补码 1-1=0,1-0=1,所以其实就是取反,所以 1 的补码也成为反码。
1’s Complement 表示法比起 Sign and Magnitude 表示法的优势明显:
不必分开考虑符号和绝对值,正数和负数的加法都一样算,减法器也用不到,只需要一套加法电路,再来一套取反的电路,就可以实现加法和减法运算了。
如此,若用 8 位采用该表示法,负数取值范围是 10000000 到 1111111(-127 到 0),正数是从 0000000 到 01111111(0到127),依旧根据最高位判断正负,但有个问题,0 的表示法仍然不唯一,11111111 也行,00000000 也行,因此引入 2’s Complement 表示法。
iii. 2’s Complement 表示法
2 的补码表示法规则:正数不变,负数用 2 的补码。
为了得到 2 的补码,实际操作是先取反码再加 1,为什么这样就能得到 2 的补码?
因为对一位二进制数 b 取 2 的补码就是 1 - b + 1 = 10 -b,相当于从 2 里面减去 b,所以也因此称为 “2 的补码”,人为地按了个名字。
2’s Complement 的计算规则:减法转换成加法,忽略计算结果最高位的进位,不必加回到最低位上去。
在正常的加法规则下,可以利用2的补码得到正数与负数相加的正确结果。换言之,计算机只要采用加法电路和补码电路,就可以完成所有整数的加法。
阮一峰 《关于2的补码》有一些具体的数学证明:https://www.ruanyifeng.com/blog/2009/08/twos_complement.html
关于 2’s Complement 的溢出问题,总之经过排列组合验证,得出结论:
在相加过程中最高位产生的进位和次高位产生的进位如果相同则没有溢出,如果不同则表示有溢出。
逻辑电路可以把两个进位连接到一个异或门,然后把异或门的输出连接到溢出标志位。
iv. 有符号数和无符号数
前面的三种表示法,都是在表达有符号数,即让整数有正负之分。如果 8 个 bit 全部表示正数,则取值范围是
0 ~ 255,这是无符号数。
但对于计算机硬件电路来说,加法器就是加法器,有没有符号意义,要看上层程序是如何来理解,如何来解读一串二进制的含义的,如果程序理解为有符号数的加法,接下来就要先检查溢出标志,如果当做无符号加法,就要检查进位标志。
13.3 浮点数
浮点数在计算机中的表示是基于科学计数法。
32767 的科学计数法是 3.2767 x 10^4,3.2767 是尾数(Significand),4 是指数(Exponent)。
浮点数在计算机中类似,只不过基数(Radix)不是 10,而是 2。
一种浮点数格式,符号位 + 指数部分 + 尾数部分
要表示 17,

尾数有效数字全移到小数点后,得到:
但要表示 0.25 就有困难了,
 。
。
指数 -1 是复数,难道在指数部分也规定一个符号位?
更广泛采用的办法是使用偏移的指数,规定一个偏移值,比如 16,实际的指数要加上偏移值,因此比 16 大就表示正指数,小则表示负指数。
因此要表示 0.25,其指数是 -1,指数部分就应填 16-1=15,下图的 01111 就是 15:
并且为了浮点数表示是唯一的,规定尾数部分的最高位必须是1,即尾数必须以 0.1(二进制)开头,
17 = ,规定必须是前者,这成为正规化(Normalize)。
,规定必须是前者,这成为正规化(Normalize)。
因为规定尾数最高位必须从 1 开始,因此实际存储是就可以省略这个最高位的 1,从而节省出以为用来提高精度。
17 表示如下,别忘了尾数部分隐藏了最高位的 1:
浮点数相加:
浮点数的精度有限,因此末尾的 10 两位会被舍去,所以浮点运算要注意精度损失问题,精度损失后得到的计算结果只能说大约是接近的,但不再是数学意义上最精准无误的。
整数运算可能产生溢出,浮点运算也可能溢出。
按本节介绍的浮点表示法,取值范围是 ,
,
超出该范围称为上溢,若结果未超出该范围,但绝对值太小,同样无法表示,称为下溢。
个人理解:浮点数的上溢是正指数太大了,而下溢是负指数太大了。
浮点数是个复杂话题,业界广泛采用的标准是 IEEE 754,在绝大多数平台,一个浮点数的所有 bit 位是 0 就表示 0 值。
14. 数据类型详解
14.1 整型
C 中 char 型占一个字节的存储空间,一个字节通常是 8 个 bit。
C 规定 signed和 unsigned 两个关键字,signed char 型表示有符号数(-128 ~ 127基于2的补码表示法)。unsigned char 型表示无符号数(0 ~ 255)。
C 标准规定 Implementation Defiend,x86 平台上的 gcc 定义 char 型是有符号的。
C标准中没有做明确规定的地方会用 Implementation-defiend、Unspecifed 或 Undefined 来表述。
Implementation-defiend,比如刚才的 char 默认是算作有符号还是无符号,C标准规定有各自编译器来做明确规定,且要写在编译器文档中。
而有些代码是 Unspecified,这样的代码编译器不必写在编译器的文档中,比如求表达式 i+++i++ 的值,到底怎么结合?就看不同编译器各自怎么处理了,C标准都认可,我们要避免写这种含糊的代码。
还有些代码属于 Undefined,C 标准没规定怎么处理,编译器很可能也没规定,有很多 Undefined 的代码,编译器都提前检查不出来,运行时才导致错误。比如数组访问越界就是 Undefined 的,同样也要避免写这样的代码。
整型:char、short int(简写 short)、int、long int(简写 long)、long long int(简写 long long)等几种。
这些类型都可以加上 signed 或 unsigned,signed int 和 unsigned int 可以简写为 signed 和 unsigned。
C标准规定,整型除了 char 要看具体平台之外,其他整型默认全都是 signed 有符号的。
因此在 x86 平台上,整型全部都默认是有符号的。
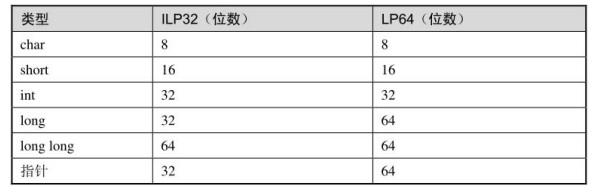

14.2 浮点型
浮点型有 float、double、long double,但没规定各占多少字节。但大多数平台浮点数实现遵循 IEEE 754,float 通常是 32 位,double 通常 64 位。
浮点数可以用科学计数法表示常量,314e-2,3.e-1, .987 等。
3.14f 是 flaot型,3.14 是 double 型,而后缀 l 或 L 的浮点数常量是 long double 型。
14.3 类型转换
C语法规则中最复杂的是类型转换,了解这些不是为了主动刻意的触发编译器的类型转换,而是要避免写这种混合不同类型的代码。
i. Integer Promotion 整型提升
表达式中,char、short、Bit-field 型能提升为 int,则提升为 int,否则提升为 unsigned int。
ii. Usual Arithmetic Convertion 寻常算数转换
算术运算中,两操作数类型不同,则编译器会自动类型转换,使得类型相同后才做运算,这叫寻常算数转换。
具体来说:有 long double 转为 long double,有 double 转为 double,有 float 转为 float,剩下的情况则两边都是整型了,则依照整型提升。
规则比较复杂,但总体上是向更高(更长)级别的类型转换的。
iii. 由赋值产生的类型转换
如果赋值或初始化时两边的类型不同,则编译器把右边的类型转换为左边的类型后再赋值。
函数调用传参的过程,相当于定义形参并用实参初始化,函数返回的过程,相当于定义临时变量并用 return 表达式对其初始化。所以同样适用该转换规则。
iv. 强制类型转换
以上三种是隐式类型转换,程序员也可以通过类型转换运算符主动进行显式类型转换,如 (double)3。
v. 编译器如何处理类型转换
对于任意两种类型之间的转换,把 M 转换成 N 类型,编译器依据以下原则进行转换,写代码要主动避免,但遇到问题时可用下表来排查: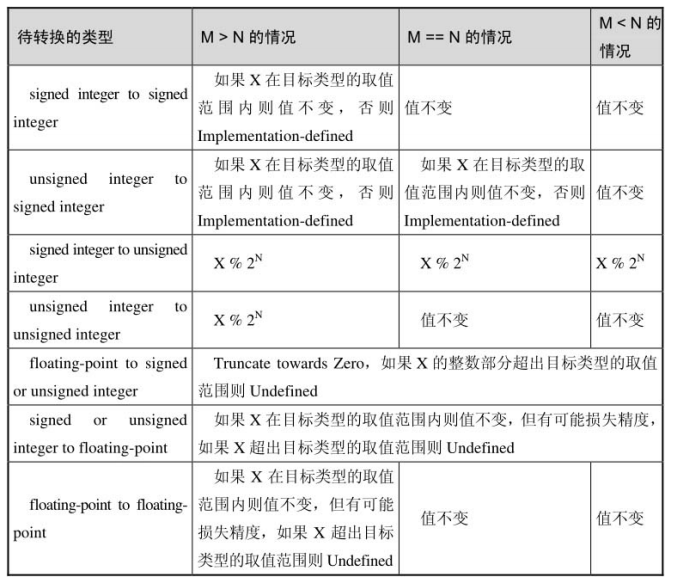
15. 运算符详解
位运算的操作数必须是整型。有些信息利用整数中的某几个位来存储。
15.1 位运算
按位与 & 、或 |、异或 ^、取反 ~ 运算。
C语言中并不存在 8 位整数的位运算,操作数在做位运算之前都至少提升为 int 型了。& | ^ 要做 寻常算数转换 Usual Arithmetic Conversion(里面有一步是整型提升),~ 要做整型提升 Integer Promotion。
移位运算左移 <<、右移 >>。
移动的位数必须小于左操作数的总位数,移位运算两边操作数的类型不要求一致,但两边操作数要做整型提升。
计算机做移位比做乘法快的多,所以编译器可据此做优化,把一些乘法编译为移位指令而不是乘法指令。
由于类型转换和移位等问题,建议只对无符号数做位运算,以减少出错的可能。
掩码(Mask)用于对整数某些位进行操作时,表示位在整数中的位置,如用掩码 0x0000ff00 表示对一个32位整数的 8~15 位进行操作:
利用掩码技术,统计一个无符号整数的二进制表示中的 1 的个数:
#include <stdio.h>/*** 统计二进制1的个数*/int countbit(unsigned int x){unsigned int count = 0, mask = 1, shift = 0;while (mask <= 0xffffffff) {if ((x & mask) >> shift++)count++;mask = ((mask + 1) << 1) - 1;if (mask == 0xffffffff)break;// printf("%x\n", mask);}return count;}int main(void){printf("count=%d\n", countbit(0xffff));}
异或运算的特性:
- 一个数和自己做异或的结果是 0,x86平台的编译器也许有这样的指令
xorl %eax, %eax来快速设置为0 - 和 0 做异或原值不变,和 1 做异或得到原值的相反值,可结合掩码来实现某些位的翻转。

- A1^A2^A3^…^An 结果是 1,则说明之中 1 的个数为奇数个,否则为偶数个,可用于奇偶校验。
- x ^ x ^ y == y,因为 x ^ x == 0,0 ^ y == y,可用于交换两个变量的值,不借助额外空间,如 RAID。

15.2 其他运算符
逗号运算符:是一种双目运算符,左边先求值,求完了值丢掉,再求右边的值并作为整个表达式的值。
sizeof 运算符:比较特殊,有两种形式,sizeof 表达式,sizeof(类型名)。
用于获取某类型所占的字节数,有些类似其他语言中的 length 属性。
sizeof 运算符的结果是 size_t 类型的,其定义在 stddef.h 头文件中。
C标准规定 size_t 是一种无符号整型,编译器可以用 typedef 做一个类型声明:typedef unsigned long size _t;
那么 size_t 就代表 unsigned long 型,不同平台的编译器可能根据自身情况定义 size_t 为别的类型,比如 unsigned long long 型。
之所以 C标准规定这种“别名”,就是屏蔽细节,是代码具有可移植性,stddef.h 中还有许多这种类型。
typedef 关键字用于给某个类型起个新名字,类似于 shell 中的 alias 命令起别名。
%u转换说明,表示后面的参数是无符号整型:
使用 array_t a 相当于声明 char a[10] :
16. 计算机体系结构基础
MMU(内存管理单元)用作地址转换,和提供内存保护机制。
17. x86汇编程序基础
.section .datadata_items:.long 3,67,34,222,45,75,54,34,44,33,22,11,66,0.section .text.globl _start_start:movl $0, %edimovl data_items(,%edi,4), %eaxmovl %eax, %ebxstart_loop:cmpl $0, %eaxje loop_exitincl %edimovl data_items(,%edi,4), %eaxcmpl %ebx, %eaxjle start_loopmovl %eax, %ebxjmp start_looploop_exit:movl $1, %eaxint $0x80
18. 汇编与C之间的关系
todo 第一节 函数调用
int bar(int c, int d)
{
int e = c + d;
return e;
}
int foo(int a, int b)
{
return bar(a, b);
}
int main(void)
{
foo(2, 3);
return 0;
}
18.2 main函数、启动例程和退出状态

gcc 只是一个外壳,使用 gcc main.c -v -o main 打印 gcc 详细的编译过程:
- 调用真正的 C 编译器 cc1 把 main.c 编译成汇编程序 /tmp/xxx.s
- 调用 as 汇编器将 /tmp/xxx.s 汇编成目标文件 /tmp/yyy.o
- 调用 collect2(链接器 ld 的外壳)把刚才的目标文件连同另外几个目标文件一起链接成可执行文件 mian


链接器在另一个目标文件中找到符号定义并确定地址的过程叫 符号解析,符号解析和重定位都是通过修改指令中的地址实现的。
链接器也是一种编辑器,就像 vi 和 emacs 编辑的是源文件,链接器编辑的是目标文件,所以也叫做 Link Editor。
分析下编译器提供的 crt1.o 目标文件中的符号 $nm /usr/lib/x86_64-linux-gnu/crt1.o:
_start 符号在 crt1.o 中提供了定义,类型是代码(Text),而 main 符号在 crt1.o 中引用了,但是没有定义(Undefined),因此需要别的目标文件提供一个定义,并且和 crt1.o 链接在一起。
__libc_start_main 也是未定义的。
所以 C 程序的入口点其实是 ctr1.o 提供的 _start,会先做初始化工作(启动例程),然后调用我们写的 main 函数。
_start 才是 C 程序入口,main 函数是被 _start 调用。
书中和使用 docker 实测时的结果略有不同,但大致一致。
反汇编编译链接好的 main,能看到 crt1.o 的 _start 中保存了 main 函数的地址,然后调用 __libc_start_main 函数,该符号在链接后的可执行文件中也是未定义的。
该符号是 libc 共享库中定义的,在运行时由动态链接器进行加载,做动态链接 -dynamic-linker。
__libc_start_main 做初始化工作后,调用我们的 main 函数。
main 函数的标准原型是 int main(int argc, char *argv[]);,这俩参数就是这时这里传入的。
但目前学习阶段,main 函数原型先写成 int main(void);即可,也是 C 标准允许的,多传了参数可以不使用,少传了参数却用了则会出问题。
main 函数 return 时返回到启动例程中,return 的返回值做参数调用 exit 函数。
exit 也是 libc 的库函数,做一些清理工作,然后调 _exit 系统调用,所以 main 函数的返回值最终传给了 _exit 系统调用,成为进程的退出状态。
启动例程一般直接用汇编写的,等价的 C 代码形式是:exit(main(argc, argv));
也可以在 main 中直接调用 exit 函数终止进程,而不必返回到启动例程,只是要记得包含头文件 #include <stdlib.h>。
甚至也可以在 C程序中调用 _exit 函数,这是对系统调用的简单包装,可能直接内嵌了汇编 int $0x80,也可能是完全的纯汇编。
按惯例:退出状态 0 表示程序执行成功,非 0 表示出错(8 位,0~255),-1 时结果为 255。
- 一个进程调用 exit 或 _exit,或从 main 函数 return 返回而终止,都属于正常终止,也成为退出(Exit)。
- 而 Ctrl + C 组合键,或运行时段错误,或 kill 命令终止进程,这几个本质是进程收到了信号,被内核强制终止,进程并没有执行 _exit 系统调用,所以也就没有退出状态。这称为异常终止。
18.3 变量的存储布局
```cinclude
const int A = 10; / const表示只读,不可修改,分配到.rodata段 / int a = 20; / 全局符号 .data / static int b = 30; / 局部符号 .data / int c; / 不占空间 .bss “Better Save Space” /
int main(void) { static int a = 40; / .data / char b[] = “Hello world”; / 函数栈中分配 / register int c = 50; / 寄存器 /
printf("Hello world %d\n", c); /* .rodata */
return 0;
}
**static 关键字:**
1. 隐藏,同时编译多个文件时,所有未加 static 前缀的全局变量和函数都具有全局可见性,而加了 static,则只能在同一个目标文件中定义和使用,链接器不会对局部符号做**符号解析**。
1. 对于函数来讲 static 作用仅限于隐藏,对于变量来说,static 变量是像全局变量一样**静态分配**,保持变量内容的持久。mian 函数里的 `static int a` 也是如此,只是其作用域仅限于 main 中,不同于普通的函数内局部变量在调用函数时分配,函数返回时释放。
A 是只读变量,定义后不能再改。mian 函数中的字符串字面值 `"Hello world %d\n"` 本质也是只读的,相当于在全局作用域定义了 const 数组。<br />操作系统的内存管理和编译器的语义检查为全局 const 变量提供了双重保护。<br />把函数的局部变量声明为 const,虽然编译器会提供服务做语义检查,但局部变量在栈中分配,因为栈要求可读可写,所以操作系统无法保证只读。
`.data` 和 `.bss` 段在链接时合并到 Data Segment 中,加载运行时 Data Segment 的页面可读可写,但 `.bss` 段在文件中不占存储空间,加载到内存时该段用 0 填充,C 规定全局变量和 static<br />**C 语言规定变量如果不初始化则初值为 0,未初始化的和明确初始化为 0 的全局变量都会分配在 **`**.bss**`**段。**
**gcc main.c -g**<br />**readelf -a a.out**<br />查看 .symtab 符号表,可以看到某些变量被分配到了某些 section 中。<br />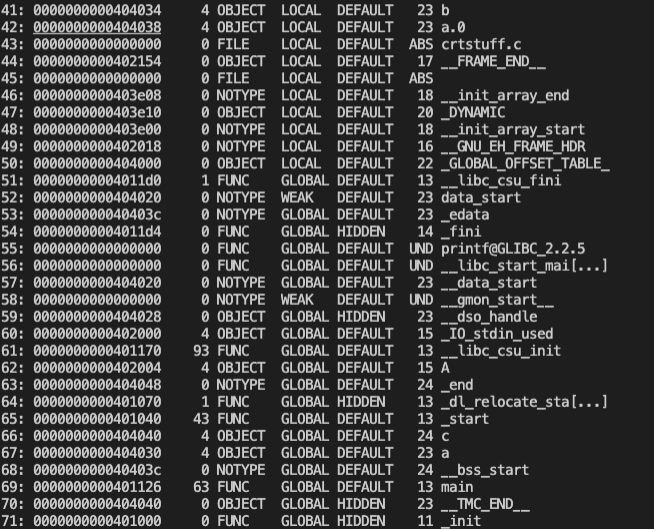<br />通过 Section to Segment mapping 能看到哪些 section 组成一个 segment:<br />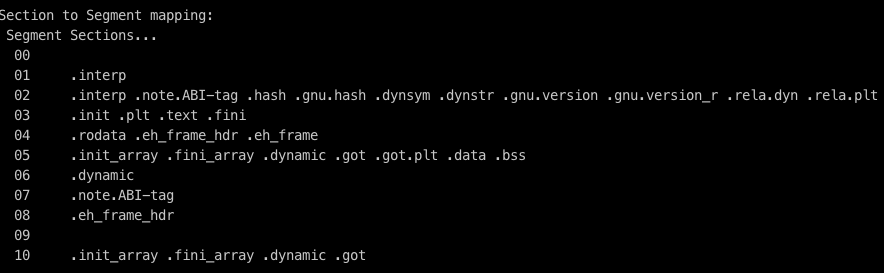<br />结合符号表和 Section Headers 可以定位某个变量或某个段在可执行文件中的位置,例如变量 A:<br />加载到内存中的地址会是 0x402004,长度 4 字节,那么查 Section Headers<br /><br />刚好 .rodata 段在内存中的地址会是 0x402000,并且长度为 18 个字节,所以可知变量 A 属于 .rodata 段,又知 .rodata 段在文件中的起始偏移地址是 0x2000,所以文件中第 0x2004 开始的 4 字节即是变量 A。<br />通过 hexdump -C a.out 获得 hex+ASCII 打印一下可执行文件,看看 A:<br /><br />注意当前平台是小端字节序,低位地址是数据的低位,0a 00 00 00 翻成自然顺序就是 00 00 00 0a,<br />0x0000000a,也就是十进制的 10,正是变量 A 的值。
**C语言作用域分类:**
- **函数作用域**
标号属于函数作用域。
- **文件作用域**
标识符、typedef 定义的类型名或 Tag,这些如果是在函数外声明的,则从声明处开始到该源文件末尾都有效(严格说是直到编译单元末尾都有效)。
- **块作用域**
标识符在在 `{}` 括号中声明的,即在函数体或语句块中声明,则只在声明的位置开始到括号结束前有效。
- **函数原型作用域**
如 `int foo(int a, int b);` 中的 a 和 b。
**同一命名空间的重名标识符,内层作用域的标识符将覆盖外层作用域的标识符。**<br />**命名空间分类:**
- 语句标号单独属于一个命名空间。
- struct、enum 和 union 的 Tag 属于一个命名空间。
- struct 和 union 的成员名属于一个命名空间。
- 所有其他标识符,变量名、函数名、宏定义、typedef 定义的类型名、enum 成员等属于同一个命名空间,重名时内层覆盖外层作用域。
- 若宏定义和其他标识符重名,则宏定义覆盖所有其他标识符,因为宏定义在预处理阶段先处理,其他则在编译阶段处理。
**标识符的链接属性:**
- **外部链接(External Linkage)**
一个标识符在不同编译单元可能被声明多次,若链接成一个可执行文件时,这些声明都代表同一个变量或函数(即同一内存地址),则该标识符具有 外部链接 属性,在编译后的目标文件中是**全局符号**,等到链接时会进行符号解析。如刚才的 a、c、main、printf。
- **内部链接(Internal Linkage)**
一个标识符在某个编译单元中被多次声明,且都代表同一个内存地址,但如果在不同编译单元中被声明多次时却不代表同一地址了,那这样的标识符只能算作具有 内部链接 属性,只在编译单元内部具有通用性。该类标识符编译后在目标文件中是**局部符号**,链接时不做符号解析。如刚才的 static int b。
- **无链接属性(No Linkage)**
除以上情况外的标识符都属于无链接属性,如函数的局部变量,以及不表示变量和函数的其他标识符。除了函数、全局变量、静态变量之外的标识符在编译时不会变成符号,所以没有连接属性。(就算编译时变成符号,同一编译单元内的两个不同函数中的 statc 变量,也不算是具有内部链接属性,会被改名为不同符号)。
**存储类修饰符(Storage Class Specifier)可以修饰变量或函数声明:**
- **static**
其修饰的变量的存储空间是静态分配的,其修饰的文件作用域的变量或函数是 Internal Linkage 的。
- **auto**
函数调用时自动在栈上分配存储空间,返回时自动释放,如 main 中 b,只不过 auto 省略了。auto 不可修饰文件作用域。
- **register**
编译器尽可能分配一个专门的寄存器来存储,做不到的话则当做 auto 变量。register 不可修饰文件作用域。register 用的较少,现代编译器会自行优化高效利用 CPU 寄存器。
- **extern**
用于多次声明同一个具有外部链接或内部链接属性的标识符(下一章详解)。
- **typedef**
纯粹是从语法角度和前面几个归为一类,而不是实际功能语义方面。
**类型限定符(Type Qualifier):**
- **const**
- **volatile**
- **restrict**
在一个变量或函数声明的开头若有修饰或限定,虽然可以任意排列,但可读性很差,因此通常按如下顺序书写:
- **Storage Class Specifier**
- **Function Specifier**(如20章的 inline)
- **Type Qualifier**
- **Type Specifier**(如 int、double)
感觉有些像英语的前置定语,有多个形容词时一般和名词关系最密切的最靠近名词。
**变量的生存期(Storage Duration 或 Lifetime):**
- **静态生存期(Static Storage Duration)**
具有外部链接、内部链接、或被 static 修饰的变量,在程序开始执行时分配内存和初始化,一直存活到程序结束,通常位于 .rodata、.data 或 .bss 段。
- **自动生存期(Automatic Storage Duration)**
无链接属性且不被 static 修饰的变量,进入块作用域时在栈上或寄存器中分配,退出块作用域时释放。
- **动态分配生存期(Allocated Storage Duration)**
调用 malloc 函数可以在进程的堆空间分配内存,调用 free 函数可以释放这块内存。
<a name="OB2A5"></a>
## 18.4 结构体和联合体
<a name="iw2p8"></a>
### i. 结构体
```c
#include <stdio.h>
int main(void)
{
struct {
char a;
short b;
int c;
char d;
} s;
s.a = 1;
s.b = 2;
s.c = 3;
s.d = 4;
printf("%u\n", sizeof(s)); /* %u表示无符号十进制整数 */
return 0;
}
gcc -g main.c
objdump -dS a.out

docker 实测和书上略有不同,书上是用的 esp,实测用的 rbp 寄存器,但效果一样。
结构体四个成员在栈上排列,虽然栈是从高地址向低地址增长,但结构体成员和数组元素一样,是从低地址向高地址排列的。
结构体各成员不是单纯一个紧挨一个,可能涉及到填充(Padding),存在空隙,本例就被编译器填充了一些空隙。填充是为了对齐。
大多数计算机体系结构对访问内存的指令有限制,一条指令访问几个字节,起始地址就应该是几的整数倍,这叫对齐(Alignment)。这样指令执行效率比较好。所以编译器在安排变量地址时会考虑对齐问题。
访问四字节的指令:movl
访问两字节的指令:movw
访问一字节的指令:movb
为什么最后一个变量 d 的后面还要填充 3字节?不是结构体已经结束了吗?
这是为了结构体后面的变量,假如用该结构体组成数组,而 C 标准要求数组元素必须紧挨着排列,不能有空隙。
这样能保证每个元素地址都可按 “基地址 + n X 每个元素的字节数”简单计算。
合理设计结构体成员顺序或可节省空间,如:a d b c 的顺序就避免了产生填充字节。
另外 gcc 提供了扩展语法消除结构体中的填充字节 __attribute__((packed))。
ii. Bit-field
之前说数据类型最少也要占一个字节,而结构体中还可用 Bit-field 语法定义只占几个 bit 的成员。
http://www.wangcong.com.org/
#include <stdio.h>
typedef struct {
unsigned int one:1;
unsigned int two:3;
unsigned int three:10;
unsigned int four:5;
unsigned int :2;
unsigned int five:8;
unsigned int six:8;
} demo_type;
int main(void)
{
demo_type s = { 1, 5, 513, 17, 129, 0x81 };
printf("sizeof demo_type = %u\n", sizeof(demo_type));
printf("values: s=%u,%u,%u,%u,%u,%u\n",
s.one, s.two, s.three, s.four, s.five, s.six);
return 0;
}

Bit-field 也属于整型,可用 int 或 unsigned int 声明,表示有符号数或无符号数,但不像普通 int 型那样占四字节,冒号后面的数字表示该 Bit-filed 占几个 bit。
five 和 six 之间有填充位(填充了3个bit),使得 six 成员单独占一个字节,访问效率会较高。
末尾也填充了 3 个字节,以便对齐到 4 字节边界,整个结构体是 4 字节。
x86 Byte Order 是小端的,one、two 的位排列能看出 Bit Order 也是小端的。即结构体靠前的成员取了字节中的低位(一个数据中的低位取地址的低位来存储就是小端)。
Bit-field 在驱动程序中很有用,经常需要单独操作设备寄存器中的一个或几个 bit。
iii. 联合体
关键字 union 定义新的数据类型:联合体。
类似于结构体,但联合体的各成员占用相同的内存空间,联合体的长度等于其中最长成员的长度。
联合体若初始化,则是为第一个成员初始化。而用 C99 Memberwise 初始化语法,则可初始化联合体任意一个成员。
比如下面的 u 这个联合体占 8 个字节,若访问成员 u.bitfield,则这 8 个字节看成由 Bit-field 组成的结构体;若访问成员 u.byte,则 8 字节看成一个数组(高0001 1011低正是数组第一项 0x1b):
#include <stdio.h>
typedef union {
struct {
unsigned int one:1;
unsigned int two:3;
unsigned int three:10;
unsigned int four:5;
unsigned int :2;
unsigned int five:8;
unsigned int six:8;
} bitfield;
unsigned char byte[8];
} demo_type;
int main(void)
{
demo_type u = {{ 1, 5, 513, 17, 129, 0x81 }};
printf("sizeof demo_type = %u\n", sizeof(demo_type));
printf("values: u=%u,%u,%u,%u,%u,%u\n",
u.bitfield.one, u.bitfield.two, u.bitfield.three,
u.bitfield.four, u.bitfield.five, u.bitfield.six);
printf("hex dump of u: %x %x %x %x %x %x\n",
u.byte[0], u.byte[1], u.byte[2], u.byte[3], u.byte[4], u.byte[5], u.byte[6], u.byte[7]);
return 0;
}
/* sizeof demo_type = 8 */
/* values: u=1,5,513,17,129,129 */
/* hex dump of u: 1b 60 24 10 81 0 */
回顾本章提到的概念:
- 数据类型的长度
- Calling Convertion
- 访问内存地址的对齐要求
- 结构体和 Bit-field 的填充方式
- 字节序(大端、小端)
- 用什么指令做系统调用,各种系统调用的参数
- 可执行文件和库文件格式(如 ELF 格式)
这些统称为应用程序二进制接口规范(ABI)。两个平台体系结构相同,且遵循相同的 ABI,则二进制程序相互直接拷贝就能运行。
而 Windows 和 Linux 二者的二进制程序则不相互兼容,因为 ABI 不同。
iv. 测试运行平台的字节序
/**
* 测试运行平台的 Byte Order
*/
#include <stdio.h>
typedef union {
unsigned char c[2]; /*低 00 ff 高*/
unsigned short s[1]; /* 小端 0xff00 大端 0x00ff */
} demo_type;
int main(void)
{
demo_type u = {{ 0x00, 0xff }};
if (sizeof(short) == 2) {
if (u.s[0] == 0xff00) {
printf("平台是小端字节序 %x\n", u.s[0]);
} else if (u.s[0] == 0x00ff) {
printf("平台是大端字节序 %x\n", u.s[0]);
} else {
printf("未知\n");
}
} else {
printf("sizeof(short) = %d\n", sizeof(short));
}
return 0;
}
18.5 内联汇编
有些平台相关的指令必须手写,C 中没有等价语法,毕竟 C 是对各平台通用的抽象。
本书不做深入讨论。
如把变量 a 的值赋给 b:
#include <stdio.h>
int main(void)
{
int a = 10, b;
// __asm__("movl $1, %eax\n\t"
// "movl $4, %ebx\n\t"
// "int $0x80");
__asm__("movl %1, %%eax\n\t"
"movl %%eax, %0\n\t"
:"=r"(b)
:"r"(a)
:"%eax"
);
printf("Result: %d, %d\n", a, b); /* 10, 10 */
return 0;
}
18.6 volatile限定符
C 语言中用 volatile 限定符修饰变量时,会告诉编译器:
即使编译时指定了优化选项,每次读写变量都要老老实实直接从内存中读写,不能省略任何步骤。
volatile unsigned char recv;
volatile unsigned char send;
gcc 编译时优化选项是 O 相关。
对于普通的内存单元,确实只要程序不去改写它,它就不会变。所以编译器优化时如会用寄存器缓存变量,毕竟CPU访问寄存器要比访问内存快很多倍。但有些时候不能如此认为内存单元不会自己变。
场景1:
对于设备寄存器,如某平台采用内存映射 I/O,串口发送寄存器和串口接收寄存器位于固定内存地址,每次读写这种内存地址都是有意义的,不能被优化、缓存或省略,要用 volatile 限定。
设备寄存器特性:
- 其中数据不需要外部改写就可自己发生变化,每次读取的值可能不一样。
- 连续多次向其写数据是有意义的,是给设备发指令。
场景2:
当一个全局变量被同一个进程中的多个控制流程访问时,如信号处理函数和多线程,为防止编译器错误优化要用 volatile 限定。
另外对于有 Cache 的平台,只有 volatile 是不够的,Cache 对程序员是透明的。有 Cache 的平台会有 MMU 配合,在页表中设置哪些页面允不允许 Cache 缓存。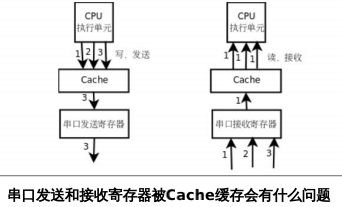

若有收获,就点个赞吧
0 人点赞
