19.1 多目标文件的链接
/* stack.c */char stack[512];int top = -1;void push(char c){stack[++top] = c;}char pop(void){return stack[top--];}int is_empty(void){return top == -1;}
/* main.c */#include <stdio.h>int a, b = 1;int main(void){push('a');push('b');push('c');while (!is_empty())putchar(pop());putchar('\n');return 0;}
有这么俩 .c 文件,一个实现堆栈,一个使用堆栈。
使用命令一步编译 gcc main.c stack.c -o main,或者分步编译:
gcc -c mian.c
gcc -c stack.c
gcc mian.o stack.o -o main
nm 查看 main.o 中的 push pop is_empty 等到链接时要做符号解析,因为实际是在 stack.o 中定义的。
而 putchar 即使在可执行文件中仍是个 U 未定义的符号,因为要等程序运行时做动态链接。
通过 readelf -a main 命令可以看到 .bss 段合并了 main.o 和 stack.o 的 .bss 段,而 .data 和 .text 段也是合并自多个目标文件中的相应段,至于合并后的一些段中,来自 main.o 的在前还是 stack.o 的在前,则看 gcc 时的顺序,更实际的是看链接时的链接脚本如何定义。
链接过程是由一个链接脚本(Linker Script)控制的,链接脚本决定了给每个段分配什么地址,如何对齐,哪个段在前在后,哪些段合并到同一个 Segment。另外链接脚本还把一些特殊地址定义为符号。
用 ld 做链接时若不通过 -T 指定链接脚本,则使用默认链接脚本,用 ld —verbose 查看默认脚本。
/*........某些片段.........*/ENTRY(_start) /* 指明整个程序的入口点是 _start,但修改链接脚本就可以改用其他符号做入口点 *//*、"." 表示当前链接地址,即程序加载运行时的虚拟地址。也就是先给链接地址赋值,然后从赋值后的地址开始组装,比如下面赋值后就要开始组装 text-segment 了。在组装 text-segment 过程中,每组装一个 section 就会自动把当前链接地址加上该 section 长度。所以各段加载时一般是紧挨着没有空隙的,但中途在脚本中又给 . 赋了新值则从新的地址继续。*/PROVIDE (__executable_start = SEGMENT_START("text-segment", 0x400000)); . = SEGMENT_START("text-segment", 0x400000) + SIZEOF_HEADERS;.text :{*(.text.unlikely .text.*_unlikely .text.unlikely.*)*(.text.exit .text.exit.*)*(.text.startup .text.startup.*)*(.text.hot .text.hot.*)*(SORT(.text.sorted.*))*(.text .stub .text.* .gnu.linkonce.t.*)/* .gnu.warning sections are handled specially by elf.em. */*(.gnu.warning)}/*后面还有 Data Segment 和其他 Segment。但每个 section 的描述格式都是 段名 : { 组成 }左边表示链接器生成的文件的某个段,右边表示所有目标文件的某些段组成。*/
gdb 调试时 .c 源文件如果不止一个的话,某些命令中需要指定某个 .c 文件中的某一行或某个函数,格式为文件名:行号或函数名,如 b stack.c:10。
19.2 定义和声明
i. extern 和 static 关键字
编译器处理函数时需要知道函数原型,是为了从而生成相应指令。
但编译器根据函数调用而推测出的隐式声明是靠不住的,因为:
- 实参未必和形参一致
- 可变参数如 printf 从调用处看不出来
- 调用处看不出来返回值类型,只能假定都是 int 型
刚才的 main.c 中编译器并不知道到哪找函数定义,所以在调用之前应先提供函数原型,这样 gcc -c main.c 生成的目标文件中的指令才足够正确。

改写 main.c:
#include <stdio.h>
extern void push(char); /* 修饰函数声明的 extern 可省略 */
extern char pop(void);
extern int is_empty(void);
extern int top;
/* 这几个声明也可以写在 main 函数体里,来限制为块作用域 */
int main(void)
{
push('a');
push('b');
push('c');
while (!is_empty())
putchar(pop());
putchar('\n');
return 0;
}
再编译也没警告了。
- 用 extern 存储类修饰符关键字修饰的函数名具有 External Linkage(函数声明中的 extern 关键字也可以不写)。
- 用 static 关键字修饰的函数名具有 Internal Linkage。
上面代码中还用 extern int top;修饰变量声明,这样就能在 main.c 中直接访问 stack.c 的 具有外部链接属性的变量 top。
凡是被多次声明的变量或函数,必须有且只有一个声明是定义,如果有多个定义,或者一个定义都没有,链接器就无法完成链接。
站在 stack.c 角度,top 变量毕竟是内部封装,一般不希望被外界访问,那么可用 static 关键字将其声明为内部链接属性的:
static char stack[512];
static int top = -1;
...
ii. 头文件
如后来的 main.c 中那样,每个使用 stack.c 模块的 .c 文件都要写一遍三个函数声明是很麻烦的,重复应被避免,如之前的学习中用宏定义避免硬编码,在这里用头文件来避免写重复声明,如 stack.h:
#ifndef STACK_H
#define STACK_H
extern void push(char);
extern char pop(void);
extern int is_empty(void);
#endif
若 STACK_H 这个宏没定义过,则从 #ifndef 到 #endif 之间的代码就包含在预处理的结果中,否则这段代码不出现在预处理中。该写法称为 Header Guard,可避免头文件被重复包含(较大项目中头文件嵌套包含很常见,难以发现重复包含)。
重复包含头文件,问题如下:
- 预处理和编译变慢了
- 互相包含,死循环超过编译器允许的层数上限会报错
- 虽然声明是可以重复声明不报错,但有些重复代码会报错,如 typedef 定义一个类型名,一个编译单元只允许出现一次。
应遵循的一般原则:
- .c 文件中可以有变量或函数定义,而 .h 文件中应只有变量或函数声明而无定义。
- 不要把一个 .c 文件包含到另一个 .c 文件中。
现在,把 main.c 改为:
#include <stdio.h>
#include "stack.h"
...
include 用 <> 角括号和用””引号,gcc 在查找头文件的时的查找顺序有些区别,角括号是 2 3 步,引号是 1 2 3 步:
- 首先查找正在被处理的 #include 指示所在的当前文件所在的目录
- 查找 -I 选项指定的目录
- 查找系统的头文件目录
若 stack.h 不在 main.c 所处目录下,如在 ./stack/ 下,则可:
include 预处理指示中可使用相对路径,相对于使用 #include 的文件处的路径,如
#include "stack/stack.h"。- -I 选项可指定相对路径也可绝对路径,若指定相对路径,是相对于 gcc 进程的当前工作目录,如
gcc -c main.c -Istack。iii. 定义和声明的详细规则
关于变量定义,C 标准规定:
- 有初始化的变量声明是定义
- 没有初始化的变量声明,如果加了 extern 则属于 Previous Linkage
- 既没初始化也没加 extern 的变量声明,叫 Tentative Difinition。
关于定义和声明,书上有详细声明,看起来比较复杂,真有那么复杂场景再说,否则知道刚才介绍的基本规则就够用了。


19.3 静态库
把四个文件编译成目标文件:gcc -c stack/stack.c stack/push.c stack/pop.c stack/is_empty.c
库文件名都是以 lib 开头,静态库以 .a 作后缀。
打包成静态库:ar rs libstack.a stack.o push.o pop.o is_empty.o
- r[ab][f][u] - replace existing or insert new file(s) into the archive
- s - act as ranlib
r 替换或创建 libstack.a
s 为静态库创建索引,该索引被链接器使用,ranlib libstack.o 命令也可为静态库创建索引。
把 libstack.a 和 main.c 编译链接在一起:gcc main.c -L. -lstack -Istack -o main
-lstack 告诉编译器要链接 libstack 库,-I 告诉要去哪里找头文件。
-L 告诉要去哪里找库文件,. 表示在当前目录找,找不到的话,在到 gcc -print-search-dirs 所打印出的默认路径去寻找库文件。gcc 链接时优先考虑共享库如 libstack.so,其次才是静态库 libstack.a,指定 -static 选项可让 gcc 只考虑静态库。
链接动态库时,链接器只是确认可执行文件中引用到的某些符号在相应的动态库中有定义,并没写死最终的符号地址,链接后的符号仍会是未定义。要运行时做动态链接。
而链接静态库时,会把静态库的目标文件取出来真正链接在一起。
反汇编查看刚才生成的可执行文件 objdump -d main 可以看出,链接器从静态库中只取出需要的目标文件来做链接,不需要的目标文件可以不链接,所以可执行文件中有 push 却没有、pop 和 is_empty。
静态库的另一个好处是只需编写一个库文件,而不需要写一长串目标文件名。
19.4 共享库
i. 编译、链接、运行
目标文件也叫做 Relocatable,刚才编译出的目标文件中,.text 段在链接时会被替换、重定位的符号,都写在了 .rel.text 段里,比如 readelf -a push.o:
标出了指令中有四处需要在重定位时做修改。等到编译链接成可执行文件后,地址从 0x0 改成绝对地址了。
而组成共享库的目标文件和一般的有所不同,编译时要加 -fPIC 选项,f 表示后面跟一些编译选项,PIC 表示生成位置无关代码(Position Independent Code):gcc -c -g -fPIC stack/stack.c stack/push.c stack/pop.c stack/is_empty.c
反汇编看一下,指令用到的 stack 和 top 地址不再是前面那种目标文件中,以 0x0 占位,而是 0x0(ebx)(docker x86_64 实测是 rip 寄存器,和书上不同,但不影响理解):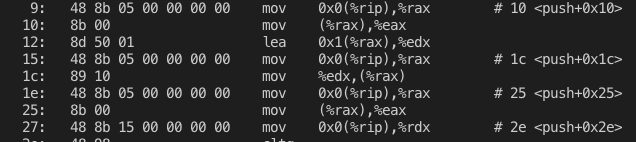
但 stack 和 top 之间仍未有区分,之前是链接后都被改为各自的绝对地址,那么这里的 0x0(ebx) 编译生成共享库后会如何呢?至少 stack 和 top 要之间有所区分吧。
现在编译生成共享库:``gcc -shared -o libstack.so stack.o push.o pop.o is_empty.o
再反汇编看一下:
0x0(%rip) 变成了 0x2ed7(%rip) 和 0x2ecb(%rip),不细究了,反正一个是 stack 一个是 top。
并且用到了间接寻址。
top 和 stack 的绝对地址保存在一个地址表中,而指令通过地址表做间接寻址,可以避免将绝对地址写死在指令中,这也是一种避免硬编码的策略。
也就是指令通过查地址表,得到了目标所在的绝对地址,显然构建出的共享库,其中的指令不会再变化了,而地址表是以后灵活的变动部分。
从某个地址里面取第一次得到新的地址,再从新地址取得变量值。
就跟澡堂子里,拿着一把钥匙打开一个储物柜,结果里面放了另一把新的钥匙,再拿新的钥匙打开另一个储物柜,才得到了想要的物品。
和刚才编译链接静态库一样的命令,现在同样把 main.c 和共享库编译链接在一起(gcc 链接时优先考虑共享库):gcc main.c -g -L. -lstack -Istack -o main
编译链接没问题,得到了可执行程序 main,结果运行 ./main 时报错找不到 libstack.so:
使用 ldd main 模拟运行一遍 main 程序,在运行过程中做动态链接,得知该程序依赖哪些共享库,以及共享库所在路径:
18.2 节研究过 gcc 调用链接器是用 -dynamic-linker 指定了动态链接器的路径,动态链接器就像其他共享库一样会被加载到 main 进程的地址空间中。
动态链接器搜索共享库的顺序:
- 在环境变量 LD_LIBRARY_PATH 保存的路径中查找
- 在缓存文件 /etc/ld.so.cache 中查找(由 ldconfig 命令读取 /etc/ld.so.conf 生成的)
- 在默认的系统库文件目录中查找,先 /lib 然后 /usr/lib
环境变量是程序运行时保存在内存中的一组字符串,每个字符串都是key=value的形式。不推荐,临时调试可以用用。
创建进程 main 时传给它一个环境变量:
XXX=xxx ./main
在 Shell 进程中设置环境变量,然后每次在该 Shell 执行命令时 Shell 进程都会把自己的环境变量传给新创建的进程,比如这里的 main 进程:
export XXX=xxx
./main
推荐第二种方式,把 libstack.so 的绝对路径添加到配置文件 /etc/ld.so.conf 中后运行 sudo ldconfig -v重建索引,生成 /etc/ld.so.cache 缓存文件,再次 ldd 可看到动态链接器已经能找到 libstack.so 了:
可执行文件运行时需要哪些共享库也都记录在可执行文件的 .dynamic 段中:
关于动态链接器,可以参考这篇文章:
动态链接器的步骤与实现:https://www.cnblogs.com/linhaostudy/p/10544917.html
ii. 函数动态链接过程
简单来说和链接静态库不同,push 函数的指令没有链接到可执行文件 main 中,通过 objdump -dS main 反汇编后可以看出不存在 push 函数的指令。
main 调 push 函数时,实际call 了.plt 段 push@plt。PLT 是 Procedure Linkage Table 过程链接表的缩写。
.plt 段也是指令,和 .text 段一起合并到 Text Segment。
push@plt 中跳转时,先读取地址处保存的另一个地址,后者才是跳转目的地。
通过 gdb si 配合 gdb disassemble 一路发现进入到了动态链接器中,在其中完成动态链接并调用共享库的 push 函数,此后再次调用 push 函数,push@plt 跳转时用来读取的地址处所保存的地址会发现已经改为 push 函数的绝对地址,因为之前做过了动态链接,而且动态链接只需一次就够了。
这里 push@plt 跳转时的所读取的地址,其实位于 Global Offset Table(GOT)中,也就是说每次到表中查到表项(其实就是读取到地址处所保存的值,该值也是一个地址),然后跳转到表项而已。
动态链接器利用 GOT 的表项保存共享库中符号的绝对地址,链接完成后,通过 GOT 的表项间接寻址即可访问共享库中的符号。
这种通过地址表间接寻址的思路,使得编译后的可执行程序 main 变得固定,无需重复编译,每次访问动态变量和函数时通过查表即可,而动态链接器链接时会设置表项,如此,表成为了可执行程序和动态库之间的桥梁。
iii. 共享库的命名惯例
系统共享库通常带有符号链接。按命名惯例,每个共享库有三个文件名:
- real name 真正的库文件名字。
- soname
符号链接的名字,只包含主版本号,主版本号一致即认为库函数接口一致。
可执行程序的 .dynamic 段只记录 soname,动态链接器只要找到 soname 一致的库就可加载做动态链接。
也就是说实际运行的程序只认 soname,以后只要是若非大版本的库函数升级,只需改一下 soname 的指向即可,无需重新编译可执行程序。
- linker name
仅在编译链接时使用,gcc 的 -L 选项应指定 linker name 所在目录,编译器只认 linker name。
有的 linker name 是库文件的符号链接,有的是一段链接脚本。
之前编译 libstack 时没指定 soname,默认就是 libstack.so,现也可指定 soname,比如给加上主版本号:gcc -shared -Wl, -soname,libstack.so.1 -o libstack.so.1.0 stack.o push.o pop.o is_empty.o,-o 是 real name,该库文件中记录了 soname,若把库所在目录加入到 /etc/ld.so.conf 中后运行 ldconfig,则会自动创建一个 soname 的符号链接,指向 real name。
5. 虚拟内存管理
todo 之前 16 章学到过,VMM 虚拟内存管理 和 CPU 的 MMU 内存管理单元,还没补充笔记。
这里先继续进一步研究。
操作系统利用体系结构提供的 VA 到 PA 的转换机制实现虚拟内存管理机制。
用 ps 查看进程的 id,然后 cat /proc/id/maps 查看某进程的虚拟地址空间。proc 目录下的文件不是真的磁盘文件,而是内核虚拟出来的。
进程地址空间:


可以看到 /bin/bash 进程被分为多个地址段加载到进程地址空间,每个段有不同访问权限,动态链接器和各共享库的加载也类似。
其中有三个特殊的地址段不是从磁盘加载,而是直接从内存里分配:
- 标有 [vdso] 的地址段,是内核虚拟出来的共享库的映射空间。
- [heap] 堆,用 malloc 函数动态分配的内存是在堆中分配的。堆由低向高增长,且增长余地很大,图中红框到绿框之间的地址空洞都是堆空间未来的增长余地,堆空间结束地址 0x55d919e00000 称为 Break,堆空间要向高地址增长就要抬高 Break,映射新的虚拟内存页面到物理内存,这通过系统调用 brk 实现,malloc 函数也是调用 brk 向内核请求分配内存的。
- [stack] 栈,高地址的部分保存着进程的环境变量和命令行参数,低地址的部分是栈空间,栈空间由高向低增长,但显然没有堆空间那么大的增长余地,毕竟几十层函数调用和非常多的局部变量是罕见的,所以栈空间明显比堆空间更容易用尽,比如无限递归会用尽栈空间。
操作系统的虚拟内存管理机制的作用:
- 控制物理内存的访问权限。
物理内存本身不限制访问,任何地址都可读写,操作系统利用 CPU 模式和 MMU 内存保护机制来使得不同页面可具有不同的访问权限,从而防止 Text Segment 被改写、或者保护内核地址空间等。
- 使每个进程有独立的地址空间。
每个进程都以为自己独占用户内存空间,防止非法内存访问意外改写其他进程的数据;简化链接器和加载器的实现,不必考虑不同进程的地址范围是否冲突。
每个进程都有自己的一套 VA 到 PA 的映射表,在一个进程中通过 VA 只能访问到属于自己的物理页面。
另外,操作系统还可以安排两个进程的 Text Segment 共享相同的物理页面,即不同进程的 VA 映射到相同的 PA。几乎所有的进程都要加载 libc,所以其实 libc 的只读部分在物理内存中是被所有进程共享访问的。
共享库必须是位置无关代码,共享库的指令才能不管加载到什么虚拟地址都能正确执行。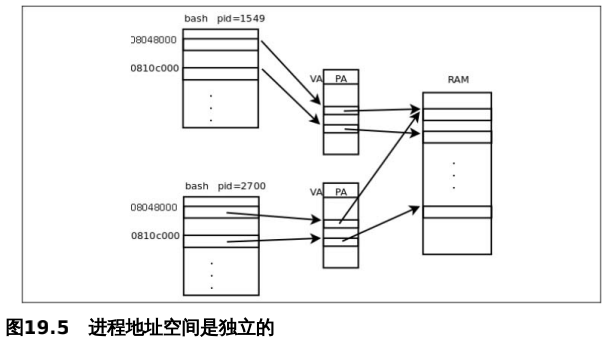
- VA 到 PA 的映射给分配和释放内存带来方便。
物理地址不连续的几块内存可以映射成连续的虚拟地址,解决了空闲物理内存不连续所导致的无法满足连续地址分配需求的问题。
- 为多个进程分配的内存之和可能会大于实际可用的物理内存时各进程仍能正常运行。
进程访问的是虚拟内存页面,真实数据可以保存在物理页面中,也可以临时保存在磁盘上的某分区或文件中,这称为交换设备(Swap Device)。系统中可分配内存总量 = 物理内存大小 + 交换设备大小。
当物理内存不足时,操作系统将不常用的物理页面中的数据临时保存到交换设备中,并解除 VA 到 PA 的映射,以释放一些物理内存,这叫换出(Page out)。当进程又要访问被换出的虚拟内存页面时,由于此前映射已被解除,访问内存的指令会引发异常,这叫缺页错误(Page Fault),此时进入异常处理程序,把缺失的页面再从交换设备加载回物理内存,并建立映射,然后回到用户模式重新执行那条内存访问指令,这叫换入(Page in)。
换入和换出操作统称为换页(Paging)。

若有收获,就点个赞吧
0 人点赞
