一、简介
名称:otter [‘ɒtə(r)]
译意: 水獭,数据搬运工
语言: 纯java开发
定位: 基于数据库增量日志解析,准实时同步到本机房或异地机房的mysql/oracle数据库. 一个分布式数据库同步系统
二、整体架构

原理描述:
1. 基于Canal开源产品,获取数据库增量日志数据。 什么是Canal, 请 点击
2. 典型管理系统架构,manager(web管理)+node(工作节点)
a. manager运行时推送同步配置到node节点
b. node节点将同步状态反馈到manager上
3. 基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作。
名词解释:
- Channel:同步通道,单向同步中一个Pipeline组成,在双向同步中有两个Pipeline组成;Pipeline:从源端到目标端的整个过程描述,主要由一些同步映射过程组成;
-
三、环境准备
新建需要的manager表:
otter manager依赖于mysql进行配置信息的存储,所以需要预先安装mysql,并初始化otter manager的系统表结构。
- 安装mysql(略)
- 新建otter manager需要的表,sql地址如下:https://raw.github.com/alibaba/otter/master/manager/deployer/src/main/resources/sql/otter-manager-schema.sql
- 安装zookeeper:
整个otter架构依赖了zookeeper进行多节点调度,所以需要预先安装zookeeper,不需要初始化节点,otter程序启动后会自检.
- 安装zookeeper(略)
- otter-manager需要在配置文件otter.properties中配置zookeeper集群机器
- 安装jdk1.8:
注意jdk1.9及以上,在启动node或者是manage时会报错 Unrecognized VM option ‘UseCMSCompactAtFullCollection’,9及以上版本废弃了CMSCompactAtFullCollection,无法支持。
四、安装
1、otter-manage
官方quickStart:https://github.com/alibaba/otter/wiki/Manager_Quickstart
1.1 下载
下载地址:https://github.com/alibaba/otter/releases
本次使用的版本是 4.2.18,下载并解压后如下:
1.2 修改配置
修改otter.properties
基本修改内容如下,其他内容可以保持默认
## 修改为正确访问ip,生成URL使用,node的配置需要用到otter.domainName= 127.0.0.1## manage页面的访问端口otter.port =8089## 修改为正确数据库信息otter.database.driver.class.name = com.mysql.jdbc.Driverotter.database.driver.url = jdbc:mysql://127.0.0.1:3306/otterotter.database.driver.username = roototter.database.driver.password = 123456## 为node连接manager的端口, node的配置需要用到otter.communication.manager.port= 1099## 配置zookeeper集群机器otter.zookeeper.cluster.default= 127.0.0.1:2181其它使用默认配置即可
1.3 manage 启动
bin目录下
- 启动 ./startup.sh
- 关闭 ./stop.sh
启动成功后,访问首页http://127.0.0.1:8089/login.htm,初始密码为:admin/admin,即可完成登录. 目前:匿名用户只有只读查看的权限,登录为管理员才可以有操作权限。
2、node
官网quickStart:https://github.com/alibaba/otter/wiki/Node_Quickstart
node会受ottermanager进行管理,所以需要预先安装otter manager,完成manager安装后,需要在manager页面为node定义配置信息,并生一个唯一id。
2.1 添加zookeeper
首先确保你的zookeeper已启动成功。
otter依赖zookeeper,访问manager页面的机器管理页面,选择菜单进入“机器管理→zookeeper管理”页面:(下图是已经添加好的页面)
点击添加,进入添加zk集群页面
填写完信息后点击保存,出现如下页面
2.2 添加node
Zookeeper添加成功后,进入“机器管理→Node管理”页面:
点击进入添加机器页面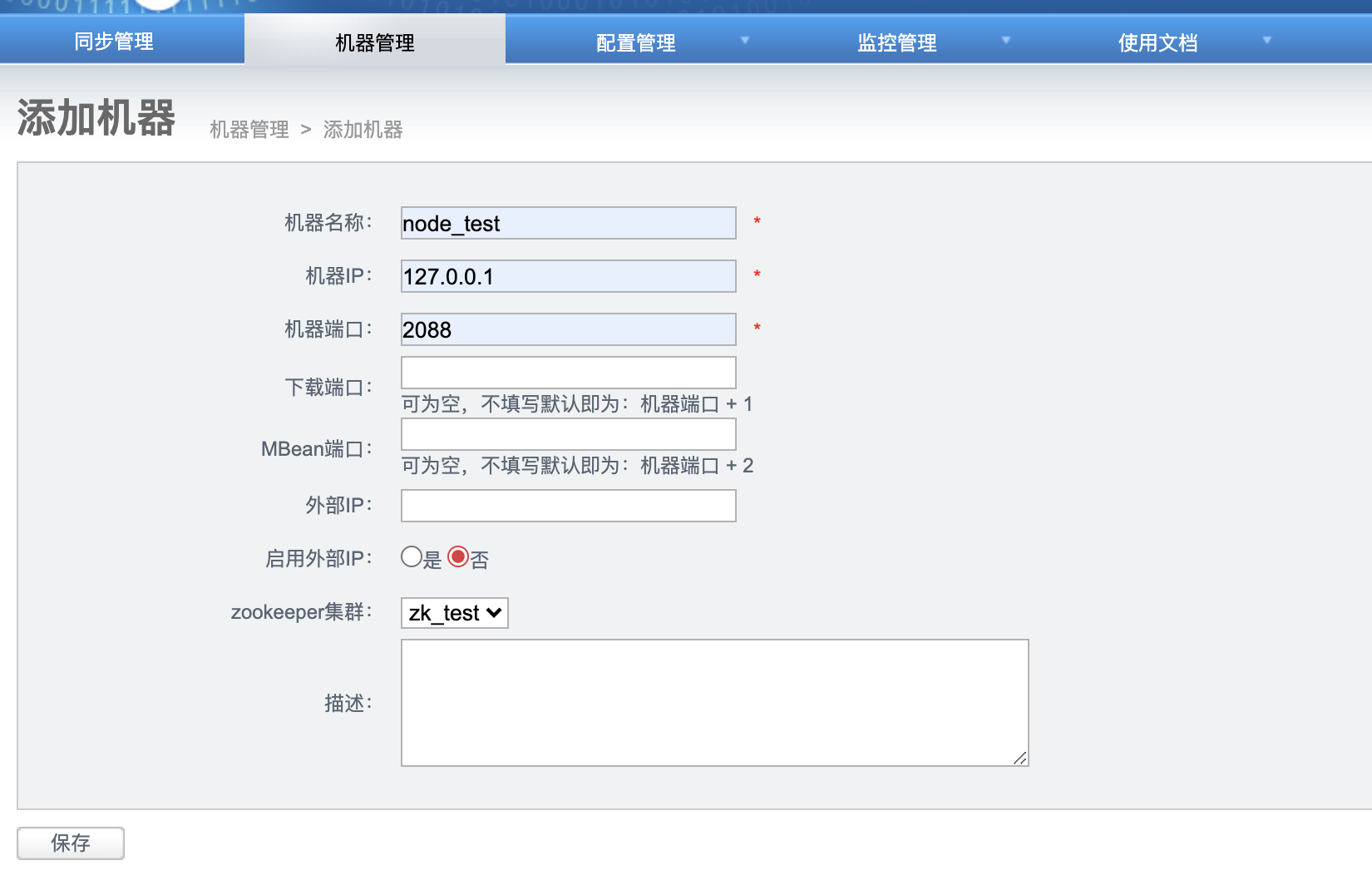
- 机器名称:可以随意定义,方便自己记忆即可
- 机器ip:对应node节点将要部署的机器ip,如果有多ip时,可选择其中一个ip进行暴露. (此ip是整个集群通讯的入口,实际情况千万别使用127.0.0.1,否则多个机器的node节点会无法识别)
- 机器端口:对应node节点将要部署时启动的数据通讯端口,建议值:2088
- 下载端口:对应node节点将要部署时启动的数据下载端口,建议值:9090
- 外部ip :对应node节点将要部署的机器ip,存在的一个外部ip,允许通讯的时候走公网处理。
- zookeeper集群:为提升通讯效率,不同机房的机器可选择就近的zookeeper集群.
- node这种设计,是为解决单机部署多实例而设计的,允许单机多node指定不同的端口

2.3 配置nid
机器添加完成后,跳转到机器列表页面,获取对应的机器序号nid:
通过这几步操作,获取到了node节点对应的唯一标示,称之为node id,简称nid,比如我添加的机器对应序号为1。
在conf目录下创建nid文本,不需要任何后缀,并写入nid:1

2.4 修改配置
打开conf/otter.properties,配置如下,其他配置可以保持不变
# node的安装目录otter.nodeHome = ${user.dir}/node# manager的服务地址otter.manager.address = 127.0.0.1:1099
2.5 启动
bin目录下
- 启动 ./startup.sh
- 关闭 ./stop.sh
logs/node/node.log 日志如下信息,则表示启动成功
访问: http://127.0.0.1:8089/,查看“机器管理-Node管理”页面,对应的节点状态,如果变为了已启动,代表已经正常启动。
五、配置一个简单的单项同步任务
本次演示将edu_db1库中的表t_udict 同步到 库user_db的表t_udict。

1、mysql开启binlog
(1)首先通过如下命令判断mysql是否开启binlog
show master status
若出现如下信息,则表示已开启binlog
若没有任何信息,则需要修改配置文件(my.cnf),开启binlog,
关于找到my.cnf的方式可以参考如下 https://www.yuque.com/wangchao-volk4/whmpo0/pad6m7#CITaO
2、添加canal
- Canal官方文档:https://github.com/alibaba/canal/wiki
- Otter使用canal开源产品获取数据库增量日志数据,可以把cannal看作是源库的一个伪slave。
- 原理:canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master 发送dump请求,mysql master收到dump请求,开始推送binarylog给slave(也就是canal),canal解析binary log对象(原始为byte流)。
- Node集成了canal,不需要单独下载canal。
(1)在otter manager “配置管理-canal配置”页面点击添加:
(2)进入添加canal页面:
Cannal 存储机制分为memory和file,也可以在运行模式选项选择作为独立服务运行;
勾选其他参数设置,可以设置cannal的服务端口;
必须配置位点信息,否则如果你的数据库已有存量数据,第一次运行时需要等待比较长的时间,可以通过连接源库客户端执行sql获取,如下:

3、添加数据源
添加数据源过程较为简单,这里不做详细阐述,具体下面两张图。添加完后会出现下图列表中的两个数据源信息(一个为源库edu_db1,一个是目标库user_db,如果两个库在同一个数据源下,则不需要配置两个数据源)

4、添加数据表
进入数据表配置项,这里需要配置两个表edu_db1库中的表t_udict 和 库user_db的表t_udict
填入相应的信息
table示例说明
- 单表配置:alibaba.product
- 分表配置:alibaba[1-64].product , alibaba.product[01-32]
- 正则配置:(.).(.)
- schema name和table name都设置成.*表示全库同步
5、添加一个channel
进入同步管理

6、添加pipeline
添加channel成功后,点击Channel名字,进入Pipeline管理页面,添加一个Pipleline

如上图填好所需信息,勾选高级设置,可以选是否过滤ddl同步等选项,点击保存,成功后会返回Pipeline管理页面。7、添加映射关系
添加pipeline成功后,点击pipeline名字
进入映射关系列表页面,点击添加
进入添加映射关系页面
点击保存返回映射关系列表页面,如果源数据表是只同步一个表可以点击下一步,选择需要同步的字段映射关系;
映射关系页面如下
8、启动同步
(1)以上步骤都配置成功之后,返回channel页面,点击启用

(2)测试
在edu_db1的t_udit中新建一条数据
在user_db的表t_udit中查看同步效果,如下图,同步成功
六、配置双向同步任务
1、添加新的canal、channel、pipeline、映射关系,添加流程和第五章一样,第五章是将将edu_db1库中的表t_udict 同步到 库user_db的表t_udict。这里将源库和目标库反过来重新配置就行了。
2、配置完后如图所示



3、验证
同时开启两个Channel即可。分别在两个表中添加信息,都能够成功同步到另外一张表则表示同步成功。七、配置单表向多表同步任务
可用于的业务场景:分库分表时,用于增量数据的同步(原表同步到分表)
整体步骤与 配置单项同步类似,以下只突出描述差异的地方。
1、canal配置
2、添加数据源和表
添加数据源的过程略过
注意分表的写法,当分表作为目标表是,不能使用[0-1]这种写法,要使用[0|1]
下面这种只能作为源表,当用作目标表时,会报错
下面这种写法可以用作目标表,当验证连接表时会报错 ‘SELECT未成功’,没有任何影响

3、添加channel
4、添加pipeline
5、添加映射关系
如下配置,注意目标表
关于EventProcessor的编写可以参考 https://github.com/alibaba/otter/wiki/Otter%E6%89%A9%E5%B1%95%E6%80%A7
EventProcessor如下: ```sql package com.alibaba.otter.node.extend.processor;
import com.alibaba.fastjson.JSON; import com.alibaba.otter.shared.etl.model.EventColumn; import com.alibaba.otter.shared.etl.model.EventData; import org.apache.commons.lang.StringUtils; import org.slf4j.Logger; import org.slf4j.LoggerFactory;
import java.math.BigInteger;
/**
- 根据Id分片
id % 2 */ public class One2NTfIncomeDetailEventProcessor extends AbstractEventProcessor {
private static final Logger logger = LoggerFactory.getLogger(One2NTfIncomeDetailEventProcessor.class);
private static final String ID = “id”; private static final BigInteger TWO = BigInteger.valueOf(2L);
/**
king_user-> kinguser[0-1] *- @param eventData
- @return
*/
@Override
public boolean process(EventData eventData) {
logger.error(“eventData:{}”, JSON.toJSONString(eventData));
EventColumn idEventColumn = getColumn(eventData, ID);
if (idEventColumn == null) {
} String id = idEventColumn.getColumnValue(); if (StringUtils.isBlank(id)) {logger.error("[同步] id is null :{}", JSON.toJSONString(eventData.getColumns()));return false;
} String name = “kinguser“ + getShardNum(new BigInteger(id)); logger.info(name); eventData.setTableName(name); return true; }logger.error("[同步] id is null :{}", JSON.toJSONString(eventData.getColumns()));return false;
/*** 获取分片键*/private static int getShardNum(BigInteger id) {return id.mod(TWO).intValue();}
八、配置多表向单表同步任务
注意,多表向单表同步时,不解决主键冲突,如果有主键冲突,则覆盖。(理论上不应该存在主键冲突)
配置过程已经简化,如下
注意多表的写法,[0-1],必须使用这个写法

若有收获,就点个赞吧
0 人点赞
