github地址:https://github.com/alibaba/DataX?spm=a2c6h.12873639.0.0.21084f642Tf0bH
官网介绍:https://developer.aliyun.com/article/59373
一、基本介绍
阿里云开源离线同步工具DataX3.0介绍 一. DataX3.0概览 DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。

1、核心模块介绍
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
2、DataX调度流程
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。(默认每个TaskGroup并发执行5个Task)
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
二、搭建环境
- 系统:macos / linux
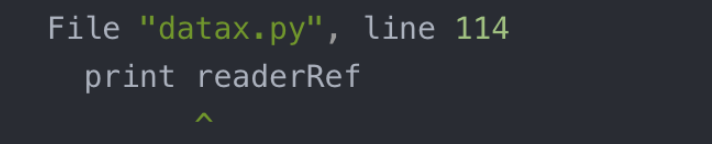
- python2.7(3以上会出以下问题)
- jdk 1.8
- datax安装 :直接下载 http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
三、macOS下使用方式
1、下载并打开datax
地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
解压并用pycharm打开
2、简单使用DataX
2.1 测试DataX安装环境
在datax包下运行如下命令,测试安装效果,注意在python2.7环境下运行datax的执行都是读取job.json中的配置信息,后面可以自行在书写job.json让datax执行相应的操作。
bin/datax.py job/job.json


2.2 查询执行脚本
1、查询从mysql读取数据,并向mysql写入数据的job
bin/datax.py -r mysqlreader -w mysqlwriter
执行上述命令后会输出job.json格式的脚本,按照如下格式填写即可,具体字段含义可以参考github文档
https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.md
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": [],"splitPk":"","connection": [{"jdbcUrl": [],"table": [],// querySql 使用之后 table、column、where将会被忽略"querySql":""}],"password": "","username": "","where": ""}},"writer": {"name": "mysqlwriter","parameter": {"column": [],"connection": [{"jdbcUrl": "","table": []}],"password": "","preSql": [],"postSql":[],"session": [],"username": "","writeMode": ""}}}],"setting": {"speed": {"channel": ""}}}}
需要介绍的字段
- querySql:自定义sql、配置之后,table、column、where将会失效
- splitPk:
- 描述:MysqlReader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能。
- 推荐splitPk用户使用表主键,因为表主键通常情况下比较均匀,因此切分出来的分片也不容易出现数据热点。
- 目前splitPk仅支持整形数据切分,不支持浮点、字符串、日期等其他类型。如果用户指定其他非支持类型,MysqlReader将报错!
- 如果splitPk不填写,包括不提供splitPk或者splitPk值为空,DataX视作使用单通道同步该表数据。
- preSql:
- 描述:写入数据到目的表前,会先执行这里的标准语句。如果 Sql 中有你需要操作到的表名称,请使用 @table 表示,这样在实际执行 Sql 语句时,会对变量按照实际表名称进行替换。比如你的任务是要写入到目的端的100个同构分表(表名称为:datax_00,datax01, … datax_98,datax_99),并且你希望导入数据前,先对表中数据进行删除操作,那么你可以这样配置:”preSql”:[“delete from 表名”],效果是:在执行到每个表写入数据前,会先执行对应的 delete from 对应表名称
- 必选:否;默认:无
- postSql:
- 描述:写入数据到目的表后,会执行这里的标准语句。(原理同 preSql )
- 必选:否;默认:无
- writeMode:
- 描述:控制写入数据到目标表采用 insert into 或者 replace into 或者 ON DUPLICATE KEY UPDATE 语句。
2.3 实际使用
单表迁移
1、将库smiler_user中的表king_user里面的数据 导入到 库user_db中的表king_user_1里面去
配置如下job.json文件
执行如下命令{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"connection": [{"querySql":["select * from king_user"],"jdbcUrl": ["jdbc:mysql://localhost:3306/smiler_user?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC"]}],"password": "123456","username": "root"}},"writer": {"name": "mysqlwriter","parameter": {"column": ["*"],"connection": [{"jdbcUrl": "jdbc:mysql://localhost:3306/user_db?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC","table": ["king_user_1"]}],"password": "123456","username": "root","writeMode": "insert"}}}],"setting": {"speed": {"channel": "1"}}}}
bin/datax.py job/job3.json

单表迁移到多表
reader配置sql语句可以如下,querySql配置为一个集合如下,查询sql语句按照顺序写,和新表名对应一致。
writer中配置表名kinguser[0-1],注意{"querySql":["select * from king_user WHERE MOD(id,2)=0;","select * from king_user WHERE MOD(id,2)=1;"],"jdbcUrl": ["jdbc:mysql://localhost:3306/smiler_user?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC"]}
{"jdbcUrl": "jdbc:mysql://localhost:3306/user_db?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC","table": ["king_user_[0-1]"]}
- 描述:控制写入数据到目标表采用 insert into 或者 replace into 或者 ON DUPLICATE KEY UPDATE 语句。
3、datax-web

若有收获,就点个赞吧
0 人点赞
