Create by Baola
环境:centos7
CentOS7下解决ifconfig command not found的办法:
sudo yum install net-tools # 需要有网
步骤:
- 修改主机名,主结点为队伍名,从节点为slave1、slave2
- 关闭防火墙(如果ssh正常可以不关闭)
- 添加主机名与ip映射(三台主从结点都需要)
- 配置ssh免密登录
- 编写xsync脚本
- 安装jdk
- 安装hadoop
- 安装mysql
- 安装hive
- 安装python和tensorflow
思考
在练习的时候,创建一台centos作为master,用master克隆两台。每个虚拟机需要拍摄快照,这样可以快速切换到裸机状态。
前奏
1、修改各主机的主机名,并配置 hosts 实现主机名和 ip 地址映射 ,要求主机名称为队伍名称 英文全拼。截图 hosts 文件配置内容
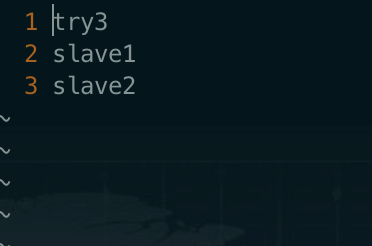
主机:try3
从机1:slave1
从机2:slave2
首先关闭防火墙
centos7关闭防火墙:# 查看防火墙开启状态sudo systemctl status firewalld# 关闭防火墙sudo systemctl stop firewalld# 关闭防火墙开机自启sudo systemctl disable firewalldcentos6关闭防火墙# service iptables stop# service iptables start# service iptables restart
修改主机名(线上赛需要,线下赛不需要)
vi /etc/hostname# 主机为try3,从机为slave1-2
添加主机名与ip的映射
在try3中修改hosts文件
# 修改hosts文件vim /etc/hosts# 添加如下内容master的ip masterslave1的ip slave1slave2的ip slave2
需要在三个节点的 hosts 文件下都配置所有节点的映射,类似下图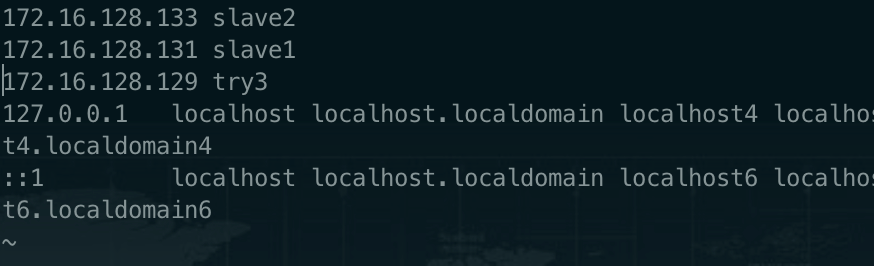
配置SSH免密登录(截图成功ssh登录到子节点截图)
在try3和slave1配置免密登陆
# 在master上生成私钥和公钥# 参数 -t rsa 表示使用rsa算法进行加密,执行后,会在/home/当前用户/.ssh目录下找到id_rsa(私钥)和id_rsa.pub(公钥)ssh-keygen -t rsa# 然后三次回车
主机上都输入以下三条命令,将自己的公钥分别分发一下
ssh-copy-id try3ssh-copy-id slave1ssh-copy-id slave2
- ssh-copy-id命令可以把本地主机的公钥复制到远程主机的authorized_keys文件上,
- ssh-copy-id命令也会给远程主机的用户主目录(home)和~/.ssh, 和~/.ssh/authorized_keys设置合适的权限。
- ssh- copy-id命令可以把本地的ssh公钥文件安装到远程主机对应的账户下。
第一次使用需要输入对方主机的密码
编写xsync脚本,方便后面同步
rsync需要提前安装好,发送主机和接受主机都需要安装rsync
#!/bin/bashpcount=$#if((pcount==0)); thenecho no args;exit;fi# get filenamep1=$1fname=`basename $p1`echo fname=$fname# get absoulute filenamepdir=`cd -P $(dirname $p1);pwd`echo pdir=$pdir# get current usernameuser=`whoami`echo -------------slave1--------------rsync -rvl $pdir/$fname $user@slave1:$pdirecho -------------slave2--------------rsync -rvl $pdir/$fname $user@slave2:$pdirecho okk!
在/usr/sbin/下写好脚本后需要添加权限chmod 777 xsync才能执行命令
安装配置 JDK(截图 java -version 命令)
所有软件统一安装到 /opt 目录下
# 解压tar -zxvf jdk-8u171-linux-x64.tar.gz# 重命名解压后的文件夹为 jdk:mv jdk1.8.0_171/ jdk# 配置环境变量:vi /etc/profile# 进入配置文件后在文件末尾添加如下内容export JAVA_HOME=/opt/jdkexport PATH=$PATH:$JAVA_HOME/bin# 安装好后使环境变量生效source /etc/profile
测试Java是否安装成功
java --version
用脚本将jdk发送到slave1和slave2
xsync /opt/jdk
安装hadoop并配置文件
# 解压hadoop安装包tar -zxvf hadoop-2.6.0.tar.gz# 重命名文件夹mv hadoop-2.6.0 hadoop
修改配置文件,配置文件都在/opt/hadoop/etc/hadoop/目录下
核心配置文件:core-site.xml
# 进入core-site.xmlvi core-site.xml# 添加如下内容,master 是主节点的主机名,根据自己的主机名或 IP 做修改<!-- 指定HDFS中NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://master的主机名或ip:9000</value></property><!-- 指定Hadoop运行时产生文件的存储目录 --><property><name>hadoop.tmp.dir</name><value>/usr/hadoop/data</value></property>
hdfs配置文件
修改hadoop-env.sh
将JAVA_HOME 为本机实际的目录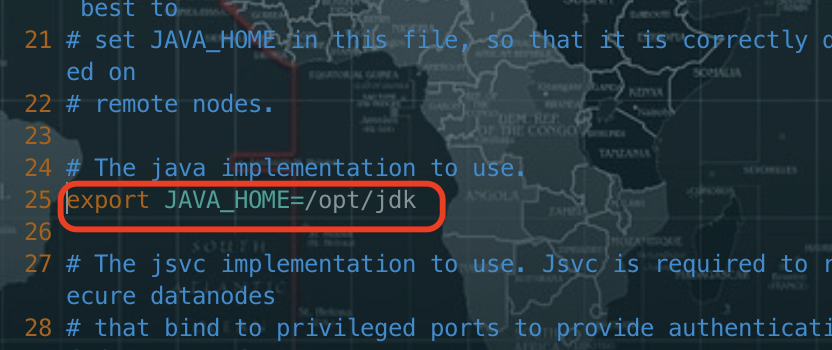
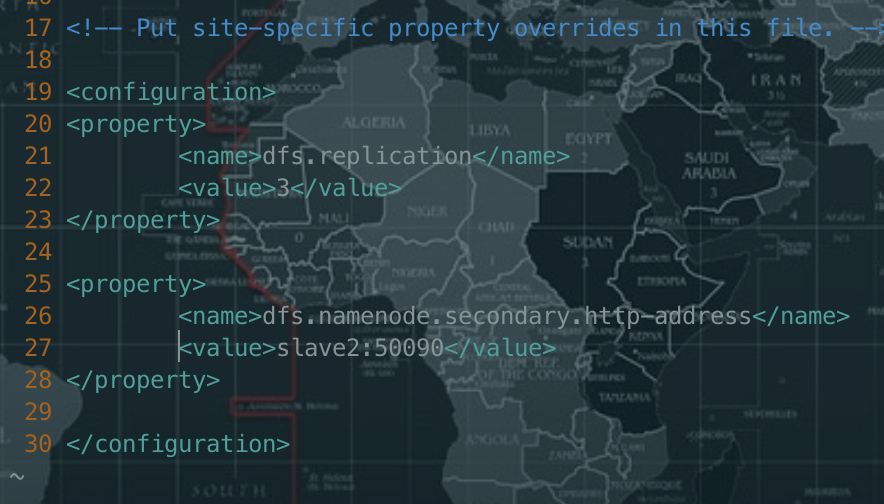
配置hdfs-site.xml
# 修改hdfs-site.xmlvi hdfs-site.xml# 添加如下内容<!-- 指定HDFS副本的数量 --><property><name>dfs.replication</name><value>3</value></property><!-- 指定Hadoop辅助名称节点主机配置 --><property><name>dfs.namenode.secondary.http-address</name><value>slave2:50090</value></property>
配置yarn
修改yarn-env.sh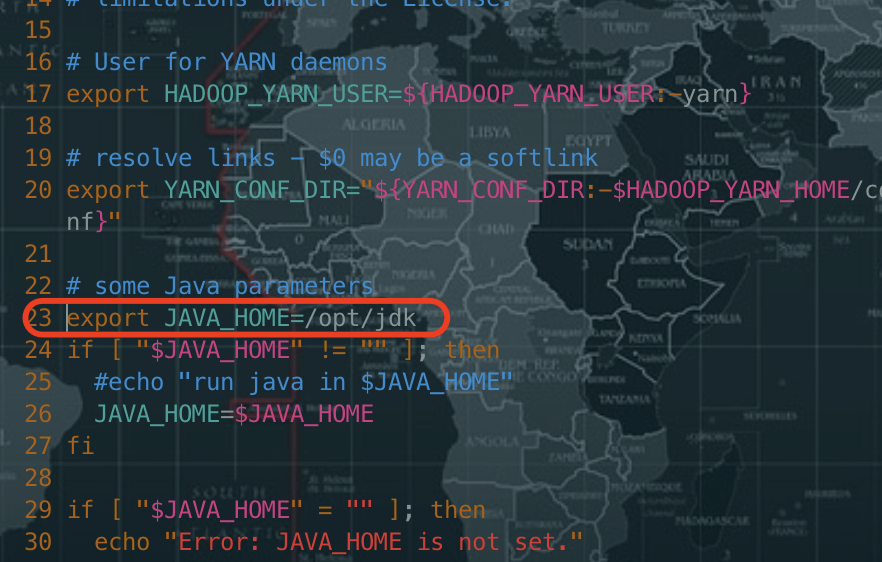
修改yarn-site.xml
# 编辑yarn-site.xmlvi yarn-site.xml# 在<configuration></configuration>中添加如下内容<property><!-- 指定resourcemanager的位置--><name>yarn.resourcemanager.hostname</name><value>slave</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
配置mapreduce
修改mapred-env.sh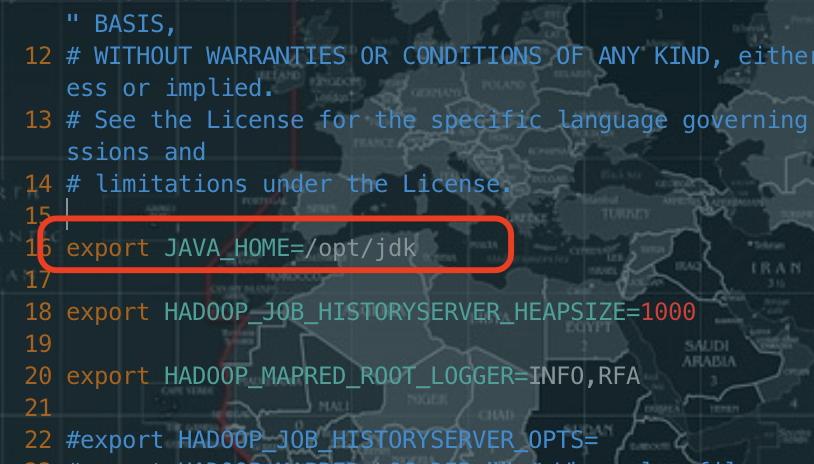
修改mapred-site.xml
# 复制一份cp mapred-site.xml.template mapred-site.xml# 编辑mapred-site.xmlvi mapred-site.xml添加如下内容<property><name>mapreduce.framework.name</name><value>yarn</value></property>
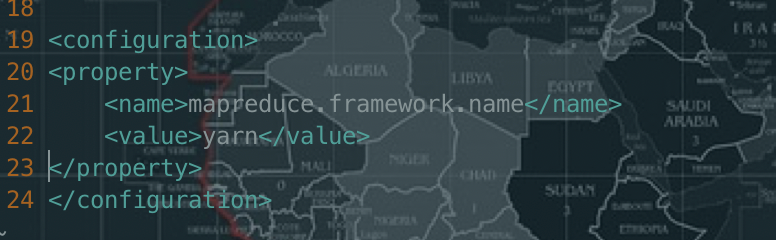
修改slaves(添加datanode结点)
vi slaves# 删除里面的localhost,添加如下内容(不允许有空格之类的)try3slave1slave2
配置环境变量(截图 profile 文件配置的关键位置)
vi /etc/profile# add one rowexport HADOOP_HOME=/opt/hadoop# add HADOOP_HOME after PATHexport PATH:$HADOOP_HOME/bin# 刷新/etc/profilesource /etc/profile
拷贝 hadoop 到其他的机器上(截图拷贝命令)
方式一:使用自己写的脚本xsync /opt/hadoop
方式二:使用scp
将修改后的 hadoop 复制到另外两个节点
cd /opt# 复制到slave1上scp -r hadoop slave1:/opt/# 复制到slave2上scp -r hadoop slave2:/opt/
初始化 hadoop 集群(截图执行命令)
hadoop namenode -format
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。中间是没有任何确认的
启动 Hadoop 集群(启动成功后执行 jps 命令,截图主节点和子节点的进程)
# 1.在master上启动hdfsstart-dfs.sh# 2.在slave1上启动yarnstart-yarn.sh
验证启动结果:jps(jps是JDK中的命令,不是Linux命令。不安装JDK不能使用jps)
try3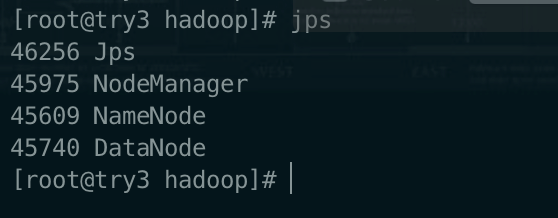
slave1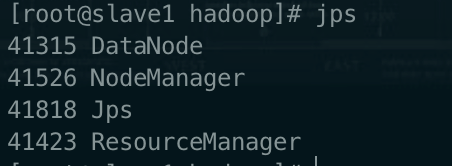
slave2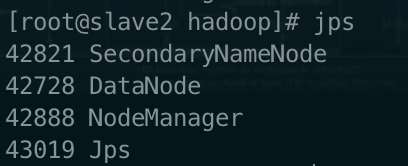
任务二 、配置 Hive 集群环境(5 分)
Mysql 安装
(截图 mysql 搭建成功 show databases 命令结果界面 2 分)
进入 /opt/目录下,解压Mysql安装包并重命名
tar –zxvf mysql-5.7.16-linux-glibc2.5-x86_64.tar.gzmv mysql-5.7.16 /opt/mysql //将重新命名后的mysql移动到/opt目录下mkdir -p /opt/mysql/data //mysql目录下生成data目录
在当前目录(/opt)下新建一个my.cnf,写入如下内容
注意:my.cnf不能放在/opt/mysql/下,否则会报错
/opt/my.cnf用完可以删除了
[mysqld]
basedir=/opt/mysql
datadir=/opt/mysql/data
socket=/tmp/mysql.sock
lower_case_table_names=1
user=root
character-set-server=utf8
symbolic-links=0
[client]
default-character-set=utf8
[mysqld-safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
覆盖掉/etc/my.cnf
cp my.cnf /etc/my.cnf
初始化数据库
/opt/mysql/bin/mysqld --initialize-insecure --basedir=/opt/mysql --datadir=/opt/mysql/data --user=root
将mysql加入服务
cp /opt/mysql/support-files/mysql.server /etc/init.d/mysql
设置mysql开机自启
chkconfig mysql on
启动mysql服务
service mysql start
配置mysql环境变量
vim /etc/profile
# 加入一下内容
export MYSQL_HOME=/opt/mysql
export PATH=$PATH:$MYSQL_HOME:bin
登陆mysql
mysql -uroot -p # 直接回车
# 修改密码
set password=password('root')
# 创建hive数据库
create database hive default charset utf8;
# 赋予权限
grant all privileges on *.* to 'root'@'%' identified by 'root';
# 刷新权限
flush privileges
# 退出mysql
exit
# 重新登录
mysql -uroot -proot
show databases;
exit
hive搭建
修改配置文件
根据环境部署的需求,修改主节点上的 hive 配置文件:hive-env.sh 和 hive-site.xml ,完成配置后,启动 hive 服务。
修改 hive-env.sh 文件
#进入 hive 的 conf 目录
cd /opt/hive/conf/
cp hive-env.sh.template hive-env.sh //重新命名
vi hive-env.sh
修改 hadoop 的安装目录=/opt/hadoop,去掉前面的注释符,行号:48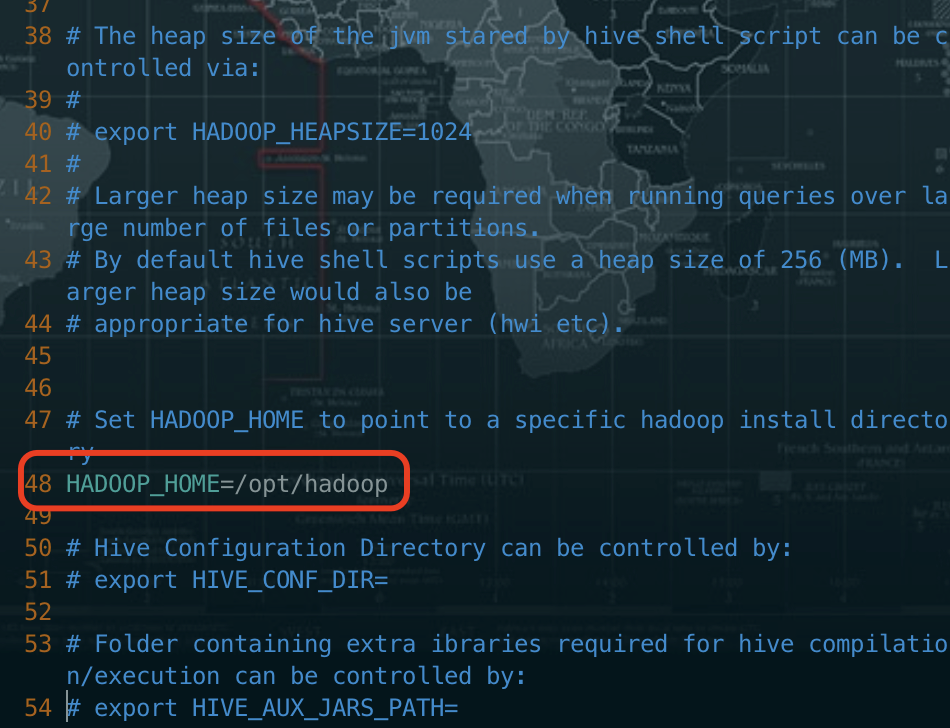
修改 hive-site.xml 文件
cp hive-default.xml.template hive-site.xml # 重新命名 hive-default.xml.template 文件
vi hive-site.xml # 编辑 hive-site.xml
主要修改以下参数,注意改为自己的主机名或 IP
第一处(行号: 395)
<property>
<name>javax.jdo.option.ConnectionURL </name>
<value>jdbc:mysql://try3:3306/hive?useSSL=false</value>
</property>
第二处(行号:790)
<property>
<name>javax.jdo.option.ConnectionDriverName </name>
<value>com.mysql.jdbc.Driver</value>
</property>
第三处(行号:381)
<property>
<name>javax.jdo.option.ConnectionPassword </name>
<value>root</value>
</property>
第四处(行号:815)
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
第五处(行号:52)
<property>
<name>hive.exec.local.scratchdir</name>
<value>/opt/hive/iotmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/opt/hive/iotmp</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
传jar包
#将mysql-connector-java-5.1.17.jar拷贝到/opt/hive/lib/
cp -r mysql-connector-java-5.1.17.jar /opt/hive/lib/
# 将hive发到从机(可省略)
xsync /opt/hive
# 以下步骤可以省略
#将 jline 包拷贝到 hadoop 中(每个机器都做一下,)
cp -r /opt/hive/lib/jline-2.12.jar /opt/hadoop/share/hadoop/yarn/lib
cd /opt/hadoop/share/hadoop/yarn/lib
mv jline-0.9.94.jar jline-0.9.94.jar.bak
xsync /opt/hadoop/share/hadoop/yarn/lib/jline-0.9.94.jar.bak
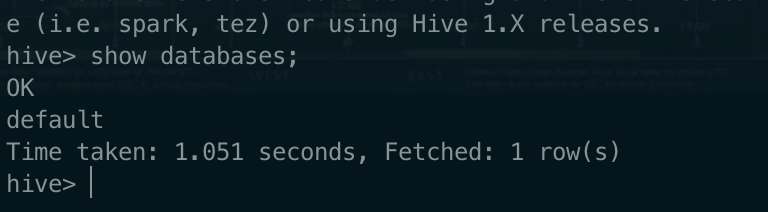
启动测试 hive(截图搭建成功 show databases 命令结果界面 1 分)
/opt/hive/bin 目录下执行
cd /opt/hive/bin
./schematool -dbType mysql -initSchema //初始化元数据
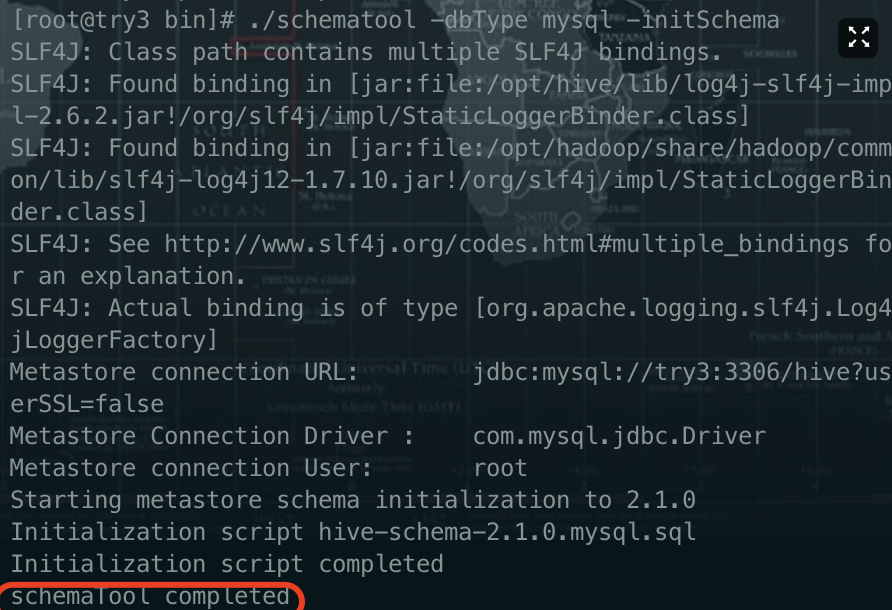
hadoop 启动情况下,执行 hive 命令
hive
安装python和TensorFlow
1.解压python安装包
tar -zxvf Python-3.6.3.tgz
2.安装编译相关工具
yum -y install zlib* openssl* gcc
3.编译安装
mkdir /usr/local/python3.6.3 #创建编译安装目录
./configure --prefix=/usr/local/python3.6.3
make && make install
4.建立软连接
ln -s /usr/local/python3/bin/python3 /usr/bin/python3
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip
使用pip安装tensorflow
pip install --upgrade pip
pip install tensorflow==1.1.0
Tensorflow测试
进入python3
import tensorflow as tf
sess = tf.Session()
hello=tf.constant('Hello,Tensorflow!')
print(sess.run(hello))
#若在终端下显示 Hello,Tensorflow! 则表示安装 tensorflow 成功
安装hbase
1、HBase安装
我们在搭建好Hadoop集群之后就可以搭建HBase数据仓库了.在安装HBase之前检查Hadoop集群是否处于启动状态。下面我们开始HBase的搭建
1、解压Hase、修改HBase的配置文件(3分)
进入/opt目录,找到HBase安装包并解压、重命名,命令如下
cd /opt
tar -zxvf hbase-1.4.3-bin.tar.gz
mv hbase-1.4.3 /opt/hbase
进入/opt/hbase/conf目录下,修改hbase-env.sh和hbase-site.xml
# 1.去掉注释,并修改JAVA_HOME
JAVA_HOME=/opt/jdk
# 2.去掉HBASE_MANAGES_ZK=true的注释
export HBASE_MANAGES_ZK=true
编辑hbase-site.xml文件,添加如下几个属性值
<property>
<name>hbase.rootdir</name>
<value>hdfs://master的主机名或ip:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>集群所有的主机名或IP,逗号隔开</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/hbase/zookeeper</value>
</property>
配置环境变量(集群每台机器都要配置一下)
vi /etc/profile
source /etc/profile
编辑regionservers,添加子节点的主机名或者IP地址
拷贝HBase到其他的机器上(1分)
xsync /opt/hbase
2、启动hbase集群(2分)
start-hbase.sh
验证集群的启动情况:jps
主节点 HMaster、HQuorumPeer
子节点HRegionServer、HQuorumPeer
做后反思
hadoop搭建时,第三台机器启动不了secondaryNamenode,我当时以为是配置文件出错。检查了好几遍。最后想到通过日志文件来排错, 但是误认为日志文件在try3上,所以问题一直没有解决。没想到在slave2上也有日志文件,一看日志文件就是知道原来是/etc/hosts文件里面的ip和域名不对应。
为了做题快速,环境搭建一开始可以将/etc/profile相关的配置(jdk的bin、hadoop的bin和sbin、mysql的bin、hive的bin)项都写上
错误:No database selected
Metastore connection URL: jdbc:mysql://try3:3306?useSSL=false
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to 1.2.0
Initialization script hive-schema-1.2.0.mysql.sql
Error: No database selected (state=3D000,code=1046)
org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent !!
*** schemaTool failed ***
原因:
<property>
<name>javax.jdo.option.ConnectionURL </name>
<value>jdbc:mysql://try3:3306/hive?useSSL=false</value>
</property>
value中的hive没有写上去,加上就可以了

若有收获,就点个赞吧
0 人点赞
