微服务实践目录,可以参见连接。
缓存系列包括:
1.微服务管理-11.缓存概述
1.微服务管理-11.缓存-0.技术
1.微服务管理-11.缓存-1.多级缓存设计
1.微服务管理-11.缓存-2.典型缓存架构设计
1.微服务管理-11.缓存-3.实践-用户中心缓存设计
1.微服务管理-11.缓存-4.总结
背景
前面介绍了缓存的设计方法,缓存技术,缓存方法等内容。本着本系列文章的一贯宗旨:理论结合实践,所以需要将理论知识真正的落地到实践中。本文主要说明在缓存实践中会遇到的问题以及这些问题的解决办法。
典型缓存架构(缓存设计模式)
对于缓存来说数据应该被怎样初始化、更新、失效、持久化都是问题,对于解决这些问题有前人总结出的架构模式帮我们解决。
缓存设计模式中分为两类:Cache-Aside、Cache-As-SoR两类。这两类代表着对缓存使用方式的不同的认知。Cache-Aside代表缓存就是进行快速访问数据的过程。Cache-As-SoR代表缓存是一个数据存储系统,以数据存储系统的使用方式使用缓存技术。
Cache-Aside即业务代码围绕着Cache写,是由业务代码维护缓存。业务代码进行缓存的读写工作,读时使用击穿读,写使用双写方式完成。
Cache-As-SoR即把Cache看作为SoR,所有操作都是对Cache进行,然后Cache再委托给SoR进行真实的读/写。即业务代码中只看到Cache的操作,看不到关于SoR相关的代码。有是那种实现:Read Through, Write Through, Write Behind Caching。
在缓存系统内中有三个概念:
- SoR(system-of-recode):记录系统,或者叫数据源,即实际存储原始数据的系统
- Cache:缓存,是SoR的快照数据,Cache的访问速度比SoR要快,放入Cache的目的是提升访问速度,减少回溯的次数。
- 回溯:即回到数据源头获取数据,Cache没命中时需要从SoR读取数据。
Cache-As-SoR的三种实现方式:
- Read Through, 业务代码首先调用Cache,如果Cache不明中有Cache回溯到SoR,而不是业务代码(即由Cache读SoR)。Read Through的特点是业务代码与更新缓存代码分离,不像Cache-Aside模式那样更新缓存代码和SoR代码角质在一起。更利于缓存代码的统一维护。
- Write Through, 被成为穿透写/直写模式—业务代码首先调用Cache写(新增/修改)数据,然后有Cache负责写缓存和写SoR,不用业务代码去写。Write Through的特点和Read Through相仿,不过从查询时发生变为在更新数据时发生。
- Write Behind Caching,又叫Write Back。一些了解Linux操作系统内核的同学对Write Back应该非常熟悉,这不就是Linux文件系统的Page Cache的算法吗?是的,你看基础这玩意全都是相通的。Write Back与Write Through不同之处在于Write Back是异步写的。说明白点就是在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。Write Back的特点是让数据的I/O操作飞快无比(因为直接操作内存嘛 ),因为异步,write backg还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的。
| 技术 | Jetedis | Guava Cache | Ehcache3.x | | —- | —- | —- | —- |
| Cache-Aside | 支持 | 支持 | 支持 |
| Read Through | 不支持 | 支持 | 支持 |
| Write Through | 不支持 | 不支持 | 支持 |
| Write Behind Caching | 不支持 | 不支持 | 支持 |
对于Cache-Aside,可能存在并发更新情况,即如果多个应用实例同时更新那么缓存怎么办?下一节就说明相关的关注点。
缓存架构关注点
在缓存真正落地时可能会遇到的问题、以及这些问题的解决方法与理论有一定的隔阂,不过这种隔阂可以考验我们的设计与架构能力。也考验我们深度思考的能力。
在缓存系统中,缓存总有失效的时候,比如我们经常使用的 Memcache 和 Redis ,都会设置超时时间;而一旦缓存到了超时时间失效之后,如果此时再有大量的并发向数据库发起请求,就会造成服务器卡顿甚至是系统当机。这就是 Dog Pile Effect 。可以使用Read Though模式进行解决。
当请求了缓存中没有的数据时或当缓存服务挂掉时,这时候就会回源到DB里面。此时如果黑客故意对上面数据发起大量请求,则DB有可能会挂掉,这就是缓存击穿。当然缓存挂掉的话,正常的用户请求也有可能造成缓存击穿的效果。
最简单的方式处理缓存击穿问题:缓存永不过期。真正的缓存过期时间不有Redis控制,而是由程序代码控制。当获取数据时发现数据超时时,就需要发起一个异步请求去加载数据。符合Write Back模式。
在缓存宕机的情况下,为了保证服务能够正常的提供服务最好的方式是使用多级缓存的本地缓存进行暂时数据保存。在这其中有两种方式选择:白名单、布隆过滤器(Bloom Filter)。
白名单顾名思义就是:在缓存宕机之前的一段时间里,会将请求的数据在系统中的有无,记录在一个Map中。当缓存宕机后,首先在Map中判断是否含有数据,有则回源DB,没有的话就直接返回结果。
Bloom Filter实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
保证线程安全的模式Copy Pattern。Copy Pattern包括两种Copy-On-Read(在读时复制)和Copy-On-Write(在写实复制),很多本地缓存技术都是基于堆缓存中对象饮用方式。这样就会导致如果有一个请求获取了缓存数据并修改它,则可能发生不可预测的问题。所以,就需要使用COR或COW进行。
解决方案
对于缓存系统来说就是为了提高系统的并发能力。在前面几篇文章过后大家也对缓存系统有了深入的认知,在此基础上提出一个终极缓存架构设计方案:
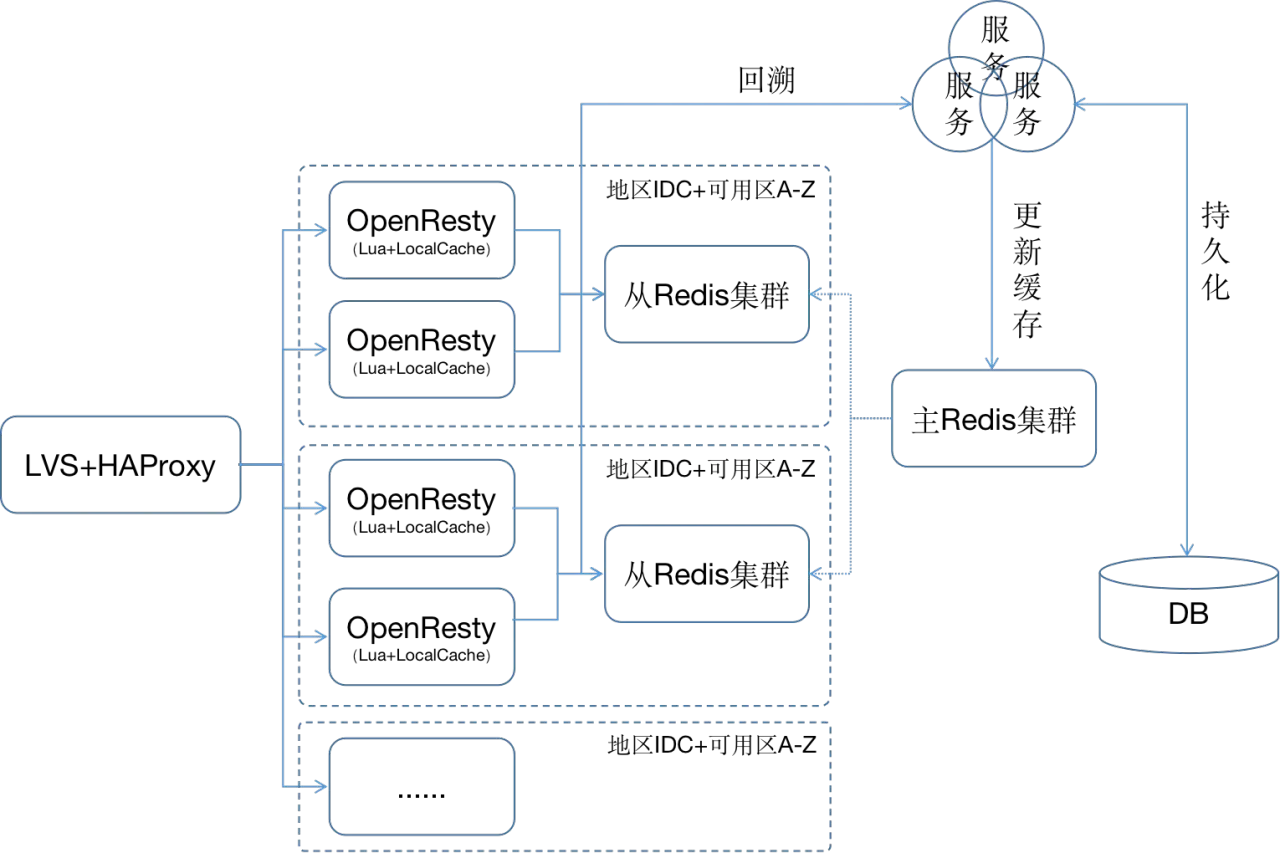
在上面的架构中将OpenResty和Redis推到最前端,将服务押后到Redis之后。对于分布式缓存,我们需要在OpenResty应用中尽享应用混存来减少Redis集群的访问冲击,即首先查询OpenResty本地缓存,如果命中则直接返回,如果没有则接着查询Redis集群,如果在没有则进行回溯查询。
架构中将Redis视为存储,而非缓存。使用几乎全量缓存的方式,将数据加入到缓存系统中。每个请求直接使用Nginx缓存或Redis缓存进行返回,不需要通过任何后台服务、数据库即可完成请求的处理。这样最大限度的降低请求处理时间,最大限度的加大并发数。
综上所有的几乎就是一个CQRS系统。将该隔离的隔离开,将该耦合的耦合上去。这样就能更好的帮助我们形成一个完善的缓存架构。
总结
缓存是支持高并发的已经很好的处理方式。不过要使用好缓存还是很考验研发人员能力的。从使用Redis、Memcache作为存储使用,还是作为缓存使用就是可以区分出一个人对于缓存的认知。所以,不要对任何一门技术设限,他不应该只是它本来擅长的位置体现作用。应该将技术扩展到其他可以满足技术特性的场景中去。
参考
缓存双写不一致问题
分布式缓存击穿(布隆过滤器 Bloom Filter)
缓存更新的套路
不懂多级缓存的分层架构?那就看看这个吧!
CDN的本质—大规模分布式多级缓存系统
如何处理 Dog Pile Effect
CQRS实践(1): 什么是CQRS
OpenResty® - 中文官方站

若有收获,就点个赞吧
0 人点赞
