微服务实践目录,可以参见连接。
起因:
在很多人的想法里认为事务是无法考量的。无法说明的,就想老子所说的:
道可道,非常道。名可名,非常名。
人对不了解的事务的学习与分析过程中有个分歧:
- 追求了解事务最根本的真相,不断的分解、抽象、联想去组织处合适的理论。
- 赋予这个事务神话的色彩。以神的意志,解释不可理解的事务
对于现代学科来说,现代的理学和文学都最终会归化到数学,数学会归化的哲学。例如:美学中的黄金比例,文学中的逻辑学,经济学中统计学等等。
但是,对于软件工程一门工程类学科来说无法考量与度量某一项事务是否是可行?答案自然是明确的软件工程必须是可以度量的,虽然在这么多年的发展过程中没有一套完整适应时代与技术的度量方法。但是度量对于一个工程类学科来说是必须的,而且之后也会不断的朝着可度量的方向发展。
度量是了解事务内部特征的最基础的方法。但在国内度量其实是从上到下都回避的一件事,所以,需要考量加入度量指标的时间点,以及加入的度量指标,加入方式等。不过可度量的标准是公司达到一定水平是一个标志。
本文主要描述度量指标的实践,上面这些社会学的理论请自行把握。
度量指标:
在网上找了很多关于度量、指标、维度的资料。这几个词可以从《统计学》到《软件运营》、再从《分析指标体系》到《软件过程度量模型》。就这几个词我找了很大一圈还是没有找到很好的解释,所以,我就妄自尊大的自己对度量指标进行一个解释:
度量是指对于一个物体或是事件的某个性质给予一个数字,使其可以和其他物体或是事件的相同性质比较。度量可以是对一物理量(如长度、尺寸或容量等)的估计或测定,也可以是其他较抽象的特质。
指标 : 预期中打算达到的指数、规格、标准
度量出自维基百科,指标出自以上是从Wiki上找到的介绍。简单的看度量就是描述事物的一个特定方面的数字。
度量指标(Metrics) : 指用于描述一个物体或事物的某个性质的指数、规格、标准,使其可以和其他的物体或者事物的提交。
从软件的角度讲度量即把所有东西都量化、数据化、可采集。指标即表示对这些量化后的数据的目标值。维度即标识一个事物某一个侧面的一组指标。
软件指标定义:
大概说明了度量指标的内容之后,接下来以工程化实施方案的思维方式思考如果要实施度量指标需要完成怎样的工作。借鉴一些ToGAF的概念,每一项事都是需要有目标的,在目标的指导下去做具体的实施工作。度量指标工作具体的实施步骤如下:
- 制定度量指标所关心的目标,所要解决的问题;(明确要解决的问题域)
- 建立一套针对问题域的分析方法,并找到要进行分析的数据域;(制定方法论,解决域)
- 对数据域中的数据进行可度量化的拆解与分析;(度量指标拆解)
- 针对解决域中的方法以及分解出的具体指标,制定实施方案;(具体实施)
- 实施完成后可以产出数据与报表。针对结果进行评估平调整整个解决过程。(持续优化)
“指标体系”这个概念是应用比较广泛的,我们从正式出版物中摘取一个定义:指标体系,即统计指标体系,是由一系列具有相互联系的指标所组成的整体,可以从各个侧面完整地反映现象总体或样本的数量特征。
统计指标体系从其功能和作用不同,可分为描述统计指标体系,评价统计指标体系和预警统计指标体系三种。描述统计指标体系是由若干对社会经济活动状况做出完整而系统描述的基础指标所组成的。评价统计指标体系是由若干对社会经济行为结果进行比较、评估、考核,以检查其工作和综合效益的统计指标所组成。预警统计指标体系主要用于对社会经济宏观运行的监测,并根据指标值的变化,预报社会经济即将出现的不平衡状态、突发事件及某些结构性障碍等。
引自《统计学教程》(主编:王怀伟 清华大学出版社)
从上图可以看到在软件行业内指标体系可以分为很多种。最终对客户有意义的,有价值的肯定是运营指标体系。运行软件指标体系是本次的目标,主要描述软件运行过程中的一些参数。《软件过程指标》、《软件指令指标》、《DevOps指标》都是软件在开发以及运营过程中的软件过程指标。
下图中是指标体系的一个实例,用于描述DevOps指标体系中的一些指标:

这个实例中描述了DevOps的几个指标。主要的指标目标是为了体现DevOps怎样为客户提供价值,并在这个基础上提出适应多变的环境(需求环境,开发环境,质量环境,过程环境等)。
真对于软件运行指标体系的目标是提高稳定性,减少故障,降低运营成本。
在驱动指标体系搭建形成闭环的最后一步就是数据应用,在采集的数据验证无误后应用于实际业务中,驱动业务增长。常用的分析理论有:4P理论、PESTEL理论、SWOT理论、5W2H理论、逻辑树理论、用户使用行为理论、AARRR理论。可以参照:数据分析方法论(二)——常用数据分析方法
真对于软件运行指标体系的目标,分析方法需要满足故障检测,平稳程度,自动化程度几个方向。分析方法以统计方法为主,统计故障情况,统计自动化占比,统计测试质量等。
上面说明了度量指标的目标和指标分析方法。都是一些通用性的分析,未对某一个特定领域中的指标体系进行分析。一个特定领域中的指标体系包括的内容有哪些,这些内容起着怎样的作用。这些内容会在本节加以分析与描述。
先给出一个指标体系的整体架构:
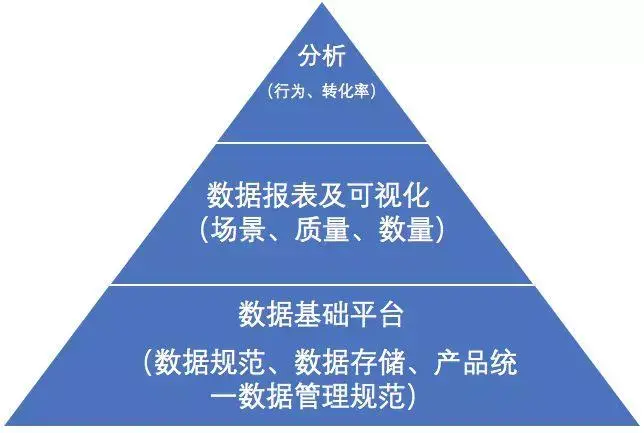
上图出自数据体系搭建 | 梳理架构和指标体系,类似于软件指标定义中提到的内容一个指标体系从上到下可以分为:分析(模型,方法),数据可视化,基础数据平台部分。
分析方法:
在整个指标体系中分析方法提供跟业务相关的,对业务负责的内容。因为分析方法是根据要解决的问题域进行建立的,并对业务是有意义的。分析方法是多变的,在针对同样的行业、同样的场景、不同的公司时使用的分析与建模的方法都可能是不同的。因为分析方法是真对大环境去把控的,所以,需要做的是真对这些元知识(分析方法),进行分析与总结之后在应用于不同的场景。
从某个侧面来说,数据分析技术(大数据,BI等)最终有意义的方面都是分析方法。具体使用哪项分析方法,怎样做展示其实对整个数据分析来说意义不大。
数据可视化:
数据需要展示出来才可以体现出数据的意义,所以,就像敏捷中“交付价值”一样。数据有了必须要提供价值才可以展现出数据的意义。这里的数据可视化的方式还是需要针对度量进行相关的分析与展示的,或者直接使用相关的内容进行展示的能力。下面说明另种可以进行定制化的展示的可视化工具。
数据基础平台:
数据基础平台即包括数据采集,数据接收,数据存储,数据分析基础等内容。主要满足基础的数据处理要求,可以与现在流程的DMP概念认为是等同的。大数据的基础也就是:
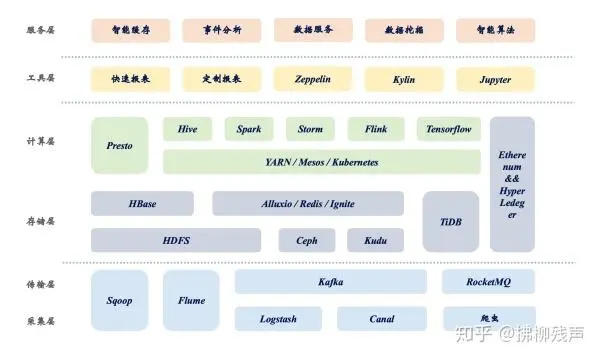
数据收集部分这里写的不是很完全,数据接收、存储、分析都还算比较完善,不过也没有做更多的深入。在之后的实施部分里会说明本文的技术选型。
- Grafana是一个开源的度量分析和可视化套件。它最常用于可视化基础设施和应用程序分析的时间序列数据,但也用于许多其他领域,包括工业传感器,家庭自动化,天气和过程控制。
- Kibana是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和 Elasticsearch 协作。您可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。您可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现。
至于其他的指标可视化工具:Tableau,FindReport,Splunk。都是商业版软件,不适合在小公司使用。所以,不会选择这些商业化软件。
上面定义了软件指标的目标以及方法,现在需要将度量指标体系确定并细化到可度量级别。所以,就需要对指标进行拆解工作。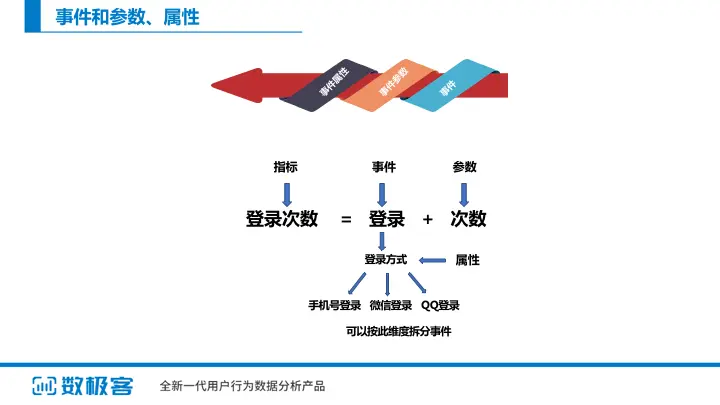
事件、参数和属性说明:先给大家解释三个概念,事件、参数和属性。事件可以理解为用户的某个行为,比如登录、注册、购买,都统称为事件;事件和参数结合起来就是指标,比如登录次数、注册人数、购买金额这些我们称为指标,而次数、人数、金额就是事件的参数。事件属性可以从某个维度对事件进行拆分分析,比如登录方式就是登录的属性,分析不同登录方式的登录次数。
上图为运营指标的实例,软件运行指标体系的例子服务从异步消息系统接收到一个消息。事件即接收到消息,参数可以是处理时长(消息处理时长以及消息处理事件)。指标是处理时长必须在10ms之内。属性是消息可以是定时任务,异步任务等等。
下面会具体的介绍软件运行指标体系中会涉及到的度量。
| 类别 | 信息 | 触发机制 | 单位 | 说明 | | —- | —- | —- | —- | —- |
| jvm | 系统内存总量 | 定时 | Kb | mem |
| jvm | 空闲内存数量 | 定时 | Kb | mem.free |
| jvm | 处理器数量 | 初始化 | 个 | processors |
| jvm | 系统正常运行时间 | 定时 | 毫秒 | uptime |
| jvm | 应用上下文正常运行时间 | 定时 | 毫秒 | instance.uptime |
| jvm | 系统平均负载 | 定时 | 百分比 | systemload.average |
| jvm | 堆信息 | 定时 | Kb | heap,heap.committed,heap.init,heap.used |
| jvm | 线程信息 | 定时 | 个 | threads,thread.peak,thead.daemon |
| jvm | 类加载信息 | 定时 | Info | classes,classes.loaded,classes.unloaded |
| jvm | 垃圾收集信息 | 定时 | 个 | gc.xxx.count, gc.xxx.time |
| tomcat | 容器session | 定时 | 个 | httpsessions.active,httpsessions.max |
| 数据库 | 连接 | 定时 | 个 | 最大连接数, 最小连接数, 活动连接数,连接池的使用情况 |
| … | | | | |
指标分类:
软件本来就是数字化的事物,不过就是涉及到度量的维度。根据度量维度的不同,可能会涉及到很多模糊不清的指标。所以针对每一个度量指标必须遵循SMART原则:
- S代表具体(Specific)
- M代表可度量(Measurable)
- A代表可实现(Attainable)
- R代表现实性(Realistic)
- T代表有时限(Timebound)
这样既有度量目标,又可以具体的去实施。不存在不可度量的指标,方便具体的落地实施工作。
- Counter(计数器)
Counter是一个累计度量指标,它是一个只能递增的数值。计数器主要用于统计服务的请求数、任务完成数和错误出现的次数等等。计数器是一个递增的值。
- Gauge(测量器)
Gauges是一个最简单的计量,一般用来统计瞬时状态的数据信息。它表示一个既可以递增, 又可以递减的值。比如系统中处于pending状态的job。
- Histogram(柱状图)
Histograms主要使用来统计数据的分布情况,最大值、最小值、平均值、中位数,百分比(75%、90%、95%、98%、99%和99.9%)。
- Meters(码表)
Meters用来度量某个时间段的平均处理次数(request per second),每1、5、15分钟的TPS。比如一个service的请求数,通过metrics.meter()实例化一个Meter之后,然后通过meter.mark()方法就能将本次请求记录下来。统计结果有总的请求数,平均每秒的请求数,以及最近的1、5、15分钟的平均TPS。
- Timers(计时器)
Timers主要是用来统计某一块代码段的执行时间以及其分布情况,具体是基于Histograms和Meters来实现的。
以上的度量指标分类是从Metrics-Java版的指标度量工具之一和
Metrics Core整理出来的。
总结:
本阶段主要分析了度量指标的成因,以及度量指标中相关的分类方法。所以,这里只介绍了度量指标的前期概念。在下面一篇文章中给出相关的技术设计以及具体实践。
参考:
度量
互联网运营,该分析哪些数据和指标
数据分析方法论(一)——构建数据指标体系
数据分析方法论(二)——常用数据分析方法
创业公司如何构建数据指标体系?
电商数据分析基础指标体系
如何搭建指标体系
从 0 到 1 搭建数据运营体系
数据体系搭建 | 梳理架构和指标体系
监控:
metrics
Metrics-Java版的指标度量工具之一
JAVA Metrics度量工具 - Metrics Core 翻译
第 44 课 度量指标(Metrics)
度量指标类型
软件度量指标:
智能分析最佳实践——指标逻辑树
利用Metrics+influxdb+grafana构建监控
基于dropwizard/metrics ,kafka,zabbix构建应用统计数据收集展示系统
软件过程度量指标:
软件度量
軟體度量
软件过程质量度量与控制
软件过程度量模型
软件度量与软件过程管理
质量度量指标设定分析-1
常见软件项目度量指标介绍
敏捷软件估算和度量

若有收获,就点个赞吧
0 人点赞
