
这将是你全面了解 Sed 命令的一个机会,深入挖掘它的运行细节和精妙之处。
— Sylvain Leroux
有用的原文链接
请访问文末的“原文链接”获得可点击的文内链接、全尺寸原图和相关文章。
致谢
编译自 |
https://linuxhandbook.com/sed-reference-guide/
作者 | Sylvain Leroux
译者 | qhwdw 💎共计翻译:156.5 篇 贡献时间:380 天
在前面的文章中,我展示了 Sed 命令的基本用法[1], Sed 是一个实用的流编辑器。今天,我们准备去了解关于 Sed 更多的知识,深入了解 Sed 的运行模式。这将是你全面了解 Sed 命令的一个机会,深入挖掘它的运行细节和精妙之处。因此,如果你已经做好了准备,那就打开终端吧,下载测试文件[2] 然后坐在电脑前:开始我们的探索之旅吧!
关于 Sed 的一点点理论知识
首先我们看一下 sed 的运行模式
要准确理解 Sed 命令,你必须先了解工具的运行模式。
当处理数据时,Sed 从输入源一次读入一行,并将它保存到所谓的模式空间pattern space中。所有 Sed 的变换都发生在模式空间。变换都是由命令行上或外部 Sed 脚本文件提供的单字母命令来描述的。大多数 Sed 命令都可以由一个地址或一个地址范围作为前导来限制它们的作用范围。
默认情况下,Sed 在结束每个处理循环后输出模式空间中的内容,也就是说,输出发生在输入的下一个行覆盖模式空间之前。我们可以将这种运行模式总结如下:
1. 尝试将下一个行读入到模式空间中
2. 如果读取成功:
1. 按脚本中的顺序将所有命令应用到与那个地址匹配的当前输入行上
2. 如果 sed 没有以静默模式(-n)运行,那么将输出模式空间中的所有内容(可能会是修改过的)。
3. 重新回到 1。
因此,在每个行被处理完毕之后,模式空间中的内容将被丢弃,它并不适合长时间保存内容。基于这种目的,Sed 有第二个缓冲区:保持空间hold space。除非你显式地要求它将数据置入到保持空间、或从保持空间中取得数据,否则 Sed 从不清除保持空间的内容。在我们后面学习到 exchange、get、hold 命令时将深入研究它。
Sed 的抽象机制
你将在许多的 Sed 教程中都会看到上面解释的模式。的确,这是充分正确理解大多数基本 Sed 程序所必需的。但是当你深入研究更多的高级命令时,你将会发现,仅这些知识还是不够的。因此,我们现在尝试去了解更深入的一些知识。
的确,Sed 可以被视为是抽象机制[3]的实现,它的状态[4]由三个缓冲区[5] 、两个寄存器[6]和两个标志[7]来定义的:
◈ 三个缓冲区用于去保存任意长度的文本。是的,是三个!在前面的基本运行模式中我们谈到了两个:模式空间和保持空间,但是 Sed 还有第三个缓冲区:追加队列append queue。从 Sed 脚本的角度来看,它是一个只写缓冲区,Sed 将在它运行时的预定义阶段来自动刷新它(一般是在从输入源读入一个新行之前,或仅在它退出运行之前)。
◈ Sed 也维护两个寄存器:行计数器line counter(LC)用于保存从输入源读取的行数,而程序计数器program counter(PC)总是用来保存下一个将要运行的命令的索引(就是脚本中的位置),Sed 将它作为它的主循环的一部分来自动增加 PC。但在使用特定的命令时,脚本也可以直接修改 PC 去跳过或重复执行程序的一部分。这就像使用 Sed 实现的一个循环或条件语句。更多内容将在下面的专用分支一节中描述。
◈ 最后,两个标志可以修改某些 Sed 命令的行为:自动输出auto-print(AP)标志和
一个更精确的 Sed 运行模式
一图胜千言,所以我画了一个流程图去描述 Sed 的运行模式。我将两个东西放在了旁边,像处理多个输入文件或错误处理,但是我认为这足够你去理解任何 Sed 程序的行为了,并且可以避免你在编写你自己的 Sed 脚本时浪费在摸索上的时间。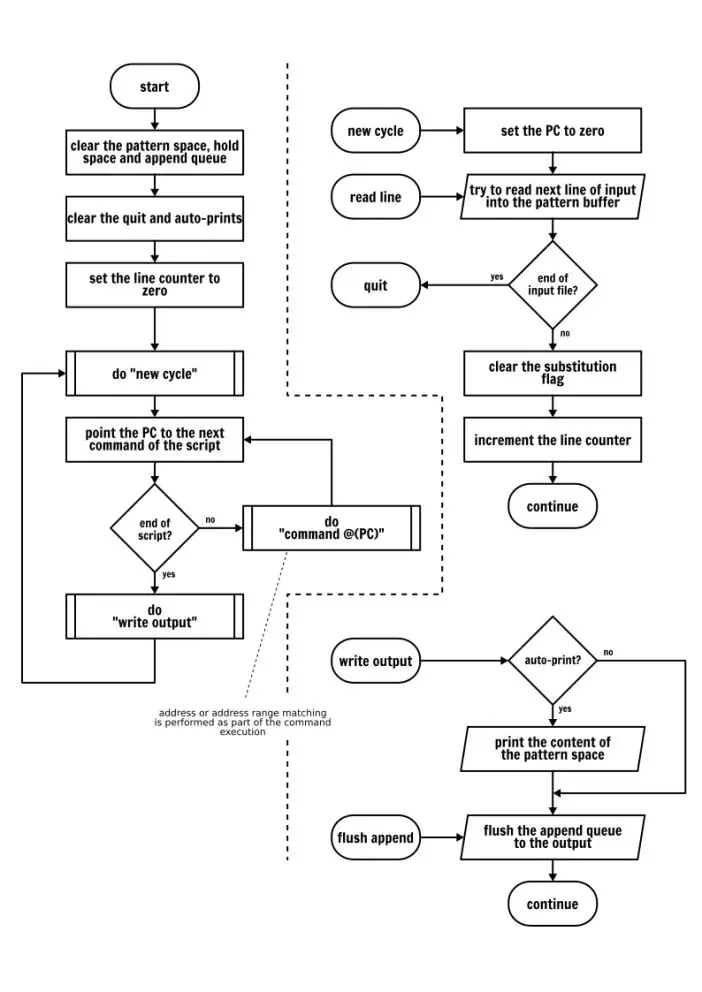
The Sed execution model
你可能已经注意到,在上面的流程图上我并没有描述特定的命令动作。对于命令,我们将逐个详细讲解。因此,不用着急,我们马上开始!
打印命令
打印命令(p)是用于输出在它运行那一刻模式空间中的内容。它并不会以任何方式改变 Sed 抽象机制中的状态。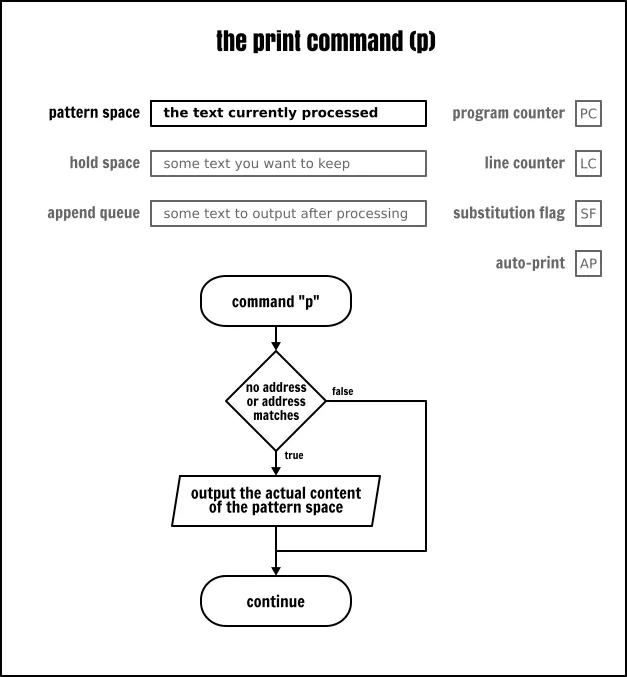
The Sed print command
示例:
sed -e ‘p’ inputfile
上面的命令将输出输入文件中每一行的内容……两次,因为你一旦显式地要求使用 p 命令时,将会在每个处理循环结束时再隐式地输出一次(因为在这里我们不是在“静默模式”中运行 Sed)。
如果我们不想每个行看到两次,我们可以用两种方式去解决它:
sed -n -e ‘p’ inputfile # 在静默模式中显式输出
sed -e ‘’ inputfile # 空的“什么都不做的”程序,隐式输出
注意:-e 选项是引入一个 Sed 命令。它被用于区分命令和文件名。由于一个 Sed 表达式必须包含至少一个命令,所以对于第一个命令,-e 标志不是必需的。但是,由于我个人使用习惯问题,为了与在这里的大多数的一个命令行上给出多个 Sed 表达式的更复杂的案例保持一致性,我添加了它。你自己去判断这是一个好习惯还是坏习惯,并且在本文的后面部分还将延用这一习惯。
地址
显而易见,print 命令本身并没有太多的用处。但是,如果你在它之前添加一个地址,这样它就只输出输入文件的一些行,这样它就突然变得能够从一个输入文件中过滤一些不希望的行。那么 Sed 的地址又是什么呢?它是如何来辨别输入文件的“行”呢?
行号
Sed 的地址既可以是一个行号($ 表示“最后一行”)也可以是一个正则表达式。在使用行号时,你需要记住 Sed 中的行数是从 1 开始的 —— 并且需要注意的是,它不是从 0 行开始的。
sed -n -e ‘1p’ inputfile # 仅输出文件的第一行
sed -n -e ‘5p’ inputfile # 仅输出第 5 行
sed -n -e ‘$p’ inputfile # 输出文件的最后一行
sed -n -e ‘0p’ inputfile # 结果将是报错,因为 0 不是有效的行号
根据 POSIX 规范[8],如果你指定了几个输出文件,那么它的行号是累加的。换句话说,当 Sed 打开一个新输入文件时,它的行计数器是不会被重置的。因此,以下的两个命令所做的事情是一样的。仅输出一行文本:
sed -n -e ‘1p’ inputfile1 inputfile2 inputfile3
cat inputfile1 inputfile2 inputfile3 | sed -n -e ‘1p’
实际上,确实在 POSIX 中规定了多个文件是如何处理的:
如果指定了多个文件,将按指定的文件命名顺序进行读取并被串联编辑。
但是,一些 Sed 的实现提供了命令行选项去改变这种行为,比如, GNU Sed 的 -s 标志(在使用 GNU Sed -i 标志时,它也被隐式地应用):
sed -sn -e ‘1p’ inputfile1 inputfile2 inputfile3
如果你的 Sed 实现支持这种非标准选项,那么关于它的具体细节请查看 man 手册页。
正则表达式
我前面说过,Sed 地址既可以是行号也可以是正则表达式。那么正则表达式是什么呢?
正如它的名字,一个正则表达式[9]是描述一个字符串集合的方法。如果一个指定的字符串符合一个正则表达式所描述的集合,那么我们就认为这个字符串与正则表达式匹配。
正则表达式可以包含必须完全匹配的文本字符。例如,所有的字母和数字,以及大部分可以打印的字符。但是,一些符号有特定意义:
◈ 它们相当于锚,像 ^ 和 $ 它们分别表示一个行的开始和结束;
◈ 能够做为整个字符集的占位符的其它符号(比如圆点 . 可以匹配任意单个字符,或者方括号 [] 用于定义一个自定义的字符集);
◈ 另外的是表示重复出现的数量(像 克莱尼星号()[10] 表示前面的模式出现 0、1 或多次);
这篇文章的目的不是给大家讲正则表达式。因此,我只粘几个示例。但是,你可以在网络上随便找到很多关于正则表达式的教程,正则表达式的功能非常强大,它可用于许多标准的 Unix 命令和编程语言中,并且是每个 Unix 用户应该掌握的技能。
下面是使用 Sed 地址的几个示例:
sed -n -e ‘/systemd/p’ inputfile # 仅输出包含字符串“systemd”的行
sed -n -e ‘/nologin$/p’ inputfile # 仅输出以“nologin”结尾的行
sed -n -e ‘/^bin/p’ inputfile # 仅输出以“bin”开头的行
sed -n -e ‘/^$/p’ inputfile # 仅输出空行(即:开始和结束之间什么都没有的行)
sed -n -e ‘/./p’ inputfile # 仅输出包含字符的行(即:非空行)
sed -n -e ‘/^.$/p’ inputfile # 仅输出只包含一个字符的行
sed -n -e ‘/admin.false/p’ inputfile # 仅输出包含字符串“admin”后面有字符串“false”的行(在它们之间有任意数量的任意字符)
sed -n -e ‘/1[0,3]/p’ inputfile # 仅输出包含一个“1”并且后面是一个“0”或“3”的行
sed -n -e ‘/1[0-2]/p’ inputfile # 仅输出包含一个“1”并且后面是一个“0”、“1”、“2”或“3”的行
sed -n -e ‘/1.2/p’ inputfile # 仅输出包含字符“1”后面是一个“2”(在它们之间有任意数量的字符)的行
sed -n -e ‘/1[0-9]2/p’ inputfile # 仅输出包含字符“1”后面跟着“0”、“1”、或更多数字,最后面是一个“2”的行
如果你想在正则表达式(包括正则表达式分隔符)中去除字符的特殊意义,你可以在它前面使用一个反斜杠:
# 输出所有包含字符串“/usr/sbin/nologin”的行
sed -ne ‘/\/usr\/sbin\/nologin/p’ inputfile
并不限制你只能使用斜杠作为地址中正则表达式的分隔符。你可以通过在第一个分隔符前面加上反斜杠(\)的方式,来使用任何你认为适合你需要和偏好的其它字符作为正则表达式的分隔符。当你用地址与带文件路径的字符一起来匹配的时,是非常有用的:
# 以下两个命令是完全相同的
sed -ne ‘/\/usr\/sbin\/nologin/p’ inputfile
sed -ne ‘\=/usr/sbin/nologin=p’ inputfile
扩展的正则表达式
默认情况下,Sed 的正则表达式引擎仅理解 POSIX 基本正则表达式[11] 的语法。如果你需要用到 扩展正则表达式[12],你必须在 Sed 命令上添加 -E 标志。扩展正则表达式在基本正则表达式基础上增加了一组额外的特性,并且很多都是很重要的,它们所要求的反斜杠要少很多。我们来比较一下:
sed -n -e ‘/(www)|(mail)/p’ inputfile
sed -En -e ‘/(www)|(mail)/p’ inputfile
花括号量词
正则表达式之所以强大的一个原因是范围量词[13] {,}。事实上,当你写一个不太精确匹配的正则表达式时,量词 * 就是一个非常完美的符号。但是,(用花括号量词)你可以显式在它边上添加一个下限和上限,这样就有了很好的灵活性。当量词范围的下限省略时,下限被假定为 0。当上限被省略时,上限被假定为无限大:
< 如显示不全,请左右滑动 >
| 括号 | 速记词 | 解释 |
|---|---|---|
| {,} | * | 前面的规则出现 0、1、或许多遍 |
| {,1} | ? | 前面的规则出现 0 或 1 遍 |
| {1,} | + | 前面的规则出现 1 或许多遍 |
| {n,n} | {n} | 前面的规则精确地出现 n 遍 |
花括号在基本正则表达式中也是可以使用的,但是它要求使用反斜杠。根据 POSIX 规范,在基本正则表达式中可以使用的量词仅有星号(*)和花括号(使用反斜杠,如 {m,n})。许多正则表达式引擎都扩展支持 \? 和 +。但是,为什么魔鬼如此有诱惑力呢?因为,如果你需要这些量词,使用扩展正则表达式将不但易于写而且可移植性更好。
为什么我要花点时间去讨论关于正则表达式的花括号量词,这是因为在 Sed 脚本中经常用这个特性去计数字符。
sed -En -e ‘/^.{35}$/p’ inputfile # 输出精确包含 35 个字符的行
sed -En -e ‘/^.{0,35}$/p’ inputfile # 输出包含 35 个字符或更少字符的行
sed -En -e ‘/^.{,35}$/p’ inputfile # 输出包含 35 个字符或更少字符的行
sed -En -e ‘/^.{35,}$/p’ inputfile # 输出包含 35 个字符或更多字符的行
sed -En -e ‘/.{35}/p’ inputfile # 你自己指出它的输出内容(这是留给你的测试题)
地址范围
到目前为止,我们使用的所有地址都是唯一地址。在我们使用一个唯一地址时,命令是应用在与那个地址匹配的行上。但是,Sed 也支持地址范围。Sed 命令可以应用到那个地址范围中从开始到结束的所有地址中的所有行上:
sed -n -e ‘1,5p’ inputfile # 仅输出 1 到 5 行
sed -n -e ‘5,$p’ inputfile # 从第 5 行输出到文件结尾
sed -n -e ‘/www/,/systemd/p’ inputfile # 输出与正则表达式 /www/ 匹配的第一行到与接下来匹配正则表达式 /systemd/ 的行为止
(LCTT 译注:下面用的一个生成的列表例子,如下供参考:)
printf “%s\n” {a,b,c}{d,e,f} | cat -n
1 ad
2 ae
3 af
4 bd
5 be
6 bf
7 cd
8 ce
9 cf
如果在开始和结束地址上使用了同一个行号,那么范围就缩小为那个行。事实上,如果第二个地址的数字小于或等于地址范围中选定的第一个行的数字,那么仅有一个行被选定:
printf “%s\n” {a,b,c}{d,e,f} | cat -n | sed -ne ‘4,4p’
4 bd
printf “%s\n” {a,b,c}{d,e,f} | cat -n | sed -ne ‘4,3p’
4 bd
下面有点难了,但是在前面的段落中给出的规则也适用于起始地址是正则表达式的情况。在那种情况下,Sed 将对正则表达式匹配的第一个行的行号和给定的作为结束地址的显式的行号进行比较。再强调一次,如果结束行号小于或等于起始行号,那么这个范围将缩小为一行:
(LCTT 译注:此处作者陈述有误,Sed 会在处理以正则表达式表示的开始行时,并不会同时测试结束表达式:从匹配开始行的正则表达式开始,直到不匹配时,才会测试结束行的表达式——无论是否是正则表达式——并在结束的表达式测试不通过时停止,并循环此测试。)
# 这个 /b/,4 地址将匹配三个单行
# 因为每个匹配的行有一个行号 >= 4
_#(_LCTT 译注:结果正确,但是说明不正确。4、5、6 行都会因为匹配开始正则表达式而通过,第 7 行因为不匹配开始正则表达式,所以开始比较行数: 7 > 4,遂停止。)
printf “%s\n” {a,b,c}{d,e,f} | cat -n | sed -ne ‘/b/,4p’
4 bd
5 be
6 bf
# 你自己指出匹配的范围是多少
# 第二个例子:
printf “%s\n” {a,b,c}{d,e,f} | cat -n | sed -ne ‘/d/,4p’
1 ad
2 ae
3 af
4 bd
7 cd
但是,当结束地址是一个正则表达式时,Sed 的行为将不一样。在那种情况下,地址范围的第一行将不会与结束地址进行检查,因此地址范围将至少包含两行(当然,如果输入数据不足的情况除外):
(LCTT 译注:如上译注,当满足开始的正则表达式时,并不会测试结束的表达式;仅当不满足开始的表达式时,才会测试结束表达式。)
printf “%s\n” {a,b,c}{d,e,f} | cat -n | sed -ne ‘/b/,/d/p’
4 bd
5 be
6 bf
7 cd
printf “%s\n” {a,b,c}{d,e,f} | cat -n | sed -ne ‘4,/d/p’
4 bd
5 be
6 bf
7 cd
(LCTT 译注:对地址范围的总结,当满足开始的条件时,从该行开始,并不测试该行是否满足结束的条件;从下一行开始测试结束条件,并在结束条件不满足时结束;然后对剩余的行,再从开始条件开始匹配,以此循环——也就是说,匹配结果可以是非连续的单/多行。大家可以调整上述命令行的条件以理解。)
补集
在一个地址选择行后面添加一个感叹号(!)表示不匹配那个地址。例如:
sed -n -e ‘5!p’ inputfile # 输出除了第 5 行外的所有行
sed -n -e ‘5,10!p’ inputfile # 输出除了第 5 到 10 之间的所有行
sed -n -e ‘/sys/!p’ inputfile # 输出除了包含字符串“sys”的所有行
交集
(LCTT 译注:原文标题为“合集”,应为“交集”)
Sed 允许在一个块中使用花括号 {…} 组合命令。你可以利用这个特性去组合几个地址的交集。例如,我们来比较下面两个命令的输出:
sed -n -e ‘/usb/{
/daemon/p
}’ inputfile
sed -n -e ‘/usb.daemon/p’ inputfile
通过在一个块中嵌套命令,我们将在任意顺序中选择包含字符串 “usb” 和 “daemon” 的行。而正则表达式 “usb.daemon” 将仅匹配在字符串 “daemon” 前面包含 “usb” 字符串的行。
离题太长时间后,我们现在重新回去学习各种 Sed 命令。
退出命令
退出命令(q)是指在当前的迭代循环处理结束之后停止 Sed。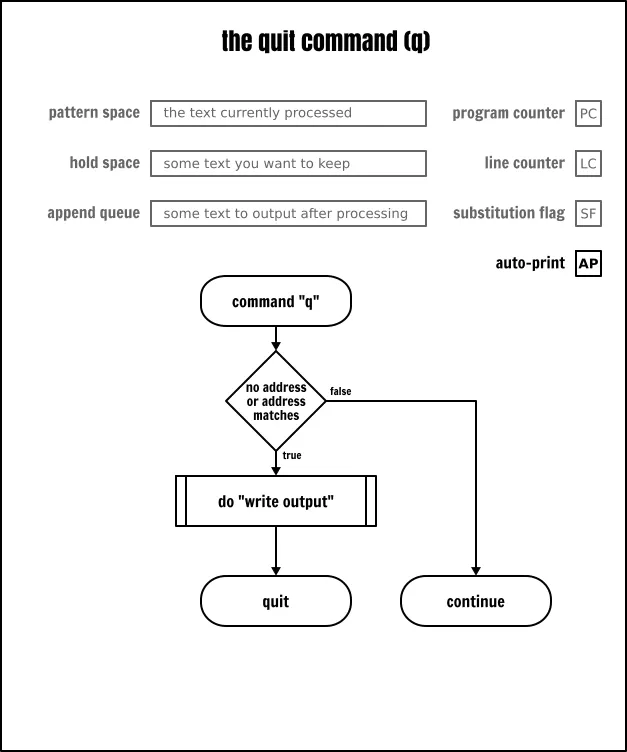
The Sed quit command
q 命令是在到达输入文件的尾部之前停止处理输入的方法。为什么会有人想去那样做呢?
很好的问题,如果你还记得,我们可以使用下面的命令来输出文件中第 1 到第 5 的行:
sed -n -e ‘1,5p’ inputfile
对于大多数 Sed 的实现方式,工具将循环读取输入文件的所有行,那怕是你只处理结果中的前 5 行。如果你的输入文件包含了几百万行(或者更糟糕的情况是,你从一个无限的数据流,比如像 /dev/urandom 中读取)将有重大影响。
使用退出命令,相同的程序可以被修改的更高效:
sed -e ‘5q’ inputfile
由于我在这里并不使用 -n 选项,Sed 将在每个循环结束后隐式输出模式空间的内容。但是在你处理完第 5 行后,它将退出,并且因此不会去读取更多的数据。
我们能够使用一个类似的技巧只输出文件中一个特定的行。这也是从命令行中提供多个 Sed 表达式的几种方法。下面的三个变体都可以从 Sed 中接受几个命令,要么是不同的 -e 选项,要么是在相同的表达式中新起一行,或用分号(;)隔开:
sed -n -e ‘5p’ -e ‘5q’ inputfile
sed -n -e ‘
5p
5q
‘ inputfile
sed -n -e ‘5p;5q’ inputfile
如果你还记得,我们在前面看到过能够使用花括号将命令组合起来,在这里我们使用它来防止相同的地址重复两次:
# 组合命令
sed -e ‘5{
p
q
}’ inputfile
# 可以简写为:
sed ‘5{p;q;}’ inputfile
# 作为 POSIX 扩展,有些实现方式可以省略闭花括号之前的分号:
sed ‘5{p;q}’ inputfile
替换命令
你可以将替换命令(s)想像为 Sed 的“查找替换”功能,这个功能在大多数的“所见即所得”的编辑器上都能找到。Sed 的替换命令与之类似,但比它们更强大。替换命令是 Sed 中最著名的命令之一,在网上有大量的关于这个命令的文档。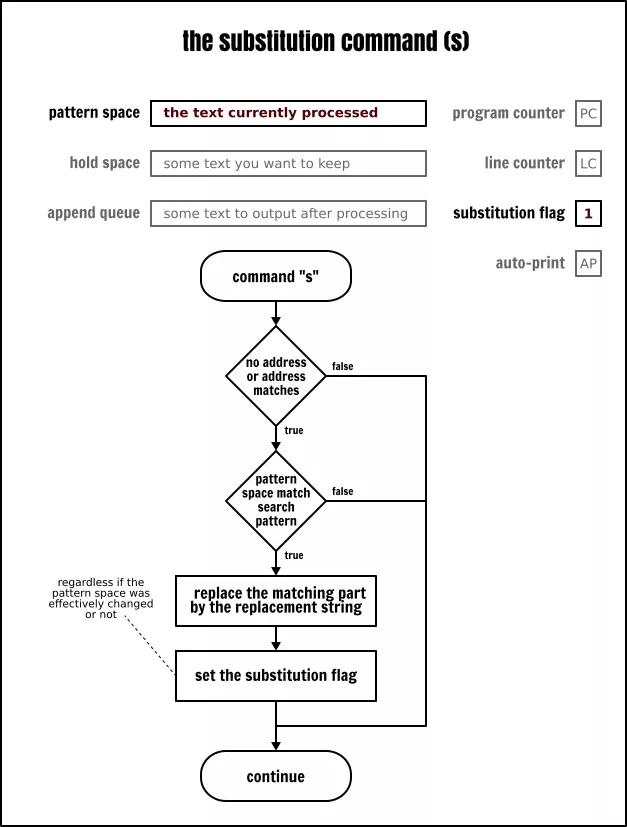
The Sed substitution command
在前一篇文章[14]中我们已经讲过它了,因此,在这里就不再重复了。但是,如果你对它的使用不是很熟悉,那么你需要记住下面的这些关键点:
◈ 替换命令有两个参数:查找模式和替换字符串:sed s/:/——-/ inputfile
◈ s 命令和它的参数是用任意一个字符来分隔的。这主要看你的习惯,在 99% 的时间中我都使用斜杠,但也会用其它的字符:sed s%:%——-% inputfile、sed sX:X——-X inputfile 或者甚至是 sed ‘s : ——- ‘ inputfile
◈ 默认情况下,替换命令仅被应用到模式空间中匹配到的第一个字符串上。你可以通过在命令之后指定一个匹配指数作为标志来改变这种情况:sed ‘s/:/——-/1’ inputfile、sed ‘s/:/——-/2’ inputfile、sed ‘s/:/——-/3’ inputfile、…
◈ 如果你想执行一个全局替换(即:在模式空间上的每个非重叠匹配上进行),你需要增加 g标志:sed ‘s/:/——-/g’ inputfile
◈ 在字符串替换中,出现的任何一个 & 符号都将被与查找模式匹配的子字符串替换:sed ‘s/:/-&&&-/g’ inputfile、sed ‘s/…/& /g’ inputfile
◈ 圆括号(在扩展的正则表达式中的 (…) ,或者基本的正则表达式中的 (…))被当做捕获组capturing group。那是匹配字符串的一部分,可以在替换字符串中被引用。\1 是第一个捕获组的内容,\2 是第二个捕获组的内容,依次类推:sed -E ‘s/(.)(.)/\2\1/g’ inputfile、sed -E ‘s/(.):x:(.):(.)/\1:\3/‘ inputfile(后者之所能正常工作是因为 正则表达式中的量词星号表示尽可能多的匹配,直到不匹配为止[15],并且它可以匹配许多个字符)
◈ 在查找模式或替换字符串时,你可以通过使用一个反斜杠来去除任何字符的特殊意义:sed ‘s/:/—\&—/g’ inputfile,sed ‘s/\//\/g’ inputfile
所有的这些看起来有点抽象,下面是一些示例。首先,我想去显示我的测试输入文件的第一个字段并给它在右侧附加 20 个空格字符,我可以这样写:
sed < inputfile -E -e ‘
s/:/ / # 用 20 个空格替换第一个字段的分隔符
s/(.{20})./\1/ # 只保留一行的前 20 个字符
s/.*/| & |/ # 为了输出好看添加竖条
‘
第二个示例是,如果我想将用户 sonia 的 UID/GID 修改为 1100,我可以这样写:
sed -En -e ‘
/sonia/{
s/[0-9]+/1100/g
p
}’ inputfile
注意在替换命令结束部分的 g 选项。这个选项改变了它的行为,因此它将查找全部的模式空间并替换,如果没有那个选项,它只替换查找到的第一个。
顺便说一下,这也是使用前面讲过的输出(p)命令的好机会,可以在命令运行时输出修改前后的模式空间的内容。因此,为了获得替换前后的内容,我可以这样写:
sed -En -e ‘
/sonia/{
p
s/[0-9]+/1100/g
p
}’ inputfile
事实上,替换后输出一个行是很常见的用法,因此,替换命令也接受 p 选项:
sed -En -e ‘/sonia/s/[0-9]+/1100/gp’ inputfile
最后,我就不详细讲替换命令的 w 选项了,我们将在稍后的学习中详细介绍。
删除命令
删除命令(d)用于清除模式空间的内容,然后立即开始下一个处理循环。这样它将会跳过隐式输出模式空间内容的行为,即便是你设置了自动输出标志(AP)也不会输出。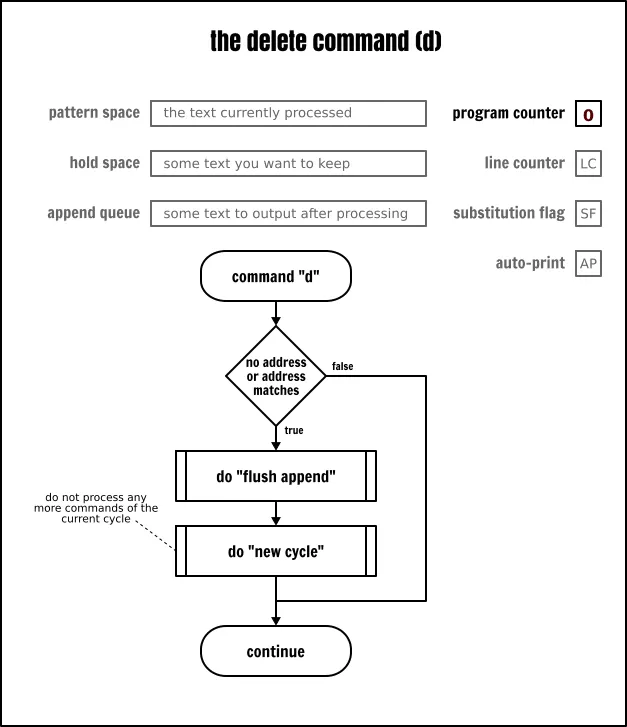
The Sed delete command
只输出一个文件前五行的一个很低效率的方法将是:
sed -e ‘6,$d’ inputfile
你猜猜看,我为什么说它很低效率?如果你猜不到,建议你再次去阅读前面的关于退出命令的章节,答案就在那里!
当你组合使用正则表达式和地址,从输出中删除匹配的行时,删除命令将非常有用:
sed -e ‘/systemd/d’ inputfile
次行命令
如果 Sed 命令没有运行在静默模式中,这个命令(n)将输出当前模式空间的内容,然后,在任何情况下它将读取下一个输入行到模式空间中,并使用新的模式空间中的内容来运行当前循环中剩余的命令。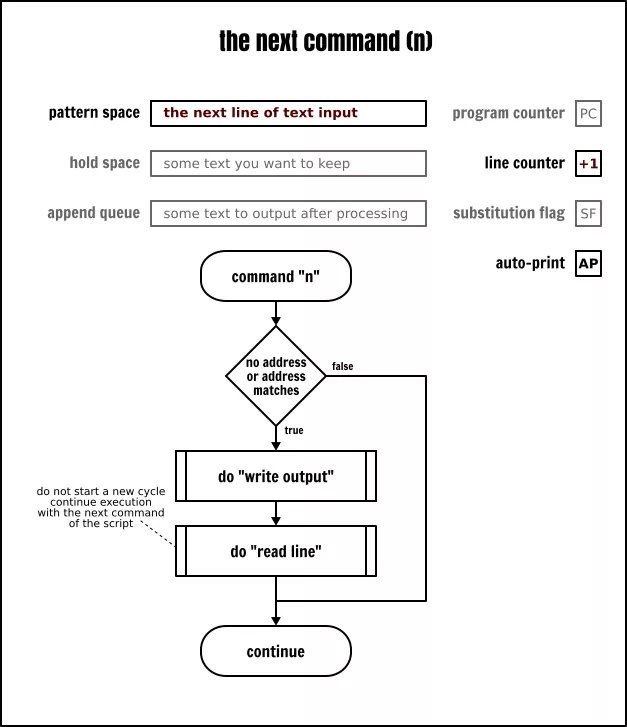
The Sed next command
用次行命令去跳过行的一个常见示例:
cat -n inputfile | sed -n -e ‘n;n;p’
在上面的例子中,Sed 将隐式地读取输入文件的第一行。但是次行命令将丢弃对模式空间中的内容的输出(不输出是因为使用了 -n 选项),并从输入文件中读取下一行来替换模式空间中的内容。而第二个次行命令做的事情和前一个是一模一样的,这就实现了跳过输入文件 2 行的目的。最后,这个脚本显式地输出包含在模式空间中的输入文件的第三行的内容。然后,Sed 将启动一个新的循环,由于次行命令,它会隐式地读取第 4 行的内容,然后跳过它,同样地也跳过第 5 行,并输出第 6 行。如此循环,直到文件结束。总体来看,这个脚本就是读取输入文件然后每三行输出一行。
使用次行命令,我们也可以找到一些显示输入文件的前五行的几种方法:
cat -n inputfile | sed -n -e ‘1{p;n;p;n;p;n;p;n;p}’
cat -n inputfile | sed -n -e ‘p;n;p;n;p;n;p;n;p;q’
cat -n inputfile | sed -e ‘n;n;n;n;q’
更有趣的是,如果你需要根据一些地址来处理行时,次行命令也非常有用:
cat -n inputfile | sed -n ‘/pulse/p’ # 输出包含 “pulse” 的行
cat -n inputfile | sed -n ‘/pulse/{n;p}’ # 输出包含 “pulse” 之后的行
cat -n inputfile | sed -n ‘/pulse/{n;n;p}’ # 输出包含 “pulse” 的行的下一行的下一行
使用保持空间
到目前为止,我们所看到的命令都是仅使用了模式空间。但是,我们在文章的开始部分已经提到过,还有第二个缓冲区:保持空间,它完全由用户管理。它就是我们在第二节中描述的目标。
交换命令
正如它的名字所表示的,交换命令(x)将交换保持空间和模式空间的内容。记住,你只要没有把任何东西放入到保持空间中,那么保持空间就是空的。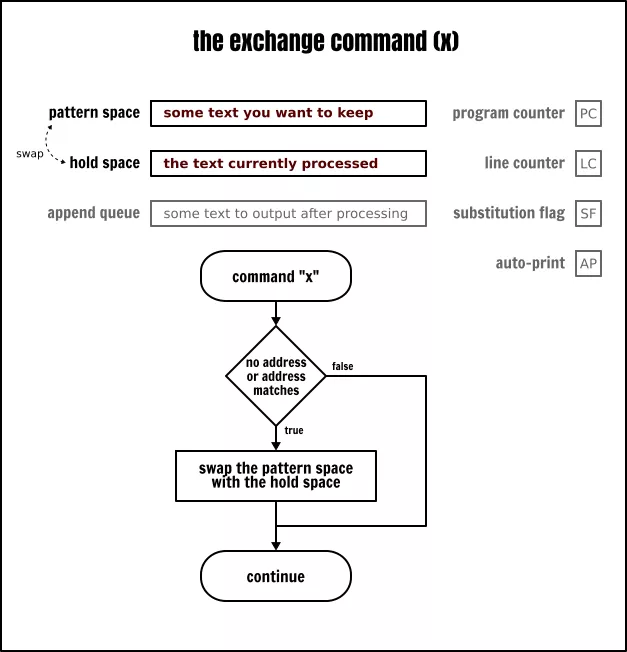
The Sed exchange command
作为第一个示例,我们可使用交换命令去反序输出一个输入文件的前两行:
cat -n inputfile | sed -n -e ‘x;n;p;x;p;q’
当然,在你设置保持空间之后你并没有立即使用它的内容,因为只要你没有显式地去修改它,保持空间中的内容就保持不变。在下面的例子中,我在输入一个文件的前五行后,使用它去删除第一行:
cat -n inputfile | sed -n -e ‘
1{x;n} # 交换保持和模式空间
# 保存第 1 行到保持空间中
# 然后读取第 2 行
5{
p # 输出第 5 行
x # 交换保持和模式空间
# 去取得第 1 行的内容放回到模式空间
}
1,5p # 输出第 2 到第 5 行
# (并没有输错!尝试找出这个规则
# 没有在第 1 行上运行的原因 ;)
‘
保持命令
保持命令(h)是用于将模式空间中的内容保存到保持空间中。但是,与交换命令不同的是,模式空间中的内容不会被改变。保持命令有两种用法:
◈ h 将复制模式空间中的内容到保持空间中,覆盖保持空间中任何已经存在的内容。
◈ H 将模式空间中的内容追加到保持空间中,使用一个新行作为分隔符。
The Sed hold command
上面使用交换命令的例子可以使用保持命令重写如下:
cat -n inputfile | sed -n -e ‘
1{h;n} # 保存第 1 行的内容到保持缓冲区并继续
5{ # 在第 5 行
x # 交换模式和保持空间
# (现在模式空间包含了第 1 行)
H # 在保持空间的第 5 行后追加第 1 行
x # 再次交换第 5 行和第 1 行,第 5 行回到模式空间
}
1,5p # 输出第 2 行到第 5 行
# (没有输错!尝试去找到为什么这个规则
# 不在第 1 行上运行 ;)
‘
获取命令
获取命令(g)与保持命令恰好相反:它从保持空间中取得内容并将它置入到模式空间中。同样它也有两种方式:
◈ g 将复制保持空间中的内容并将其放入到模式空间,覆盖模式空间中已存在的任何内容
◈ G 将保持空间中的内容追加到模式空间中,并使用一个新行作为分隔符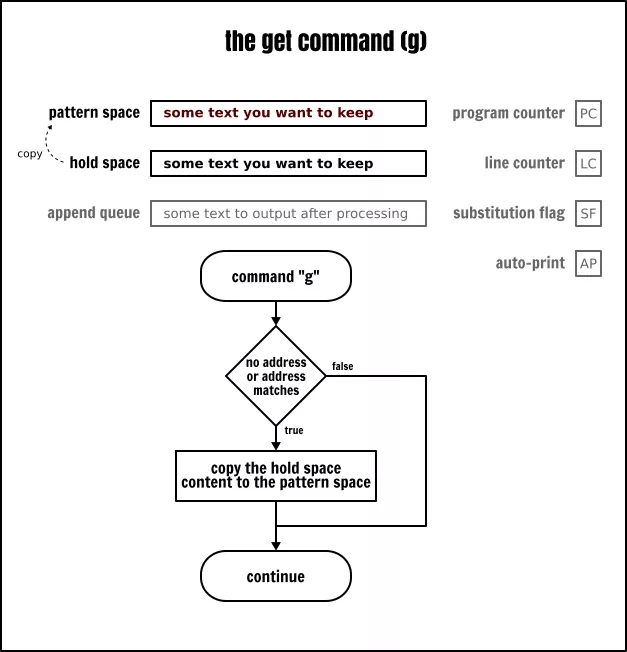
The Sed get command
将保持命令和获取命令一起使用,可以允许你去存储并调回数据。作为一个小挑战,我让你重写前一节中的示例,将输入文件的第 1 行放置在第 5 行之后,但是这次必须使用获取和保持命令(使用大写或小写命令的版本)而不能使用交换命令。带点小运气,可以更简单!
同时,我可以给你展示另一个示例,它能给你一些灵感。目标是将拥有登录 shell 权限的用户与其它用户分开:
cat -n inputfile | sed -En -e ‘
\=(/usr/sbin/nologin|/bin/false)$= { H;d; }
# 追回匹配的行到保持空间
# 然后继续下一个循环
p # 输出其它行
$ { g;p } # 在最后一行上
# 获取并打印保持空间中的内容
‘
复习打印、删除和次行命令
现在你已经更熟悉使用保持空间了,我们回到打印、删除和次行命令。我们已经讨论了小写的 p、d 和 n 命令了。而它们也有大写的版本。因为每个命令都有大小写版本,似乎是 Sed 的习惯,这些命令的大写版本将与多行缓冲区有关:
◈ P 将模式空间中第一个新行之前的内容输出
◈ D 删除模式空间中第一个新行之前的内容(包含新行),然后不读取任何新的输入而是使用剩余的文本去重启一个循环
◈ N 读取输入并追加一个新行到模式空间,用一个新行作为新旧数据的分隔符。继续运行当前的循环。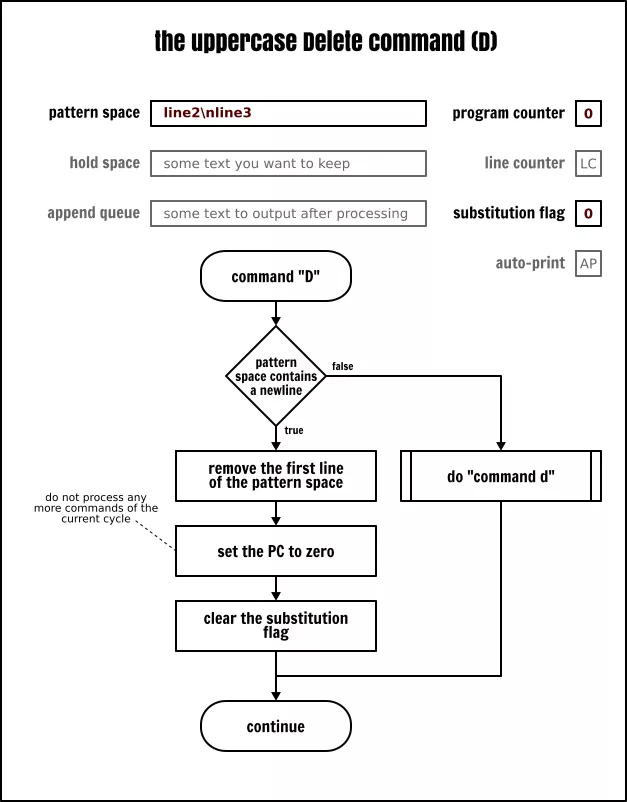
The Sed uppercase Delete command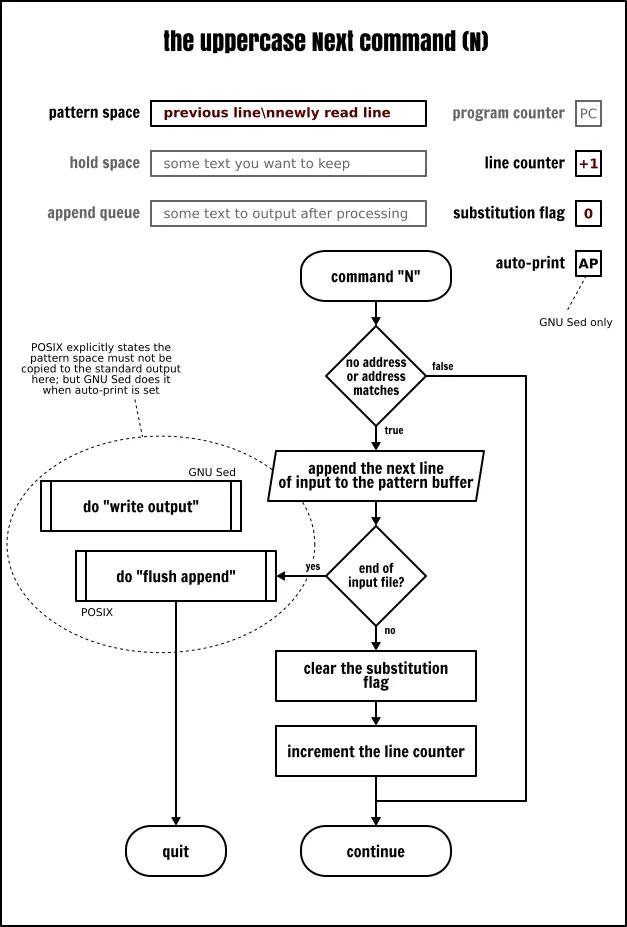
The Sed uppercase Next command
这些命令的使用场景主要用于实现队列(FIFO 列表[16])。从一个输入文件中删除最后 5 行就是一个很权威的例子:
cat -n inputfile | sed -En -e ‘
1 { N;N;N;N } # 确保模式空间中包含 5 行
N # 追加第 6 行到队列中
P # 输出队列的第 1 行
D # 删除队列的第 1 行
‘
作为第二个示例,我们可以在两个列上显示输入数据:
# 输出两列
sed < inputfile -En -e ‘
$!N # 追加一个新行到模式空间
# 除了输入文件的最后一行
# 当在输入文件的最后一行使用 N 命令时
# GNU Sed 和 POSIX Sed 的行为是有差异的
# 需要使用一个技巧去处理这种情况
# https://www.gnu.org/software/sed/manual/sed.html#N_005fcommand_005flast_005fline
# 用空间填充第 1 行的第 1 个字段<br /> # 并丢弃其余行<br /> s/:.*\n/ \n/<br /> s/:.*// # 除了第 2 行上的第 1 个字段外,丢弃其余的行<br /> s/(.{20}).*\n/\1/ # 修剪并连接行<br /> p # 输出结果<br />'<br />分支<br />我们刚才已经看到,Sed 因为有保持空间所以有了缓存的功能。其实它还有测试和分支的指令。因为有这些特性使得 Sed 是一个图灵完备[17]的语言。虽然它可能看起来很傻,但意味着你可以使用 Sed 写任何程序。你可以实现任何你的目的,但并不意味着实现起来会很容易,而且结果也不一定会很高效。<br />不过不用担心。在本文中,我们将使用能够展示测试和分支功能的最简单的例子。虽然这些功能乍一看似乎很有限,但请记住,有些人用 Sed 写了 http://www.catonmat.net/ftp/sed/dc.sed [计算器]、http://www.catonmat.net/ftp/sed/sedtris.sed [俄罗斯方块] 或许多其它类型的应用程序!<br />标签和分支<br />从某些方面,你可以将 Sed 看到是一个功能有限的汇编语言。因此,你不会找到在高级语言中常见的 “for” 或 “while” 循环,或者 “if … else” 语句,但是你可以使用分支来实现同样的功能。<br /><br />_The Sed branch command_<br />如果你在本文开始部分看到了用流程图描述的 Sed 运行模型,那么你应该知道 Sed 会自动增加程序计数器(PC)的值,命令是按程序的指令顺序来运行的。但是,使用分支(b)指令,你可以通过选择执行程序中的任意命令来改变顺序运行的程序。跳转目的地是使用一个标签(:)来显式定义的。<br />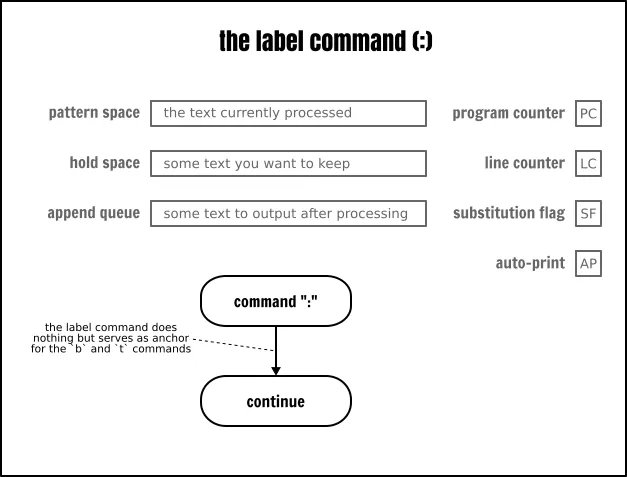<br />_The Sed label command_<br />这是一个这样的示例:<br />echo hello | sed -ne '<br /> :start # 在程序的该行上放置一个 “start” 标签<br /> p # 输出模式空间内容<br /> b start # 继续在 :start 标签上运行<br />' | less<br />那个 Sed 程序的行为非常类似于 yes 命令:它获取一个字符串并产生一个包含那个字符串的无限流。<br />切换到一个标签就像我们绕开了 Sed 的自动化特性一样:它既不读取任何输入,也不输出任何内容,更不更新任何缓冲区。它只是跳转到源程序指令顺序中下一条的另外一个指令。<br />值得一提的是,如果在分支命令(b)上没有指定一个标签作为它的参数,那么分支将直接切换到程序结束的地方。因此,Sed 将启动一个新的循环。这个特性可以用于去跳过一些指令并且因此可以用于作为“块”的替代者:<br />cat -n inputfile | sed -ne '<br />/usb/!b<br />/daemon/!b<br />p<br />'<br />条件分支<br />到目前为止,我们已经看到了无条件分支,这个术语可能有点误导嫌疑,因为 Sed 命令总是基于它们的可选地址来作为条件的。<br />但是,在传统意义上,一个无条件分支也是一个分支,当它运行时,将跳转到特定的目的地,而条件分支既有可能也或许不可能跳转到特定的指令,这取决于系统的当前状态。<br />Sed 只有一个条件指令,就是测试(t)命令。只有在当前循环的开始或因为前一个条件分支运行了替换,它才跳转到不同的指令。更多的情况是,只有替换标志被设置时,测试命令才会切换分支。<br />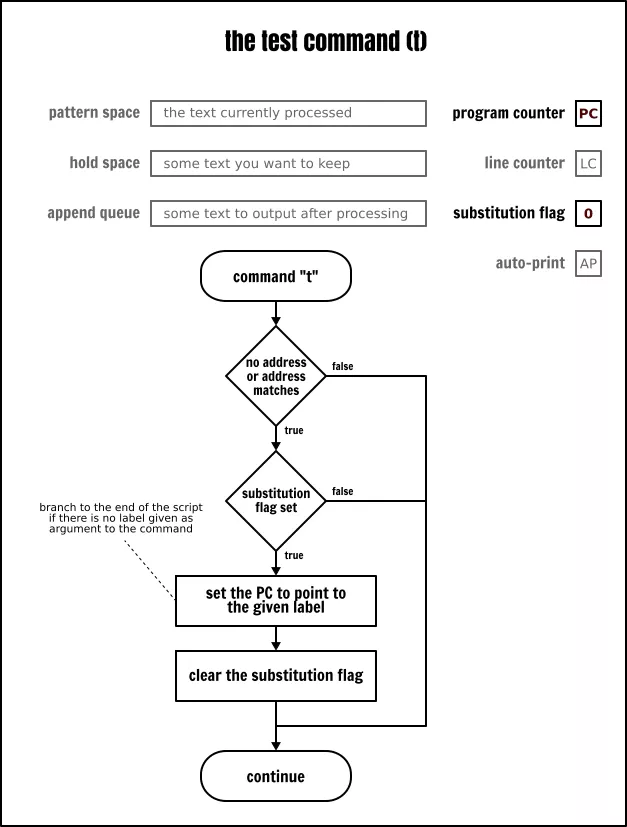<br />_The Sed `test` command_<br />使用测试指令,你可以在一个 Sed 程序中很轻松地执行一个循环。作为一个特定的示例,你可以用它将一个行填充到某个长度(这是使用正则表达式无法实现的):<br />_#_ 居中文本<br />cut -d: -f1 inputfile | sed -Ee '<br /> :start<br /> s/^(.{,19})$/ \1 / # 用一个空格填充少于 20 个字符的行的开始处<br /> # 并在结束处添加另一个空格<br /> t start # 如果我们已经添加了一个空格,则返回到 :start 标签<br /> s/(.{20}).*/| \1 |/ # 只保留一个行的前 20 个字符<br /> # 以修复由于奇数行引起的差一错误<br />'<br />如果你仔细读前面的示例,你可能注意到,在将要把数据“喂”给 Sed 之前,我通过 cut 命令做了一点小修正去预处理数据。<br />不过,我们也可以只使用 Sed 对程序做一些小修改来执行相同的任务:<br />cat inputfile | sed -Ee '<br /> s/:.*// # 除第 1 个字段外删除剩余字段<br /> t start<br /> :start<br /> s/^(.{,19})$/ \1 / # 用一个空格填充少于 20 个字符的行的开始处<br /> # 并在结束处添加另一个空格<br /> t start # 如果我们已经添加了一个空格,则返回到 :start 标签<br /> s/(.{20}).*/| \1 |/ # 仅保留一个行的前 20 个字符<br /> # 以修复由于奇数行引起的差一错误<br />'<br />在上面的示例中,你或许对下列的结构感到惊奇:<br />t start<br />:start<br />乍一看,在这里的分支并没有用,因为它只是跳转到将要运行的指令处。但是,如果你仔细阅读了测试命令的定义,你将会看到,如果在当前循环的开始或者前一个测试命令运行后发生了一个替换,分支才会起作用。换句话说就是,测试指令有清除替换标志的副作用。这也正是上面的代码片段的真实目的。这是一个在包含条件分支的 Sed 程序中经常看到的技巧,用于在使用多个替换命令时避免出现误报_false positive_的情况。<br />通过它并不能绝对强制地清除替换标志,我同意这一说法。因为在将字符串填充到正确的长度时我使用的特定的替换命令是幂等_idempotent_的。因此,一个多余的迭代并不会改变结果。不过,我们可以现在再次看一下第二个示例:<br />_#_ 基于它们的登录程序来分类用户帐户<br />cat inputfile | sed -Ene '<br /> s/^/login=/<br /> /nologin/s/^/type=SERV /<br /> /false/s/^/type=SERV /<br /> t print<br /> s/^/type=USER /<br /> :print<br /> s/:.*//p<br />'<br />我希望在这里根据用户默认配置的登录程序,为用户帐户打上 “SERV” 或 “USER” 的标签。如果你运行它,预计你将看到 “SERV” 标签。然而,并没有在输出中跟踪到 “USER” 标签。为什么呢?因为 t print 指令不论行的内容是什么,它总是切换,替换标志总是由程序的第一个替换命令来设置。一旦替换标志设置完成后,在下一个行被读取或直到下一个测试命令之前,这个标志将保持不变。下面我们给出修复这个程序的解决方案:<br />_#_ 基于用户登录程序来分类用户帐户<br />cat inputfile | sed -Ene '<br /> s/^/login=/
t classify # clear the “substitution flag”
:classify
/nologin/s/^/type=SERV /
/false/s/^/type=SERV /
t print
s/^/type=USER /
:print
s/:.//p
‘
精确地处理文本
Sed 是一个非交互式文本编辑器。虽然是非交互式的,但仍然是文本编辑器。而如果没有在输出中插入一些东西的功能,那它就不算一个完整的文本编辑器。我不是很喜欢它的文本编辑的特性,因为我发现它的语法太难用了(即便是以 Sed 的标准而言),但有时你难免会用到它。
采用严格的 POSIX 语法的只有三个命令:改变(c)、插入(i)或追加(a)一些文字文本到输出,都遵循相同的特定语法:命令字母后面跟着一个反斜杠,并且文本从脚本的下一行上开始插入:
head -5 inputfile | sed ‘
1i\
# List of user accounts
$a\
# end
‘
插入多行文本,你必须每一行结束的位置使用一个反斜杠:
head -5 inputfile | sed ‘
1i\
# List of user accounts\
# (users 1 through 5)
$a\
# end
‘
一些 Sed 实现,比如 GNU Sed,在初始的反斜杠后面的换行符是可选的,即便是在 —posix模式下仍然如此。我在标准中并没有找到任何关于该替代语法的说明(如果是因为我没有在标准中找到那个特性,请在评论区留言告诉我!)。因此,如果对可移植性要求很高,请注意使用它的风险:
# 非 POSIX 语法:
head -5 inputfile | sed -e ‘
1i# List of user accounts
$a# end
‘
也有一些 Sed 的实现,让初始的反斜杠完全是可选的。因此毫无疑问,它是一个厂商对 POSIX 标准进行扩展的特定版本,它是否支持那个语法,你需要去查看那个 Sed 版本的手册。
在简单概述之后,我们现在来回顾一下这些命令的更多细节,从我还没有介绍的改变命令开始。
改变命令
改变命令(c\)就像 d 命令一样删除模式空间的内容并开始一个新的循环。唯一的不同在于,当命令运行之后,用户提供的文本是写往输出的。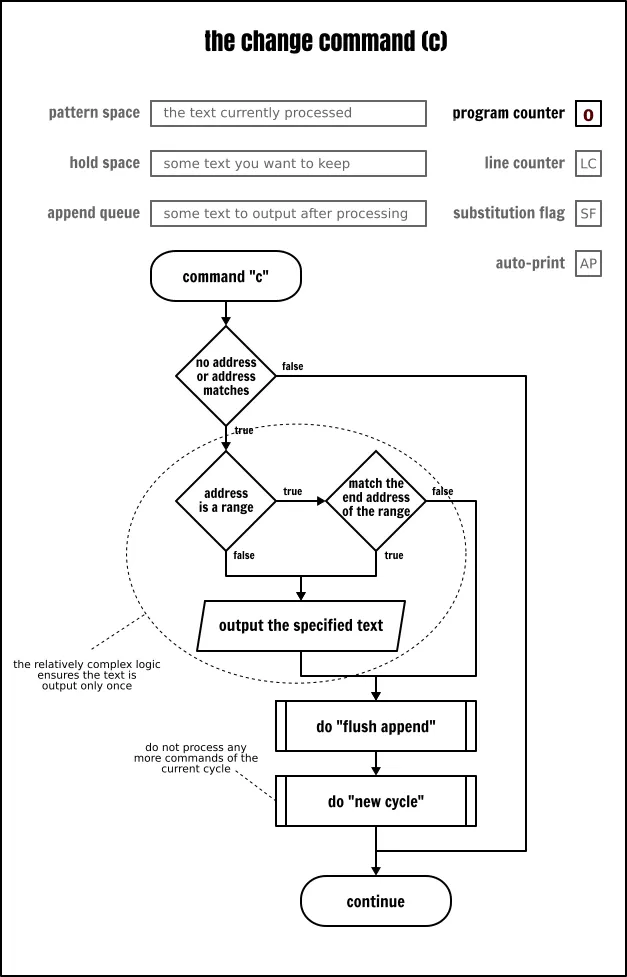
The Sed change command
cat -n inputfile | sed -e ‘
/systemd/c\
# :REMOVED:
s/:.// # This will NOT be applied to the “changed” text
‘
如果改变命令与一个地址范围关联,当到达范围的最后一行时,这个文本将仅输出一次。这在某种程度上成为 Sed 命令将被重复应用在地址范围内所有行这一惯例的一个例外情况:
cat -n inputfile | sed -e ‘
19,22c\
# :REMOVED:
s/:.// # This will NOT be applied to the “changed” text
‘
因此,如果你希望将改变命令重复应用到地址范围内的所有行上,除了将它封装到一个块中之外,你将没有其它的选择:
cat -n inputfile | sed -e ‘
19,22{c\
# :REMOVED:
}
s/:.// # This will NOT be applied to the “changed” text
‘
插入命令
插入命令(i\)将立即在输出中给出用户提供的文本。它并不以任何方式修改程序流或缓冲区的内容。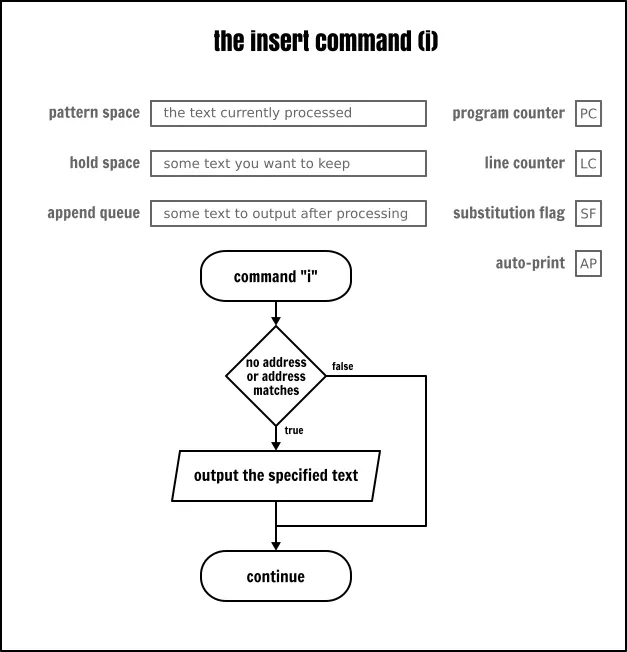
The Sed insert command
# display the first five user names with a title on the first row
sed < inputfile -e ‘
1i\
USER NAME
s/:.//
5q
‘
追加命令
当输入的下一行被读取时,追加命令(a\)将一些文本追加到显示队列。文本在当前循环的结束部分(包含程序结束的情况)或当使用 n 或 N 命令从输入中读取一个新行时被输出。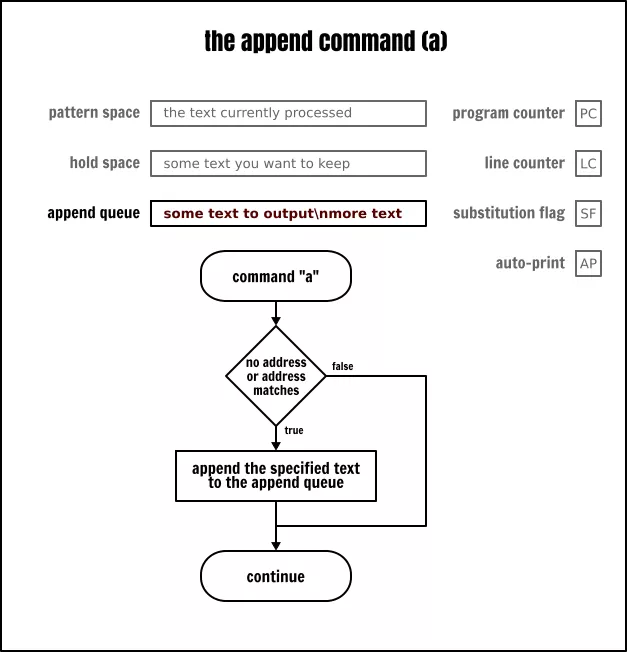
The Sed append command
与上面相同的一个示例,但这次是插入到底部而不是顶部:
sed < inputfile -e ‘
5a\
USER NAME
s/:.//
5q
‘
读取命令
这是插入一些文本内容到输出流的第四个命令:读取命令(r)。它的工作方式与追加命令完全一样,但不同的,它不从 Sed 脚本中取得硬编码到脚本中的文本,而是把一个文件的内容写入到一个输出上。
读取命令只调度要读取的文件。当清理追加队列时,后者才被高效地读取,而不是在读取命令运行时。如果这时候对这个文件有并发的访问读取,或那个文件不是一个普通的文件(比如,它是一个字符设备或命名管道),或文件在读取期间被修改,这时可能会产生严重的后果。
作为一个例证,如果你使用我们将在下一节详细讲述的写入命令,它与读取命令共同配合从一个临时文件中写入并重新读取,你可能会获得一些创造性的结果(使用法语版的 Shiritori[20] 游戏作为一个例证):
printf “%s\n” “Trois p’tits chats” “Chapeau d’ paille” “Paillasson” |
sed -ne ‘
r temp
a\
——
w temp
‘
现在,在流输出中专门用于插入一些文本的 Sed 命令清单结束了。我的最后一个示例纯属好玩,但是由于我前面提到过有一个写入命令,这个示例将我们完美地带到下一节,在下一节我们将看到在 Sed 中如何将数据写入到一个外部文件。
替代的输出
Sed 的设计思想是,所有的文本转换都将写入到进程的标准输出上。但是,Sed 也有一些特性支持将数据发送到替代的目的地。你有两种方式去实现上述的输出目标替换:使用专门的写入命令(w),或者在一个替换命令(s)上添加一个写入标志。
写入命令
写入命令(w)会追加模式空间的内容到给定的目标文件中。POSIX 要求在 Sed 处理任何数据之前,目标文件能够被 Sed 所创建。如果给定的目标文件已经存在,它将被覆写。
The Sed write command
因此,即便是你从未真的写入到该文件中,但该文件仍然会被创建。例如,下列的 Sed 程序将创建/覆写这个 output 文件,那怕是这个写入命令从未被运行过:
echo | sed -ne ‘
q # 立刻退出
w output # 这个命令从未被运行
‘
你可以将几个写入命令指向到同一个目标文件。指向同一个目标文件的所有写入命令将追加那个文件的内容(工作方式几乎与 shell 的重定向符 >> 相同):
sed < inputfile -ne ‘
/:\/bin\/false$/w server
/:\/usr\/sbin\/nologin$/w server
w output
‘
cat server
替换命令的写入标志
在前面,我们已经学习了替换命令(s),它有一个 p 选项用于在替换之后输出模式空间的内容。同样它也提供一个类似功能的 w 选项,用于在替换之后将模式空间的内容输出到一个文件中:
sed < inputfile -ne ‘
s/:.\/nologin$//w server
s/:.\/false$//w server
‘
cat server
注释
我无数次使用过它们,但我从未花时间正式介绍过它们,因此,我决定现在来正式地介绍它们:就像大多数编程语言一样,注释是添加软件不去解析的自由格式文本的一种方法。Sed 的语法很晦涩,我不得不强调在脚本中需要的地方添加足够的注释。否则,除了作者外其他人将几乎无法理解它。
The Sed comment command
不过,和 Sed 的其它部分一样,注释也有它自己的微妙之处。首先并且是最重要的,注释并不是语法结构,但它是真正意义的 Sed 命令。注释虽然是一个“什么也不做”的命令,但它仍然是一个命令。至少,它是在 POSIX 中定义了的。因此,严格地说,它们只允许使用在其它命令允许使用的地方。
大多数 Sed 实现都通过允许行内命令来放松了那种要求,就像在那个文章中我到处都使用的那样。
结束那个主题之前,需要说一下 #n 注释(# 后面紧跟一个字母 n,中间没有空格)的特殊情况。如果在脚本的第一行找到这个精确注释,Sed 将切换到静默模式(即:清除自动输出标志),就像在命令行上指定了 -n 选项一样。
很少用得到的命令
现在,我们已经学习的命令能让你写出你所用到的 99.99% 的脚本。但是,如果我没有提到剩余的 Sed 命令,那么本教程就不能称为完全指南。我把它们留到最后是因为我们很少用到它。但或许你有实际使用案例,那么你就会发现它们很有用。如果是那样,请不要犹豫,在下面的评论区中把它分享给我们吧。
行数命令
这个 = 命令将向标准输出上显示当前 Sed 正在读取的行数,这个行数就是行计数器(LC)的内容。没有任何方式从任何一个 Sed 缓冲区中捕获那个数字,也不能对它进行输出格式化。由于这两个限制使得这个命令的可用性大大降低。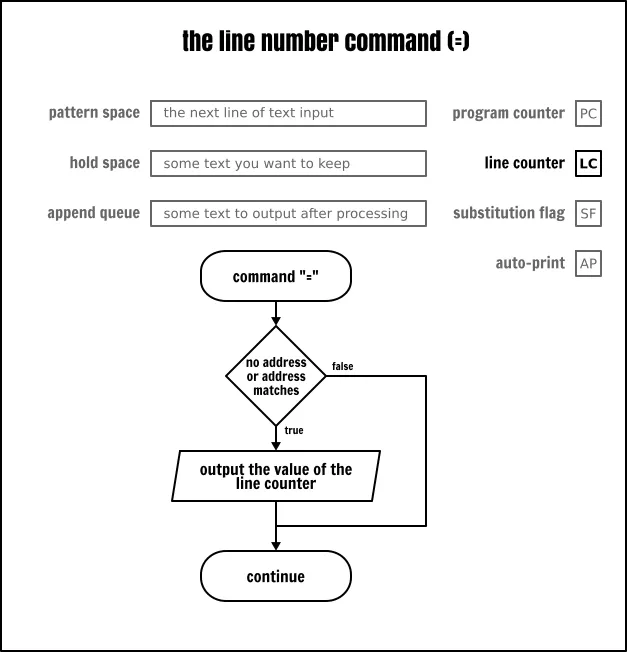
The Sed line number command
请记住,在严格的 POSIX 兼容模式中,当在命令行上给定几个输入文件时,Sed 并不重置那个计数器,而是连续地增长它,就像所有的输入文件是连接在一起的一样。一些 Sed 实现,像 GNU Sed,它就有一个选项可以在每个输入文件读取结束后去重置计数器。
明确打印命令
这个 l(小写的字母 l)作用类似于打印命令(p),但它是以精确的格式去输出模式空间的内容。以下引用自 POSIX 标准[8]:
在 XBD 转义序列中列出的字符和相关的动作(\、\a、\b、\f、\r、\t、\v)将被写为相应的转义序列;在那个表中的 \n 是不适用的。不在那个表中的不可打印字符将被写为一个三位八进制数字(在前面使用一个反斜杠 \),表示字符中的每个字节(最重要的字节在前面)。长行应该被换行,通过写一个反斜杠后跟一个换行符来表示换行位置;发生换行时的长度是不确定的,但应该适合输出设备的具体情况。每个行应该以一个 $标记结束。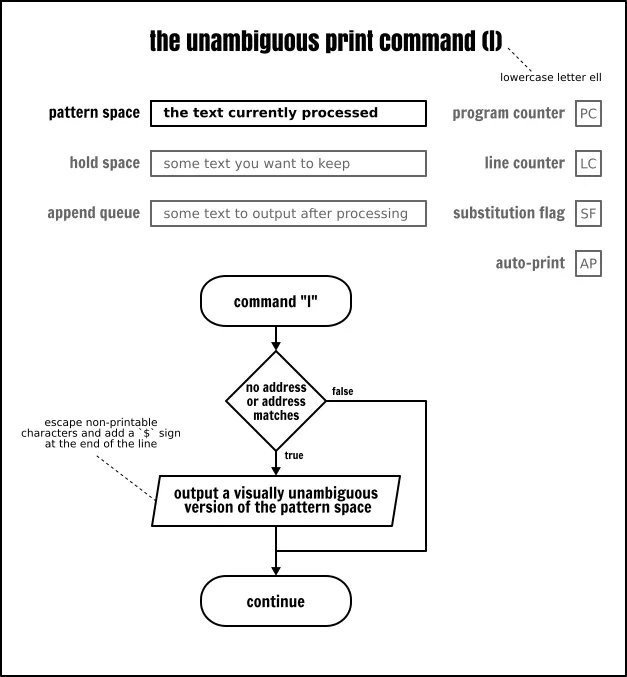
The Sed unambiguous print command
我怀疑这个命令是在非 8 位规则化信道[21] 上交换数据的。就我本人而言,除了调试用途以外,也从未使用过它。
移译命令
移译transliterate(y)命令允许从一个源集到一个目标集映射模式空间的字符。它非常类似于 tr命令,但是限制更多。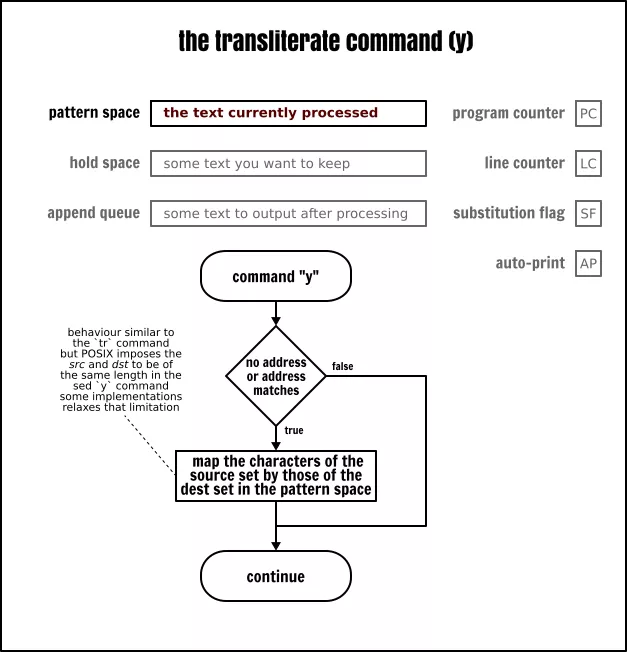
The Sed transliterate command
# The y c0mm4nd 1s for h4x0rz only
sed < inputfile -e ‘
s/:.//
y/abcegio/48<3610/
‘
虽然移译命令语法与替换命令的语法有一些相似之处,但它在替换字符串之后不接受任何选项。这个移译总是全局的。
请注意,移译命令要求源集和目标集之间要一一对应地转换。这意味着下面的 Sed 程序可能所做的事情并不是你乍一看所想的那样:
# 注意:这可能并不如你想的那样工作!
sed < inputfile -e ‘
s/:.//
y/[a-z]/[A-Z]/
‘
写在最后的话
# 它要做什么?
# 提示:答案就在不远处…
sed -E ‘
s/.\W(.)/\1/
h
${ x; p; }
d’ < inputfile
我们已经学习了所有的 Sed 命令,真不敢相信我们已经做到了!如果你也读到这里了,应该恭喜你,尤其是如果你花费了一些时间,在你的系统上尝试了所有的不同示例!
正如你所见,Sed 是非常复杂的,不仅因为它的语法比较零乱,也因为许多极端案例或命令行为之间的细微差别。毫无疑问,我们可以将这些归结于历史的原因。尽管它有这么多缺点,但是 Sed 仍然是一个非常强大的工具,甚至到现在,它仍然是 Unix 工具箱中为数不多的大量使用的命令之一。是时候总结一下这篇文章了,没有你们的支持我将无法做到:请节选你对喜欢的或最具创意的 Sed 脚本,并共享给我们。如果我收集到的你们共享出的脚本足够多了,我将会把这些 Sed 脚本结集发布!

若有收获,就点个赞吧
0 人点赞
