一 回溯法、递归
79.单词搜索
842.将数组拆分成斐波那契序列
**306.累加数** 剑指Offer34:二叉树的路径和
回溯法的经典模板:
private void backtrack("原始参数") {//终止条件(递归必须要有终止条件)if ("终止条件") {//一些逻辑操作(可有可无,视情况而定)return;}for (int i = "for循环开始的参数"; i < "for循环结束的参数"; i++) {//一些逻辑操作(可有可无,视情况而定)//做出选择//递归backtrack("新的参数");//一些逻辑操作(可有可无,视情况而定)//撤销选择}}
二 一些重要的方法
1 compare & compareTo
注意要想自定义排序规则,就不能使用基本数据类型int,double ,char
//数组排序String[] str = new String[5];Arrays.sort(str, new Comparator<String>() {@Overridepublic int compare(String o1, String o2) {// TODO Auto-generated method stubreturn 0;}});//List集合排序ArrayList<String> list = new ArrayList<String>();Collections.sort(list, new Comparator<String>() {@Overridepublic int compare(String o1, String o2) {// TODO Auto-generated method stubreturn 0;}});
String[] str = new String[5];Arrays.sort(str, new Comparator<String>() {@Overridepublic int compare(String o1, String o2) {// TODO Auto-generated method stubreturn o1.compareTo(o2);}});
2 字符串的一些操作
string.substring()str.startwith()str.charAt()str.toCharArray()str.equals()## 字符串列表转字符串List<String> arr = new ArrayList<>();String ret = String.join("", arr);
3 埃氏筛
4 位运算
与运算(&)
**n & 1 = 0:** 表示数字最末尾的二进制数为0
移位运算
**n >>> 1:**表示n的二进制数 无符号右移 1位,当n为负数时,最高位表示正负的1不会扩展,右移后,用0补充**n >> 1:**表示n的二进制数带符号右移1为,当n为负数时,最高位表示正负的1会扩展,右移后,用1补充,相当于除以2
异或操作:相同为0,不同为1
res ^= s.charAt(i)
使用异或运算,将所有值进行异或
异或运算,相异为真,相同为假,所以 a^a = 0 ;0^a = a
因为异或运算 满足交换律 a^b^a = a^a^b = b 所以数组经过异或运算,单独的值就剩下了
5 最长递增子序列
- 俄罗斯套娃
6 二维数组排序
Arrays.sort(people, new Comparator<int[]>() {@Overridepublic int compare(int[] o1, int[] o2) {if(o1[0] == o2[0]) return o2[1] - o1[1];return o2[0] - o1[0];}})
7 数组列表转二维数组
List<int[]> arr = new ArrayList<>();int[][] ret = arr.toArray(new int[arr.size()][2]);
三 丑数
四 链表的操作
每一个都是一个节点
基础:206(翻转链表)
试着用双指针做做:剑指offer22
147 对于链表的插入排序 :引入哑节点的作用,方便在头节点插入数据148 排序链表 328 奇偶链表
先从最简单的合并链表开始
// 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。class Solution {public ListNode mergeTwoLists(ListNode l1, ListNode l2) {ListNode head = new ListNode(0);ListNode node = head;while(l1 != null && l2 != null) {if(l1.val > l2.val) {node.next = l2;node = node.next;l2 = l2.next;} else {node.next = l1;node = node.next;l1 = l1.next;}}if(l1 != null) node.next = l1;if(l2 != null) node.next = l2;return head.next;}}
七 Map
拼多多:454:四数相加
map的基本操作:
Map<Integer, Integer> map = new HashMap<>();map.put(key, value);map.containsKey(Key) //返回的是boolean -->map.get(Key) // return Valuemap.merge(Key, Value, BiFunction<? super V,? super V,? extends V> remappingFunction) // 新功能!!!
1 Map的遍历
Java中Map遍历的四种方式
- 使用for循环加上Entry ```java /**
- 最常见也是大多数情况下用的最多的,一般在键值对都需要使用
*/
Map
在for循环中遍历Key使用keySet和values集合,在性能上比使用entrySet较好
Map <String,String>map = new HashMap<String,String>();map.put("熊大", "棕色");map.put("熊二", "黄色");//keyfor(String key : map.keySet()){System.out.println(key);}//valuefor(String value : map.values()){System.out.println(value);}
通过使用Iterator遍历
Iterator<Entry<String, String>> entries = map.entrySet().iterator();while(entries.hasNext()){Entry<String, String> entry = entries.next();String key = entry.getKey();String value = entry.getValue();System.out.println(key+":"+value);}
通过键找值遍历,效率较低
for(String key : map.keySet()){String value = map.get(key);System.out.println(key+":"+value);}
八 位运算(&、|、<<、>>、^(异或)、>>>)
剑指Offer65:不用加减乘除做加法
^:异或运算符,两数的对应位置不同才是1,否则是0
405:数字转换为十六进制数:StringBuffer
是无符号右移运算符,在后面补零
例:4>>>1 = 2LC:191 位运算法优化n中1的个数
**n&(n - 1)** 结果是把n的二进制位总最低位的1变成0之后的结果**6&(6 - 1) = 4, 6 = (110), 4 = (100)** ,不断的进行 **n&(n - 1)** 操作,当值变为0时操作的次数,即为二进制n中1的个数。
九 栈
单调栈:739:每日温度、456:132模式
单调栈维护的都是临时状态,随时可能会被更新
十 树
110. 平衡二叉树
1530. 好叶子节点对的数量
之后再做做吧
十一 Set
特性:不可以添加重复元素
api如下:
add()addAll()clear()contains(Object o)containsAllequals()hashCode()isEmpty()remove()removeAll()retainAll()toArray()size()
1 HashSet(哈希表)
普通的List集合转为HashSet
Set<String> wordSet = new HashSet<>(wordList); // 直接将内容转为HashSet存储,加快查询的速度??
2 TreeSet
treeSet.ceiling可以用来维护滑动窗口
public E ceiling(E e) {return m.ceilingKey(e);}/*** Returns the least key greater than or equal to the given key,* or {@code null} if there is no such key.** @param key the key* @return the least key greater than or equal to {@code key},* or {@code null} if there is no such key* @throws ClassCastException if the specified key cannot be compared* with the keys currently in the map* @throws NullPointerException if the specified key is null* and this map does not permit null keys*/K ceilingKey(K key);
treeSet.ceiling(key)用来返回窗口中大于等于给定键值的值,没有的话返回null
十二 java8的Stream流操作
Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。 Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。 Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。 这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如 筛选 (filter), 排序 (sorted), 映射 (map) 聚合 (collect)等。 元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。
如:
List<Integer> transactionsIds =widgets.stream().filter(b -> b.getColor() == RED) // 过滤.sorted((x,y) -> x.getWeight() - y.getWeight()) // 排序.mapToInt(Widget::getWeight) // 映射(变换数据).sum(); // 聚合// 列表转换为int数组也可以使用流操作转换List<Integer> arr = new ArrayList<>();return arr.stream().mapToInt(i -> i).toArray();// Int、Integer数组转换为ListInteger [] myArray = { 1, 2, 3 };List myList = Arrays.stream(myArray).collect(Collectors.toList());//基本类型也可以实现转换(依赖boxed的装箱操作)int [] myArray2 = { 1, 2, 3 };List myList = Arrays.stream(myArray2).boxed().collect(Collectors.toList());// 再补充两个int max = Arrays.stream(myArray2).max().getAsInt();int sum = Arrays.stream(myArray2).sum();
1 一个旧的集合变成一个新的集合
spu.stream().map(spu -> {}).collect(Collectors.toList());
十三 队列
队列是一种特殊的线性表,它只允许在表的前端进行删除操作,而在表的后端进行插入操作。 LinkedList类实现了Queue接口,因此我们可以把LinkedList当成Queue来用。
import java.util.LinkedList;import java.util.Queue;public class Main {public static void main(String[] args) {//add()和remove()方法在失败的时候会抛出异常(不推荐)Queue<String> queue = new LinkedList<String>();//添加元素queue.offer("a");queue.offer("b");queue.offer("c");queue.offer("d");queue.offer("e");for(String q : queue){System.out.println(q);}System.out.println("===");System.out.println("poll="+queue.poll()); //返回第一个元素,并在队列中删除for(String q : queue){System.out.println(q);}System.out.println("===");System.out.println("element="+queue.element()); //返回第一个元素for(String q : queue){System.out.println(q);}System.out.println("===");System.out.println("peek="+queue.peek()); //返回第一个元素for(String q : queue){System.out.println(q);}}}
1 优先队列
23.合并K个升序链表
// 使用优先队列求解PriorityQueue<ListNode> queue = new PriorityQueue<>((x1, y1) -> x1.val - y1.val);ListNode pre = new ListNode(0);ListNode tail = pre;for(ListNode list : lists) {if(list != null)queue.offer(list);}while(!queue.isEmpty()) {ListNode curr = queue.poll();tail.next = curr;tail = tail.next;if(curr.next != null) {queue.offer(curr.next);}}return pre.next;
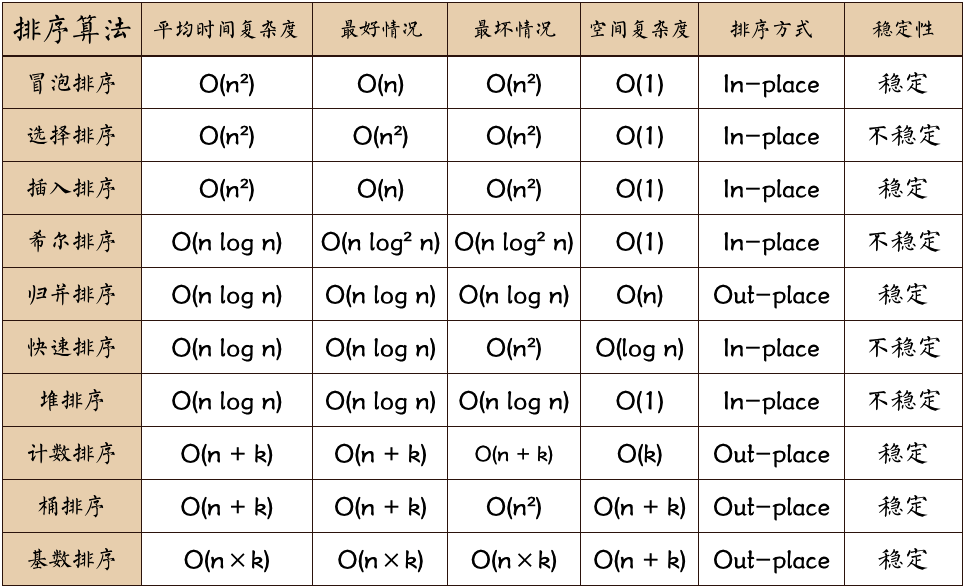
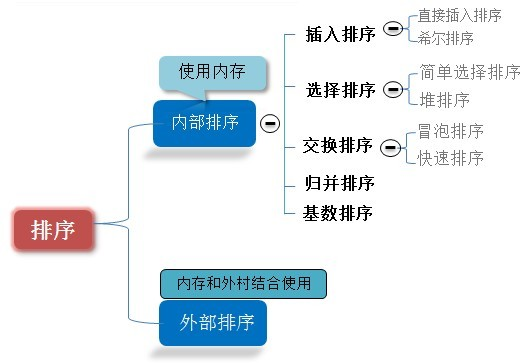
十五 Sort
以下参考自排序总结
Arrays.sort(arr, new Comparator<>() {@Overridepublic int compare(int a, int b) {return a - b; // 升序排列}})
插入排序的时间复杂度是 O(n^2)O(_n_2) 时间复杂度是 O(nlog n) 的排序算法包括归并排序、堆排序和快速排序(快速排序的最差时间复杂度是 O(n^2),其中最适合链表的排序算法是归并排序,
因为归并排序是稳定的
1 快速排序
时间复杂度:O(NlogN) 快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
哨兵: 选定每一个二分的起始节点作为判定点,j先从右往左找小于的值,i再从左往右找大于的值,将两者交换,依次进行下去,直到i >= j停止,将哨兵放在中间,迭代上述过程,直到数组长度等于1
2 希尔排序
希尔排序是把记录按下表的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
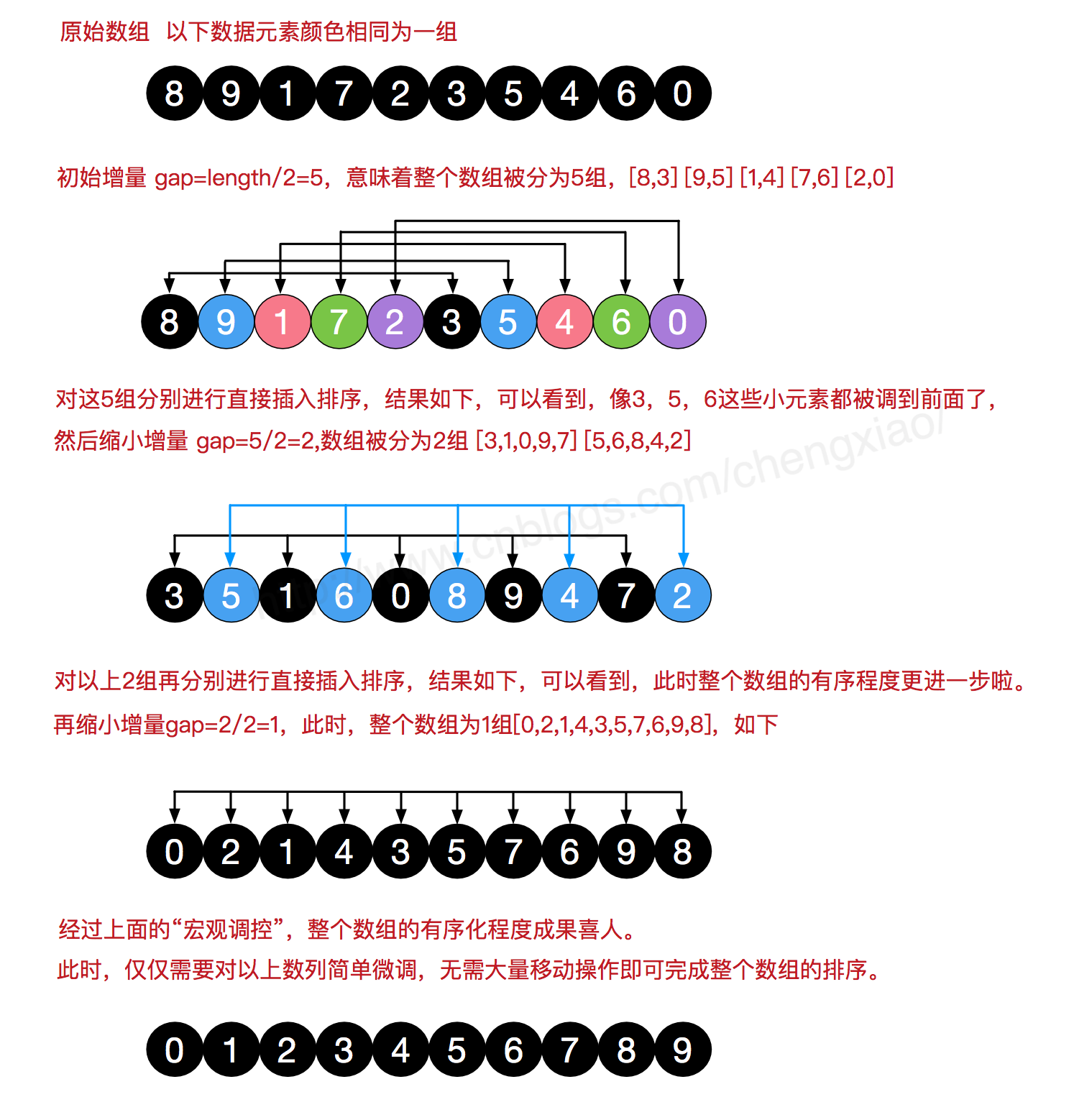
/*** 希尔排序** @param array* @return*/public static int[] ShellSort(int[] array) {int len = array.length;int temp, gap = len / 2;while (gap > 0) {for (int i = gap; i < len; i++) {temp = array[i];int preIndex = i - gap;while (preIndex >= 0 && array[preIndex] > temp) {array[preIndex + gap] = array[preIndex];preIndex -= gap;}array[preIndex + gap] = temp;}gap /= 2;}return array;}
3 归并排序
时间复杂度:O(NlogN)
归并排序基于分治算法。最容易想到的实现方式是自顶向下的递归实现,考虑到递归调用的栈空间,自顶向下归并排序的空间复杂度是 O(logn)。如果要达到O(1) 的空间复杂度,则需要使用自底向上的实现方式
分而治之:
- 找到数组、链表(使用快慢指针)的中间值,不断二分迭代,再进行比较
代码实现
/*** 二路-归并排序** @param array* @return*/public static int[] MergeSort(int[] array) {if (array.length < 2) return array;int mid = array.length / 2;int[] left = Arrays.copyOfRange(array, 0, mid);int[] right = Arrays.copyOfRange(array, mid, array.length);return merge(MergeSort(left), MergeSort(right));}/*** 归并排序——将两段排序好的数组结合成一个排序数组** @param left* @param right* @return*/public static int[] merge(int[] left, int[] right) {int[] result = new int[left.length + right.length];for (int index = 0, i = 0, j = 0; index < result.length; index++) {if (i >= left.length)result[index] = right[j++];else if (j >= right.length)result[index] = left[i++];else if (left[i] > right[j])result[index] = right[j++];elseresult[index] = left[i++];}return result;}
以链表的归并排序为例:
ListNode head;public ListNode sortList(ListNode head, ListNode tail) {// 定义边界情况if(head == null) return head;if(head.next == tail) {head.next = null;return head;}// 定义快慢指针ListNode fast = head, low = head;// 使用快慢指针查找链表中值while(fast.next != null && fast != null) {fast = fast.next;low = low.next;while(fast != null) {fast = fast.next;}}ListNode list1 = sortList(head, low);ListNode list2 = sortList(low, tail);ListNode res = merge(list1, list2);return res;}public ListNode merge(...) {...}
4 堆排序
堆排序(Heap Sort)是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
** 大顶堆原理:**根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最大者,称为大顶堆。大顶堆要求根节点的关键字既大于或等于左子树的关键字值,又大于或等于右子树的关键字值。<br /> **小顶堆原理:**根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最小者,称为小顶堆。小堆堆要求根节点的关键字既小于或等于左子树的关键字值,又小于或等于右子树的关键字值。
堆排序的基本思路
- 将无需序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆;
- 将堆顶元素与末尾元素交换,将最大元素”沉”到数组末端;
- 重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。 ```java
import java.util.Arrays; /**
@author Administrator / public class HeapSort { public static void main(String []args){
int []arr = {7,6,7,11,5,12,3,0,1};System.out.println("排序前:"+Arrays.toString(arr));sort(arr);System.out.println("排序前:"+Arrays.toString(arr));
}
public static void sort(int []arr){
//1.构建大顶堆for(int i=arr.length/2-1;i>=0;i--){//从第一个非叶子结点从下至上,从右至左调整结构adjustHeap(arr,i,arr.length);}//2.调整堆结构+交换堆顶元素与末尾元素for(int j=arr.length-1;j>0;j--){swap(arr,0,j);//将堆顶元素与末尾元素进行交换adjustHeap(arr,0,j);//重新对堆进行调整}
}
/**
- 调整大顶堆(仅是调整过程,建立在大顶堆已构建的基础上)
- @param arr
- @param i
@param length / public static void adjustHeap(int []arr,int i,int length){ int temp = arr[i];//先取出当前元素i for(int k=i2+1;k<length;k=k*2+1){//从i结点的左子结点开始,也就是2i+1处开始
if(k+1<length && arr[k]<arr[k+1]){//如果左子结点小于右子结点,k指向右子结点k++;}if(arr[k] >temp){//如果子节点大于父节点,将子节点值赋给父节点(不用进行交换)arr[i] = arr[k];i = k;}else{break;}
} arr[i] = temp;//将temp值放到最终的位置 }
/**
- 交换元素
- @param arr
- @param a
- @param b */ public static void swap(int []arr,int a ,int b){ int temp=arr[a]; arr[a] = arr[b]; arr[b] = temp; } } ```
5 桶排序
时间复杂度:O(N),
**164: 最大间距**
桶的间距:ids = Math.max((max - min) / (length - 1) )
桶的数量:num = (max - min) / ids + 1
十六 String
String、StringBuffer、StringBuilder的关系
| String | StringBuffer | StringBuilder |
|---|---|---|
| String的值是不可变的,这就导致每次对String的操作都会生成新的String对象,不仅效率低下,而且浪费大量优先的内存空间 | StringBuffer是可变类,和线程安全的字符串操作类,任何对它指向的字符串的操作都不会产生新的对象。每个StringBuffer对象都有一定的缓冲区容量,当字符串大小没有超过容量时,不会分配新的容量,当字符串大小超过容量时,会自动增加容量 | 可变类,速度更快 |
| 不可变 | 可变 | 可变 |
| 线程安全 (有synchronized) | 线程不安全(无synchronized) | |
| 多线程操作字符串 | 单线程操作字符串 |
StringBuffer的赋值:通过构造函数赋值
两份代码:
StringBuffer stb1 = new StringBuffer();int i = 0, n = s.length(); //s = "abc"while(i < n) {if(Character.isLetterOrDigit(s.charAt(i))) {stb1.append(Character.toLowerCase(s.charAt(i)));}i++;}// stb1 = "abc", stb2 = "cba"StringBuffer stb2 = new StringBuffer(stb1).reverse();return stb2.toString().equals(stb1.toString()); // false
StringBuffer stb1 = new StringBuffer();StringBuffer stb2 = new StringBuffer();int i = 0, n = s.length();while(i < n) {if(Character.isLetterOrDigit(s.charAt(i))) {stb1.append(Character.toLowerCase(s.charAt(i)));}i++;}// stb1 = stb2 = "abc"stb2 = stb1.reverse(); // 错误写法return stb2.toString().equals(stb1.toString()); // true
StringBuffer str1= new StringBuffer();//1
StringBuffer str2 = new StringBuffer();//2
str2=str1执行后,指向同一个StringBuffer//1 的对象地址。
第2就不被引用,操作str1,str2都是操作第一个new StringBuffer() 所以改其中任一个值,另一个也会变。

若有收获,就点个赞吧
0 人点赞
