一:flink
flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算
1:优点
(1):低延迟
(2):高吞吐
(3):结果准确良好容错
2:哪些行业需要处理流数据
(1):电商市场营销
(2):物联网(IOT)
(3):电信业
(4):银行和金融业
实时计算和通知推送,实时检测异常行为
3:批处理和流式处理
(1):批处理
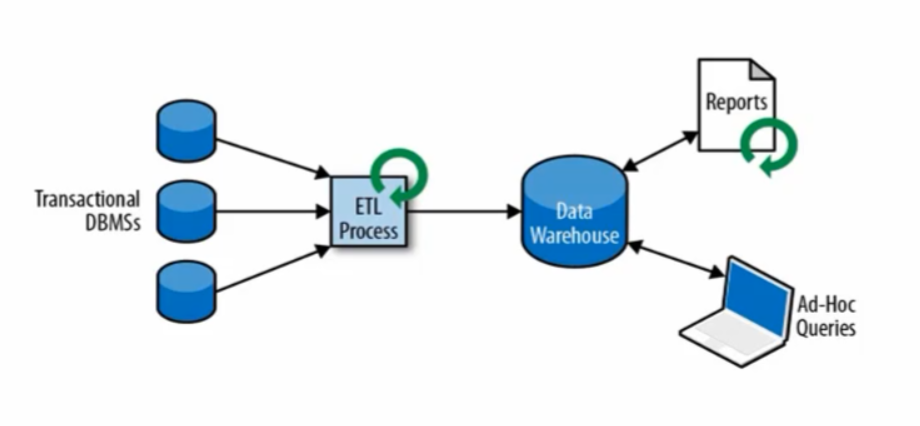
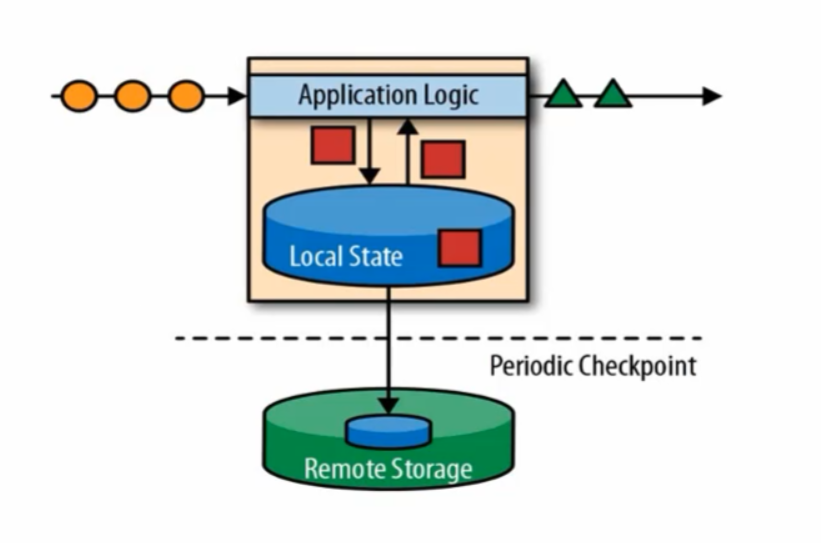
(2):流式处理
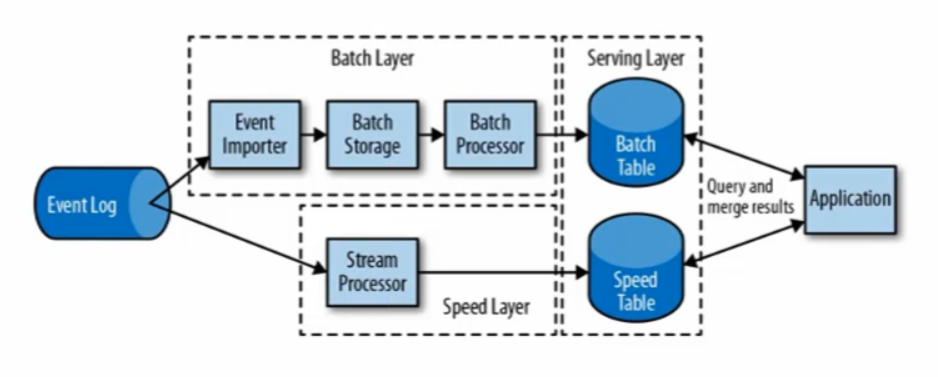
(3):流批处理 lamada架构
4:特点
(1):事件驱动
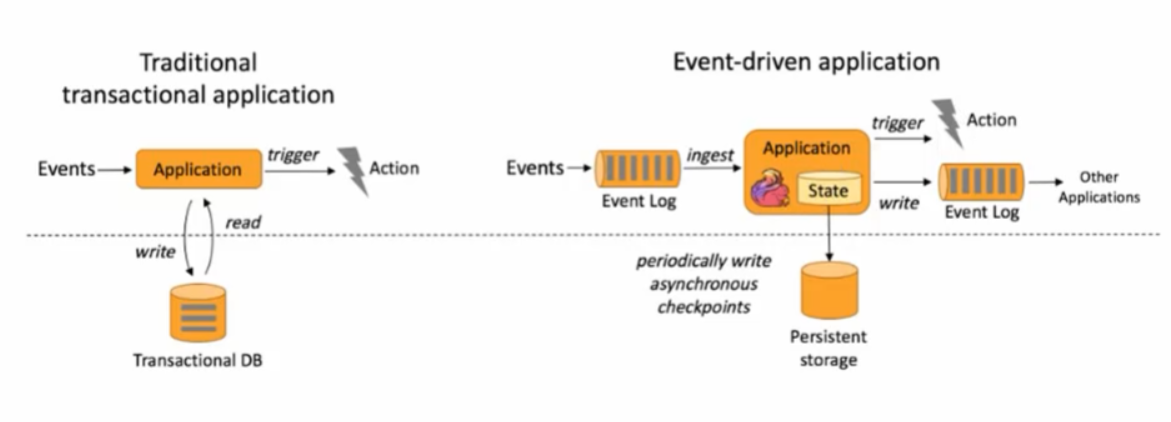
(2):基于流
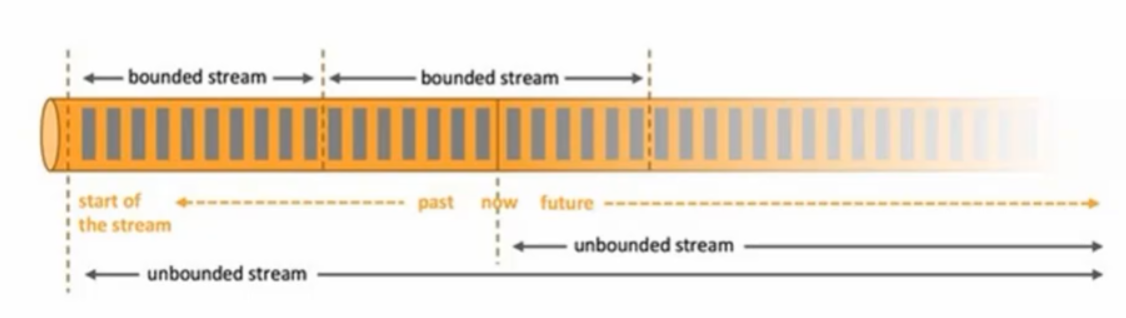
(3):分层API
(4):支持事件事件和处理时间
(5):精确一次的状态一致性保证
(6):低延迟,每秒处理数百万事件,毫秒级延迟
(7):与众多常用存储系统的连接
(8):高可用,动态扩展,7*24小时
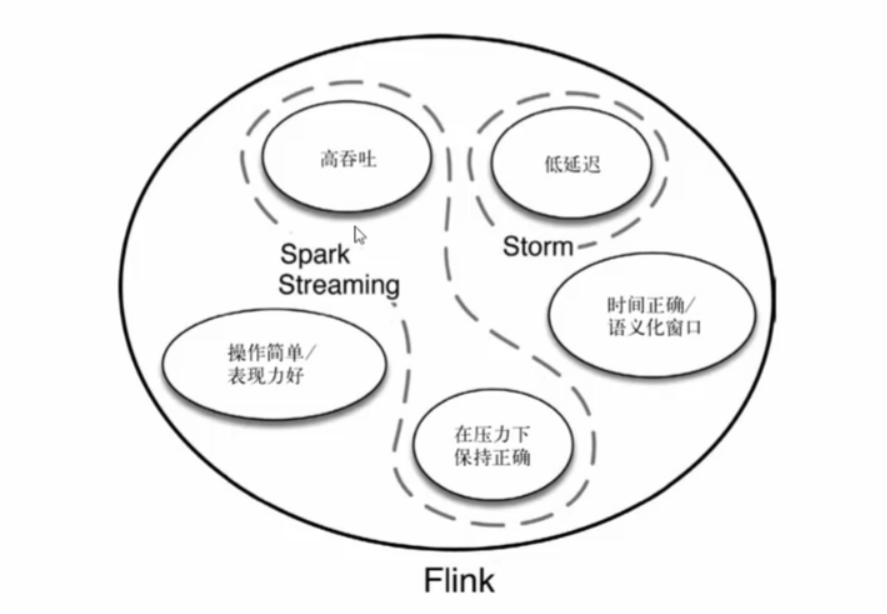
4:VS spark Streaming
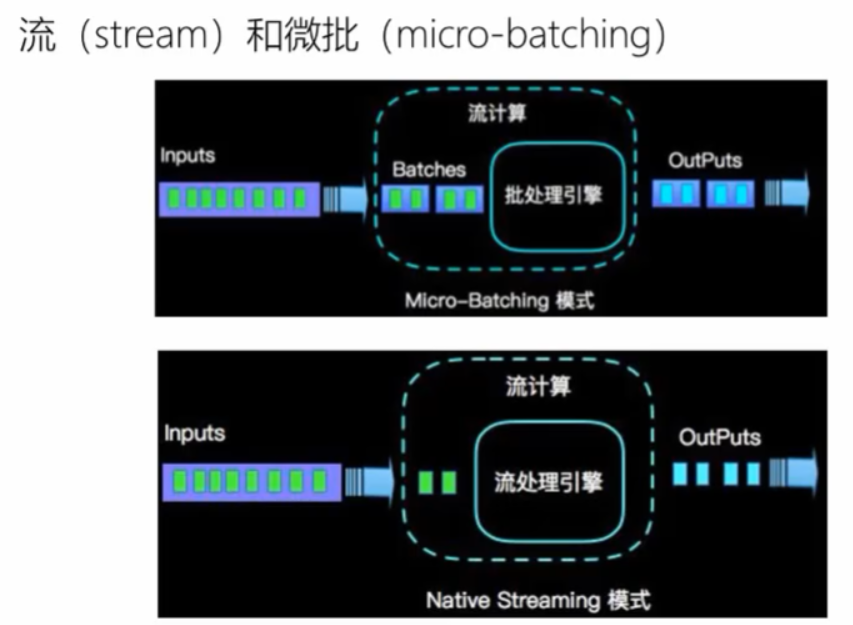
(1):spark采用RDD模型,spark streaming的DStream实际上也就是一组小批数RDD的集合
(2):flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点处理
二:安装部署
1:local部署
(1):下载
https://archive.apache.org/dist/flink/flink-1.12.1/
(2):解压
cd /opt/modulestar -zxvf flink-1.12.1-bin-scala_2.11.tgz
(3):启动
cd flink-1.12.1/bin./start-cluster.sh#查看进程jps###StandaloneSessionClusterEntrypointTaskManagerRunner
(4):访问web ui
http://hadoop102:8081/#/overview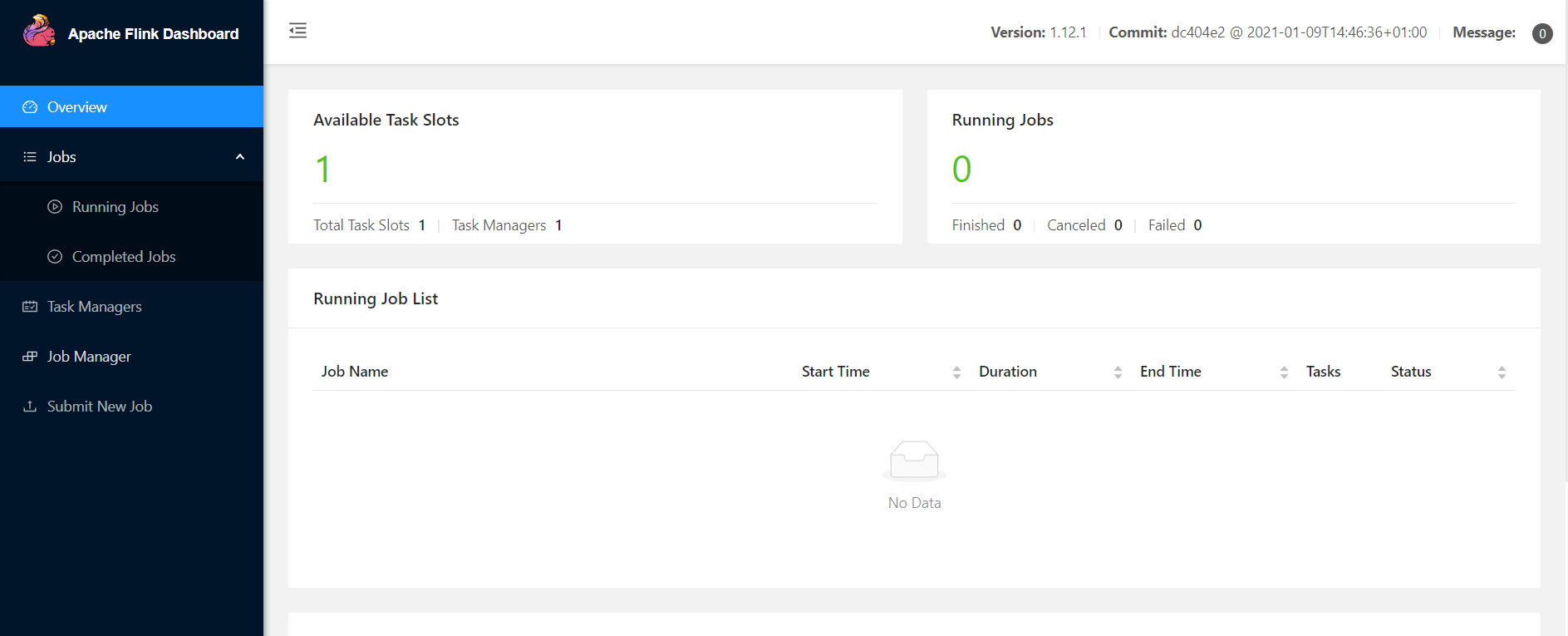
(5):执行官方示例
#编写测试文件cd /opt/software/flink-1.12.1/examplesvim words.txthello me you herhello me youhello mehellocd flink-1.12.1/bin#启动WordCount./flink run /opt/software/flink-1.12.1/examples/batch/WordCount.jar --input ../examples/words.txt --output ../examples/out#查看结果cat ../examples/outhello 4her 1me 3you 2
(6):停止
./stop-cluster.sh
(7):查看web结果
2:standalone独立集群
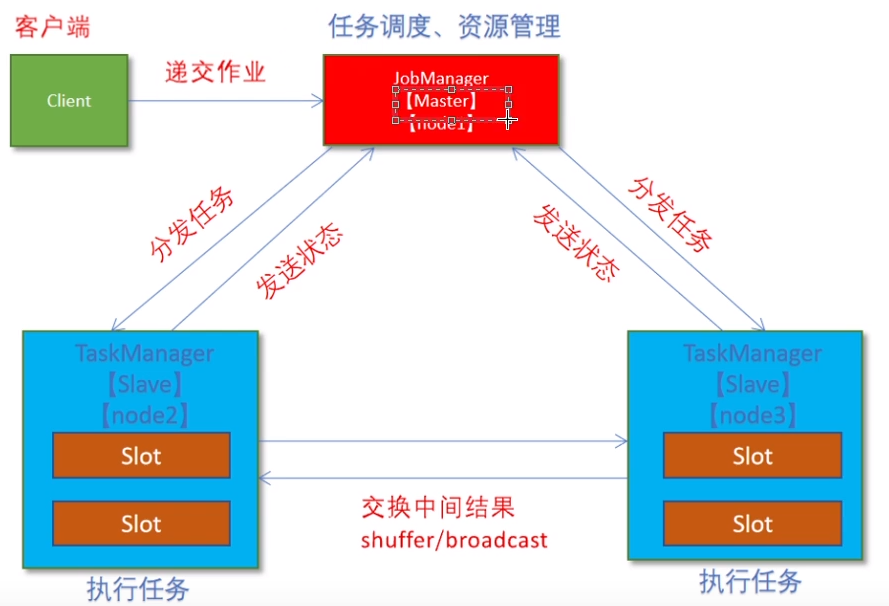
(1):集群规划
hadoop102 master slavehadoop103 slave
(2):修改flink-conf.yaml
jobmanager.rpc.address: hadoop102jobmanager.rpc.port: 6123jobmanager.memory.process.size: 1600mtaskmanager.memory.process.size: 1728m# taskmanager.memory.flink.size: 1280mtaskmanager.numberOfTaskSlots: 2parallelism.default: 1# The default file system scheme and authority.## By default file paths without scheme are interpreted relative to the local# root file system 'file:///'. Use this to override the default and interpret# relative paths relative to a different file system,# for example 'hdfs://mynamenode:12345'## fs.default-scheme#==============================================================================# High Availability#==============================================================================# The high-availability mode. Possible options are 'NONE' or 'zookeeper'.## high-availability: zookeeper# The path where metadata for master recovery is persisted. While ZooKeeper stores# the small ground truth for checkpoint and leader election, this location stores# the larger objects, like persisted dataflow graphs.## Must be a durable file system that is accessible from all nodes# (like HDFS, S3, Ceph, nfs, ...)## high-availability.storageDir: hdfs:///flink/ha/# The list of ZooKeeper quorum peers that coordinate the high-availability# setup. This must be a list of the form:# "host1:clientPort,host2:clientPort,..." (default clientPort: 2181)## high-availability.zookeeper.quorum: localhost:2181# ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes# It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE)# The default value is "open" and it can be changed to "creator" if ZK security is enabled## high-availability.zookeeper.client.acl: open#==============================================================================# Fault tolerance and checkpointing#==============================================================================# The backend that will be used to store operator state checkpoints if# checkpointing is enabled.## Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the# <class-name-of-factory>.## state.backend: filesystem# Directory for checkpoints filesystem, when using any of the default bundled# state backends.## state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints# Default target directory for savepoints, optional.## state.savepoints.dir: hdfs://namenode-host:port/flink-savepoints# Flag to enable/disable incremental checkpoints for backends that# support incremental checkpoints (like the RocksDB state backend).## state.backend.incremental: false# The failover strategy, i.e., how the job computation recovers from task failures.# Only restart tasks that may have been affected by the task failure, which typically includes# downstream tasks and potentially upstream tasks if their produced data is no longer available for consumption.jobmanager.execution.failover-strategy: region#==============================================================================# Rest & web frontend#==============================================================================# The port to which the REST client connects to. If rest.bind-port has# not been specified, then the server will bind to this port as well.##rest.port: 8081# The address to which the REST client will connect to##rest.address: 0.0.0.0# Port range for the REST and web server to bind to.##rest.bind-port: 8080-8090# The address that the REST & web server binds to##rest.bind-address: 0.0.0.0# Flag to specify whether job submission is enabled from the web-based# runtime monitor. Uncomment to disable.web.submit.enable: true#==============================================================================# Advanced#==============================================================================# Override the directories for temporary files. If not specified, the# system-specific Java temporary directory (java.io.tmpdir property) is taken.## For framework setups on Yarn or Mesos, Flink will automatically pick up the# containers' temp directories without any need for configuration.## Add a delimited list for multiple directories, using the system directory# delimiter (colon ':' on unix) or a comma, e.g.:# /data1/tmp:/data2/tmp:/data3/tmp## Note: Each directory entry is read from and written to by a different I/O# thread. You can include the same directory multiple times in order to create# multiple I/O threads against that directory. This is for example relevant for# high-throughput RAIDs.## io.tmp.dirs: /tmp# The classloading resolve order. Possible values are 'child-first' (Flink's default)# and 'parent-first' (Java's default).## Child first classloading allows users to use different dependency/library# versions in their application than those in the classpath. Switching back# to 'parent-first' may help with debugging dependency issues.## classloader.resolve-order: child-first# The amount of memory going to the network stack. These numbers usually need# no tuning. Adjusting them may be necessary in case of an "Insufficient number# of network buffers" error. The default min is 64MB, the default max is 1GB.## taskmanager.memory.network.fraction: 0.1# taskmanager.memory.network.min: 64mb# taskmanager.memory.network.max: 1gb#==============================================================================# Flink Cluster Security Configuration#==============================================================================# Kerberos authentication for various components - Hadoop, ZooKeeper, and connectors -# may be enabled in four steps:# 1. configure the local krb5.conf file# 2. provide Kerberos credentials (either a keytab or a ticket cache w/ kinit)# 3. make the credentials available to various JAAS login contexts# 4. configure the connector to use JAAS/SASL# The below configure how Kerberos credentials are provided. A keytab will be used instead of# a ticket cache if the keytab path and principal are set.# security.kerberos.login.use-ticket-cache: true# security.kerberos.login.keytab: /path/to/kerberos/keytab# security.kerberos.login.principal: flink-user# The configuration below defines which JAAS login contexts# security.kerberos.login.contexts: Client,KafkaClient#==============================================================================# ZK Security Configuration#==============================================================================# Below configurations are applicable if ZK ensemble is configured for security# Override below configuration to provide custom ZK service name if configured# zookeeper.sasl.service-name: zookeeper# The configuration below must match one of the values set in "security.kerberos.login.contexts"# zookeeper.sasl.login-context-name: Client#==============================================================================# HistoryServer#==============================================================================# The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)# Directory to upload completed jobs to. Add this directory to the list of# monitored directories of the HistoryServer as well (see below).jobmanager.archive.fs.dir: hdfs:///flink/completed-jobs/# The address under which the web-based HistoryServer listens.historyserver.web.address: hadoop102# The port under which the web-based HistoryServer listens.historyserver.web.port: 8082# Comma separated list of directories to monitor for completed jobs.historyserver.archive.fs.dir: hdfs:///flink/completed-jobs/# Interval in milliseconds for refreshing the monitored directories.#historyserver.archive.fs.refresh-interval: 10000historyserver.web.tmpdir: /tmp/flinkhistoryserver/
(3):修改masters
hadoop102:8081
(4):修改workers
hadoop102
hadoop103
(5):增加jar
/opt/software/flink-1.12.1/lib/flink-shaded-hadoop-3-uber-3.1.1.7.1.1.0-565-9.0.jar
(6):修改/etc/profile增加配置
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export HADOOP_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#HIVE_HOME
HIVE_HOME=/opt/module/hive
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin
export PATH JAVA_HOME HADOOP_HOME HIVE_HOME
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
(7):启动flink服务,historyserver服务
./start-cluster.sh
./historyserver.sh start
4个可用任务线程,因为2台worker,配置taskmanager.numberOfTaskSlots: 2
一台服务2个所以为4个
3:standaloneHA
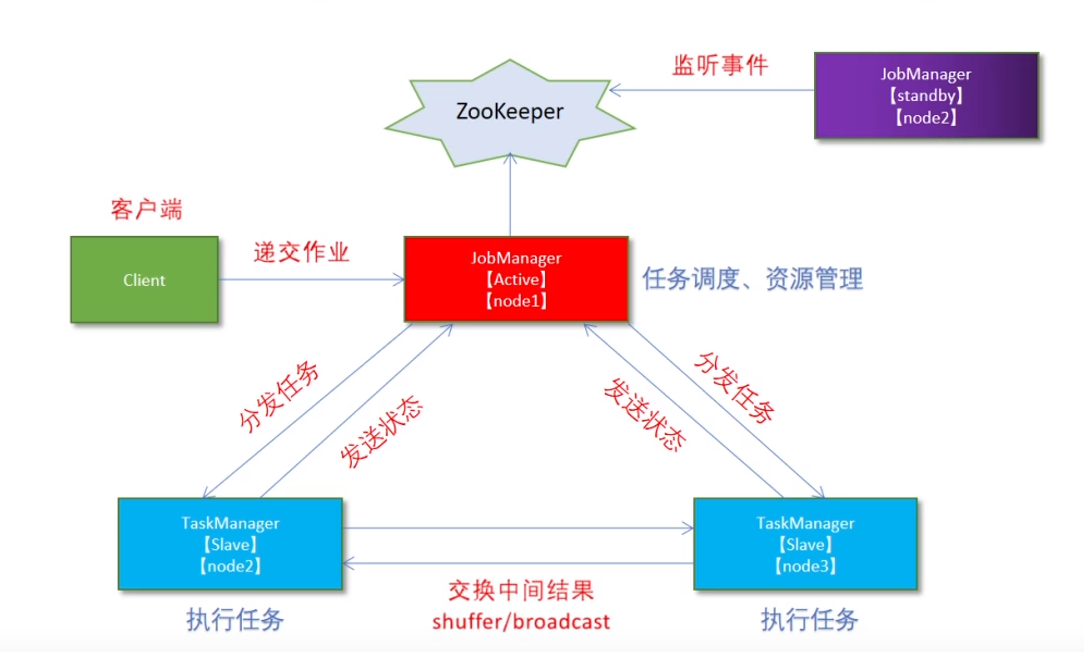
(1):集群规划
hadoop102 master+slave jobManager+TaskManager
hadoop103 master+slave jobManager+TaskManager
(2):启动zk
(3):启动hdfs
(4):修改flink-conf.yaml
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################
#==============================================================================
# Common
#==============================================================================
# The external address of the host on which the JobManager runs and can be
# reached by the TaskManagers and any clients which want to connect. This setting
# is only used in Standalone mode and may be overwritten on the JobManager side
# by specifying the --host <hostname> parameter of the bin/jobmanager.sh executable.
# In high availability mode, if you use the bin/start-cluster.sh script and setup
# the conf/masters file, this will be taken care of automatically. Yarn/Mesos
# automatically configure the host name based on the hostname of the node where the
# JobManager runs.
jobmanager.rpc.address: hadoop102
# The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6123
# The total process memory size for the JobManager.
#
# Note this accounts for all memory usage within the JobManager process, including JVM metaspace and other overhead.
jobmanager.memory.process.size: 1600m
# The total process memory size for the TaskManager.
#
# Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead.
taskmanager.memory.process.size: 1728m
# To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'.
# It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory.
#
# taskmanager.memory.flink.size: 1280m
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
taskmanager.numberOfTaskSlots: 2
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
# The default file system scheme and authority.
#
# By default file paths without scheme are interpreted relative to the local
# root file system 'file:///'. Use this to override the default and interpret
# relative paths relative to a different file system,
# for example 'hdfs://mynamenode:12345'
#
# fs.default-scheme
#==============================================================================
# High Availability
#==============================================================================
# The high-availability mode. Possible options are 'NONE' or 'zookeeper'.
#
high-availability: zookeeper
# The path where metadata for master recovery is persisted. While ZooKeeper stores
# the small ground truth for checkpoint and leader election, this location stores
# the larger objects, like persisted dataflow graphs.
#
# Must be a durable file system that is accessible from all nodes
# (like HDFS, S3, Ceph, nfs, ...)
#
high-availability.storageDir: hdfs://hadoop102:9820/flink/ha/
# The list of ZooKeeper quorum peers that coordinate the high-availability
# setup. This must be a list of the form:
# "host1:clientPort,host2:clientPort,..." (default clientPort: 2181)
#
high-availability.zookeeper.quorum: hadoop102:2181,hadoop103:2181
# ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes
# It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE)
# The default value is "open" and it can be changed to "creator" if ZK security is enabled
#
# high-availability.zookeeper.client.acl: open
#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================
# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled.
#
# Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the
# <class-name-of-factory>.
#
state.backend: filesystem
# Directory for checkpoints filesystem, when using any of the default bundled
# state backends.
#
state.checkpoints.dir: hdfs://hadoop102:9820/flink-checkpoints
# Default target directory for savepoints, optional.
#
# state.savepoints.dir: hdfs://namenode-host:port/flink-savepoints
# Flag to enable/disable incremental checkpoints for backends that
# support incremental checkpoints (like the RocksDB state backend).
#
# state.backend.incremental: false
# The failover strategy, i.e., how the job computation recovers from task failures.
# Only restart tasks that may have been affected by the task failure, which typically includes
# downstream tasks and potentially upstream tasks if their produced data is no longer available for consumption.
jobmanager.execution.failover-strategy: region
#==============================================================================
# Rest & web frontend
#==============================================================================
# The port to which the REST client connects to. If rest.bind-port has
# not been specified, then the server will bind to this port as well.
#
#rest.port: 8081
# The address to which the REST client will connect to
#
#rest.address: 0.0.0.0
# Port range for the REST and web server to bind to.
#
#rest.bind-port: 8080-8090
# The address that the REST & web server binds to
#
#rest.bind-address: 0.0.0.0
# Flag to specify whether job submission is enabled from the web-based
# runtime monitor. Uncomment to disable.
web.submit.enable: true
#==============================================================================
# Advanced
#==============================================================================
# Override the directories for temporary files. If not specified, the
# system-specific Java temporary directory (java.io.tmpdir property) is taken.
#
# For framework setups on Yarn or Mesos, Flink will automatically pick up the
# containers' temp directories without any need for configuration.
#
# Add a delimited list for multiple directories, using the system directory
# delimiter (colon ':' on unix) or a comma, e.g.:
# /data1/tmp:/data2/tmp:/data3/tmp
#
# Note: Each directory entry is read from and written to by a different I/O
# thread. You can include the same directory multiple times in order to create
# multiple I/O threads against that directory. This is for example relevant for
# high-throughput RAIDs.
#
# io.tmp.dirs: /tmp
# The classloading resolve order. Possible values are 'child-first' (Flink's default)
# and 'parent-first' (Java's default).
#
# Child first classloading allows users to use different dependency/library
# versions in their application than those in the classpath. Switching back
# to 'parent-first' may help with debugging dependency issues.
#
# classloader.resolve-order: child-first
# The amount of memory going to the network stack. These numbers usually need
# no tuning. Adjusting them may be necessary in case of an "Insufficient number
# of network buffers" error. The default min is 64MB, the default max is 1GB.
#
# taskmanager.memory.network.fraction: 0.1
# taskmanager.memory.network.min: 64mb
# taskmanager.memory.network.max: 1gb
#==============================================================================
# Flink Cluster Security Configuration
#==============================================================================
# Kerberos authentication for various components - Hadoop, ZooKeeper, and connectors -
# may be enabled in four steps:
# 1. configure the local krb5.conf file
# 2. provide Kerberos credentials (either a keytab or a ticket cache w/ kinit)
# 3. make the credentials available to various JAAS login contexts
# 4. configure the connector to use JAAS/SASL
# The below configure how Kerberos credentials are provided. A keytab will be used instead of
# a ticket cache if the keytab path and principal are set.
# security.kerberos.login.use-ticket-cache: true
# security.kerberos.login.keytab: /path/to/kerberos/keytab
# security.kerberos.login.principal: flink-user
# The configuration below defines which JAAS login contexts
# security.kerberos.login.contexts: Client,KafkaClient
#==============================================================================
# ZK Security Configuration
#==============================================================================
# Below configurations are applicable if ZK ensemble is configured for security
# Override below configuration to provide custom ZK service name if configured
# zookeeper.sasl.service-name: zookeeper
# The configuration below must match one of the values set in "security.kerberos.login.contexts"
# zookeeper.sasl.login-context-name: Client
#==============================================================================
# HistoryServer
#==============================================================================
# The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)
# Directory to upload completed jobs to. Add this directory to the list of
# monitored directories of the HistoryServer as well (see below).
jobmanager.archive.fs.dir: hdfs://hadoop102:9820/flink/completed-jobs/
# The address under which the web-based HistoryServer listens.
historyserver.web.address: hadoop102
# The port under which the web-based HistoryServer listens.
historyserver.web.port: 8082
# Comma separated list of directories to monitor for completed jobs.
historyserver.archive.fs.dir: hdfs://hadoop102:9820/flink/completed-jobs/
# Interval in milliseconds for refreshing the monitored directories.
#historyserver.archive.fs.refresh-interval: 10000
historyserver.web.tmpdir: /tmp/flinkhistoryserver/
(5):修改masters
hadoop102:8081
hadoop103:8081
三:flink on yarn
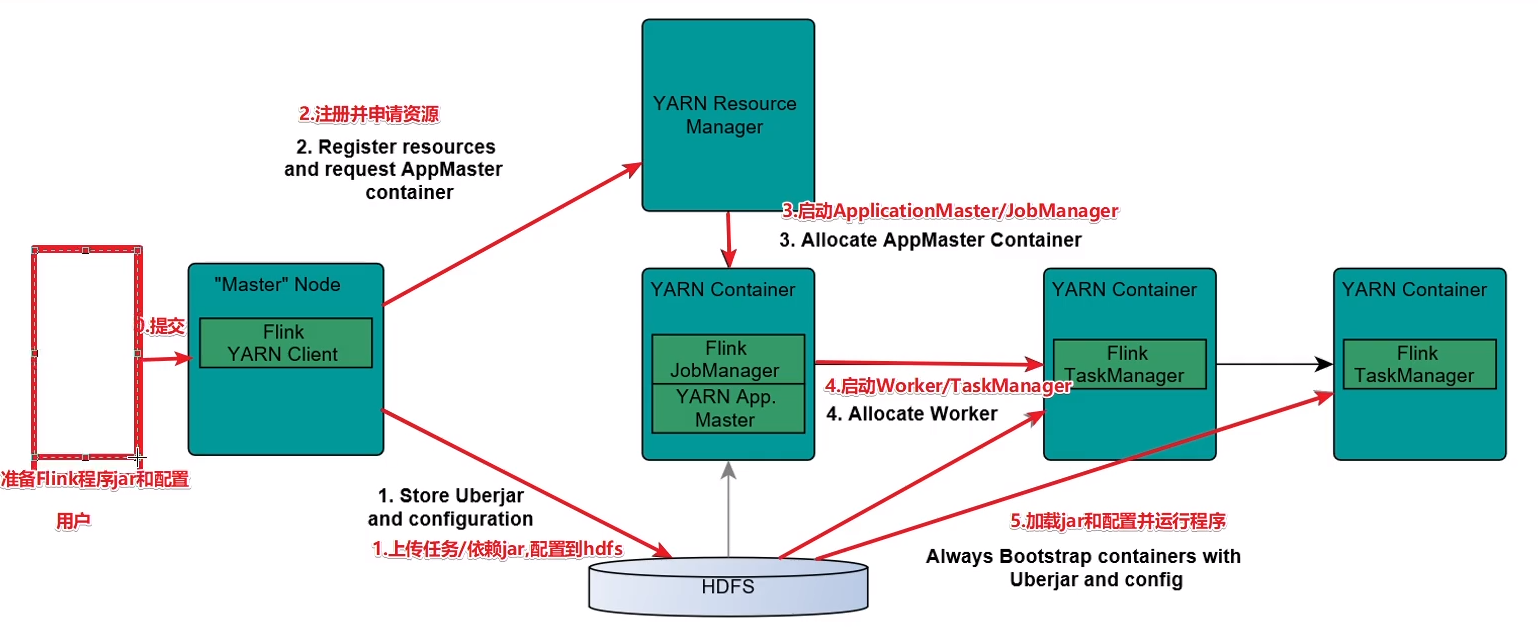
实际开发中,更多方式使用flink on yarn,原因:
yarn的资源可以按需使用,提高集群的资源利用率
yarn的任务有优先级,根据优先级运行作业
基于yarn调度,能够自动化的处理各个角色failover(容错)
Jobmanager和Taskmanager进程由yarn Nodemanager监控
Jobmanager异常退出,yarn ResourceManager重新调度JobManager到其他机器
TaskManager进程异常退出,Jobmanager会受到消息重新向ResourceManager申请资源,重新启动
关闭yarn的内存检查
vim yarn-site.xml
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
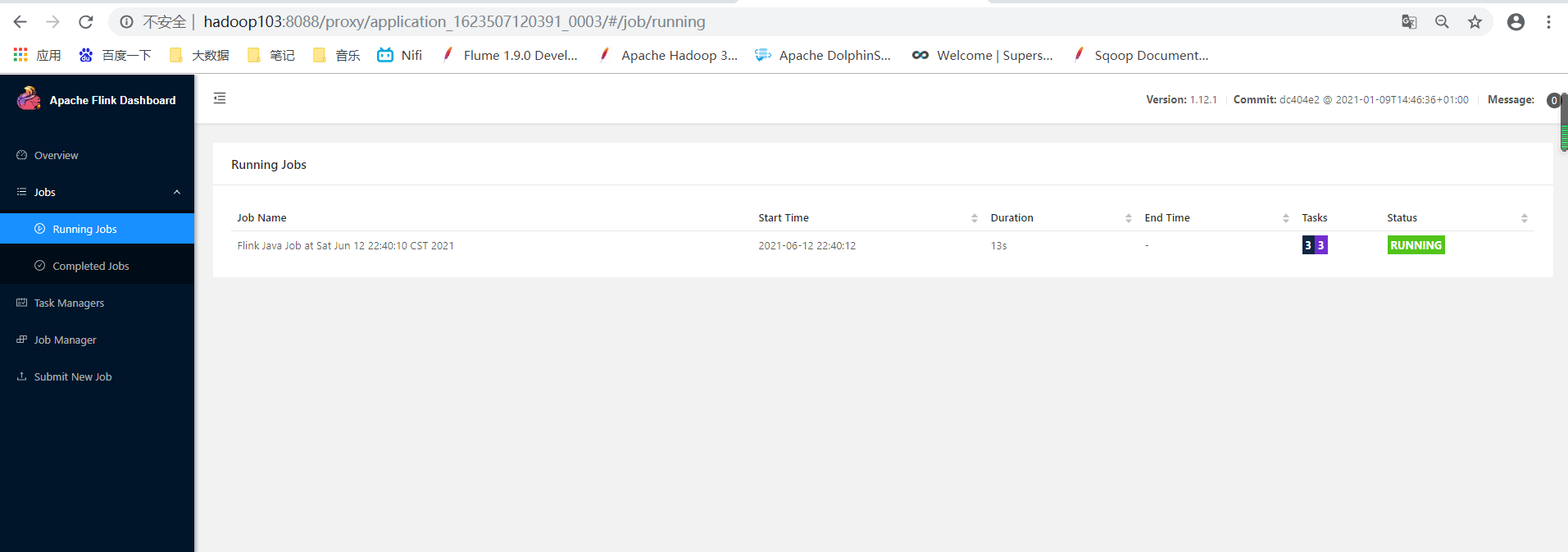
1:session模式
在yarn上启动一个flink集群,并重复使用该集群,后续提交的任务都是给该集群,资源会被一直占用,除非手动关闭该集群—-适用于大量的小任务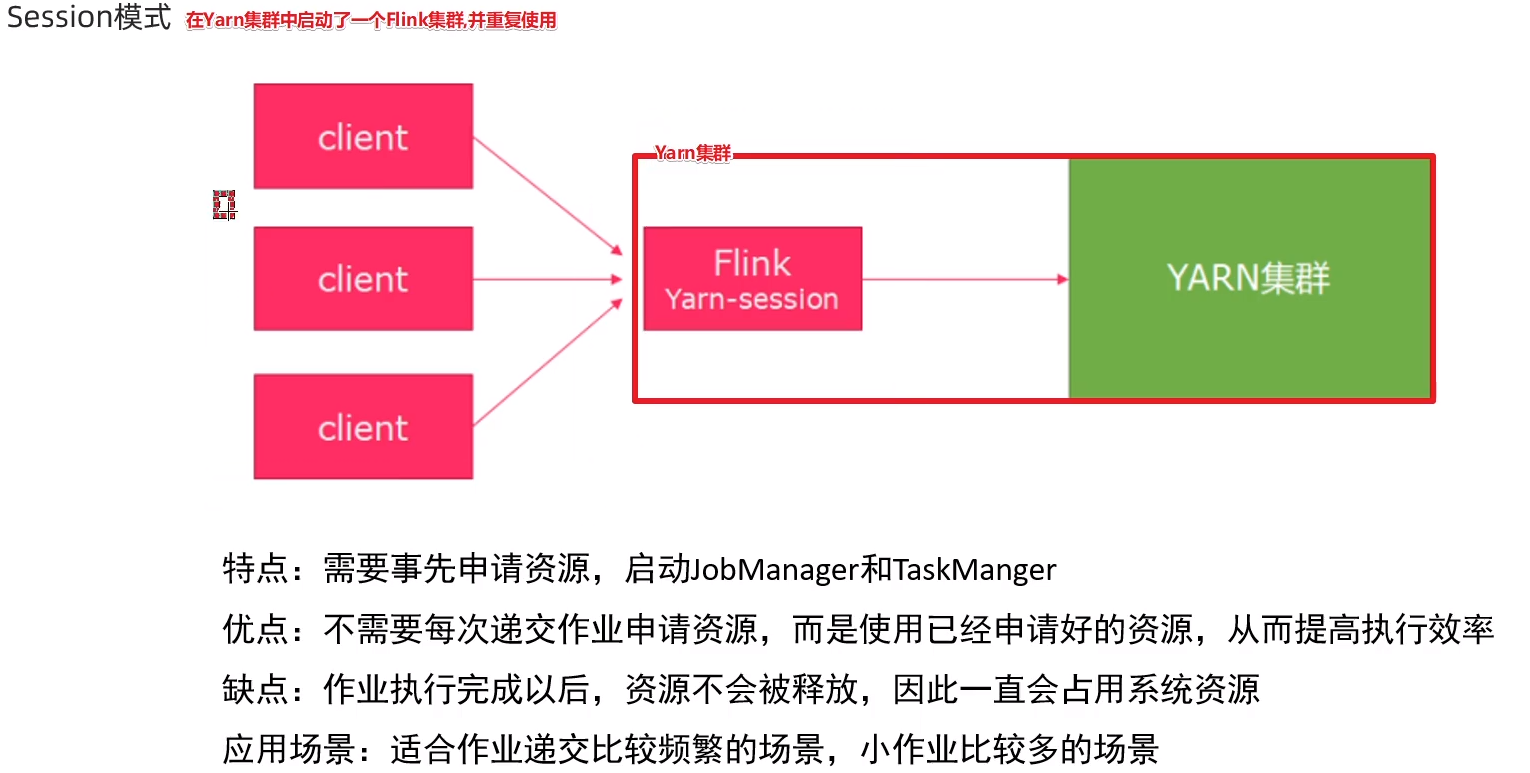
(1):在yarn上启动flink集群,hadoop102执行
# 申请2个cpu,1600m内存
# n表示申请2个容器,指多少个taskmanager
# -tm表示每个taskmanager的内存大小
# -s表示每个Taskmanager的slots数量
# -d表示后台运行
/bin/yarn-session.sh -n 2 -tm 800 -s 1 -d
访问hadoop103:8088 yarn集群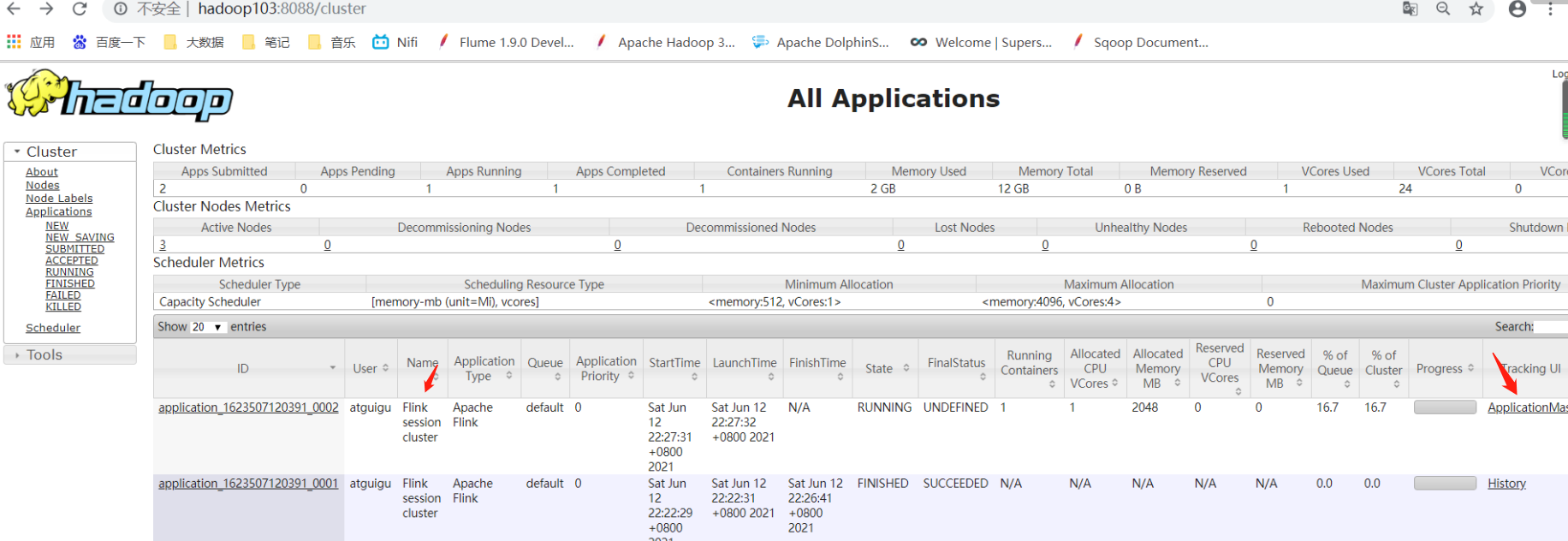
yarn启动flink集群,点击ApplicationMaster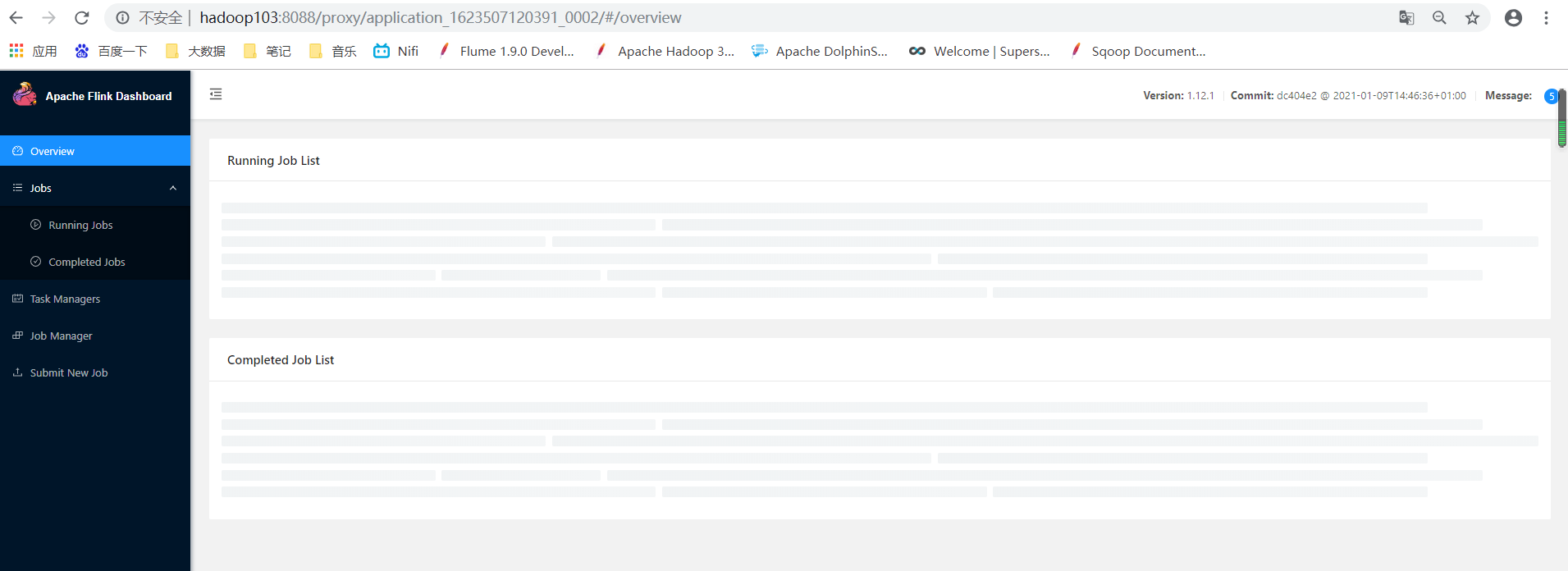
(2):提交job
./flink run /opt/software/flink-1.12.1/examples/batch/WordCount.jar
(3):yarn-session关闭
yarn application -kill application_1623507120391_0002
2:per-job模式
针对每个flink任务在yarn上启动一个独立的flink集群并运行,结束后自动关闭并释放资源——适用于少量大任务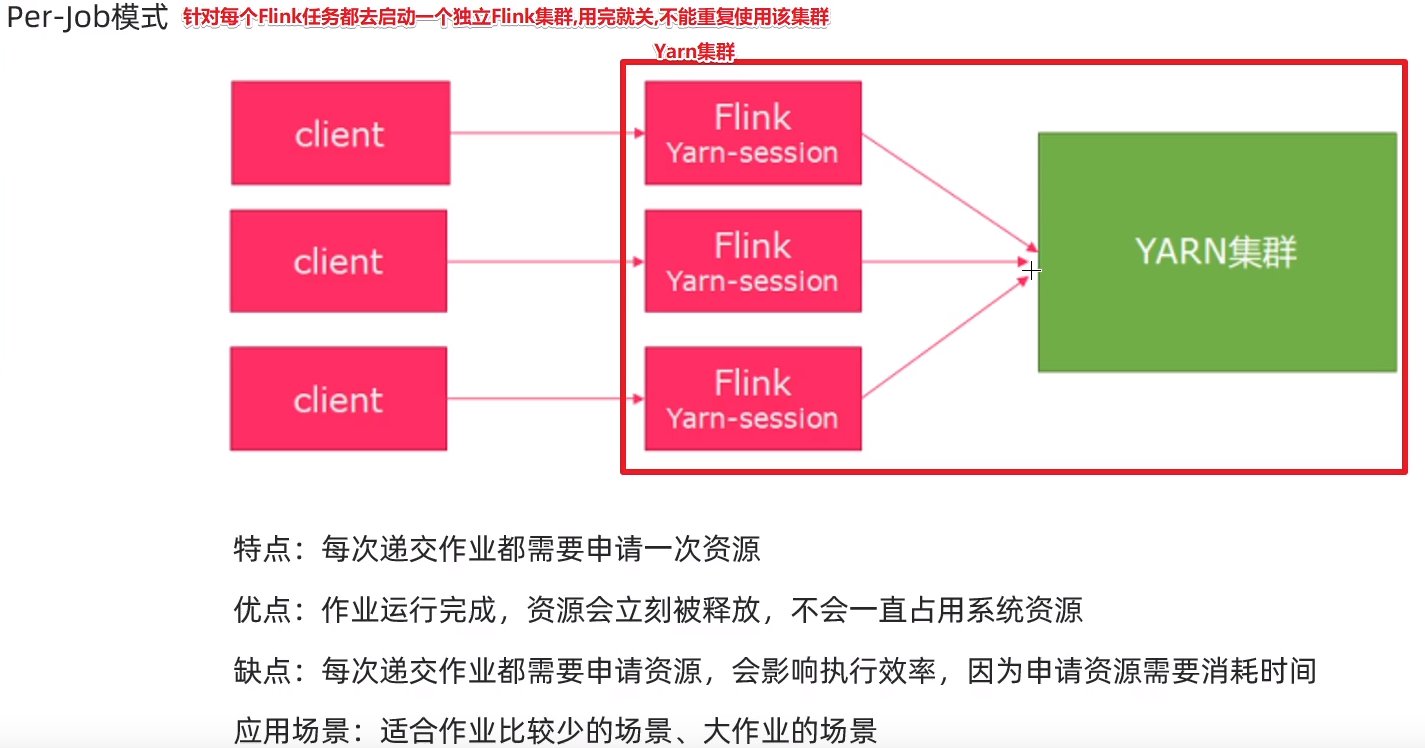
#-m jobmanager地址
#yjm 1024 指定jobmanager内存
#ytm 1024 指定taskmanager内存
./flink run -m yarn-cluster -yjm 1024 -ytm 1024 /opt/software/flink-1.12.1/examples/batch/WordCount.jar
(1)执行过程中flink集群运行
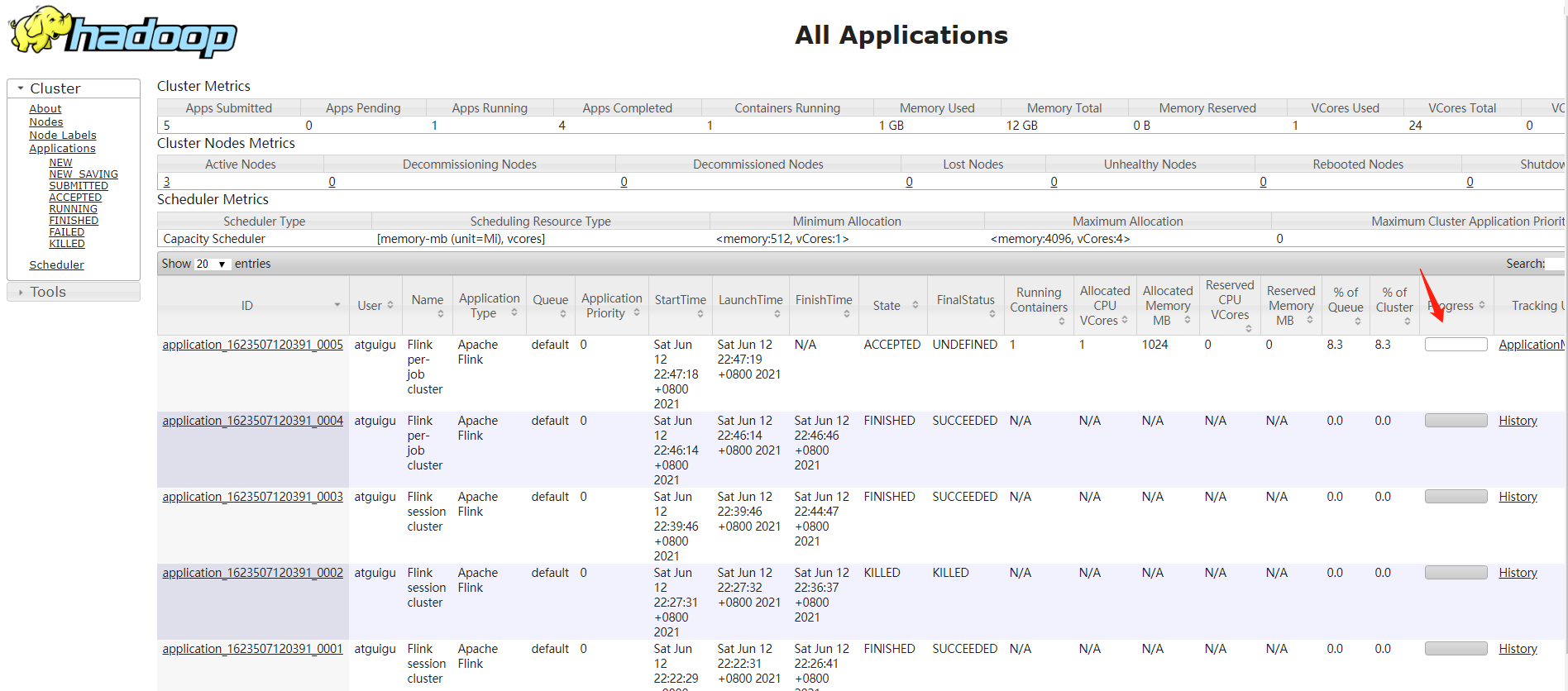
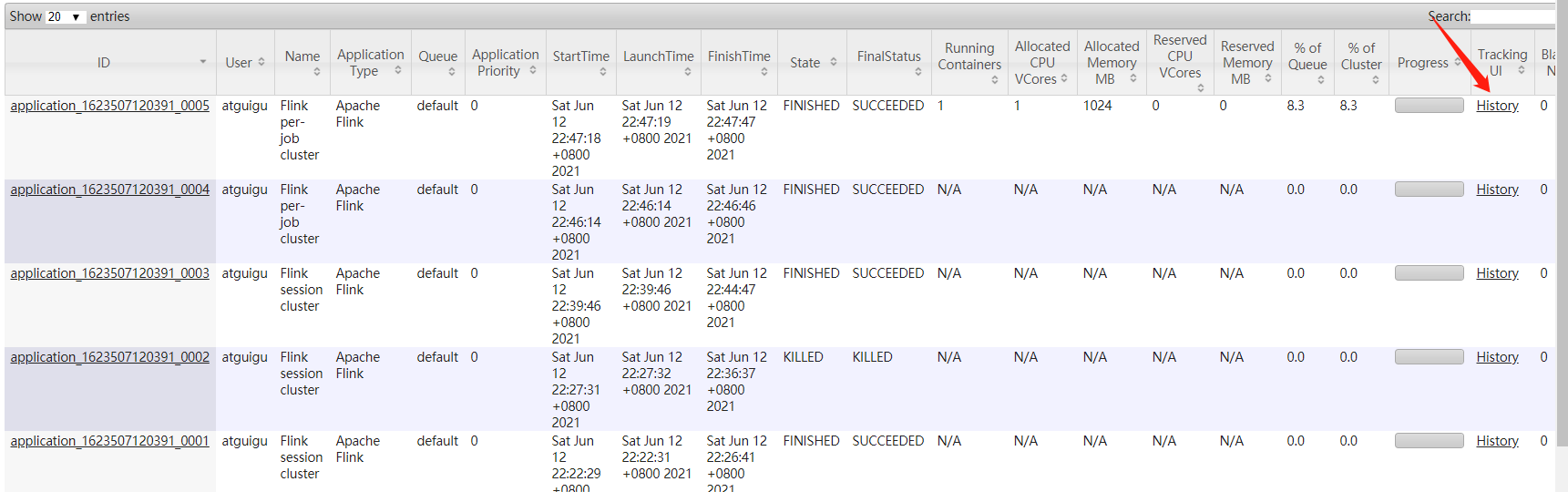
(2)执行过程后flink集群作业完成,资源释放
四:flink入门
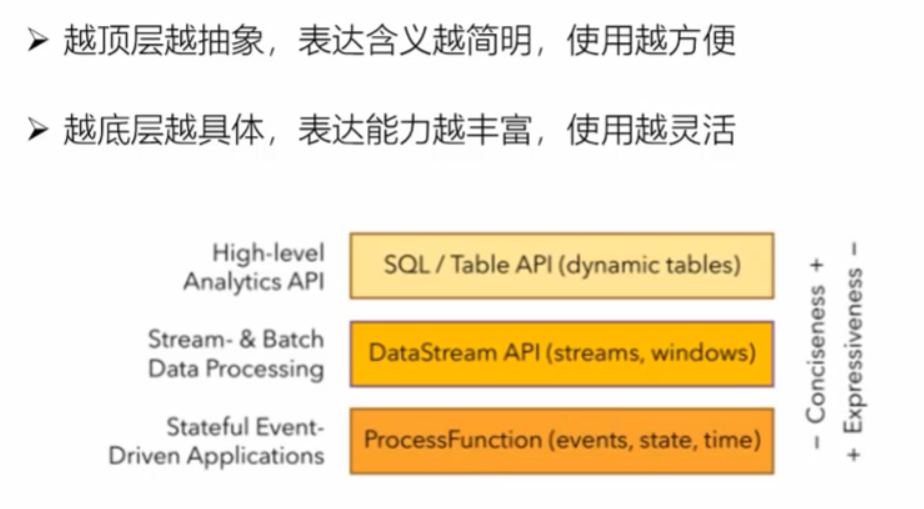
1:api层
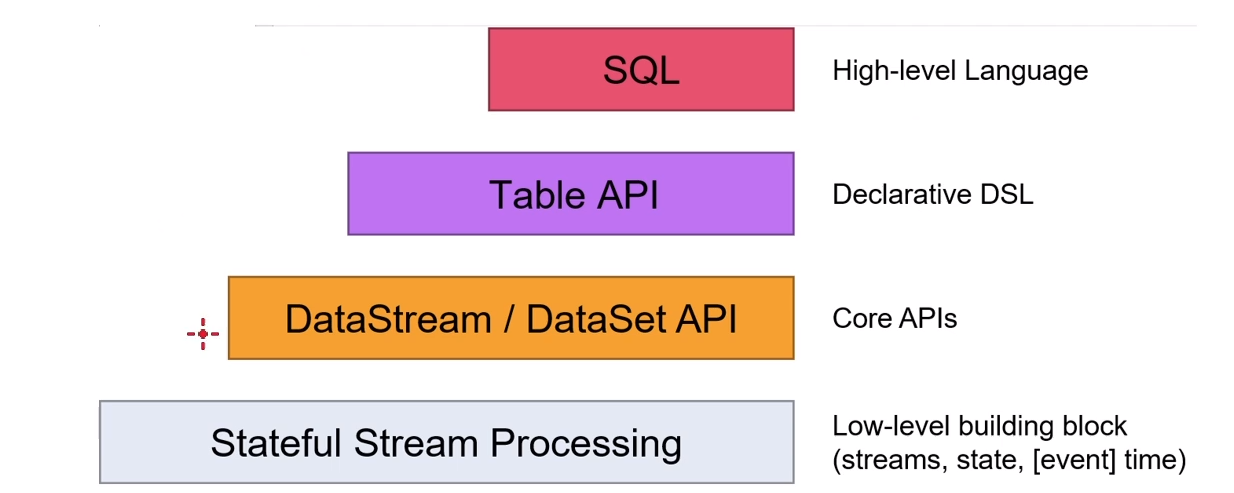
注意: Core APIs DataSet API flink 1.12.1 过时, 所以后续会使用DataStream API
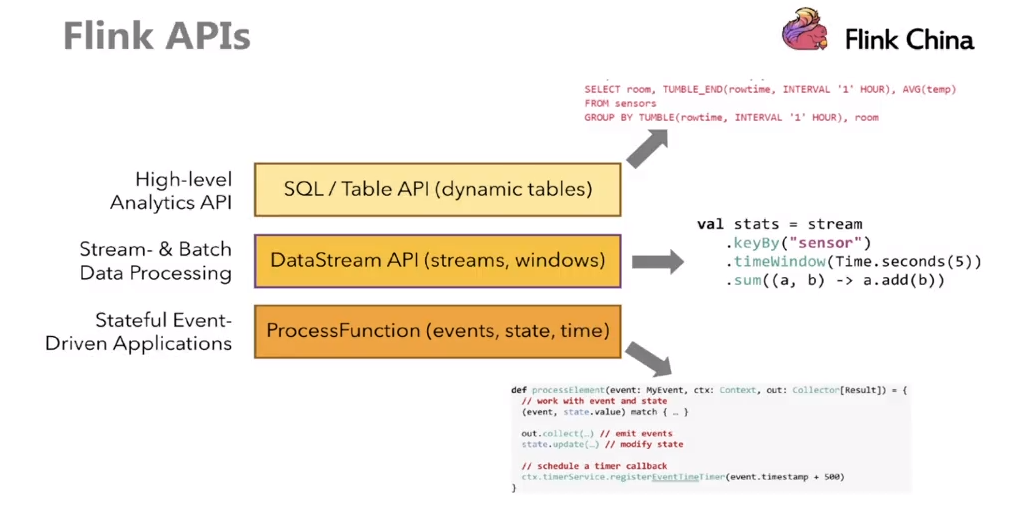
#官方文档
https://ci.apache.org/projects/flink/flink-docs-release-1.12/
2:编程模型
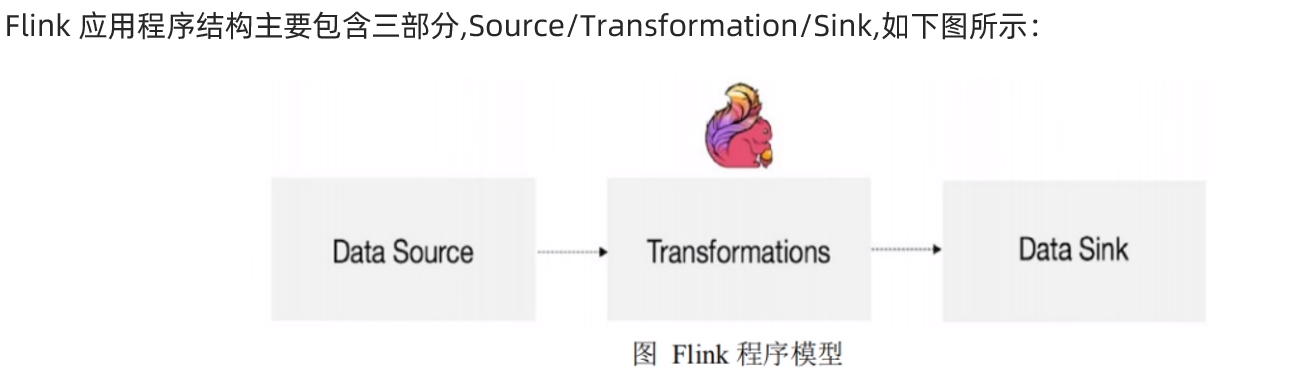
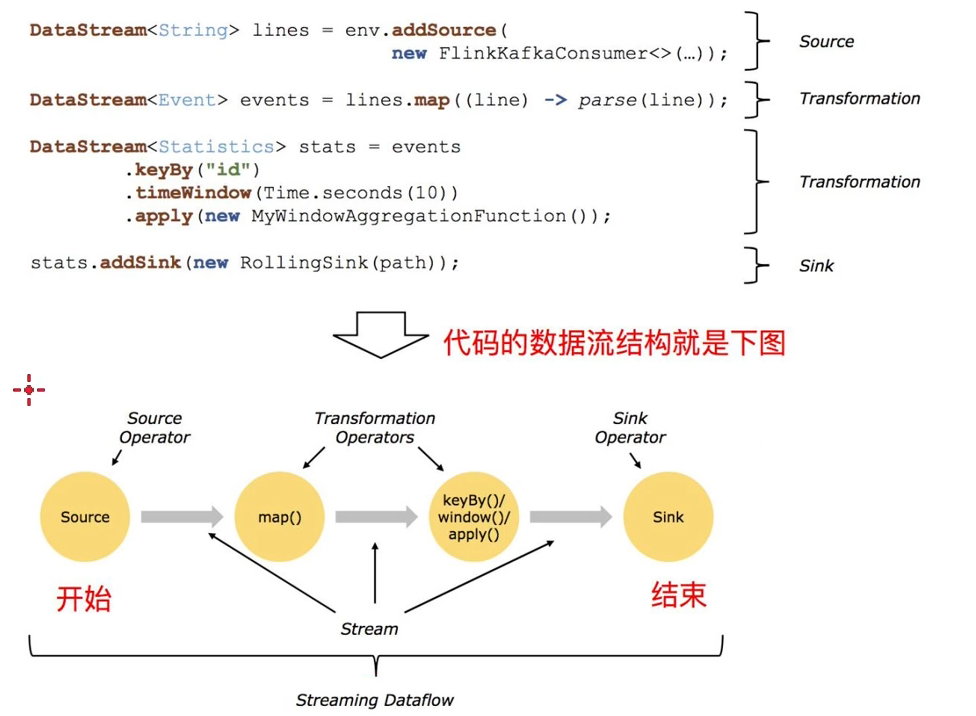
3:入门示例
pom.xml
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
<!-- 指定仓库位置,依次为aliyun、apache和cloudera仓库 -->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>apache</id>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<properties>
<encoding>UTF-8</encoding>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<java.version>1.8</java.version>
<scala.version>2.12</scala.version>
<flink.version>1.12.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink执行计划,这是1.9版本之前的-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- blink执行计划,1.11+默认的-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<!--<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_2.12</artifactId>
<version>${flink.version}</version>
</dependency>-->
<!-- flink连接器-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-filesystem_2.12</artifactId>
<version>${flink.version}</version>
</dependency>-->
<!--<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.12</artifactId>
<version>${flink.version}</version>
</dependency>-->
<!--<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_2.12</artifactId>
<version>${flink.version}</version>
</dependency>-->
<!--<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.10.0</version>
</dependency>-->
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
<exclusions>
<exclusion>
<artifactId>flink-streaming-java_2.11</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
<exclusion>
<artifactId>flink-runtime_2.11</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
<exclusion>
<artifactId>flink-core</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
<exclusion>
<artifactId>flink-java</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>2.1.0</version>
</dependency>
<!-- <dependency>-->
<!-- <groupId>org.apache.hive</groupId>-->
<!-- <artifactId>hive-exec</artifactId>-->
<!-- <version>2.1.0</version>-->
<!-- </dependency>-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2-uber</artifactId>
<version>2.7.5-10.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
<!--<version>8.0.20</version>-->
</dependency>
<!-- 高性能异步组件:Vertx-->
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-core</artifactId>
<version>3.9.0</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-jdbc-client</artifactId>
<version>3.9.0</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-redis-client</artifactId>
<version>3.9.0</version>
</dependency>
<!-- 日志 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.44</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.2</version>
<scope>provided</scope>
</dependency>
<!-- 参考:https://blog.csdn.net/f641385712/article/details/84109098-->
<!--<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.4</version>
</dependency>-->
<!--<dependency>
<groupId>org.apache.thrift</groupId>
<artifactId>libfb303</artifactId>
<version>0.9.3</version>
<type>pom</type>
<scope>provided</scope>
</dependency>-->
<!--<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.2-jre</version>
</dependency>-->
</dependencies>
(1):wordcount datastream
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
//普通版本
public class WordCount {
public static void main(String[] args) throws Exception {
//TODO 0.env
//ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//env.setRuntimeMode(RuntimeExecutionMode.BATCH);//注意:使用DataStream实现批处理
//env.setRuntimeMode(RuntimeExecutionMode.STREAMING);//注意:使用DataStream实现流处理
//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//注意:使用DataStream根据数据源自动选择使用流还是批
//TODO 1.source
//DataSet<String> lines = env.fromElements("itcast hadoop spark", "itcast hadoop spark", "itcast hadoop", "itcast");
DataStream<String> lines = env.fromElements("itcast hadoop spark", "itcast hadoop spark", "itcast hadoop", "itcast");
//TODO 2.transformation
//切割
/*
@FunctionalInterface
public interface FlatMapFunction<T, O> extends Function, Serializable {
void flatMap(T value, Collector<O> out) throws Exception;
}
*/
DataStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
public void flatMap(String value, Collector<String> out) throws Exception {
//value就是每一行数据
String[] arr = value.split(" ");
for (String word : arr) {
out.collect(word);
}
}
});
//记为1
/*
@FunctionalInterface
public interface MapFunction<T, O> extends Function, Serializable {
O map(T value) throws Exception;
}
*/
DataStream<Tuple2<String, Integer>> wordAndOne = words.map(new MapFunction<String, Tuple2<String, Integer>>() {
public Tuple2<String, Integer> map(String value) throws Exception {
//value就是一个个单词
return Tuple2.of(value, 1);
}
});
//分组:注意DataSet中分组是groupBy,DataStream分组是keyBy
//wordAndOne.keyBy(0);
/*
@FunctionalInterface
public interface KeySelector<IN, KEY> extends Function, Serializable {
KEY getKey(IN value) throws Exception;
}
*/
KeyedStream<Tuple2<String, Integer>, String> grouped = wordAndOne.keyBy(t -> t.f0);
//聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> result = grouped.sum(1);
//TODO 3.sink
result.print();
//TODO 4.execute/启动并等待程序结束
env.execute();
}
}
(2):wordcount datastream lamada
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
//lamada 版本
public class WordCount2 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = streamExecutionEnvironment.fromElements("String string" ,"a1 a2" , "a3 a5");
SingleOutputStreamOperator<String> words = lines.flatMap((String value, Collector<String> out) ->{
Arrays.asList(value.split(" ")).forEach(out::collect);
}).returns(Types.STRING);
DataStream<Tuple2<String, Integer>> wordAndOne = words.map(
(String value) -> Tuple2.of(value, 1)
).returns(Types.TUPLE(Types.STRING,Types.INT));
KeyedStream<Tuple2<String, Integer>, String> grouped = wordAndOne.keyBy(t -> t.f0);
//聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> result = grouped.sum(1);
//TODO 3.sink
result.print();
//TODO 4.execute/启动并等待程序结束
streamExecutionEnvironment.execute();
}
}
(3):wordcount datastream on yarn
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* Author itcast
* Desc 演示Flink-DataStream-API-实现WordCount
* 注意:在Flink1.12中DataStream既支持流处理也支持批处理,如何区分?
*/
public class WordCount5_Yarn {
public static void main(String[] args) throws Exception {
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String output = "";
if (parameterTool.has("output")) {
output = parameterTool.get("output");
System.out.println("指定了输出路径使用:" + output);
} else {
output = "hdfs://node1:8020/wordcount/output47_";
System.out.println("可以指定输出路径使用 --output ,没有指定使用默认的:" + output);
}
//TODO 0.env
//ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//env.setRuntimeMode(RuntimeExecutionMode.BATCH);//注意:使用DataStream实现批处理
//env.setRuntimeMode(RuntimeExecutionMode.STREAMING);//注意:使用DataStream实现流处理
//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//注意:使用DataStream根据数据源自动选择使用流还是批
//TODO 1.source
//DataSet<String> lines = env.fromElements("itcast hadoop spark", "itcast hadoop spark", "itcast hadoop", "itcast");
DataStream<String> lines = env.fromElements("itcast hadoop spark", "itcast hadoop spark", "itcast hadoop", "itcast");
//TODO 2.transformation
//切割
/*
@FunctionalInterface
public interface FlatMapFunction<T, O> extends Function, Serializable {
void flatMap(T value, Collector<O> out) throws Exception;
}
*/
/*DataStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
//value就是每一行数据
String[] arr = value.split(" ");
for (String word : arr) {
out.collect(word);
}
}
});*/
SingleOutputStreamOperator<String> words = lines.flatMap(
(String value, Collector<String> out) -> Arrays.stream(value.split(" ")).forEach(out::collect)
).returns(Types.STRING);
//记为1
/*
@FunctionalInterface
public interface MapFunction<T, O> extends Function, Serializable {
O map(T value) throws Exception;
}
*/
/*DataStream<Tuple2<String, Integer>> wordAndOne = words.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
//value就是一个个单词
return Tuple2.of(value, 1);
}
});*/
DataStream<Tuple2<String, Integer>> wordAndOne = words.map(
(String value) -> Tuple2.of(value, 1)
).returns(Types.TUPLE(Types.STRING, Types.INT));
//分组:注意DataSet中分组是groupBy,DataStream分组是keyBy
//wordAndOne.keyBy(0);
/*
@FunctionalInterface
public interface KeySelector<IN, KEY> extends Function, Serializable {
KEY getKey(IN value) throws Exception;
}
*/
KeyedStream<Tuple2<String, Integer>, String> grouped = wordAndOne.keyBy(t -> t.f0);
//聚
SingleOutputStreamOperator<Tuple2<String, Integer>> result = grouped.sum(1);
//TODO 3.sink
//如果执行报hdfs权限相关错误,可以执行 hadoop fs -chmod -R 777 /
System.setProperty("HADOOP_USER_NAME", "atguigu");//设置用户名
//result.print();
//result.writeAsText("hdfs://node1:8020/wordcount/output47_"+System.currentTimeMillis()).setParallelism(1);
result.writeAsText(output + System.currentTimeMillis()).setParallelism(1);
//TODO 4.execute/启动并等待程序结束
env.execute();
}
}
./flink run -Dexecution.runtime-mode=BATCH -yjm 1024 -ytm 1024 -c cn.itcast.hello.WordCount5_Yarn wc1.jar --output hdfs://hadoop102:9820/wordcount/output_xx
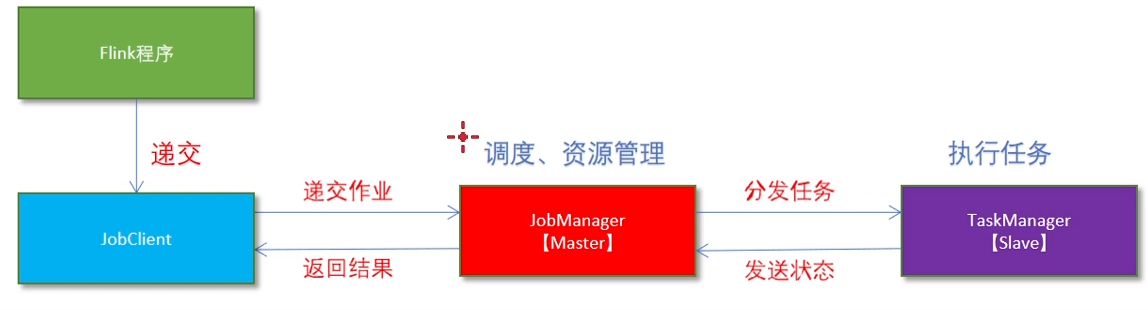
4:flink角色分工
(1):jobmanager
集群管理者,负责调度任务,协调checkpoints,协调故障恢复,收集job状态信息,并管理flink集群中从节点taskmanager
(2):taskmanager
负责计算的worker,在其上执行flink job的一组task,taskmanager还是所在节点管理员,负责把该节点的服务器信息例如内存,磁盘,任务运行情况等想jobmanager汇报
(3):client
用户在提交编写好的flink程序后,会先创建一个客户端再进行提交,这个客户端就是client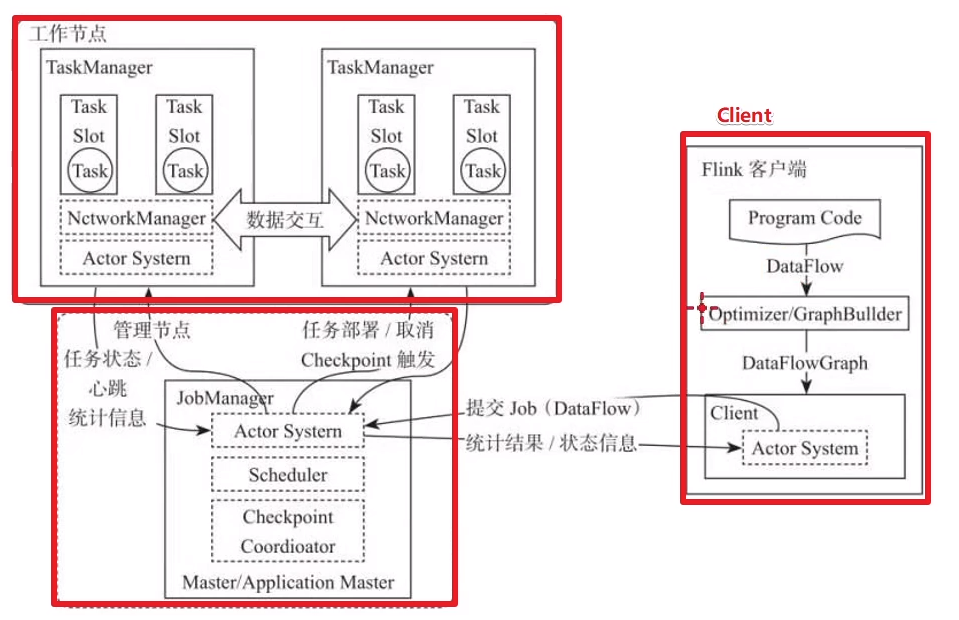
(4):执行流程 on yarn
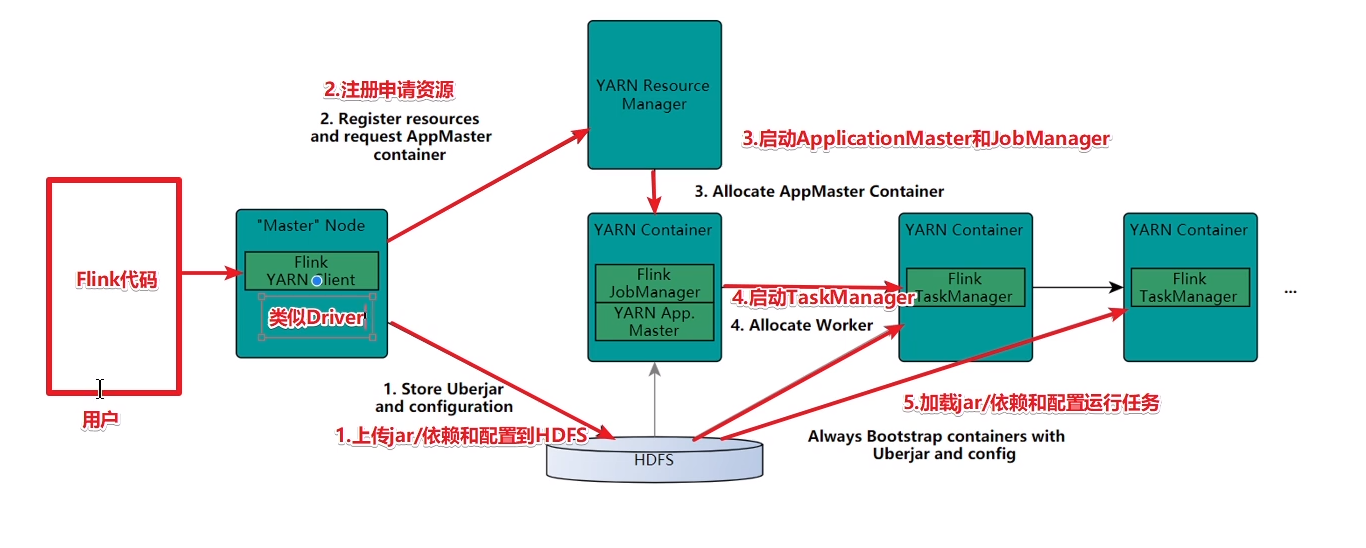
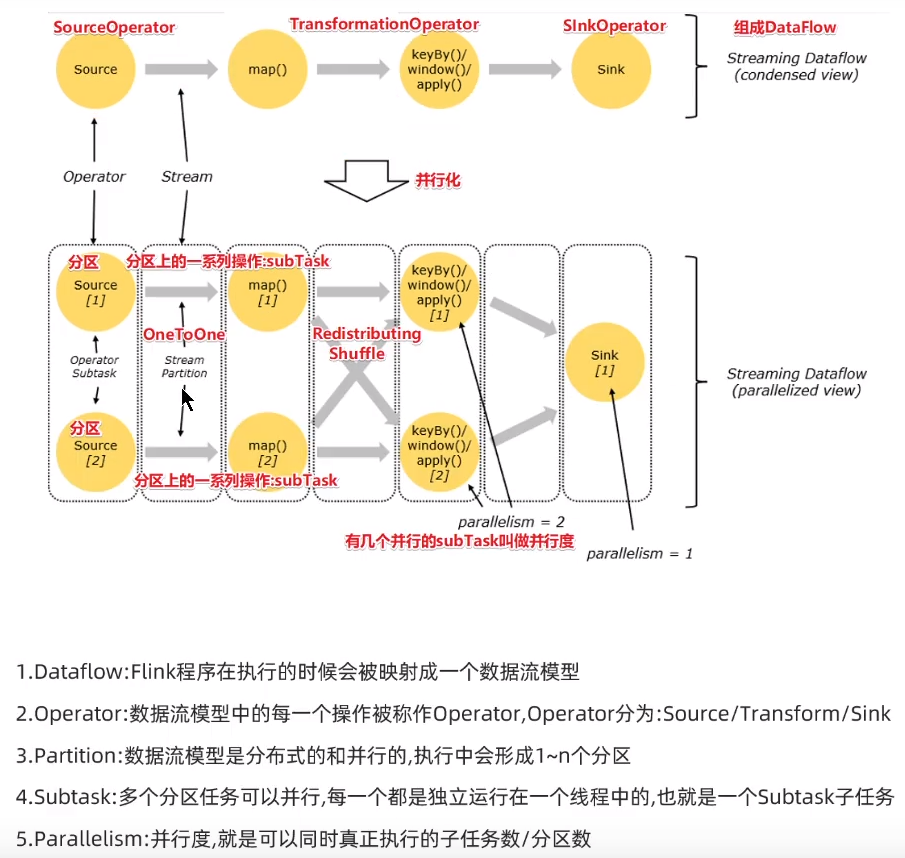
(5):dataflow
五:基础api
1:Source
(1):collection
package source;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class demo01_collection {
public static void main(String[] args) throws Exception {
//1:env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2:source
DataStream<String> ds1 = env.fromElements("hadoop hive spark" , "hadoop spark flink");
DataStream<String> ds2 = env.fromElements("hadoop hive spark" , "hadoop spark flink");
DataStream<String> ds3 = env.fromElements("hadoop hive spark" , "hadoop spark flink");
DataStream<Long> ds4 = env.fromSequence(1 ,100);
//3:transform
//4:sink
ds1.print();
ds2.print();
ds3.print();
ds4.print();
env.execute();
}
}
(2):file
package source;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class demo02_file {
public static void main(String[] args) throws Exception {
//1:env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2:source
DataStream<String> ds1 = env.readTextFile("G:\\java\\idea\\2020.2\\workspaces\\flink\\src\\main\\java\\test\\WordCount.java");
DataStream<String> ds2 = env.readTextFile("G:\\java\\idea\\2020.2\\workspaces\\flink\\src\\main\\java\\test\\WordCount2.java");
//3:transform
//4:sink
ds1.print();
ds2.print();
env.execute();
}
}
(3):socket
package source;
import com.google.inject.internal.cglib.proxy.$FixedValue;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class demo03_socket {
public static void main(String[] args) throws Exception {
//1:env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2:source
DataStream<String> ds1 = env.socketTextStream("192.168.234.129" , 9999);
SingleOutputStreamOperator<Tuple2<String ,Integer>> words = ds1.flatMap(new FlatMapFunction<String, Tuple2<String ,Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String ,Integer>> collector) throws Exception {
String []arr = s.split(" ");
for(String word : arr){
collector.collect(Tuple2.of(word ,1));
}
}
});
SingleOutputStreamOperator<Tuple2<String ,Integer>> result = words.keyBy(t->t.f0).sum(1);
result.print();
env.execute();
}
}
(4):customer
package source;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.apache.flink.util.Collector;
import java.util.Random;
import java.util.UUID;
public class demo04_customer {
public static void main(String[] args) throws Exception {
//1:env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2:source
DataStream<Order> ds1 = env.addSource(new MyOrderSource()).setParallelism(2);
ds1.print();
env.execute();
}
@Data
@NoArgsConstructor
public static class Order{
private String id;
private Integer userId;
private Integer money;
private Long createTime;
public Order(String oid, Integer userId, Integer money, Long createTime) {
this.id = oid;
this.userId = userId;
this.money = money;
this.createTime = createTime;
}
}
public static class MyOrderSource extends RichParallelSourceFunction<Order>{
private boolean flag = true;
@Override
public void run(SourceContext<Order> ctx) throws Exception {
Random r = new Random();
while (flag){
String oid = UUID.randomUUID().toString();
Integer userId = r.nextInt(3);
Integer money = r.nextInt(101);
Long createTime = System.currentTimeMillis();
ctx.collect(new Order(oid,userId,money,createTime));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
flag = false;
}
}
}
(5):mysqlcustomer
package source;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.Random;
import java.util.UUID;
public class demo05_mysqlcustomer {
public static void main(String[] args) throws Exception {
//1:env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2:source
DataStream<Canal> ds1 = env.addSource(new MyCanalSource()).setParallelism(2);
ds1.print();
env.execute();
}
@Data
@NoArgsConstructor
public static class Canal{
private int id;
private String name;
private int age;
public Canal(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
}
public static class MyCanalSource extends RichParallelSourceFunction<Canal>{
private boolean flag = true;
private Connection connection;
private PreparedStatement preparedStatement;
private ResultSet resultSet;
@Override
public void open(Configuration parameters) throws Exception {
connection = DriverManager.getConnection("jdbc:mysql://192.168.234.129:3306/canaltest" , "root" ,
"123456");
String sql = "select * from canaltest";
preparedStatement = connection.prepareStatement(sql);
}
@Override
public void run(SourceContext<Canal> ctx) throws Exception {
while (flag){
resultSet = preparedStatement.executeQuery();
while (resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
int age = resultSet.getInt("age");
ctx.collect(new Canal(id , name ,age));
}
}
}
@Override
public void cancel() {
flag = false;
}
@Override
public void close() throws Exception {
resultSet.close();
preparedStatement.close();
connection.close();
}
}
}
2:transform
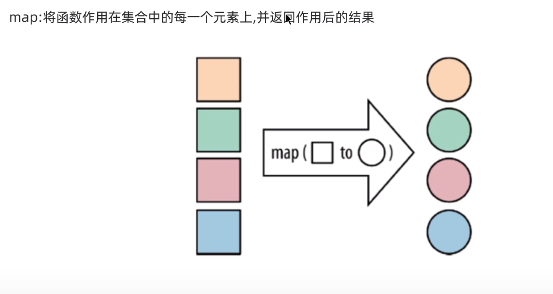
(1):map
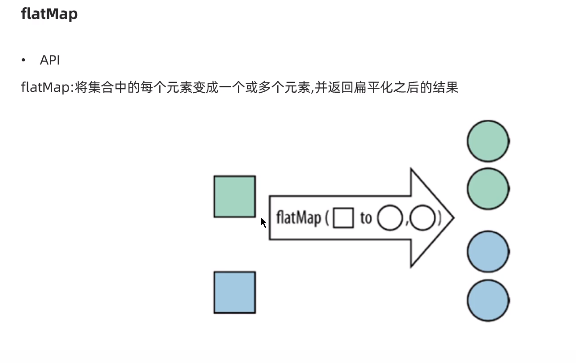
(2):flatMap
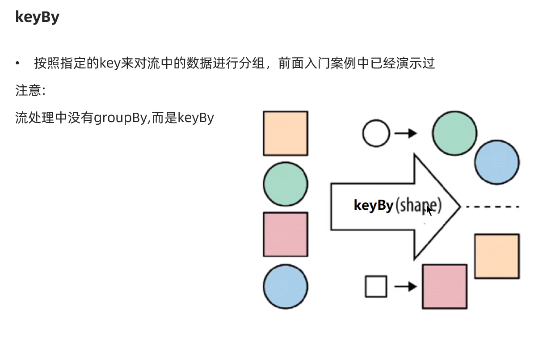
(3):keyBy
(4):filter
按照指定的条件对集合中元素进行过滤,过滤出返回true/符合条件的元素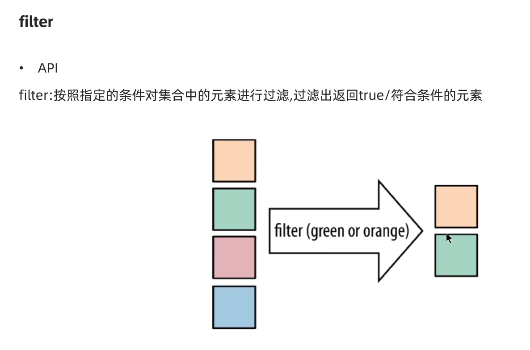
(5):reduce
对集合中元素进行聚合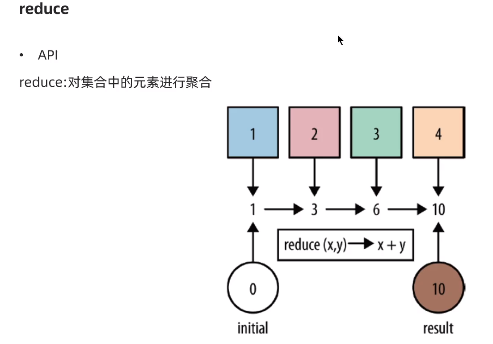
package transform;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
public class Demo01_basic {
public static void main(String[] args) throws Exception {
//1:env
StreamExecutionEnvironment streamExecutionEnvironment =
StreamExecutionEnvironment.getExecutionEnvironment();
streamExecutionEnvironment.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2:source
DataStream<String> lines = streamExecutionEnvironment.socketTextStream("192.168.234.129", 9999);
//3:flatmap
DataStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
String []values = s.split(" ");
for(String val : values){
collector.collect(val);
}
}
});
//4:过滤tmd 不计算
DataStream<String> filted = words.filter(new FilterFunction<String>() {
@Override
public boolean filter(String s) throws Exception {
if(s.equals("tmd")){
return false;
}
return true;
}
});
//5:返回对应word -> map(word,1)
SingleOutputStreamOperator<Tuple2<String,Integer>> wordAndOne = filted.map(new MapFunction<String, Tuple2<String,Integer>>() {
@Override
public Tuple2<String,Integer> map(String s) throws Exception {
return Tuple2.of(s , 1);
}
});
//6:按照word分组
KeyedStream<Tuple2<String,Integer> , String> grouped = wordAndOne.keyBy(t -> t.f0
);
//SingleOutputStreamOperator<Tuple2<String,Integer>> result = grouped.sum(1);
//7:累加前值和后值
SingleOutputStreamOperator<Tuple2<String,Integer>> result = grouped.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {
return Tuple2.of(t1.f0 , t1.f1 + t2.f1);
}
});
result.print();
streamExecutionEnvironment.execute();
}
}
(6):union和connect
union:可以合并多个同类型的数据流,并生成同类型的数据流,将多个DataStream合并新的DataStream,数据按先进先出模式合并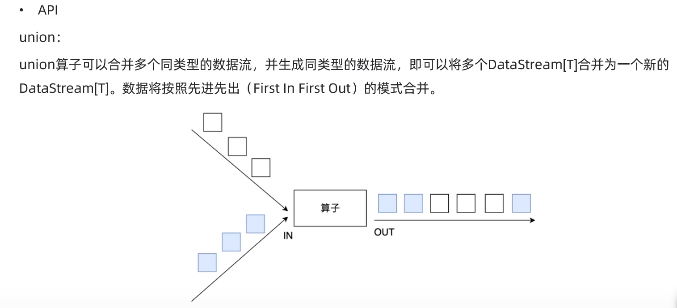
connect:提供类似union功能,连接两个数据流,和union区别
connect只能连接两个数据流,union可以连接多个数据流
connect连接两个数据流类型可以不一致,union则必须一样
package transform;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
public class Demo02_connect_union {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<String> ds1 = env.fromElements("hadoop", "spark", "flink");
DataStream<String> ds2 = env.fromElements("hadoop", "spark", "flink");
DataStream<Long> ds3 = env.fromElements(1L, 2L, 3L);
//TODO 2.transformation
DataStream<String> result1 = ds1.union(ds2);//注意union能合并同类型
//ds1.union(ds3);//注意union不可以合并不同类型
ConnectedStreams<String, String> result2 = ds1.connect(ds2);//注意:connet可以合并同类型
ConnectedStreams<String, Long> result3 = ds1.connect(ds3);//注意connet可以合并不同类型
/*
public interface CoMapFunction<IN1, IN2, OUT> extends Function, Serializable {
OUT map1(IN1 value) throws Exception;
OUT map2(IN2 value) throws Exception;
}
*/
SingleOutputStreamOperator<String> result = result3.map(new CoMapFunction<String, Long, String>() {
@Override
public String map1(String value) throws Exception {
return "String:" + value;
}
@Override
public String map2(Long value) throws Exception {
return "Long:" + value;
}
});
//TODO 3.sink
// result1.print();
//result2.print();//注意:connect之后需要做其他的处理,不能直接输出
//result3.print();//注意:connect之后需要做其他的处理,不能直接输出
result.print();
//TODO 4.execute
env.execute();
}
}
(7):split和select,side outputs
package transform;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
public class Demo03_split {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStreamSource<Integer> ds = env.fromElements(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
//TODO 2.transformation
//需求:对流中的数据按照奇数和偶数拆分并选择
OutputTag<Integer> oddTag = new OutputTag<>("奇数", TypeInformation.of(Integer.class));
OutputTag<Integer> evenTag = new OutputTag<>("偶数",TypeInformation.of(Integer.class));
/*
public abstract class ProcessFunction<I, O> extends AbstractRichFunction {
public abstract void processElement(I value, ProcessFunction.Context ctx, Collector<O> out) throws Exception;
}
*/
SingleOutputStreamOperator<Integer> result = ds.process(new ProcessFunction<Integer, Integer>() {
@Override
public void processElement(Integer value, Context ctx, Collector<Integer> out) throws Exception {
//out收集完的还是放在一起的,ctx可以将数据放到不同的OutputTag
if (value % 2 == 0) {
ctx.output(evenTag, value);
} else {
ctx.output(oddTag, value);
}
}
});
DataStream<Integer> oddResult = result.getSideOutput(oddTag);
DataStream<Integer> evenResult = result.getSideOutput(evenTag);
//TODO 3.sink
System.out.println(oddTag);//OutputTag(Integer, 奇数)
System.out.println(evenTag);//OutputTag(Integer, 偶数)
oddResult.print("奇数:");
evenResult.print("偶数:");
//TODO 4.execute
env.execute();
}
}
3:分区
(1):rebalance重平衡分区
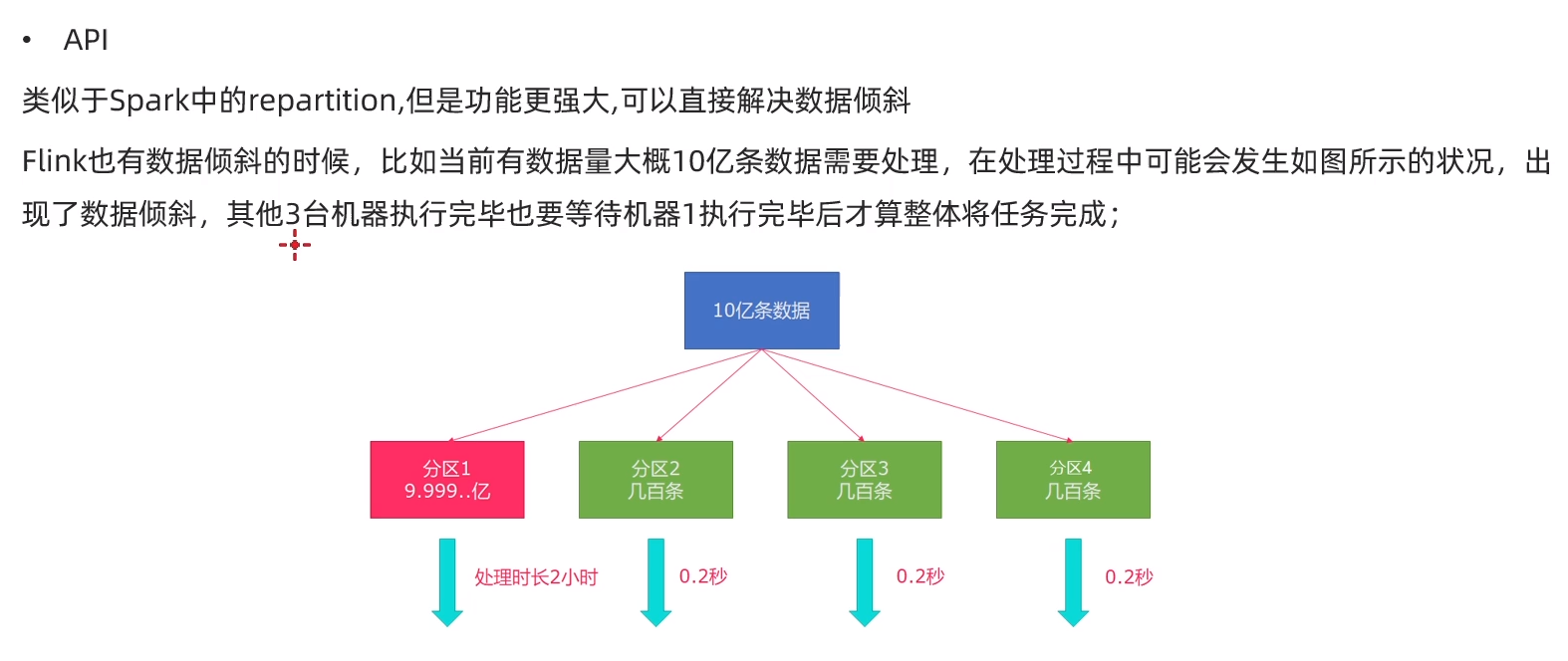
实际工作中,比较好的解决方案是rebalance(内部使用round robin方法)将数据均匀打散
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* Author itcast
* Desc 演示DataStream-Transformation-rebalance-重平衡分区
*/
public class Demo04_rebalance {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<Long> longDS = env.fromSequence(0, 100);
//下面的操作相当于将数据随机分配一下,有可能出现数据倾斜
DataStream<Long> filterDS = longDS.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long num) throws Exception {
return num > 10;
}
});
//TODO 2.transformation
//没有经过rebalance有可能出现数据倾斜
SingleOutputStreamOperator<Tuple2<Integer, Integer>> result1 = filterDS
.map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long value) throws Exception {
int subTaskId = getRuntimeContext().getIndexOfThisSubtask();//子任务id/分区编号
return Tuple2.of(subTaskId, 1);
}
//按照子任务id/分区编号分组,并统计每个子任务/分区中有几个元素
}).keyBy(t -> t.f0).sum(1);
//调用了rebalance解决了数据倾斜
SingleOutputStreamOperator<Tuple2<Integer, Integer>> result2 = filterDS.rebalance()
.map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long value) throws Exception {
int subTaskId = getRuntimeContext().getIndexOfThisSubtask();//子任务id/分区编号
return Tuple2.of(subTaskId, 1);
}
//按照子任务id/分区编号分组,并统计每个子任务/分区中有几个元素
}).keyBy(t -> t.f0).sum(1);
//TODO 3.sink
result1.print("result1");
result2.print("result2");
//TODO 4.execute
env.execute();
}
}
(2):其他策略
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class Demo05_other {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<String> linesDS = env.readTextFile("G:\\java\\idea\\2020.2\\workspaces\\flink\\src\\main\\resources\\words.txt");
SingleOutputStreamOperator<Tuple2<String, Integer>> tupleDS = linesDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
});
//TODO 2.transformation
DataStream<Tuple2<String, Integer>> result1 = tupleDS.global();
DataStream<Tuple2<String, Integer>> result2 = tupleDS.broadcast();
DataStream<Tuple2<String, Integer>> result3 = tupleDS.forward();
DataStream<Tuple2<String, Integer>> result4 = tupleDS.shuffle();
DataStream<Tuple2<String, Integer>> result5 = tupleDS.rebalance();
DataStream<Tuple2<String, Integer>> result6 = tupleDS.rescale();
DataStream<Tuple2<String, Integer>> result7 = tupleDS.partitionCustom(new MyPartitioner(), t -> t.f0);
//TODO 3.sink
result1.print("result1");
result2.print("result2");
result3.print("result3");
result4.print("result4");
result5.print("result5");
result6.print("result6");
result7.print("result7");
//TODO 4.execute
env.execute();
}
public static class MyPartitioner implements Partitioner<String> {
@Override
public int partition(String key, int numPartitions) {
//if(key.equals("北京")) return 0; 这里写自己的分区逻辑即可
return 0;
}
}
}
4:sink
(1):console
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Demo01_console {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<String> ds = env.readTextFile("G:\\java\\idea\\2020.2\\workspaces\\flink\\src\\main\\resources\\words.txt");
//TODO 2.transformation
//TODO 3.sink
ds.print();
ds.print("输出标识");
ds.printToErr();//会在控制台上以红色输出
ds.printToErr("输出标识");//会在控制台上以红色输出
ds.writeAsText("G:\\java\\idea\\2020.2\\workspaces\\flink\\src\\main\\resources\\result1").setParallelism(1);
ds.writeAsText("G:\\java\\idea\\2020.2\\workspaces\\flink\\src\\main\\resources\\result2").setParallelism(2);
//TODO 4.execute
env.execute();
}
}
(2):custom sink
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
/**
* Author itcast
* Desc 演示DataStream-Sink-自定义Sink
*/
public class Demo02_sink {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<Student> studentDS = env.fromElements(new Student(null, "tony", 18));
//TODO 2.transformation
//TODO 3.sink
studentDS.addSink(new MySQLSink());
//TODO 4.execute
env.execute();
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Student {
private Integer id;
private String name;
private Integer age;
}
public static class MySQLSink extends RichSinkFunction<Student> {
private Connection conn = null;
private PreparedStatement ps =null;
@Override
public void open(Configuration parameters) throws Exception {
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata", "root", "root");
String sql = "INSERT INTO `t_student` (`id`, `name`, `age`) VALUES (null, ?, ?);";
ps = conn.prepareStatement(sql);
}
@Override
public void invoke(Student value, Context context) throws Exception {
//设置?占位符参数值
ps.setString(1,value.getName());
ps.setInt(2,value.getAge());
//执行sql
ps.executeUpdate();
}
@Override
public void close() throws Exception {
if(conn != null) conn.close();
if(ps != null) ps.close();
}
}
}
5:Connectors
(1):JDBC
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* Author itcast
* Desc 演示Flink官方提供的JdbcSink
*/
public class JDBCDemo {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<Student> studentDS = env.fromElements(new Student(null, "tony2", 18));
//TODO 2.transformation
//TODO 3.sink
studentDS.addSink(JdbcSink.sink(
"INSERT INTO `t_student` (`id`, `name`, `age`) VALUES (null, ?, ?)",
(ps, value) -> {
ps.setString(1, value.getName());
ps.setInt(2, value.getAge());
}, new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/bigdata")
.withUsername("root")
.withPassword("root")
.withDriverName("com.mysql.jdbc.Driver")
.build()));
//TODO 4.execute
env.execute();
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Student {
private Integer id;
private String name;
private Integer age;
}
}
(2):kafka
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class Demo01_consumer {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
//准备kafka连接参数
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.234.129:9092");//集群地址
props.setProperty("group.id", "flink");//消费者组id
props.setProperty("auto.offset.reset","latest");//latest有offset记录从记录位置开始消费,没有记录从最新的/最后的消息开始消费 /earliest有offset记录从记录位置开始消费,没有记录从最早的/最开始的消息开始消费
props.setProperty("flink.partition-discovery.interval-millis","5000");//会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测
props.setProperty("enable.auto.commit", "true");//自动提交(提交到默认主题,后续学习了Checkpoint后随着Checkpoint存储在Checkpoint和默认主题中)
props.setProperty("auto.commit.interval.ms", "2000");//自动提交的时间间隔
//使用连接参数创建FlinkKafkaConsumer/kafkaSource
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("topic01", new SimpleStringSchema(), props);
//使用kafkaSource
DataStream<String> kafkaDS = env.addSource(kafkaSource);
//TODO 2.transformation
//TODO 3.sink
kafkaDS.print();
//TODO 4.execute
env.execute();
}
}
(3):kafka_sink
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.Properties;
public class Demo02_consumer_sink {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
//准备kafka连接参数
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.234.129:9092");//集群地址
props.setProperty("group.id", "flink");//消费者组id
props.setProperty("auto.offset.reset","latest");//latest有offset记录从记录位置开始消费,没有记录从最新的/最后的消息开始消费 /earliest有offset记录从记录位置开始消费,没有记录从最早的/最开始的消息开始消费
props.setProperty("flink.partition-discovery.interval-millis","5000");//会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测
props.setProperty("enable.auto.commit", "true");//自动提交(提交到默认主题,后续学习了Checkpoint后随着Checkpoint存储在Checkpoint和默认主题中)
props.setProperty("auto.commit.interval.ms", "2000");//自动提交的时间间隔
//使用连接参数创建FlinkKafkaConsumer/kafkaSource
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("topic01", new SimpleStringSchema(), props);
//使用kafkaSource
DataStream<String> kafkaDS = env.addSource(kafkaSource);
//TODO 2.transformation
SingleOutputStreamOperator<String> etlDS = kafkaDS.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.contains("success");
}
});
//TODO 3.sink
etlDS.print();
Properties props2 = new Properties();
props2.setProperty("bootstrap.servers", "192.168.234.129:9092");
FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>("topic04", new SimpleStringSchema(), props2);
etlDS.addSink(kafkaSink);
//TODO 4.execute
env.execute();
}
}
//控制台生成者 ---> flink_kafka主题 --> Flink -->etl ---> flink_kafka2主题--->控制台消费者
//准备主题 /export/server/kafka/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 2 --partitions 3 --topic flink_kafka
//准备主题 /export/server/kafka/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 2 --partitions 3 --topic flink_kafka2
//启动控制台生产者发送数据 /export/server/kafka/bin/kafka-console-producer.sh --broker-list node1:9092 --topic flink_kafka
//log:2020-10-10 success xxx
//log:2020-10-10 success xxx
//log:2020-10-10 success xxx
//log:2020-10-10 fail xxx
//启动控制台消费者消费数据 /export/server/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic flink_kafka2 --from-beginning
//启动程序FlinkKafkaConsumer
//观察控制台输出结果
(4):redis
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
import org.apache.flink.util.Collector;
public class Demo01_redis {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<String> lines = env.socketTextStream("node1", 9999);
//TODO 2.transformation
SingleOutputStreamOperator<Tuple2<String, Integer>> result = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] arr = value.split(" ");
for (String word : arr) {
out.collect(Tuple2.of(word, 1));
}
}
}).keyBy(t -> t.f0).sum(1);
//TODO 3.sink
result.print();
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("127.0.0.1").build();
RedisSink<Tuple2<String, Integer>> redisSink = new RedisSink<Tuple2<String, Integer>>(conf,new MyRedisMapper());
result.addSink(redisSink);
//TODO 4.execute
env.execute();
}
public static class MyRedisMapper implements RedisMapper<Tuple2<String, Integer>>{
@Override
public RedisCommandDescription getCommandDescription() {
//我们选择的数据结构对应的是 key:String("wcresult"),value:Hash(单词,数量),命令为HSET
return new RedisCommandDescription(RedisCommand.HSET,"wcresult");
}
@Override
public String getKeyFromData(Tuple2<String, Integer> t) {
return t.f0;
}
@Override
public String getValueFromData(Tuple2<String, Integer> t) {
return t.f1.toString();
}
}
}
六:高级api

1:flink-window
(1)time
时间窗口根据时间划分窗口,如:每xx分钟统计最近xx分钟的数据
I:基于时间的滑动窗口

II:基于时间的滚动窗口

import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
/**
* Author itcast
* Desc 演示基于时间的滚动和滑动窗口
*/
public class Demo01_window {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<String> lines = env.socketTextStream("192.168.234.129", 9999);
//TODO 2.transformation
SingleOutputStreamOperator<CartInfo> carDS = lines.map(new MapFunction<String, CartInfo>() {
@Override
public CartInfo map(String value) throws Exception {
String[] arr = value.split(",");
return new CartInfo(arr[0], Integer.parseInt(arr[1]));
}
});
//注意: 需求中要求的是各个路口/红绿灯的结果,所以需要先分组
//carDS.keyBy(car->car.getSensorId())
KeyedStream<CartInfo, String> keyedDS = carDS.keyBy(CartInfo::getSensorId);
// * 需求1:每5秒钟统计一次,最近5秒钟内,各个路口通过红绿灯汽车的数量--基于时间的滚动窗口
//keyedDS.timeWindow(Time.seconds(5))
SingleOutputStreamOperator<CartInfo> result1 = keyedDS
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum("count");
// * 需求2:每5秒钟统计一次,最近10秒钟内,各个路口通过红绿灯汽车的数量--基于时间的滑动窗口
SingleOutputStreamOperator<CartInfo> result2 = keyedDS
//of(Time size, Time slide)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.sum("count");
//TODO 3.sink
//result1.print();
result2.print();
/*
nc -lk 9999
1,5
2,5
3,5
4,5
*/
//TODO 4.execute
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class CartInfo {
private String sensorId;//信号灯id
private Integer count;//通过该信号灯的车的数量
public CartInfo(String s, int parseInt) {
this.sensorId = s;
this.count = parseInt;
}
public String getSensorId(){
return this.sensorId;
}
public Integer getCount(){
return this.count;
}
public void setSensorId(String sensorId){
this.sensorId = sensorId;
}
public void setCount(Integer count){
this.count = count;
}
}
}
(2)count
I:基于数量的滑动窗口
II:基于数量的滚动窗口
数量窗口,根据数量划分窗口,如:每xx个数据统计最近xx个数据
package cn.itcast.window;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* Author itcast
* Desc 演示基于数量的滚动和滑动窗口
*/
public class WindowDemo_3_4 {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<String> lines = env.socketTextStream("node1", 9999);
//TODO 2.transformation
SingleOutputStreamOperator<CartInfo> carDS = lines.map(new MapFunction<String, CartInfo>() {
@Override
public CartInfo map(String value) throws Exception {
String[] arr = value.split(",");
return new CartInfo(arr[0], Integer.parseInt(arr[1]));
}
});
//注意: 需求中要求的是各个路口/红绿灯的结果,所以需要先分组
//carDS.keyBy(car->car.getSensorId())
KeyedStream<CartInfo, String> keyedDS = carDS.keyBy(CartInfo::getSensorId);
// * 需求1:统计在最近5条消息中,各自路口通过的汽车数量,相同的key每出现5次进行统计--基于数量的滚动窗口
SingleOutputStreamOperator<CartInfo> result1 = keyedDS
.countWindow(5)
.sum("count");
// * 需求2:统计在最近5条消息中,各自路口通过的汽车数量,相同的key每出现3次进行统计--基于数量的滑动窗口
SingleOutputStreamOperator<CartInfo> result2 = keyedDS
.countWindow(5,3)
.sum("count");
//TODO 3.sink
//result1.print();
/*
1,1
1,1
1,1
1,1
2,1
1,1
*/
result2.print();
/*
1,1
1,1
2,1
1,1
2,1
3,1
4,1
*/
//TODO 4.execute
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class CartInfo {
private String sensorId;//信号灯id
private Integer count;//通过该信号灯的车的数量
}
}
(3):基于window session
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class Demo02_window_session {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<String> lines = env.socketTextStream("192.168.234.129", 9999);
//TODO 2.transformation
SingleOutputStreamOperator<CartInfo> carDS = lines.map(new MapFunction<String, CartInfo>() {
@Override
public CartInfo map(String value) throws Exception {
String[] arr = value.split(",");
return new CartInfo(arr[0], Integer.parseInt(arr[1]));
}
});
//注意: 需求中要求的是各个路口/红绿灯的结果,所以需要先分组
//carDS.keyBy(car->car.getSensorId())
KeyedStream<CartInfo, String> keyedDS = carDS.keyBy(CartInfo::getSensorId);
//需求:设置会话超时时间为10s,10s内没有数据到来,则触发上个窗口的计算(前提是上一个窗口得有数据!)
SingleOutputStreamOperator<CartInfo> result = keyedDS.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
.sum("count");
//TODO 3.sink
result.print();
/*
1,1
1,1
2,1
2,1
*/
//TODO 4.execute
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class CartInfo {
private String sensorId;//信号灯id
private Integer count;//通过该信号灯的车的数量
public CartInfo(String s, int parseInt) {
this.sensorId = s;
this.count = parseInt;
}
public String getSensorId(){
return this.sensorId;
}
public Integer getCount(){
return this.count;
}
public void setSensorId(String sensorId){
this.sensorId = sensorId;
}
public void setCount(Integer count){
this.count = count;
}
}
}
2:flink-time和watermark
(1):Time分类
flink流式处理,涉及到时间不同概念
事件时间EventTime:事件真正发生的时间
摄入时间IngeestionTIme:事件到达flink时间
处理时间processTIme:事件被处理的计算的时间
3:flink状态管理
4:flink容错机制

若有收获,就点个赞吧
0 人点赞
