SHIRO自述文档
基于liblrhsmm的音位-语音对齐工具包
使用C及Lua荣誉出品。以GPLv3发布。
简介
SHIRO是一系列基于HSMM(隐半马尔可夫模型)的工具,用于将音位转写与语音录音对齐,以及训练音位-语音对齐模型。
收集数小时计带有音位转写的语音数据在如今大多数训练语音识别器与合成器的方式中是重要的先决条件。通常此任务使用隐马尔可夫模型由名为强制对齐的操作自动化执行,特别是从90年代中期起,HTK软件包已成为语音识别与对齐的标准。
SHIRO提供了与HTK相比许可证更宽松的轻量替代品。它类似于仅进行音位-语音对齐的精简版本,并配备了HSMM以及从零开始以几千行坚实的C代码(加上一点Lua)编写。
一点历史
SHIRO是liblrhsmm的姊妹项目,其首个版本于2015年夏季被开发。SHIRO初为liblrhsmm的一部分,后并入Moresampler。转变为工具包前,SHIRO仅支持flat-start训练,因此得名SHIRO(日语中含义为“白色”)。
HSMM入门
要使用SHIRO,有一些对隐半马尔可夫模型基础概念的理解比较好。
一种理解HSMM的方式为通过马里奥类比。我们有一个带有平面地图及顶部一排问号砖块的超级马里奥设定,

假如说每块砖块含有一枚不同的隐藏物品,可能是金币也可能是蘑菇。前几块砖块中隐藏的物品为金币的可能性更大而后几块中蘑菇的可能性更大。
马里奥每次向右行走随机步数后跳起撞击一块砖块,该砖块将释放一枚物品。

现在的问题为,马里奥已经从左到右走完此地图,我们获得了一些砖块释放的物品(按原始顺序),我们能否推断马里奥都在何处跳跃?
这就是我们处理的典型类型HSMM问题。我们基本上是要将一序列物品与一序列可能的起跳位置对齐。
在音位-语音对齐的语境下,马里奥在一排时长未知的音位间跳跃,当他穿过一个音位时,某种音位发音的声波会被发出。我们已知所有的音位,并拥有全部声音文件。问题为定位每一音位起始及终止的位置。
HSMM用以描述此问题的方法论为:每一跳跃间隔是一个隐藏状态,在一个状态中会根据某种与状态关联的概率分布发出一个输出。一个状态的时长亦受一个概率分布调控。我们可以做两件事:
- 干涉。已知输出序列及状态序列,确定每一状态起始/终止的最可能时间。
- 训练。已知输出序列、状态序列及关联的时间序列,寻找调控状态时长及输出发出的概率分布。
语音作为连续过程,必须被切割为短段以契合HSMM模式。这在特征提取阶段进行,即分析输入语音并每5或10毫秒提取一次特征。特征是描述输入在特定时刻听觉特性的浓缩数据。并且由于许多音位的丰富时间结构超出单一状态所能描述,实践中音位与状态并非一对一对应。通常对每一音位分配3至5个状态。
组件
SHIRO由下列工具构成,
| 工具 | 描述 | 输入 | 输出 |
|---|---|---|---|
shiro-mkhsmm |
模型创建工具 | 模型配置 | 模型 |
shiro-init |
模型初始化工具 | 模型、分段 | 模型 |
shiro-rest |
模型重估算(即训练)工具 | 模型、分段 | 模型 |
shiro-align |
对齐器(使用训练后模型) | 模型、分段 | 分段(更新后) |
shiro-untie |
解开单声模型的工具 | 模型、分段 | 模型、分段 |
shiro-wav2raw |
将.wav转换为浮点二进制大型对象的工具 |
.wav文件 |
.raw文件 |
shiro-xxcc |
简易倒频谱参数提取器 | .raw文件 |
参量文件 |
shiro-fextr.lua |
特征提取器包装器 | 目录 | 参量文件 |
shiro-mkpm.lua |
创建音位映射的工具 | 音位列 | 音位映射 |
shiro-pm2md.lua |
从音位映射创建模型定义的工具 | 音位映射 | 模型定义 |
shiro-mkseg.lua |
从.csv表创建分段文件的工具 |
.csv文件 |
分段 |
shiro-seg2lab.lua |
将分段文件转换为Audacity标签的工具 | 分段 | Audacity标签文件 |
shiro-lab2seg.lua |
将Audacity标签转换为分段文件的工具 | Audacity标签文件, .csv索引 | 分段 |
shiro-wavsplit.lua |
用于发声级分段的Lua脚本 | .wav文件 |
分段、Audacity标签文件、模型 |
以-h参数运行以查看用法。
编译
依赖库只有ciglet和liblrhsmm。你还需要lua(版本5.1或以上)或luajit。无需第三方lua库(包括已包含在external/中的)。
cd进ciglet,运行make single-file。这会在ciglet/single-file/下创建ciglet.h和ciglet.c。将此目录复制并重命名至shiro/external/ciglet。- 将
liblrhsmm放置在shiro/external/下并从shiro/external/liblrhsmm/运行make。 - 最后从
shiro/运行make。
供参考,路径结构应当类似于
shiro/external/ciglet/ciglet.hciglet.c
liblrhsmm/- 一堆
.c和.h Makefile、LICENSE、readme.md等等external/、test/、build/
- 一堆
cJSON/dkjson.lua、getopt.lua等等
开始使用
以下节包含基于CMU Arctic语音数据库的示例。
创建美式英语的模型及Arpabet音位定义
整个架构事实上与语言无关(由于音位与特征的匹配为数据驱动的)。
因而,要在选定的任何语言上使用SHIRO,替换arpabet-phoneset.csv为另一音素列表即可。
lua shiro-mkpm.lua examples/arpabet-phoneset.csv \-s 3 -S 3 > phonemap.jsonlua shiro-pm2md.lua phonemap.json \-d 12 > modeldef.json
使用训练后模型对齐音位与语音
第一步:特征提取。输入声波被下采样至16000赫兹采样率,然后带有一阶及二阶差分的12阶梅尔倒频谱系数被提取。
lua shiro-fextr.lua index.csv \-d "../cmu_us_bdl_arctic/orig/" \-x ./extractors/extractor-xxcc-mfcc12-da-16k -r 16000
第二步:从索引文件建立伪分段。
lua shiro-mkseg.lua index.csv \-m phonemap.json \-d "../cmu_us_bdl_arctic/orig/" \-e .param -n 36 -L sil -R sil > unaligned.json
第三步:由于HSMM的搜索空间较HMM大一个数量级,从基于HMM的强制对齐开始并在缩减后搜索空间内使用HSMM更有效。运行HSMM训练时,SHIRO默认应用此缩减。虽然会减慢运行速度,但可能仍需要增加一点搜索空间(-p 10 -d 50)以规避狭窄搜索空间引发的对齐错误。选定p的经验规则为将文件中平均状态数目乘0.1。例如,若平均音频文件含有30个音位且每个音位有5个状态,p应当为30 5 0.1 = 15。如果直接从HSMM进行对齐,此因子会在0.2上下。
./shiro-align \-m trained-model.hsmm \-s unaligned.json \-g > initial-alignment.json./shiro-align \-m trained-model.hsmm \-s initial-alignment.json \-p 10 -d 50 > refined-alignment.json
最后一步:转换精校的分段为标签文件。
lua shiro-seg2lab.lua refined-alignment.json -t 0.005
.txt标签文件将在../cmu_us_bdl_arctic/orig/下被创建。
已知语音与音位转写训练模型
(假定特征提取已完成)
第一步:创建空模型。
./shiro-mkhsmm -c modeldef.json > empty.hsmm
第二步:初始化模型(flat start初始化方案)。
lua shiro-mkseg.lua index.csv \-m phonemap.json \-d "../cmu_us_bdl_arctic/orig/" \-e .param -n 36 -L sil -R sil > unaligned-segmentation.json./shiro-init \-m empty.hsmm \-s unaligned-segmentation.json \-FT > flat.hsmm
第三步:使用HMM训练算法引导/预训练并相应地更新对齐。
./shiro-rest \-m flat.hsmm \-s unaligned-segmentation.json \-n 5 -g > markovian.hsmm./shiro-align \-m markovian.hsmm \-s unaligned-segmentation.json \-g > markovian-segmentation.json
最后一步:使用HSMM训练算法训练模型。
./shiro-rest \-m markovian.hsmm \-s markovian-segmentation.json \-n 5 -p 10 -d 50 > trained.hsmm
使用SPTK替代shiro-xxcc
SHIRO的特征文件与SPTK生成的二进制大型对象二进制兼容,从而允许用户试验大量shiro-xxcc不支持的特征类型。使用SPTK提取MFCC的一个示例为extractors/extractor-sptk-mfcc12-da-16k.lua,
return function (try_excute, path, rawfile)local mfccfile = path .. ".mfcc"local paramfile = path .. ".param"try_execute("frame -l 512 -p 80 \"" .. rawfile .. "\" | " .."mfcc -l 512 -m 12 -s 16 > \"" .. mfccfile .. "\"")try_execute("delta -l 12 -d -0.5 0 0.5 -d 0.25 0 -0.5 0 0.25 \"" ..mfccfile .. "\" > \"" .. paramfile .. "\"")end
任何输入rawfile并输出.param文件的Lua文件都可以。
注意:即使配置相同,也不保证从shiro-xxcc生成的参量匹配SPTK的结果。
进阶主题
可跳过音素
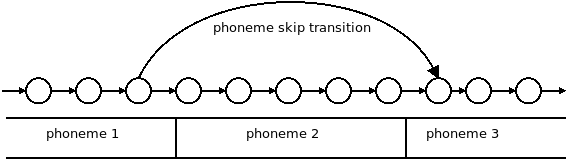
在特定情况下在语音及其音素转写间可能存在轻微不匹配。最常见的情况之一为在单词或词组间插入停顿。要纠正此不匹配,可以在每个单词及词组边界处加入一个停顿音素(例如Arpabet中的“pau”),并通过在音位映射中指定0与1之间的跳过概率使此音素可跳过,
..."pau":{"pskip":0.5,"states":[{"dur":0,"out":[0,0,0]},{"dur":1,"out":[1,1,1]},{"dur":2,"out":[2,2,2]},{
此后一旦其出现在分段文件中,shiro-mkseg.lua将穿越音位“pau”中全部状态加入跳过过渡。跳过过渡可被可视化为,
可替代音位内拓扑
单一音位内的状态亦可通过拓扑指定跳过,如,
..."pau":{"topology":"type-b","states":[{"dur":0,"out":[0,0,0]},{"dur":1,"out":[1,1,1]},{"dur":2,"out":[2,2,2]},{
默认拓扑为type-a,即完全不存在跳过,在大多数情况下此选项运行良好。
其他选项包括
- type-b
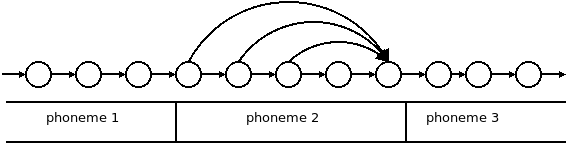
- type-c

- skip-boundary

DAEM训练
DAEM(DorAEMon Deterministic Annealing Expectation-Maximization,确定性退火最大期望算法)是一个修改版本的标准HSMM训练算法。在DAEM训练中,对数概率根据一个在循环中从0逐渐收敛至1的温度系数缩放。据文献报告,DAEM提升flat-start训练HMM语音识别系统的准确性。
要为shiro-rest启用DAEM,只需增加-D选项。显示的对数相似度将按照温度被调整。

若有收获,就点个赞吧
0 人点赞
