一、计算机系统
计算机系统由硬件、软件组成;
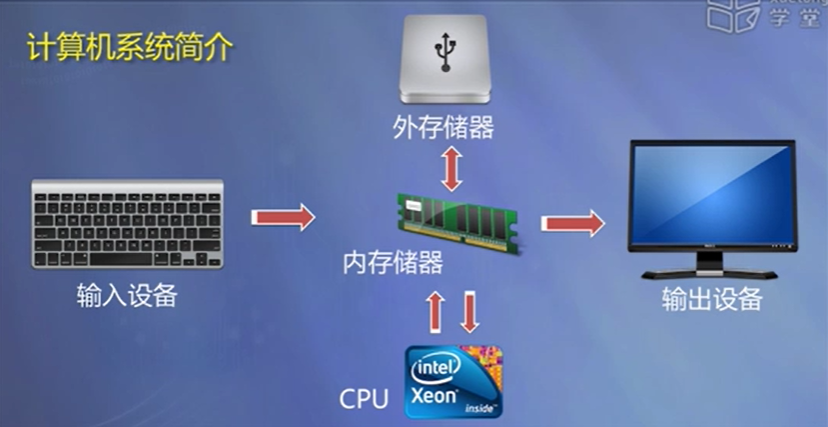
输入、输出、 内存储、外存储、CPU(GPU)
指令系统是硬件和软件的界面
计算机能识别的只能是机器语言,就是0和1编码的。
机器硬件能够识别的语言(机器语言)的集合就是这个计算机的指令系统
计算机软件:(软件 = 程序+文档)
- 应用软件
- 系统软件
- 中间件 : 提供系统软件和应用软件之间链接的软件 (大型软件开发需要)
二、计算机语言和程序设计方法
计算机语言(程序)
程序员与计算机沟通的语言
描述解决问题的方法和相关数据
计算机解决问题是程序控制的
程序就是操作步骤 - 指令的序列
程序要使用语言来表达
计算机语言的级别
二进制代码构成的机器语言;
由二进制代码构成
计算机硬件可以识别
可以表示简单的操作
例如:加法、减法、数据移动等等使用助记符的汇编语言;
将机器指令映射为助记符
如ADD、SUB、MOV等;
抽象层次低,需要考虑机器细节。使用类似英语单词和语句的高级语言;
关键字、语句容易理解;
有含义的数据命名和算式;
抽象层次较高;
例如,算式:a+b+c/d
屏蔽了机器的细节;
例如,这样显示计算结果:std::cout<<a+b+c/dC++是面向对象的高级语言
l 支持面向对象的观点和方法
将客观事物看做对象
对象间通过消息传送进行沟通
支持分类和抽象
(C++支持的)程序设计方法
- 面向过程的程序设计方法;
最初目的:数学计算
主要用于设计求解问题的过程
- 面向对象的程序设计方法;
由面向对象的高级语言支持;
一个系统由对象构成;
对象之间通过消息进行通信。 - 泛型程序设计方法。
三、面向对象的基本概念 Object Oriented
面向对象的方法就是利用抽象、封装等机制,借助于对象、类、继承、消息传递等概念进行软件系统构造的软件开发方法。
对象 Object
l 一般意义上的对象:现实世界中实际存在的事物。
l 面向对象方法中的对象:程序中用来描述客观事物的实体。
抽象与分类 Abstraction
l 分类依据的原则——抽象;
l 抽象出同一类对象的共同属性和行为形成类;
l 类与对象是类型与实例的关系。
封装 Encapsulation
l 隐蔽对象的内部细节;
l 对外形成一个边界;
l 只保留有限的对外接口;
l 使用方便、安全性好。
类 Class
l 类是具有相同特性(数据元素)和行为(功能)的对象的抽象。
l 类的属性是对象的状态的抽象,类的操作是对象行为的抽象。
l 类实际上就是一种数据类型
继承 Inheritance
l 意义在于软件复用;
l 改造、扩展已有类形成新的类。
多态 Polymorphism
l 同样的消息作用在不同对象上,可以引起不同的行为。
l 怎加软件的灵活和重用性。
比如说 动态绑定:将一个过程调用与相应代码链接起来的行为。动态绑定是指与给定的过程调用相关联的代码只有在运行期才可知的一种绑定,它是多态实现的具体形式。
消息传递
对象之间需要相互沟通,沟通的途径就是对象之间收发信息。消息内容包括接收消息的对象的标识,需要调用的函数的标识,以及必要的信息。消息传递的概念使得对现实世界的描述更容易。
四、C++程序的开发过程
程序的三个阶段:
源程序:用源语言写的,有待翻译的程序;
目标程序:源程序通过翻译程序加工以后生成的机器语言程序;
可执行程序:连接目标程序以及库中的某些文件,生成的一个可执行文件;
三种不同类型的翻译程序
汇编程序:将汇编语言源程序翻译成目标程序;
编译程序:将高级语言源程序翻译成目标程序;
解释程序:将高级语言源程序翻译成机器指令,边翻译边执行。(JVM的JAVA字节码)
程序开发过程
- DSA设计
- 源程序编辑
- 编译器:
- 编译预处理
- 语法检查
- 编译
- 连接
- 测试
- 调试
五、信息在计算机中的表示与存储
- 计算机中的数据用二进制表示;
- 逻辑数据、字符数据用二进制编码表示。
计算机的基本功能
算术运算
逻辑运算
计算机中的信息
一般来说,下图对应内置类型:int(定点数)double(浮点数)char(字符)bool(逻辑)。但是不要忽略还有一类
复合类型数组和指针。
 这里的数值信息其实只包含实数和整数。定点数指的是小数点位置确定,浮点数相反。计算机通常是采用浮点方式表示小数。
这里的数值信息其实只包含实数和整数。定点数指的是小数点位置确定,浮点数相反。计算机通常是采用浮点方式表示小数。
实数 N 用浮点形式可表示为: N=M×2E
E:2的幂,N:阶码;
M:N的尾数。
字符在计算机中的表示
l 字符在计算机中是通过编码表示的, 例如:
- ASCII码是一种常用的西文字符编码:用7位二进制数表示一个字符,最多可以表示27=128个字符; (上个世纪60年代,美国制定)这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
- 非ASCII码 : 低7位与ASCII一样,剩下128-255字段是各自不同国家的符号
- 《GB 18030-2005 信息技术 中文编码字符集》是中国国家标准。
- 简体中文常见的编码方式是 GB2312:使用两个字节表示一个汉字,所以理论上最多可以表示 256 x 256 = 65536 个符号。虽然都是用多个字节表示一个符号,但是GB类的汉字编码与后文的 Unicode 和 UTF-8 是毫无关系的。Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。UTF-8 是 Unicode 的实现方式之一。
- 针对上一点:
Unicode符号范围 | UTF-8编码方式(十六进制) | (二进制)--------------------+----------------------------------------0000 0000-0000 007F | 0xxxxxxx0000 0080-0000 07FF | 110xxxxx 10xxxxxx0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
更多见:http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
计算机中数据的单位
l 位(bit,b):数据的最小单位,表示一位二进制信息;
l 字节(byte,B):八位二进制数字组成(1 byte = 8 bit);
l 千字节 1 KB = 1024 B;
l 兆字节 1 MB = 1024 K;
l 吉字节 1 GB = 1024 M。
所以 1GB = 2 B , 两边同时除去单位B,得到1G = 2 ≈ 10 = 十亿。
数字系统与进制
| 进制 | R(基数) | 进位原则 | 基本符号 |
|---|---|---|---|
| 二进制 | 2 | 逢2进1 | 0,1 |
| 八进制 | 8 | 逢8进1 | 0,1,2,3,4,5,6,7,8 |
| 十进制 | 10 | 逢10进1 | 0,1,2,3,4,5,6,7,8,9 |
| 十六进制 | 16 | 逢16进1 | 0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F |
R进制转化为十进制
各位数字与它的权相乘,其积相加,例如R =2:
(11111111.11) =1×2+1×2+1×2+1×2+1×2+1×2+1×2+1×2+1×2+1×2 =(255.75)
十进制整数转换为R 进制整数和小数
“除以R取余”法。 “乘 以R 取整”法。以R=2为例
| < | —— | —— | . | —— | —— | —— | > |
|---|---|---|---|---|---|---|---|
| ÷R | 十进制整数 | 余数 | . | 十制小数 | ×R | 结果整数部 | 结果小数部 |
| 2 | 68 | 0 | . | 0.3125 | 2 | 0 | .625 |
| 2 | 34 | 0 | . | 0.625 | 2 | 1 | .25 |
| 2 | 17 | 1 | . | 0.25 | 2 | 0 | .5 |
| 2 | 8 | 0 | . | 0.5 | 2 | 1 | .0 |
| 2 | 4 | 0 | . | > | |||
| 2 | 2 | 0 | . | ||||
| 2 | 1 | 1 | . | ||||
| 2 | 0 | < | . |
68.3125 = 1000100.0101
八、十六进制与二进制的互相转化
非常直观不用十进制那么复杂。
(1011010.10)=(001 011 010 .100)=(132.4)
(1011010.10)=(0101 1010 .1000)=(5A.8)
(F7)=(1111 0111)=(11110111)
编码(针对signed数而言)
宽泛来理解:R其实就是模数 module, 取模就是除以R取余数 — mod操作。
当R = 12 的时候,记作 (mod12),有以下等式:
-3 ≡ +9(mod12)
-4 ≡ +8(mod12)
(-2) = 10 (mod12)
8 + (-2) = 8 + 10 (mod 12) = 6
一个数加上一个负数等于它加上负数的补数(把减法转化为加法)
更多请看:
原码-反码-补码
第2章主要内容和教学要求
六、C++历史
l C++最早叫做C with Class 。是在C的基础上发展的。
l 1983年正式取名为C++;
l 1998年11月被国际标准化组织(ISO)批准为国际标准;
l 2003年10月15日发布第2版C++标准ISO/IEC 14882:2003;
l 2011年8月12日ISO公布了第三版C标准C11,包含核心语言的新机能、扩展C++标准程序库。
l 2014年8月18日ISO公布了C14,其正式名称为”International Standard ISO/IEC 14882:2014(E) Programming Language C”。
l C14作为C11的一个小扩展,主要提供漏洞修复和小的改进。
l C++17
l C++20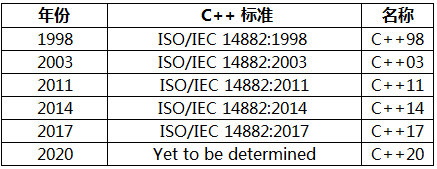
C++的特性
- 完全兼容C ,所以可以面向过程编写
- 支持面向对象
- 支持泛型
七、语言构词
C++字符集
大小写的英文字母:A~Z 、 a~z
数字字符:0-9
特殊字符:
C++构词法(词法记号)
- 关键字 (保留字) C++预定义的单词 详情
- 标识符 程序员声明的单词,它命名程序正文中的一些实体
- l 以大写字母、小写字母或下划线()
开始。(不能是数字)
l 可以由以**大写字母、小写字母、下划线()或数字0~9**组成。
l 大写字母和小写字母代表不同的标识符。(大小写敏感)
l 不能是C++关键字或操作符。
- l 以大写字母、小写字母或下划线()
- 文字(字面量) 在程序中直接使用符号表示的数据
- 分隔符() {} , : ;
用于分隔各个词法记号或程序正文 - 运算符(操作符) 用于实现各种运算的符号
- 空白符 空格、制表符(TAB键产生的字符)、垂直制表符、换行符、回车符和注释的总称
一个空格等于多个空格等于制表符等于回车
八、C++能够处理的基本数据类型
l 整数类型;l 浮点数类型;l 字符类型;l 布尔类型。
整数类型
l 基本的整数类型:int
l 按符号分
n 符号的(signed)n 无符号的(unsigned)
l 按照数据范围分
n 短整数(short)n 长整数(long)n 长长整数( long long )
l ISO C++标准并没有明确规定每种数据类型的字节数和取值范围,它只是规定它们之间的字节数大小顺序满足:(具体要看编译器)
(signed/unsigned)signed char ≤(unsigned) short int ≤(unsigned) int ≤(unsigned) long int ≤ long long int
为解决这个问题出现了(ps 也可以用Sizeof来计算当前变量类型所占多少字节)
int_t同类:
int_t 为一个结构的标注,可以理解为type/typedef的缩写,表示它是通过typedef定义的,而不是一种新的数据类型。因为跨平台,不同的平台会有不同的字长,所以利用预编译和typedef可以最有效的维护代码。
- int8_t : typedef signed char;
- uint8_t : typedef unsigned char;
- int16_t : typedef signed short ;
- uint16_t : typedef unsigned short ;
- int32_t : typedef signed int;
- uint32_t : typedef unsigned int;
- int64_t : typedef signed long long;
- uint64_t : typedef unsigned long long; | Specifier | Common Equivalent | Signing | Bits | Bytes | Minimum Value | Maximum Value | | —- | —- | —- | —- | —- | —- | —- | | int8_t | signed char | Signed | 8 | 1 | -128 | 127 | | uint8_t | unsigned char | Unsigned | 8 | 1 | 0 | 255 | | int16_t | short | Signed | 16 | 2 | -32,768 | 32,767 | | uint16_t | unsigned short | Unsigned | 16 | 2 | 0 | 65,535 | | int32_t | int | Signed | 32 | 4 | -2,147,483,648 | 2,147,483,647 | | uint32_t | unsigned int | Unsigned | 32 | 4 | 0 | 4,294,967,295 | | int64_t | long long | Signed | 64 | 8 | -9,223,372,03-6,854,775,808 | 9,223,372,03-6,854,775,807 | | uint64_t | unsigned long long | Unsigned | 64 | 8 | 0 | 18,446,744,07-3,709,551,615 |
size_t和ssize_t
size_t主要用于计数,如sizeof函数返回值类型即为size_t。在不同位的机器中所占的位数也不同,size_t是无符号数,ssize_t是有符号数。
在32位机器中定义为:typedef unsigned int size_t; (4个字节)
在64位机器中定义为:typedef unsigned long size_t;(8个字节)
由于size_t是无符号数,因此,当变量有可能为负数时,必须使用ssize_t。因为当有符号整型和无符号整型进行运算时,有符号整型会先自动转化成无符号。(变成补数了)
int main(){unsigned short a;short int b = -1;a = b;cout << "b=" << b << endl; //b=-1cout << "a=" << a << endl; //a=65535}
此外,int 无论在32位还是64位机器中,都是4个字节, 且带符号。可见size_t与int 的区别之处。
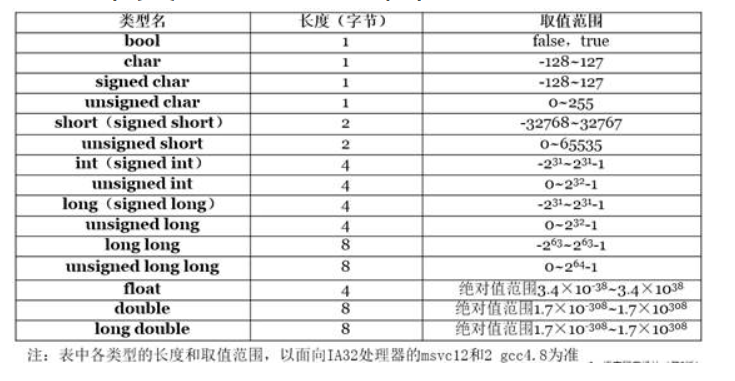
浮点数类型(实数)
l 单精度(float)
l 双精度(double)
l 扩展精度(long double)
字符类型(char)
l 容纳单个字符的编码;
l 实质上存储的也是整数。
字符串类型 详见
基本类型中没有字符串变量 但是有字符串常量
定义:用双引号(“”)括起来的0个或者多个字符组成的序列存储:每个字符串尾自动加一个 ‘\0’ 作为字符串结束标志所以:'A'是char字符类型;而"A"其实是‘A’ +‘\0’ ,是字符串常量
采用字符数组存储字符串(C风格的字符串)
char c[] = {'a','b','c'};const chat * c = "abc" (这个意义上两者是可以互换的)
标准C类库中的String类(C风格的字符串)(容器)
String s;
 尽管C支持C风格字符串,但在C程序中最好不要使用它们。一些用于操作C风格字符串的标准库函数定义在cstring头文件中
尽管C支持C风格字符串,但在C程序中最好不要使用它们。一些用于操作C风格字符串的标准库函数定义在cstring头文件中
strlen(p) ;strcmp(p1,p2) ;strcat(p1,p2) ;strcpy(p1,p2)
布尔类型(bool)
l 只有两个值:true(真) 、false(假)
l 常用来表示关系比较、相等比较或逻辑运算的结果
拓展类型
枚举类型
通过列出所有可取值来定义的一种新类型。可以解决合法性检验问题。
从C继承得到,实际上是int的子集,被叫做弱类型枚举,强类型枚举见 进入
enum Weekday{SUN,MON,TUE,WED,THU,FRI,SAT};//默认情况下 SUN =0 ; MON = 1 ,... ,SAT = 6enum Weekday{SUN=7,MON=1,TUE,WED,THU,FRI,SAT}//手动赋值 MON之后会自增//可以认为 enum是一种整型常量,需要在定义时赋值,之后不可改变。Weekday dayOne;Weekday dayTwo = SUN;enum Weekday dayThree = TUE;
auto
编译器通过初始值自动推断数据类型。
typedef、using
讲已有类型名增加新的类型名(表)
//C styletypedef double Area, Volume;Area a ; Volume b;//C++ styleusing Area = double;using Vloume = double;Area a ; Volume b;
九、程序中的数据
常量
在源程序中直接使用符号(文字)表示的值;其值在整个程序运行期间不可改变。
整数常量
l 以文字形式出现的整数;
l 十进制 DEC
n 若干个0~9的数字,但数字部分不能以0开头,正数前边的正号可以省略。
l 八进制 OCT
n `前导`0+若干个0~7的数字。 比如071 = 111 001
l 十六进制 HEX
n `前导`0x+若干个0F的字母(大小写均可)。 比如0x71 = 0111 0001
l 后缀
n 后缀L(或l)表示类型至少是long,后缀LL(或ll)表示类型是long long,后缀U(或u)表示unsigned类型。
浮点数常量
l 以文字形式出现的实数;
l 一般形式:
n 例如,12.5,-12.5等。
l 指数形式:
n 例如,0.345E+2,-34.4E-3;n 整数部分和小数部分可以省略其一。
l 浮点常量默认为double型,如果后缀F(或f)可以使其成为float型,例如:12.3f。一般我们都用double因为它比float更加优异。
字符常量char
l 单引号括起来的一个字符,如:’a’、’D’、’?’、’$’;
l C++转义字符列表(用于在程序中表示不可显示字符)
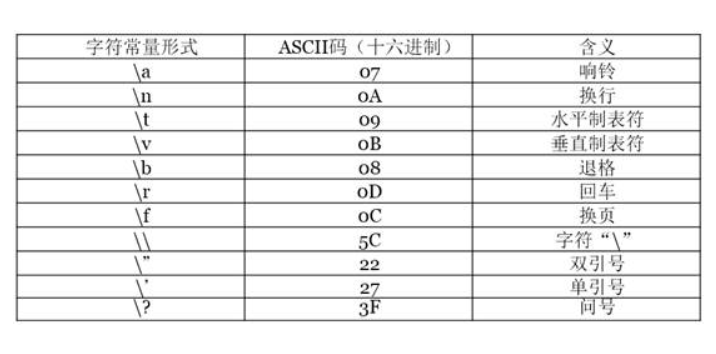
符号常量
l 常量定义语句的形式为:
const 数据类型说明符 常量名=常量值;
或:
数据类型说明符 const 常量名=常量值;
l 例如,可以定义一个代表圆周率的符号常量:
const float PI = 3.1415926;
l 符号常量在定义时一定要初始化,在程序中间不能改变其值。
详见:
数据共享与保护
常量表达式 constexpr
在编译期间进行求值的表达式。
留待讨论
变量
在程序运行过程中允许改变的数据。
初始化
C++语言中提供了多种初始化方式;
int a = 0; //拷贝初始化 - 常量int a(0); //构造初始化 - 常量int a = {0}; //拷贝初始化 - 列表初始化int a{0}; // 构造初始化 - 列表初始化struct A{int x;int y;}a={1,2}; //简单结构体的初始化//C++11中为了统一初始化方式,提出了列表初始化(list-initialization)的概念。
列表初始化时不允许信息的丢失。例如用double值初始化int变量,就会造成数据丢失。其实可以理解列表初始化是传入了一个列表类型std::initializer_list<type> , 比如下面这段代码:
class FooVec{public:std::vector<int> m_vec;FooVec(std::initializer_list<int> list){for (auto it = list.begin(); it != list.end(); it++)m_vec.push_back(*it);}};int _tmain(int argc, _TCHAR* argv[]){FooVec foo1 { 1, 2, 3, 4, 5, 6 };FooVec foo2 { 1, 2, 3, 4, 5, 6, 7, 8, 9 };return 0;}
十、运算
运算类型、运算优先级、结合律、混合运算时的类型转换
运算类型
算术运算、赋值运算、逗号运算符、关系运算符、条件运算符、逻辑运算符,sizeof运算、位运算
算数运算
基本算数运算符 + - * / % ++ --
赋值运算
赋值表达式返回的是左边的值与类型(注意类型与值总是绑定在一起的就像现实世界中数量与单位总是绑定在一起的)所以我们可以说他返回左值
复合赋值运算 += -= *= /= %= <<= >>= &= ^= |=
逗号运算
l 格式
表达式1,表达式2
l 求解顺序及结果
n 先求解表达式1,再求解表达式2
n 最终结果为表达式2的值 (返回表达式2)
l 例
a = 3 5 , a 4 最终结果为60 可以这么看a =( 3 5 , a 4)运算了两次。
关系运算
l 关系表达式是一种最简单的逻辑表达式
逻辑运算 (&& 和 || 具有短路特性)
逻辑运算符
!(非) &&(与) ||(或)
优先次序: 高 → 低
l 逻辑运算结果类型:bool,值只能为 true 或false
l 逻辑表达式
例如:(a > b) && (x > y)
条件运算
l 一般形式
n 表达式1?表达式2:表达式3
表达式1 必须是bool 类型
优先级低于逻辑运算
位运算
按位与 &
用途:
n 将某一位置0,其他位不变。例如:将char型变量a的最低位置0: a = a & 0xfe; ;(0xfe:1111 1110)
n 取指定位。例如:有char c; int a; 取出a的低字节,置于c中:c=a & 0xff; (0xff:1111 1111)
按位或 |
- l 用途:
n 将某些位置1,其他位不变。
例如:将 int 型变量 a 的低字节置 1 :
a = a | 0xff;
- l 用途:
- 按位异或 ^ (相同为0 ,不同为1)
- 用于使特定位翻转(异或一个1)
- 按位取反 ~
- 左移<< 低位补0 高位舍弃。 a << 1 相当于a*2 但是需要注意溢出情况
- 右移 >> 低位舍弃,高位补符号 a << 1 相当于a/2
sizeof运算
特别适用于类类型计算所占空间字节
运算优先级
| 优先级 | 运算符 | 结合性 |
|---|---|---|
| 1 | [ ] ( ) . –> 后置 ++ 后置 – – | 左→右 |
| 2 | 前置 ++ 前置 – – sizeof & * +(正号) –(负号) ~ ! | 右→左 |
| 3 | (强制转换类型) | 右→左 |
| 4 | . -> | 左→右 |
| 5 | * / % | 左→右 |
| 6 | + – | 左→右 |
| 7 | << >> | 左→右 |
| 8 | < > <= >= | 左→右 |
| 9 | == != | 左→右 |
| 10 | & | 左→右 |
| 11 | ^ | 左→右 |
| 12 | | | 左→右 |
| 13 | && | 左→右 |
| 14 | || | 左→右 |
| 15 | ? : | 右→左 |
| 16 | = *= /= %= += –= <<= >>=&= ^= |= | 右→左 |
| 17 | , | 左→右 |
混合运算时的类型转换
一些二元运算符(算术运算符、关系运算符、逻辑运算符、位运算符和赋值运算符)要求两个操作数的类型一致。
l 在算术运算和关系运算中如果参与运算的操作数类型不一致,编译系统会自动对数据进行转换(即隐含转换),基本原则是将低类型数据转换为高类型数据。

注意char是最低类型的。(因为它只有一个字节,而int在32和64系统中都是4个字节)

l 将一个非布尔类型的算术值赋给布尔类型时,算术值为0则结果为false,否则结果为true。
l 将一个布尔值赋给非布尔类型时,布尔值为false则结果为0,布尔值为true则结果为1
l 将一个浮点数赋给整数类型时,结果值将只保留浮点数中的整数部分,小数部分将丢失。(而不是四舍五入)
l 将一个整数值赋给浮点类型时,小数部分记为0。如果整数所占的空间超过了浮点类型的容量,精度可能有损失。
混合运算时数据类型的转换——显式转换
显式类型转换的作用是将表达式的结果类型转换为类型说明符所指定的类型。
语法形式
n 类型说明符(表达式)
n (类型说明符)表达式
n 类型转换操作符<类型说明符>(表达式) (C++风格)
n 类型转换操作符可以是:const_cast、dynamic_cast、reinterpret_cast、static_cast
l 例:int(z); (int)z,;static_cast(z) ;三种完全等价

若有收获,就点个赞吧
0 人点赞
