导入测试数据
https://gitee.com/UnityAlvin/test/blob/master/accounts.json
导入测试数据。
POST bank/account/_bulk

SearchAPI
以下操作都是在Kibana dev-tools执行
uri+检索参数
请求
通过REST request uri 发送搜索参数
GET bank/_search?q=*&sort=account_number:asc
bank/:bank这个索引下_search:固定格式?:所有的检索条件q=*:查询所有&sort=account_number:asc:按照account_number升序排列
结果
Elasticsearch 默认会返回10条数据
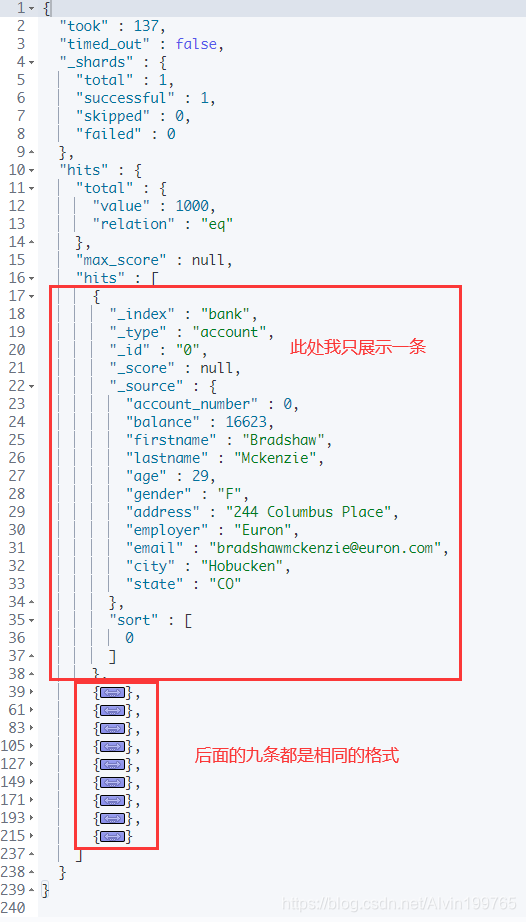
took– Elasticsearch 执行搜索的时间(毫秒)timed_out– 搜索是否超时_shards– 多少个分片被搜索了,以及统计了成功/失败的搜索分片hits.total- 查询到的记录hits.total.value- 表示有多少条记录被匹配到了hits.total.relation- 检索的关系hits.max_score– 最大得分(全文检索用)hits.hits- 实际的搜索结果数组(默认为前 10 的文档)hits.hits._score- 相关性得分(全文检索用)hits.hits.sort- 结果的排序 key(键)(没有则按 score 排序)
uri+请求体
通过REST request body 来发送它们
请求
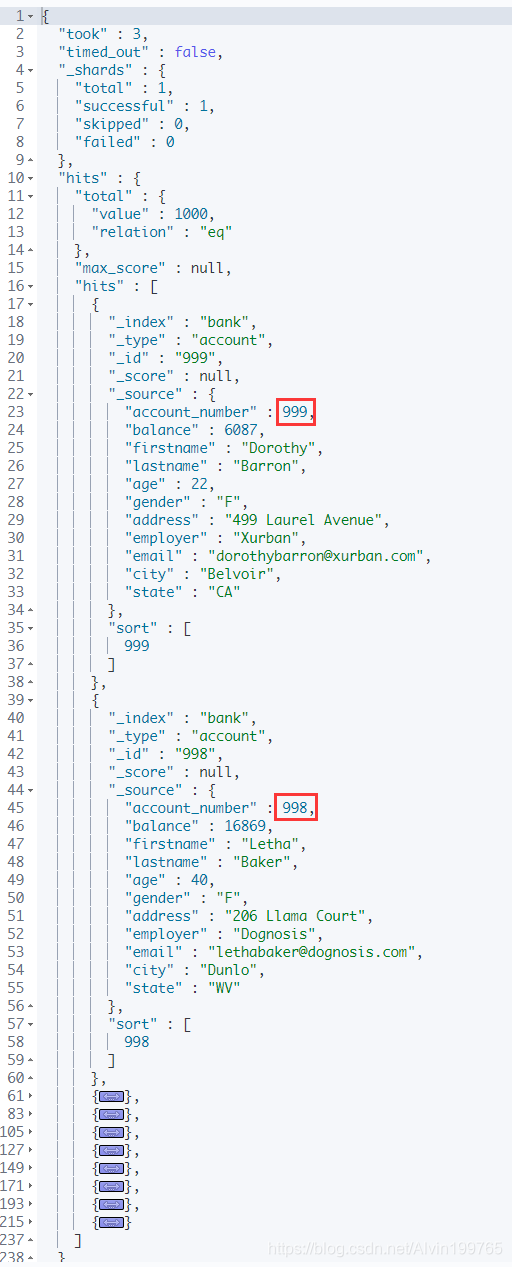
GET bank/_search{"query": {"match_all": {}},"sort": [{"account_number": "desc"}]}
"query":查询条件"match_all":匹配所有的详细规则"sort":排序条件,可以添加多个"account_number": "desc":按照account_number降序排列
结果
Query DSL
Elasticsearch提供了一个可以执行查询的Json风格的DSL(domain-specific language 领域特定语言)。被称为Query DSL,该查询语言非常全面。
基本语法格式
一个查询语句的典型结构:
QUERY_NAME:{ARGUMENT:VALUE,ARGUMENT:VALUE,...}
如果针对于某个字段,那么它的结构如下:
{QUERY_NAME:{FIELD_NAME:{ARGUMENT:VALUE,ARGUMENT:VALUE,...}}}
请求示例:
GET bank/_search{"query": {"match_all": {}},"from": 0,"size": 5,"sort": [{"account_number": {"order": "desc"},"balance": {"order": "asc"}}]}# match_all 查询类型【代表查询所有的所有】,es中可以在query中组合非常多的查询类型完成复杂查询;# from+size 限定,完成分页功能;从第几条数据开始,每页有多少数据# sort 排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准;
返回部分字段
请求
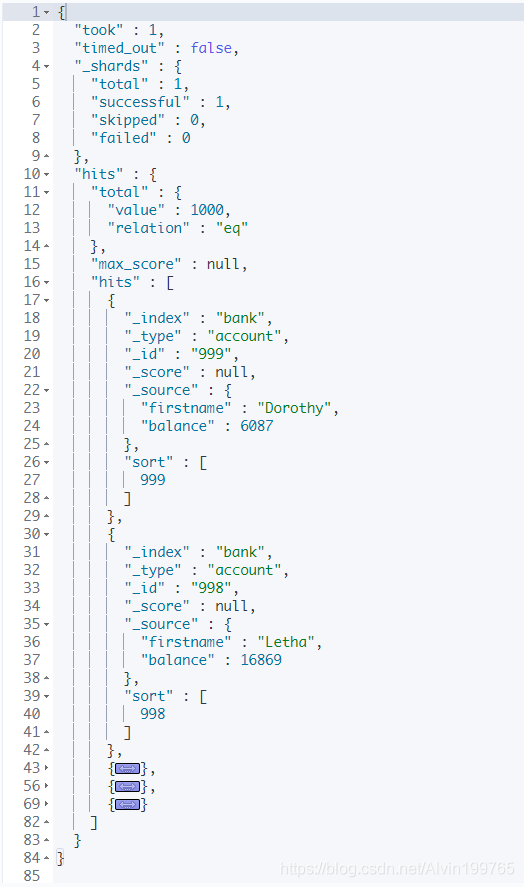
GET bank/_search{"query": {"match_all": {}},"from": 0,"size": 5,"sort": [{"account_number": {"order": "desc"}}],"_source": ["balance","firstname"]}
"_source":查询部分字段"from":从第1条记录开始"size":查询5条记录
结果
match-匹配查询
精确匹配-基本类型(非字符串)
查找 account_number 为 20 的数据 ,建议使用 term 进行检索
GET bank/_search{"query": {"match": {"account_number": 20}}}
精确匹配-字符串
查找 address 为 288 Mill Street 的数据
GET bank/_search{"query": {"match": {"address.keyword": "288 Mill Street"}}}
全文检索-字符串
全文检索,会对检索条件进行分词匹配,最终会按照得分降序排列。
查找 address 包含 mill 或 lane 的数据
GET bank/_search{"query": {"match": {"address": "mill lane"}}}
全文检索-基本类型(非字符串)
GET bank/_search{"query": {"match": {"account_number": "20"}}}
match_phrase-短语匹配
将需要匹配的值当成一个整体(不分词)进行检索
查找 address 包含 mill lane 的数据
GET bank/_search{"query": {"match_phrase": {"address": "mill lane"}}}
multi_math-多字段匹配
查找 city 或 address 包含 mill movico 的数据,会对查询条件分词
GET bank/_search{"query": {"multi_match": {"query": "mill movico","fields": ["city","address"]}}}
bool-复合查询
复合语句可以合并任何其他查询语句,包括复合语句。这就意味着,复合语句之间可以互相嵌套,可以表达非常复杂的逻辑。
查询 address 包含 mill 、 gender 包含 M 、age 不是 18 、lastname 最好包含 Wallace 的数据
GET bank/_search{"query": {"bool": {"must": [{"match": {"address": "mill"}},{"match": {"gender": "M"}}],"must_not": [{"match": {"age": 18}}],"should": [{"match": {"lastname": "Wallace"}}]}}}
"must":必须满足的条件"must_not":必须不满足的条件"should":非必须满足的条件,满足之后可加分
filter-结果过滤
查询 18 <= age <= 30 的数据
GET bank/_search{"query": {"bool": {"filter": {"range": {"age": {"gte": 18,"lte": 30}}}}}}
filter 对结果进行过滤,且不计算相关性得分。
term-精确检索
Elasticsearch 官方对于非文本字段,推荐使用 term 来精确检索。
查找 age 为 28 的数据
GET bank/_search{"query": {"term": {"age": "28"}}}
Aggregation-执行聚合
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于 SQL GROUPBY 和 SQL 聚合函数。在 Elasticsearch 中,您有执行搜索返回 hits(命中结果),并且同时返回聚合结果,把一个响应中的所有 hits(命中结果)分隔开的能力。这是非常强大且有效的,您可以执行查询和多个聚合,并且在一次使用中得到各自的(任何一个的)返回结果,使用一次简洁和简化的 API 来避免网络往返。
语法
"aggs/aggregations" : {"<聚合名称>" : {"<聚合类型>" : {<聚合体的内容>}[,"meta" : { [<meta_data_body>] } ]?[,"aggs/aggregations" : { [<sub_aggregation>]+ } ]?}[,"<聚合2>" : { ... } ]*}
一个aggs中可以有多个同级聚合,如果想在一个聚合里面添加子聚合的话,需要为子聚合单独加个aggs才可以
示例1
# 搜索 address 中包含 mill 的所有人的年龄分布、平均年龄、平均薪资GET bank/_search{"query": {"match": {"address": "mill"}},"aggs": {"ageAgg": {"terms": {"field": "age","size": 10}},"ageAvg":{"avg": {"field": "age"}},"balanceAvg":{"avg": {"field": "balance"}}},"size": 0}
示例2
# 按照年龄聚合,并且求这些年龄段的人的平均薪资GET bank/_search{"query": {"match_all": {}},"aggs": {"ageAggs": {"terms": {"field": "age","size": 100},"aggs": {"balanceAvg": {"avg": {"field": "balance"}}}}},"size": 0}
示例3
# 查出所有年龄分布,并查出这些年龄段中M的平均薪资、F的平均薪资、以及这个年龄段的平均薪资GET bank/_search{"query": {"match_all": {}},"aggs": {"ageAgg": {"terms": {"field": "age","size": 100},"aggs": {"genderAgg": {"terms": {"field": "gender.keyword","size": 10},"aggs": {"genderBalanceAvg": {"avg": {"field": "balance"}}}},"ageBalanceAvg": {"avg": {"field": "balance"}}}}},"size": 0}
Mapping-映射
介绍
Mapping是用来定义一个文档(document),以及它所包含的属性(field)是如何存储和索引的。
比如,使用mapping来定义:
- 哪些字符串属性应该被看做全文本属性(full text fields);
- 哪些属性包含数字,日期或地理位置;
- 文档中的所有属性是否都被索引(all 配置);
- 日期的格式;
- 自定义映射规则来执行动态添加属性;
新版本改变
ElasticSearch7-去掉type概念
- 关系型数据库中两个数据的表示是独立的,即使他们里面有相同名称的列也不影响使用,但ES中不是这样的。elasticsearch是基于Lucene开发的搜索引擎,而ES中不同type下名称相同的filed最终在Lucene中的处理方式是一样
- 两个不同type下的两个user_name,在ES同一个索引下其实被认为是同一个filed,你必须在两个不同的type中定义相同的filed映射。否则,不同type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降。
- 去掉type就是为了提高ES处理数据的效率。
- Elasticsearch 7.x URL中的type参数为可选。比如,索引一个文档不再要求提供文档类型。
- Elasticsearch 8.x 不再支持URL中的type参数。
解决:
- 将索引从多类型迁移到单类型,每种类型文档一个独立索引
- 将已存在的索引下的类型数据,全部迁移到指定位置即可。详见数据迁移
字段类型
核心类型
| 字符串( string ) | text, keyword |
| 数字类型( Numeric ) | long, integer, short, byte, double, float,half_float,scaled_float |
| 日期类型( Date ) | date |
| 布尔类型( Boolean ) | boolean |
| 二进制类型( binary ) | binary |
复合类型
| 数组类型( Array ) | Array支持不针对特定的类型 |
| 对象类型( Object) | object用于单JSON对象 |
| 嵌套类型(Nested ) | nested用于JSON对象数组 |
地理类型(Geo)
| 地理坐标( Geo-points ) | geo_ point用于描述经纬度坐标 |
| 地理图形( Geo-Shape ) | geo_ shape用于描述复杂形状,如多边形 |
特定类型
| IP类型 | ip用于描述ipv4和ipv6地址 |
| 补全类型( Completion ) | completion提供自动完成提示 |
| 令牌计数类型( Token count ) | token_ count 用于统计字符串中的词条数量 |
| 附件类型( attachment ) | 参考mapper-attachements插件,支持将附件如Microsoft Office格式,Open Document格式,ePub, HTML 等等索引为attachment数据类型。 |
| 抽取类型( Percolator ) | 接受特定领域查询语言(query-dsI) 的查询 |
多字段
通常用于为不同目的用不同的方法索引同一个字段。例如,string 字段可以映射为一个text字段用于全文检索,同样可以映射为一个keyword字段用于排序和聚台。另外,你可以使用standard analyzer, english analyzer, french analyzer 来索引一个text字段
这就是muti-fields的目的。大多数的数据类型通过felds参数来支持muti-fields.
映射操作
创建索引映射
创建索引并指定属性的映射规则(相当于新建表并指定字段和字段类型)
PUT /my_index{"mappings": {"properties": {"age": {"type": "integer"},"email": {"type": "keyword"},"name": {"type": "text"}}}}
查看映射
GET my_index/_mapping
为映射添加新的字段
PUT my_index/_mapping{"properties": {"employee-id": {"type": "keyword","index": false}}}
更新映射
对于已经存在的映射字段,我们不能更新。因为一旦修改,会导致相关数据的检索规则发生变化,那样会产生问题,所以想要更新必须要创建新的索引进行数据迁移。
数据迁移
先创建一个新索引,指定好正确的映射关系,使用reindex将数据迁移到新的索引中
1、创建新索引
PUT /newbank{"mappings": {"properties": {"account_number": {"type": "long"},"address": {"type": "text"},"age": {"type": "integer"},"balance": {"type": "long"},"city": {"type": "keyword"} ,"email": {"type": "keyword"},"employer": {"type": "keyword"},"firstname": {"type": "text"},"gender": {"type": "keyword"},"lastname": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"state": {"type": "keyword"}}}}
2、数据迁移
POST _reindex{"source": {"index":"bank","type": "account"},"dest": {"index": "newbank"}}
3、查看结果
GET newbank/_search


若有收获,就点个赞吧
0 人点赞
