简介
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.x/analysis.html
一个tokenizer(分词器)接收一个字符流,将之分割为独立的tokens(词元,通常是独立的单词),然后输出tokens流。
例如:whitespace tokenizer遇到空白字符时分割文本。它会将文本“Quick brown fox!”分割为[Quick,brown,fox!]。
该tokenizer(分词器)还负责记录各个terms(词条)的顺序或position位置(用于phrase短语和word proximity词近邻查询),以及term(词条)所代表的原始word(单词)的start(起始)和end(结束)的character offsets(字符串偏移量)(用于高亮显示搜索的内容)。
elasticsearch提供了很多内置的分词器,可以用来构建custom analyzers(自定义分词器)。
POST _analyze{"analyzer": "standard","text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."}
默认的分词器一般都是针对于英文,对于中文我们需要安装额外的分词器来进行分词。
安装IK分词器
事前准备:
IK 分词器属于 Elasticsearch 的插件,所以 IK 分词器的安装目录是 Elasticsearch 的 plugins 目录,在我们使用Docker启动 Elasticsearch 时,已经将该目录挂载到主机的 /mydata/elasticsearch/plugins 目录。
IK 分词器的版本需要跟 Elasticsearch 的版本对应,当前选择的版本为 7.4.2,下载地址为:Github Release 或访问:镜像地址
1. 下载
# 进入挂载的插件目录 /mydata/elasticsearch/pluginscd /mydata/elasticsearch/plugins# 安装 wget 下载工具(已安装,则跳过)yum install -y wget# 下载对应版本的 IK 分词器(这里是7.4.2)wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
这里已经在挂载的 plugins 目录安装好了 IK分词器。现在我们进入到 es 容器内部检查是否成功安装
# 进入容器内部docker exec -it elasticsearch /bin/bash# 查看 es 插件目录ls /usr/share/elasticsearch/plugins# 可以看到 elasticsearch-analysis-ik-7.4.2.zip
所以我们之后只需要在挂载的目录/mydata/elasticsearch/plugins下进行操作即可。
2. 解压
# 进入到 es 的插件目录cd /mydata/elasticsearch/plugins# 解压到 plugins 目录下的 ik 目录unzip elasticsearch-analysis-ik-7.4.2.zip -d ik# 删除下载的压缩包rm -f elasticsearch-analysis-ik-7.4.2.zip# 修改文件夹访问权限chmod -R 777 ik/
3. 查看安装的ik插件
# 进入 es 容器内部docker exec -it elasticsearch /bin/bash# 进入 es bin 目录cd /usr/share/elasticsearch/bin# 执行查看命令 显示 ikelasticsearch-plugin list# 退出容器exit# 重启 Elasticsearchdocker restart elasticsearch
4. 测试 ik 分词器
智能分词
GET _analyze{"analyzer": "ik_smart","text": "我是中国人"}

最大分词
GET _analyze{"analyzer": "ik_max_word","text": "我是中国人"}

自定义扩展分词库
对于一些比较新的词汇,ik分词器并不支持,所以我们需要自定义词库
我们在 nginx 中自定义分词文件,通过配置 es 的 ik 配置文件来远程调用 nginx 中的分词文件来实现自定义扩展词库。
注:默认 nginx 请求的是 数据目录的 html 静态目录
nginx 安装参考:docker 安装 nginx
1. nginx 中自定义分词文件
echo "尚硅谷" > /mydata/nginx/html/fenci.txt
nginx 默认请求地址为 ip:port/fenci.txt;
如果想要增加新的词语,只需要在该文件追加新的行并保存新的词语即可。
2. 给 es 配置自定义词库
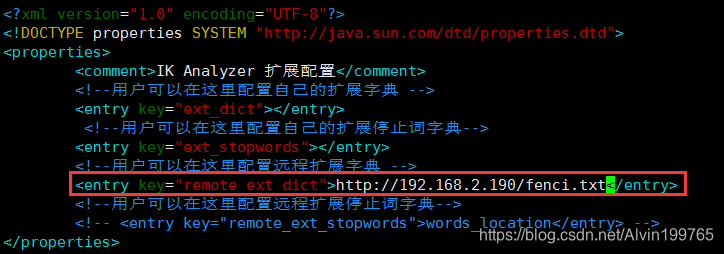
# 1. 打开并编辑 ik 插件配置文件vim /mydata/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
把这行的注释打开,里面配置上自己的分词字典
3. 重启 elasticsearch 容器
docker restart elasticsearch
4. 测试自定义词库
GET _analyze{"analyzer": "ik_smart","text": "尚硅谷"}
结果:


若有收获,就点个赞吧
0 人点赞
