- Deep Reinforcement Learning Nanodegree
- Content
- Part 01 : Introduction to Deep Reinforcement Learning
- Part 02 : Value-Based Methods
- Part 03 : Policy-Based Methods
- Part 04 : Multi-Agent Reinforcement Learning
- Part 05 (Elective): Special Topics in Deep Reinforcement Learning
- Part 06 (Elective): Neural Networks in PyTorch
- Part 07 (Elective): Computing Resources
- Part 08 (Elective): C++ Programming
- Content
Deep Reinforcement Learning Nanodegree
助教微信
udacity公众号
Nanodegree key: nd893
Version: 6.0.0
Locale: en-us
This course trains the learner to master the deep reinforcement learning skills that are powering amazing advances in AI.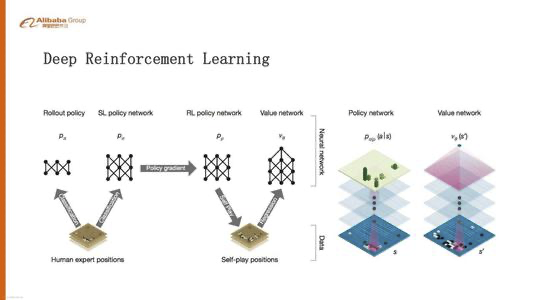
Content
Part 01 : Introduction to Deep Reinforcement Learning
Module 01: Introduction to Deep Reinforcement Learning
- Lesson 01: Welcome to Deep Reinforcement LearningWelcome to the Deep Reinforcement Learning Nanodegree program!
- Lesson 02: Knowledge, Community, and CareersYou are starting a challenging but rewarding journey! Take 5 minutes to read how to get help with projects and content.
- Lesson 03: Get Help with Your AccountWhat to do if you have questions about your account or general questions about the program.
- Lesson 04: Learning PlanObtain helpful resources to accelerate your learning in this first part of the Nanodegree program.
- Lesson 05: Introduction to RLReinforcement learning is a type of machine learning where the machine or software agent learns how to maximize its performance at a task.
- Lesson 06: The RL Framework: The ProblemLearn how to mathematically formulate tasks as Markov Decision Processes.
- Concept 01: Introduction
- Concept 02: The Setting, Revisited
- Concept 03: Episodic vs. Continuing Tasks
- Concept 04: Quiz: Test Your Intuition
- Concept 05: Quiz: Episodic or Continuing?
- Concept 06: The Reward Hypothesis
- Concept 07: Goals and Rewards, Part 1
- Concept 08: Goals and Rewards, Part 2
- Concept 09: Quiz: Goals and Rewards
- Concept 10: Cumulative Reward
- Concept 11: Discounted Return
- Concept 12: Quiz: Pole-Balancing
- Concept 13: MDPs, Part 1
- Concept 14: MDPs, Part 2
- Concept 15: Quiz: One-Step Dynamics, Part 1
- Concept 16: Quiz: One-Step Dynamics, Part 2
- Concept 17: MDPs, Part 3
- Concept 18: Finite MDPs
- Concept 19: Summary
- Lesson 07: The RL Framework: The SolutionIn reinforcement learning, agents learn to prioritize different decisions based on the rewards and punishments associated with different outcomes.
- Concept 01: Introduction
- Concept 02: Policies
- Concept 03: Quiz: Interpret the Policy
- Concept 04: Gridworld Example
- Concept 05: State-Value Functions
- Concept 06: Bellman Equations
- Concept 07: Quiz: State-Value Functions
- Concept 08: Optimality
- Concept 09: Action-Value Functions
- Concept 10: Quiz: Action-Value Functions
- Concept 11: Optimal Policies
- Concept 12: Quiz: Optimal Policies
- Concept 13: Summary
- Lesson 08: Monte Carlo MethodsWrite your own implementation of Monte Carlo control to teach an agent to play Blackjack!
- Concept 01: Review
- Concept 02: Gridworld Example
- Concept 03: Monte Carlo Methods
- Concept 04: MC Prediction - Part 1
- Concept 05: MC Prediction - Part 2
- Concept 06: MC Prediction - Part 3
- Concept 07: OpenAI Gym: BlackJackEnv
- Concept 08: Workspace - Introduction
- Concept 09: Coding Exercise
- Concept 10: Workspace
- Concept 11: Greedy Policies
- Concept 12: Epsilon-Greedy Policies
- Concept 13: MC Control
- Concept 14: Exploration vs. Exploitation
- Concept 15: Incremental Mean
- Concept 16: Constant-alpha
- Concept 17: Coding Exercise
- Concept 18: Workspace
- Concept 19: Summary
- Lesson 09: Temporal-Difference MethodsLearn about how to apply temporal-difference methods such as SARSA, Q-Learning, and Expected SARSA to solve both episodic and continuing tasks.
- Concept 01: Introduction
- Concept 02: Review: MC Control Methods
- Concept 03: Quiz: MC Control Methods
- Concept 04: TD Control: Sarsa
- Concept 05: Quiz: Sarsa
- Concept 06: TD Control: Q-Learning
- Concept 07: Quiz: Q-Learning
- Concept 08: TD Control: Expected Sarsa
- Concept 09: Quiz: Expected Sarsa
- Concept 10: TD Control: Theory and Practice
- Concept 11: OpenAI Gym: CliffWalkingEnv
- Concept 12: Workspace - Introduction
- Concept 13: Coding Exercise
- Concept 14: Workspace
- Concept 15: Analyzing Performance
- Concept 16: Quiz: Check Your Understanding
- Concept 17: Summary
- Lesson 10: Solve OpenAI Gym’s Taxi-v2 TaskWith reinforcement learning now in your toolbox, you’re ready to explore a mini project using OpenAI Gym!
- Lesson 11: RL in Continuous SpacesLearn how to adapt traditional algorithms to work with continuous spaces.
- Concept 01: Introducing Arpan
- Concept 02: Lesson Overview
- Concept 03: Discrete vs. Continuous Spaces
- Concept 04: Quiz: Space Representations
- Concept 05: Discretization
- Concept 06: Exercise: Discretization
- Concept 07: Workspace: Discretization
- Concept 08: Tile Coding
- Concept 09: Exercise: Tile Coding
- Concept 10: Workspace: Tile Coding
- Concept 11: Coarse Coding
- Concept 12: Function Approximation
- Concept 13: Linear Function Approximation
- Concept 14: Kernel Functions
- Concept 15: Non-Linear Function Approximation
- Concept 16: Summary
- Lesson 12: What’s Next?In the next parts of the Nanodegree program, you’ll learn all about how to use neural networks as powerful function approximators in reinforcement learning.
- Concept 01: Congratulations!
- Concept 02: What can you do now?
Part 02 : Value-Based Methods
Module 01: Value-Based Methods
- Lesson 01: Study PlanObtain helpful resources to accelerate your learning in the second part of the Nanodegree program.
- Lesson 02: Deep Q-NetworksExtend value-based reinforcement learning methods to complex problems using deep neural networks.
- Concept 01: From RL to Deep RL
- Concept 02: Deep Q-Networks
- Concept 03: Experience Replay
- Concept 04: Fixed Q-Targets
- Concept 05: Deep Q-Learning Algorithm
- Concept 06: Coding Exercise
- Concept 07: Workspace
- Concept 08: Deep Q-Learning Improvements
- Concept 09: Double DQN
- Concept 10: Prioritized Experience Replay
- Concept 11: Dueling DQN
- Concept 12: Rainbow
- Concept 13: Summary
- Lesson 03: NavigationTrain an agent to navigate a large world and collect yellow bananas, while avoiding blue bananas.Project Description - NavigationProject Rubric - Navigation
- Concept 01: Unity ML-Agents
- Concept 02: The Environment - Introduction
- Concept 03: The Environment - Play
- Concept 04: The Environment - Explore
- Concept 05: Project Instructions
- Concept 06: Benchmark Implementation
- Concept 07: Not sure where to start?
- Concept 08: Collaborate!
- Concept 09: Workspace
- Concept 10: (Optional) Challenge: Learning from Pixels
Module 02: Career Services
- Lesson 01: Opportunities in Deep Reinforcement LearningLearn about common career opportunities in deep reinforcement learning, and get tips on how to stay active in the community.
- Lesson 02: Optimize Your GitHub ProfileOther professionals are collaborating on GitHub and growing their network. Submit your profile to ensure your profile is on par with leaders in your field.Project Description - Optimize Your GitHub ProfileProject Rubric - Optimize Your GitHub Profile
- Concept 01: Prove Your Skills With GitHub
- Concept 02: Introduction
- Concept 03: GitHub profile important items
- Concept 04: Good GitHub repository
- Concept 05: Interview with Art - Part 1
- Concept 06: Identify fixes for example “bad” profile
- Concept 07: Quick Fixes #1
- Concept 08: Quick Fixes #2
- Concept 09: Writing READMEs with Walter
- Concept 10: Interview with Art - Part 2
- Concept 11: Commit messages best practices
- Concept 12: Reflect on your commit messages
- Concept 13: Participating in open source projects
- Concept 14: Interview with Art - Part 3
- Concept 15: Participating in open source projects 2
- Concept 16: Starring interesting repositories
- Concept 17: Next Steps
Part 03 : Policy-Based Methods
Module 01: Policy-Based Methods
- Lesson 01: Study PlanObtain helpful resources to accelerate your learning in the third part of the Nanodegree program.
- Lesson 02: Introduction to Policy-Based MethodsPolicy-based methods try to directly optimize for the optimal policy.
- Concept 01: Policy-Based Methods
- Concept 02: Policy Function Approximation
- Concept 03: More on the Policy
- Concept 04: Hill Climbing
- Concept 05: Hill Climbing Pseudocode
- Concept 06: Beyond Hill Climbing
- Concept 07: More Black-Box Optimization
- Concept 08: Coding Exercise
- Concept 09: Workspace
- Concept 10: OpenAI Request for Research
- Concept 11: Why Policy-Based Methods?
- Concept 12: Summary
- Lesson 03: Policy Gradient MethodsPolicy gradient methods search for the optimal policy through gradient ascent.
- Lesson 04: Proximal Policy OptimizationLearn what Proximal Policy Optimization (PPO) is and how it can improve policy gradients. Also learn how to implement the algorithm by training a computer to play the Atari Pong game.
- Concept 01: Instructor Introduction
- Concept 02: Lesson Preview
- Concept 03: Beyond REINFORCE
- Concept 04: Noise Reduction
- Concept 05: Credit Assignment
- Concept 06: Policy Gradient Quiz
- Concept 07: pong with REINFORCE (code walkthrough)
- Concept 08: pong with REINFORCE (workspace)
- Concept 09: Importance Sampling
- Concept 10: PPO part 1- The Surrogate Function
- Concept 11: PPO part 2- Clipping Policy Updates
- Concept 12: PPO summary
- Concept 13: pong with PPO (code walkthrough)
- Concept 14: pong with PPO (workspace)
- Lesson 05: Actor-Critic MethodsMiguel Morales explains how to combine value-based and policy-based methods, bringing together the best of both worlds, to solve challenging reinforcement learning problems.
- Concept 01: Introduction
- Concept 02: Motivation
- Concept 03: Bias and Variance
- Concept 04: Two Ways for Estimating Expected Returns
- Concept 05: Baselines and Critics
- Concept 06: Policy-based, Value-Based, and Actor-Critic
- Concept 07: A Basic Actor-Critic Agent
- Concept 08: A3C: Asynchronous Advantage Actor-Critic, N-step
- Concept 09: A3C: Asynchronous Advantage Actor-Critic, Parallel Training
- Concept 10: A3C: Asynchronous Advantage Actor-Critic, Off- vs On-policy
- Concept 11: A2C: Advantage Actor-Critic
- Concept 12: A2C Code Walk-through
- Concept 13: GAE: Generalized Advantage Estimation
- Concept 14: DDPG: Deep Deterministic Policy Gradient, Continuous Actions
- Concept 15: DDPG: Deep Deterministic Policy Gradient, Soft Updates
- Concept 16: DDPG Code Walk-through
- Concept 17: Summary
- Lesson 06: Deep RL for Finance (Optional)Learn how to apply deep reinforcement learning techniques for optimal execution of portfolio transactions.
- Concept 01: Introduction
- Concept 02: High Frequency Trading
- Concept 03: Challenges of Supervised Learning
- Concept 04: Advantages of RL for Trading
- Concept 05: Optimal Liquidation Problem - Part 1 - Introduction
- Concept 06: Optimal Liquidation Problem - Part 2 - Market Impact
- Concept 07: Optimal Liquidation Problem - Part 3 - Price Model
- Concept 08: Optimal Liquidation Problem - Part 4 - Expected Shortfall
- Concept 09: Almgren and Chriss Model
- Concept 10: Trading Lists
- Concept 11: The Efficient Frontier
- Concept 12: DRL for Optimal Execution of Portfolio Transactions
- Lesson 07: Continuous ControlTrain a double-jointed arm to reach target locations.Project Description - Continuous ControlProject Rubric - Continuous Control
- Concept 01: Unity ML-Agents
- Concept 02: The Environment - Introduction
- Concept 03: The Environment - Real World
- Concept 04: The Environment - Explore
- Concept 05: Project Instructions
- Concept 06: Benchmark Implementation
- Concept 07: Not sure where to start?
- Concept 08: General Advice
- Concept 09: Collaborate!
- Concept 10: Workspace
- Concept 11: (Optional) Challenge: Crawl
Module 02: Career Services
- Lesson 01: Take 30 Min to Improve your LinkedInFind your next job or connect with industry peers on LinkedIn. Ensure your profile attracts relevant leads that will grow your professional network.Project Description - Improve Your LinkedIn ProfileProject Rubric - Improve Your LinkedIn Profile
- Concept 01: Get Opportunities with LinkedIn
- Concept 02: Use Your Story to Stand Out
- Concept 03: Why Use an Elevator Pitch
- Concept 04: Create Your Elevator Pitch
- Concept 05: Use Your Elevator Pitch on LinkedIn
- Concept 06: Create Your Profile With SEO In Mind
- Concept 07: Profile Essentials
- Concept 08: Work Experiences & Accomplishments
- Concept 09: Build and Strengthen Your Network
- Concept 10: Reaching Out on LinkedIn
- Concept 11: Boost Your Visibility
- Concept 12: Up Next
Part 04 : Multi-Agent Reinforcement Learning
- Lesson 01: Take 30 Min to Improve your LinkedInFind your next job or connect with industry peers on LinkedIn. Ensure your profile attracts relevant leads that will grow your professional network.Project Description - Improve Your LinkedIn ProfileProject Rubric - Improve Your LinkedIn Profile
Module 01: Multi-Agent Reinforcement Learning
- Lesson 01: Study PlanObtain helpful resources to accelerate your learning in the fourth part of the Nanodegree program.
- Lesson 02: Introduction to Multi-Agent RL
- Concept 01: Introducing Chhavi
- Concept 02: Introduction to Multi-Agent Systems
- Concept 03: Motivation for Multi-Agent Systems
- Concept 04: Applications of Multi-Agent Systems
- Concept 05: Benefits of Multi-Agent Systems
- Concept 06: Markov Games
- Concept 07: Markov Games
- Concept 08: Approaches to MARL
- Concept 09: Cooperation, Competition, Mixed Environments
- Concept 10: Research Topics
- Concept 11: Paper Description, Part 1
- Concept 12: Paper Description, Part 2
- Concept 13: Summary
- Concept 14: Lab Instructions
- Concept 15: MADDPG - Lab
- Lesson 03: Case Study: AlphaZero
- Concept 01: AlphaZero Preview
- Concept 02: Zero-Sum Game
- Concept 03: Monte Carlo Tree Search 1 - Random Sampling
- Concept 04: Monte Carlo Tree Search 2 - Expansion and Back-propagation
- Concept 05: AlphaZero 1: Guided Tree Search
- Concept 06: AlphaZero 2: Self-Play Training
- Concept 07: TicTacToe using AlphaZero - walkthrough
- Concept 08: TicTacToe using AlphaZero - Workspace
- Concept 09: Advanced TicTacToe using AlphaZero
- Lesson 04: Collaboration and CompetitionTrain a pair of agents to play tennis.Project Description - Collaboration and CompetitionProject Rubric - Collaboration and Competition
- Concept 01: Unity ML-Agents
- Concept 02: The Environment - Introduction
- Concept 03: The Environment - Explore
- Concept 04: Project Instructions
- Concept 05: Benchmark Implementation
- Concept 06: Collaborate!
- Concept 07: Workspace
- Concept 08: (Optional) Challenge: Play Soccer
Part 05 (Elective): Special Topics in Deep Reinforcement Learning
Module 01: Special Topics in Deep Reinforcement Learning
- Lesson 01: Dynamic ProgrammingThe dynamic programming setting is a useful first step towards tackling the reinforcement learning problem.
- Concept 01: Introduction
- Concept 02: OpenAI Gym: FrozenLakeEnv
- Concept 03: Your Workspace
- Concept 04: Another Gridworld Example
- Concept 05: An Iterative Method, Part 1
- Concept 06: An Iterative Method, Part 2
- Concept 07: Quiz: An Iterative Method
- Concept 08: Iterative Policy Evaluation
- Concept 09: Implementation
- Concept 10: Mini Project: DP (Parts 0 and 1)
- Concept 11: Action Values
- Concept 12: Implementation
- Concept 13: Mini Project: DP (Part 2)
- Concept 14: Policy Improvement
- Concept 15: Implementation
- Concept 16: Mini Project: DP (Part 3)
- Concept 17: Policy Iteration
- Concept 18: Implementation
- Concept 19: Mini Project: DP (Part 4)
- Concept 20: Truncated Policy Iteration
- Concept 21: Implementation
- Concept 22: Mini Project: DP (Part 5)
- Concept 23: Value Iteration
- Concept 24: Implementation
- Concept 25: Mini Project: DP (Part 6)
- Concept 26: Check Your Understanding
- Concept 27: Summary
Part 06 (Elective): Neural Networks in PyTorch
- Lesson 01: Dynamic ProgrammingThe dynamic programming setting is a useful first step towards tackling the reinforcement learning problem.
Module 01: Neural Networks in PyTorch
- Lesson 01: Neural NetworksReview the basics of neural networks.
- Concept 01: Introducing Luis
- Concept 02: Why “Neural Networks”?
- Concept 03: Neural Network Architecture
- Concept 04: Feedforward
- Concept 05: Backpropagation
- Concept 06: Training Optimization
- Concept 07: Testing
- Concept 08: Overfitting and Underfitting
- Concept 09: Early Stopping
- Concept 10: Regularization
- Concept 11: Regularization 2
- Concept 12: Dropout
- Concept 13: Local Minima
- Concept 14: Vanishing Gradient
- Concept 15: Other Activation Functions
- Concept 16: Batch vs Stochastic Gradient Descent
- Concept 17: Learning Rate Decay
- Concept 18: Random Restart
- Concept 19: Momentum
- Lesson 02: Convolutional Neural NetworksReview the basics of convolutional neural networks.
- Concept 01: Introducing Cezanne
- Concept 02: Lesson Outline and Data
- Concept 03: CNN Architecture, VGG-16
- Concept 04: Convolutional Layers
- Concept 05: Defining Layers in PyTorch
- Concept 06: Notebook: Visualizing a Convolutional Layer
- Concept 07: Pooling, VGG-16 Architecture
- Concept 08: Pooling Layers
- Concept 09: Notebook: Visualizing a Pooling Layer
- Concept 10: Fully-Connected Layers, VGG-16
- Concept 11: Notebook: Visualizing FashionMNIST
- Concept 12: Training in PyTorch
- Concept 13: Notebook: Fashion MNIST Training Exercise
- Concept 14: Notebook: FashionMNIST, Solution 1
- Concept 15: Review: Dropout
- Concept 16: Notebook: FashionMNIST, Solution 2
- Concept 17: Feature Visualization
- Concept 18: Feature Maps
- Concept 19: First Convolutional Layer
- Concept 20: Visualizing CNNs (Part 2)
- Concept 21: Visualizing Activations
- Concept 22: Notebook: Feature Viz for FashionMNIST
- Concept 23: Last Feature Vector and t-SNE
- Concept 24: Occlusion, Saliency, and Guided Backpropagation
- Concept 25: Summary of Feature Viz
- Lesson 03: Deep Learning with PyTorchLearn how to use PyTorch for building deep learning models.
- Concept 01: Introducing Mat
- Concept 02: Introducing PyTorch
- Concept 03: PyTorch Tensors
- Concept 04: Defining Networks
- Concept 05: Training Networks
- Concept 06: Fashion-MNIST Exercise
- Concept 07: Inference & Validation
- Concept 08: Saving and Loading Trained Networks
- Concept 09: Loading Data Sets with Torchvision
- Concept 10: Transfer Learning
Part 07 (Elective): Computing Resources
- Lesson 01: Neural NetworksReview the basics of neural networks.
Module 01: Computing Resources
- Lesson 01: Udacity WorkspacesLearn how to use Workspaces in the Udacity classroom.
- Concept 01: Overview
- Concept 02: Introduction to Workspaces
- Concept 03: Workspaces: Best Practices
Part 08 (Elective): C++ Programming
- Lesson 01: Udacity WorkspacesLearn how to use Workspaces in the Udacity classroom.
Module 01: C++ Basics
- Lesson 01: C++ Getting StartedThe differences between C++ and Python and how to write C++ code.
- Concept 01: Introduction
- Concept 02: Lesson Overview
- Concept 03: Elecia White
- Concept 04: Why C++
- Concept 05: Python and C++ Comparison
- Concept 06: Static vs Dynamic Typing
- Concept 07: C++ - A Statically Typed Language
- Concept 08: Basic Data Types
- Concept 09: Floating versus Double [demonstration]
- Concept 10: Doubles are Bigger
- Concept 11: Common Errors and Error Messages
- Concept 12: C++ Functions
- Concept 13: Anatomy of a Function
- Concept 14: Multiple Outputs
- Concept 15: Two Functions Same Name
- Concept 16: Function Signatures 1
- Concept 17: Function Signatures 2
- Concept 18: If and Boolean Logic
- Concept 19: While and For Loops
- Concept 20: Switch Statement
- Concept 21: Libraries
- Concept 22: Forge on!
- Lesson 02: C++ VectorsTo program matrix algebra operations and translate your Python code, you will need to use C++ Vectors. These vectors are similar to Python lists, but the syntax can be somewhat tricky.
- Concept 01: C++ Vectors
- Concept 02: Namespaces
- Concept 03: Python Lists vs. C++ Vectors
- Concept 04: Initializing Vector Values
- Concept 05: Vector Methods
- Concept 06: Vectors and For Loops
- Concept 07: Math and Vectors
- Concept 08: 1D Vector Playground
- Concept 09: 2D Vectors
- Concept 10: 2D Vectors and For Loops
- Concept 11: 2D Vector Playground
- Concept 12: Next Lesson
- Lesson 03: Practical C++Learn how to write C++ code on your own computer and compile it into a executable program without running into too many compilation errors.
- Lesson 04: C++ Object Oriented ProgrammingLearn the syntax of C++ object oriented programming as well as some of the additional OOP features provided by the language.
- Concept 01: Introduction
- Concept 02: Python vs. C++
- Concept 03: Why use Object Oriented Programming?
- Concept 04: Using a Class in C++ [Demo]
- Concept 05: Explanation of the Main.cpp File
- Concept 06: Practice Using a Class
- Concept 07: Review: Anatomy of a Class
- Concept 08: Other Facets of C++ Classes
- Concept 09: Private and Public
- Concept 10: Header Files
- Concept 11: Inclusion Guards
- Concept 12: Implement a Class
- Concept 13: Class Variables
- Concept 14: Class Function Declarations
- Concept 15: Constructor Functions
- Concept 16: Set and Get Functions
- Concept 17: Matrix Functions
- Concept 18: Use an Inclusion Guard
- Concept 19: Instantiate an Object
- Concept 20: Running your Program Locally
- Lesson 01: C++ Getting StartedThe differences between C++ and Python and how to write C++ code.
- Module 02: Performance Programming in C++
- Lesson 01: C++ Intro to OptimizationOptimizing C++ involves understanding how a computer actually runs your programs. You’ll learn how C++ uses the CPU and RAM to execute your code and get a sense for what can slow things down.
- Concept 01: Course Introduction
- Concept 02: Empathize with the Computer
- Concept 03: Intro to Computer Hardware
- Concept 04: Embedded Terminal Explanation
- Concept 05: Demo: Machine Code
- Concept 06: Assembly Language
- Concept 07: Binary
- Concept 08: Demo: Binary
- Concept 09: Demo: Binary Floats
- Concept 10: Memory and the CPU
- Concept 11: Demo: Stack vs Heap
- Concept 12: Outro
- Lesson 02: C++ Optimization PracticeNow you understand how C++ programs execute. It’s time to learn specific optimization techniques and put them into practice. This lesson will prepare you for the lesson’s code optimization project.
- Concept 01: Introduction
- Concept 02: Software Development and Optimization
- Concept 03: Optimization Techniques
- Concept 04: Dead Code
- Concept 05: Exercise: Remove Dead Code
- Concept 06: If Statements
- Concept 07: Exercise: If Statements
- Concept 08: For Loops
- Concept 09: Exercise: For Loops
- Concept 10: Intermediate Variables
- Concept 11: Exercise: Intermediate Variables
- Concept 12: Vector Storage
- Concept 13: Exercise: Vector Storage
- Concept 14: References
- Concept 15: Exercise: References
- Concept 16: Sebastian’s Synchronization Story
- Concept 17: Static Keyword
- Concept 18: Exercise: Static Keyword
- Concept 19: Speed Challenge
- Lesson 01: C++ Intro to OptimizationOptimizing C++ involves understanding how a computer actually runs your programs. You’ll learn how C++ uses the CPU and RAM to execute your code and get a sense for what can slow things down.
【点击购买】

若有收获,就点个赞吧
0 人点赞
