MySQL SQL基础
4.1 SQL介绍
SQL语言 (Structured Query Language)☞ 结构化的查询语言:关系型数据库中通用的一类语言。(关系型数据库中,语言基本类似)
SQL标准:89 92 99 03
4.2 SQL类型
常用类型有:
mysql客户端自带的功能:
mysql> help;
mysql服务服务端命令:
mysql> help contents You asked for help about help category: “Contents”For more information, type ‘help
常用SQL类型:
DQL:(data query language) 数据查询个语言—-用于查询和检索数据
DML:(data manipulation language)数据操作语言—-用户数据写操作(增删改)*
DDL:(data defualt language)数据定义语言—-用于创建数据结构
DCL: (data control language) 数据控制语言—-用于用户权限管理
TPL: Transaction Process Language 事务处理语言, 辅助DML进行操作归属DML
4.3 SQL的各种名词
4.3.1 sql_mode SQL模式
作用:规范SQL语句书写的方式(默认就有很多规范,my.cnf可加入sql_mode参数)
mysql> select @@sql_mode;
ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
面试:sql_mode解释规范SQL语句书写方式作用 (影响了SQL执行行为,定了些规矩)
举例:举一个例子:在现实的数学角度汇总,出发运算中,除数不能为0
所以通过设定sql_mode参数,规范我们,不会出现类似在数学中使用0作为除数的这种违背现实数学逻辑的SQL语句
再比如说,实际生活中,日期不会出现0月0日的情况
1. 个各版本的区别:5.7 版本之后加入了 OLLY_GROUP_BY
4.3.2 字符集 (charset)及校对规则(collation)
字符集:建库建表时使用,都会做字符集的设定
UTF8 —-(不完整,不完善)
UTF8mb4 ——(建议使用 8.0默认) 8.0 之前默认字符集是latin存不了中文
面试举个例子: 比如emoji字符 mb4中支持 utf8不支持emoji表情,1个字符战4个字节。utf8存不下—>3字节
校对规则 / 排序规则
每种字符集都有多种校对规则 简单来说就是大小写是否敏感(影响数据最终排序结果)
mysql> show collation;
4.3.3 数据类型
作用: 规范,约束。录入数据的时候更加规范,有意义。
类型有: 选择:根据数据大小选择合适类型(年龄:tinyint )
数字类型: 整数 小数
| 储存长度 | 二进制范围 | 十进制范围 | |
|---|---|---|---|
| tinyint | 1B字节 (8位) | 0-255 (最多存3位数) | 0~255, -128~127 |
| int | 4B字节 (32位) | 0-2^32-1 (最多存10位数) | 0~2^32-1, -231~231-1 |
| bigin | 8B字节 (64位) | 0-2^32-1 (最多存20位数) | 0~2^64-1, -264~264-1 |
Ps: 面试题: 1. tinyint int bigint区别 (标红部分)
2.浮点数存储是怎么做的. 123.45 X100 —> 使用int类型放入数据库中 取: ÷100再取出。
b. 字符串类型 (较多)
| char(长度) | 定长字符串类型 最长255字符 |
|---|---|
| varchar(长度) | 变长字符串类型 最长65535字符(超过255—>自动转化text类型) |
| enum(‘bj’,sh) | 枚举字符串类型 |
应用场景(一般在225以内,大字段一般text、二进制..)
字符串固定——> char
字符串不固定—->varchar
#括号内数字问题 (括号内的值是字符的个数,无关字符类型,但是不同种类占用的空间是不同的,uft8,utf8bmb4:
数字/英文——>1字节
中文——>3字节 (gbk中1中文=2字节)
emoji——>4字节) 注意总长度不能超过数据类型的最大长度
mysql> show databases;+——————————+| Database |+——————————+| information_schema | | mysql | | performance_schema | | sys |+——————————+4 rows in set (0.04 sec) mysql> mysql> mysql> create database oldboy charset utf8mb4; Query OK, 1 row affected (0.01 sec) mysql> use oldboy Database changed mysql> create table t2 (n1 char(10),n2 varchar(10)); Query OK, 0 rows affected (0.03 sec) mysql> select from t2 ;+——————+—————-+| n1 | n2 |+——————+—————-+| adfafasdf | afafdfa | | 1234567890 | 123456789 |+——————+—————-+2 rows in set (0.00 sec) mysql> select length(n1) from t2;+——————+| length(n1) |+——————+| 9 | | 10 |+——————+2 rows in set (0.00 sec)
面试:
char(10) :最多10个字符,如果储存的字符不够10个,自动用空格填充剩余空间
varchar(10) :最多10个字符,按需分配空间,判断长度影响性能
abcde——> 1. 判断字符长度——> 2.申请空间——> 3.存字符——> 4.申请一个字节 储存5这个数字
彩蛋:
以上两种数据类型选择需考虑周全,会影响到索引应用
varchar类型在存储数据是会先判断字符长度,然后合理分配储存空间
而char类型,不会判断,立即分配空间
在固定长度中,还是推荐选择char类型
varchar类型,除了会储存字符串之外,还会额外使用1-2字节储存长度信息
补充: enum(‘bj’,sh) : 枚举类型 (字符串)
作用:就是把可能性的值,提前创建好,并加下标索引
列如:表格中有不同的省市,可先创建好,直接调用索引应用。(提升性能字的符串类型)
*时间类型
| 类型 | 范围 |
|---|---|
| timestamp 占4字节 | 1970-01-01 00:00:00.000000 至 2038-12-31 23:59:59.999999 |
| datetime 占8字节 | 1000-01-01 00:00:00.000000 至 9999-12-31 23:59:59.999999 |
二进制类型
json (也是一种数据类型,无结构化,任意存储数据,比较高效)
{
id:10
name:’zhang’
}
4.3.4 mysql数据库中的约束
| 名称 | 作用 |
|---|---|
| primary key :主键约束 | 非空且唯一,每张表只能有一个主键,作为聚簇索引。 |
| unique key 唯一键 | 必须不重复的值,独一无二的值 |
| not null: 非空约束 | 必须非空,我们建议每个列都设置非空 |
其他属性
| auto_increment: | 自增 |
|---|---|
| deault: | 默认值 配合非空 |
| commet: | 注释功能 |
| unsigned : | 针对数字列, 无符号 |
*4.4 SQL的应用
4.4.1 Client
\? == help : 帮助 \c : 类似Linux ctrl + c \G : 格式化输出(列很多,一行显示不开,堆到一起贼难受) notee / tee : 类似审计source : 导入SQL脚本,类似于 < system : 调用Linux命令exit = \q = ctrl + d : 退出会话
4.4.2 Server
Linux中一切皆文件,Linux中一切皆文件。 MySQL中一切皆SQL,MySQL一切皆表
4.4.21 DDL 数据定义语言(怎么规范别人)
1.库定义: 库名 库属性 (开发人员—>> 写,数据库人员—>> 审核,规范否?) 创建库: CREATE DATABASE oldgou CHARSET utf8mb4; 规范:1.库名:小写,业务有关,不要数字开头,库名勿长,勿使保留字符串2.必须制定字符集 查寻库: show create database oldguo; 修改库: alter database oldguo charset utf8mb4; 规范:A——> B (改完之后的字符集要比原来的丰富) B是A字符集的严格超集 删除库:危险,不代表生产操作,PS:生产数据库中,除了管理员,任何人没有删除权限 drop database worldpress; 2. 表定义: 创建表: CREATE TABLE wordpress.Untitled ( id int(11) NOT NULL AUTO_INCREMENT COMMENT ‘用户序号,主键’, name varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT ‘用户名’, age tinyint(4) NOT NULL DEFAULT 18 COMMENT ‘年龄’, gender char(1) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT ‘性别’, cometime datetime(0) NOT NULL COMMENT ‘注册时间’, shengfen enum(‘上海市’,’天津市’,’北京市’,’深圳市’,’重庆市’,’四川市’) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT ‘上海市’ COMMENT ‘地址’, PRIMARY KEY (id) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic; 建表规范(面试-优化建议): 1.表明: 小写字母(多平台的兼容) 2.不能数字开头,表明和业务有关 3.名字不要太长,不能使用关键字 4.必须设置存储引擎和字符集 5.#数据类型:合适,简短,足够 6.必须要有主键 ( ???) 7.每个列尽量设置not null 不知道填啥,设定默认值 8.每个列要有注释 9.列明不要太长
1.查询表: B站P25 1.1 mysql> show tables; +——————————-+ | Tables_in_wordpress | +——————————-+ | wp_users | +——————————-+ 1.2 mysql> desc wp_users ; #查看额外信息+—————-+———————————————————————————————————————-+| Field | Type | Null | Key | Default | Extra |+—————-+———————————————————————————————————————-+——| id | int(11) | NO | PRI | NULL | auto_increment || name | varchar(64) | NO | | NULL | || age | tinyint(4) | NO | | 18 | || gender | char(1) | NO | | NULL | || cometime | datetime | NO | | NULL | || shengfen | enum(‘上海市’,’天津市’,’北京市’,’深圳市’,’重庆市’,’四川市’) | NO上海市 |+—————-+———————————————————————————————————————-+7 rows in set (0.00 sec) 1.3 mysql> show create table wp_users; #查看建表语句 2.修改表:———>添加手机号: mysql> alter table wp_users add column shouji bigint not null comment ‘shoujihao’; | shouji | bigint(20) | NO | | NULL | ———>修改数字类型:将数库类型修改成char (原来的属性也要打上去) mysql> alter table wp_users modify shouji char(11) not null comment ‘手机号’ ; | shouji | char(11) | NO | | NULL | ———>删除列: mysql> alter table wp_users drop shouji; 3.删除表: mysql> drop table wp_users; mysql> show tables; Empty set (0.00 sec) ps:unique key 不能重复的值
DDL补充
手撕一张表:了解建表语句
USE oldboy
CREATE TABLE oldboy.student (
id INT NOT NULL PRIMARY KEY COMMENT ‘学号’,
idname VARCHAR(64) NOT NULL COMMENT ‘学生名’,
xinbie TINYINT NOT NULL DEFAULT 2 COMMENT ‘0代表女,1代表男,2代表不祥’,
addr ENUM(‘北京’,’上海’,’四川’,’湖北’,’新疆’,’杭州’) NOT NULL DEFAULT ‘北京’ COMMENT ‘地址’,
telep BIGINT NOT NULL UNIQUE KEY COMMENT ‘手机号’
) ENGINE=INNODB CHARSET=utf8mb4;
产品开发流程:
1.公司节单子,开发一个wordpress 博客产品
2.设计产品功能,产品逻辑图
3.研发部门,设计和开发产品功能
代码+数据库开发(ER图)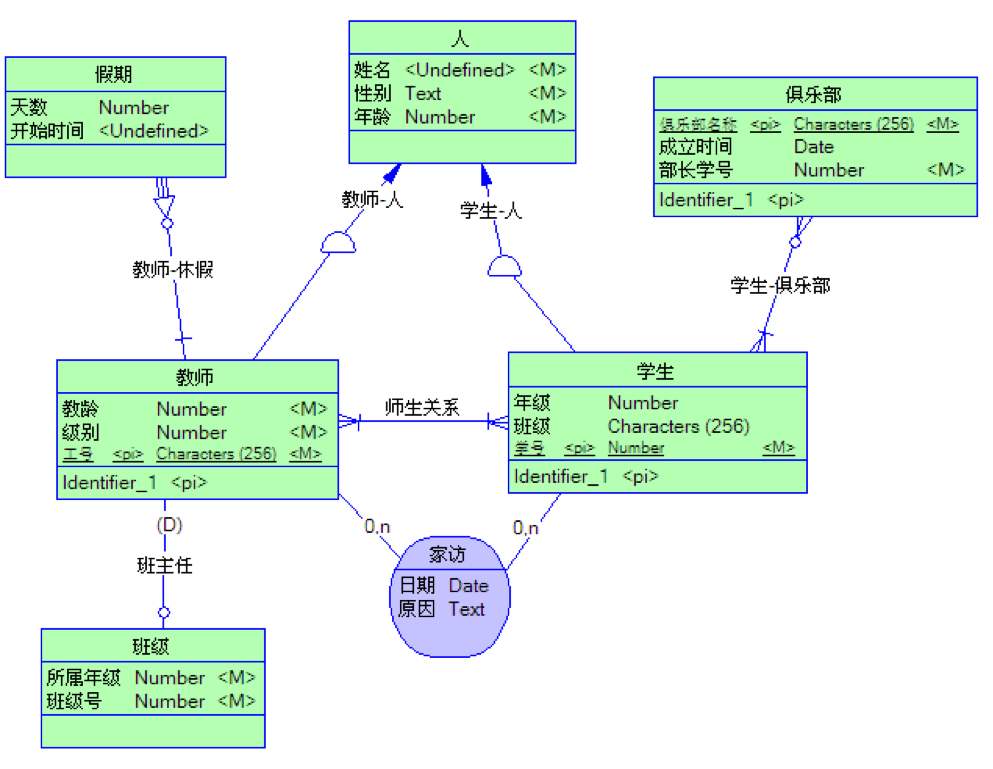
4.开发测试
5.交付生产系统git
6.DBA 审核 SQL语句,指定备份策略,日常维护规范,监控,数据库架 构设计,性能,故障
DDL面试题:
线上的DDL表的增删改查 (alter)操作对于生产的影响?????

SQL审核平台: yearing , inception
说明: 在Mysql中,DDL语句在对表进行操作时,是要锁”元数据表“的,此时所有修改类的命令无法正常运行 (夯主)扩展: 元数据是什么? ——> 类似于Linux中 Inode信息
所以: 对于大表,业务繁忙的表,进行线上的DDL操作时,要谨慎。尽量避免业务繁忙的期间进行DDL。
面试题回答要点: 1. sql语句是什么意思? 以上四条语句是对2张核心业务表,进行DDL加列操作的 2. 以上操作带来的影响? 在MySQL中,DDL语句在对表进行操作时,是要锁“元数据表”的,此时,所有修改类的命令读无法正常运行 在对于大表,业务繁忙的表,进行线上的DDL操作时,要谨慎。尽量避免业务繁忙的期间进行DDL。 3. 建议: 1 尽量避开业务繁忙期间,进行DDL。 走流程 2 建议使用: pt-onlines-schema-change(pt-osc) gh-os 工具进行DDL操作。 减少锁表的影响 3 如果是8.0版本, 可以不是勇pt工具 8.0以前一般需要借助以上工具。
作业: 自己扩展pt-osc工具 : 往列表中添加列 ,理解pt-osc工作原理
4.4.22.DCL ( 数据控制语言)
grant 授权操作 revoke 权限回收
4.4.23.DML (数据操作语言)
作用: 表中数据行进操作
insert(插入表) 1.规范用法: DESC student; INSERT INTO student(id,idname,xinbei,dianhua,dizhi) VALUES(1,’张三’,1,13109022310,’成都市’); 2.简单用法 INSERT INTO student VALUES(2,’oldboy’,2,151000,’成都市’); 3.部分录入 INSERT INTO student(idname,xinbei,dianhua) VALUES(‘oldgirl’,0,151000); 4.批量录入方法 INSERT INTO student(idname,xinbei,dianhua) VALUES(‘oldgirl1’,0,1510001),(‘oldgirl2’,0,1510002),(‘oldgirl3’,0,1510003); update (修改指定数据行的值) —前提:必须要明确修改哪一行,一般update语句都有where的条件(否则会改变其他所有行内容) 1.应用示例 UPDATE student SET idname=’oldgrilxxxxxxx’ WHERE id=4; delete (删除指定行的值) —前提:必须要明确要删除哪些行,一般delete语句都有where的条件(否侧会逐行清空) 1. DELETE FROM student WHERE id=9;
扩展:
伪删除(delete—->update——>查找标签为1的行)
需求:删除id为1的数据行?
—1.原操作: DELETE FROM student WHERE id=1;
查询数据: SELECT FROM student;
—==2.优化操作:==添加state状态列1 (修改表结构)
ALTER TABLE student ADD COLUMN state TINYINT NOT NULL DEFALT 1;
UPDATE student SET state=0 WHERE id=1; — 删除数据改为update语句
SELECT FROM student WHERE state=1 — 查询语句修改为查询状态为1
面试题: 说出 delete from student , drop table student, truncate table student,的区别
说明:
以上三条命令都能删除全表数据。
区别:
delete from student :逻辑上,逐行删除,如果数据行多,操作很慢。/ 并没有正真从磁盘上删除,只是存储层面打标记,磁盘空间不立即释放。 HWM高水位先不会降低(自增列不从1开始)
drop table student : 将表结构(元数据) 和数据行物理层次删除(只能从备份恢复)
truncate table student:清空表段中的所有数据页,物理磁盘空间会立即释放,很快很彻底,HWM高水位先回立即降低
1.问题 delete, drop,truncate如果不小心删除数据了,他们都可以恢复吗? 可以 常规:以上都可以通过备份的方式 恢复数据 (delete可以通,翻转日志(binlog)恢复) 灵活: 三种删除数据的情况都可以通过,《延迟从库》进行恢复
如何了解生产的业务: 查看表结构
—-> 准备学习环境: (world库由orcole官网下载)[root@db01 ~]# mysql -uroot -p123456
生产如何了解业务: 1. 查看每个列的列名,字面意思了解情况 2. 查看注释信息 3.查询前几行的数据,推断意思
* 4.4.24 DQL (数据查询语言)
select: 获取表中数据行
1. select单独使用 (MySQL独有)
1.select配合内置函数使用: mysql> select now();+——————————-+| now() |+——————————-+| 2020-10-07 18:06:42 |+——————————-+1 row in set (0.00 sec) mysql> use mysql mysql> select database();+——————+| database() |+——————+| mysql |+——————+1 row in set (0.00 sec) mysql> select concat(“woshinibaba”);+———————————-+| concat(“woshinibaba”) |+———————————-+| woshinibaba |+———————————-+1 row in set (0.00 sec) ——>扩展用法: mysql> select concat(user,”@”,host) from mysql.user;+————————————-+| concat(user,”@”,host) |+————————————-+| oldhou@10.0.0.% | | mysql.session@localhost | | mysql.sys@localhost | | root@localhost |+————————————-+4 rows in set (0.01 sec) 其他:(可 help查看函数) mysql> select version(); mysql> select user(); —查看登录用户 2.计算用法 mysql> select 10*100; 3.查询数据库的参数 mysql> select @@port; mysql> select @@datadir; mysql> select @@socket; mysql> select @@innodb_flush_log_at_trx_commit; #替代1:show variables like “%trx%”; 模糊匹配参数#替代2:show variable; 显示mysql中所有参数
2.select 标准用法
(配合其他子句使用)
—-单表前提: 默认执行顺序: 严格按照顺序写select 1. from 表1.. 表2.. 2. where 过滤条件1.. 过滤条件2..3. group by 条件1列.. 条件列2..3.5 select_list 列名列表4. having 过滤条1.. 过滤条2..5. order by 条件列1.. 条件列2..6. limit 限制条件1.. 限制条件2..
一,select 配合 from 子句的使用 语法: select 列 from 表; — 类似 cat/etc/passwd1.查询全表列 示例1: SELECT id,NAME,CountryCode,District,Population FROM world.city; 或 SELECT * FROM world.city; —生产不使用(虽然方便,但是文件特别大的时候类似有cat命令的缺陷) 2. 查询部分列。类似于awk取列 示例2: SELECT Name,Population FROM world.city;
select + Limit 显示10-20行
mysql> SELECT Id Name,Population FROM world.city LIMIT 10,20;
二,select + from + where —相当于grep过滤功能 1. WHERE 配合比较判断符 = < > >= <= != 查询city中,中国所有城市信息 示例: SELECT FROM world.city WHERE CountryCode=’CHN’; 查询city中,人口数量< 1000 示例: SELECT FROM world.city WHERE Population<1000; 2. WHERE 配合 like 语句 模糊查询(只适合字符串) 查询city中,国家代号是以CH开头的城市信息 示例: --注意不要出现前面带 %的模糊查询,不走索引 SELECT * FROM world.city WHERE CountryCode LIKE 'CH%'; 3. WHERE 配合逻辑连接符 AND OR 查询中国,人口大于500万的城市。 示例: SELECT * FROM world.city WHERE CountryCode='CHN' AND Population>5000000; 查询中国或美国的城市信息 示例: SELECT FROM world.city WHERE CountryCode=’CHN’ OR CountryCode=’USA’ AND Population>5000000; ps: 查询中国/美国,人口大于500万的城市。 SELECT FROM world.city WHERE CountryCode IN (‘CHN’,’USA’) AND Population>5000000; 4. WHERE + BETWEEN AND 查询城市人口数在100w-200w之间的。 SELECT FROM world.city WHERE Population<=5000000 AND Population>=2000000; 或者: SELECT FROM world.city WHERE Population BETWEEN 1000000 AND 2000000;
三, select + from + where + group by说明: group by 配合聚合函数(max(),min(),avg(),count(),goup_concat)使用, —->>> 碰到group by 一定会有聚合函数(站队———>报数)应用场景:需要对一张表中,按照不同数据特点,需要分组计算统计时用 group by + 聚合函数 聚合函数: max() : 最大值 min() :最小值 avg() :平均数 count() :统计个数 sum() :求和 group_concat() :列转行 1. 统计city中,每个国家的城市个数 SELECT CountryCode,COUNT(id) FROM world.city GROUP BY CountryCode; 2. 统计中国每个省的城市个数 SELECT District,COUNT(ID) FROM world.city WHERE CountryCode=’CHN’ GROUP BY District; 综合练习:1. 统计每个国家的总人口 SELECT CountryCode,SUM(Population)FROM world.city GROUP BY CountryCode; 2. 统计中国,每个省的总人口 SELECT District,COUNT(ID) FROM world.city WHERE CountryCode=’CHN’ GROUP BY District; 3. 统计中国,每个省总人口数,每个城市个数,(城市名列表???) SELECT District,SUM(Population),COUNT(ID) FROM world.city WHERE CountryCode=’CHN’ GROUP BY District; 讲解3: 直接在SELECT + name城市名 会报错--> 原因:MySQL不支持结果集是1行对多行显示方式 SELECT District,SUM(Population),COUNT(ID),Name FROM world.city WHERE CountryCode=’CHN’ GROUP BY District; —-> 报错:Expression #4 of SELECT list is not in GROUP BY clause and contains nonaggregated column ‘world.city.Name’ which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by —->使用 group_concat() :列转行 改变一对多的关系 SELECT District,SUM(Population),COUNT(ID),GROUP_CONCAT(Name) FROM world.city WHERE CountryCode=’CHN’ GROUP BY District;
group by + count():统计个数 流程
练习
PS:自己扩展pt-osc工具的使用,往列表中加载,理解pt-osc的工作原理->教程
3.单表查询
四, select + / having / order by / limit 的使用 1.1 having 场景: 需求在group by +聚合函数后,在做判断使用 说明:与 WHERE子句类型相似。having属于 后过滤 统计中国,每个省的总人口,只显示总人口数大于500W信息 SELECT District ,SUM(Population) FROM world.city WHERE CountryCode=’CHN’ GROUP BY District HAVING SUM(Population)>500000; 1.2 order by 场景:排序 统计中国,每个省的总人口,只显示总人口数大于500W,并且按照总人口数从小到大排列输出 SELECT District ,SUM(Population) FROM world.city WHERE CountryCode=’CHN’ GROUP BY District HAVING SUM(Population)>500000 ORDER BY SUM(Population) DESC; — 加DESC从大到小 1.3 limit 场景: 分页显示结果集 SELECT District ,SUM(Population) FROM world.city WHERE CountryCode=’CHN’ GROUP BY District HAVING SUM(Population)>500000 ORDER BY SUM(Population) DESC LIMIT 5; —显示前5名。limit 5,5 跳过5行,显示5行 (6-10)
4.多表连接查询
- 按需求差创建表结构CREATE TABLE student(sno INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT ‘学号’, sname VARCHAR(20) NOT NULL COMMENT ‘姓名’, sage TINYINT UNSIGNED NOT NULL COMMENT ‘年龄’, ssex ENUM(‘f’,’m’) NOT NULL DEFAULT ‘m’ COMMENT ‘性别’)ENGINE=INNODB CHARSET=utf8; CREATE TABLE course(cno INT NOT NULL PRIMARY KEY COMMENT ‘课程编号’, cname VARCHAR(20) NOT NULL COMMENT ‘课程名字’, tno INT NOT NULL COMMENT ‘教师编号’)ENGINE=INNODB CHARSET utf8; CREATE TABLE sc (sno INT NOT NULL COMMENT ‘学号’, cno INT NOT NULL COMMENT ‘课程编号’, score INT NOT NULL DEFAULT 0 COMMENT ‘成绩’)ENGINE=INNODB CHARSET=utf8; CREATE TABLE teacher(tno INT NOT NULL PRIMARY KEY COMMENT ‘教师编号’, tname VARCHAR(20) NOT NULL COMMENT ‘教师名字’)ENGINE=INNODB CHARSET utf8; INSERT INTO student(sno,sname,sage,ssex)VALUES (1,’zhang3’,18,’m’),(2,’zhang4’,18,’m’),(3,’li4’,18,’m’),(4,’wang5’,19,’f’),(5,’zh4’,18,’m’),(6,’zhao4’,18,’m’),(7,’ma6’,19,’f’),(8,’oldboy’,20,’m’),(9,’oldgirl’,20,’f’),(10,’oldp’,25,’m’); INSERT INTO teacher(tno,tname) VALUES(101,’oldboy’),(102,’hesw’),(103,’oldguo’),(104,’alex’); INSERT INTO course(cno,cname,tno)VALUES(1001,’linux’,101),(1002,’python’,102),(1003,’mysql’,103),(1004,’go’,105); INSERT INTO sc(sno,cno,score)VALUES(1,1001,80),(1,1002,59),(2,1002,90),(2,1003,100),(3,1001,99),(3,1003,40),(4,1001,79),(4,1002,61),(4,1003,99),(5,1003,40),(6,1001,89),(6,1003,77),(7,1001,67),(7,1003,82),(8,1001,70),(9,1003,80),(10,1003,96);

若有收获,就点个赞吧
0 人点赞
