主键索引
针对主键的索引实际上就是主键目录,这个主键目录呢,就是把每个数据页的页号,还有数据页里最小的主键值放在一起,组成一个索引的目录
B+树
你的表里的数据可能很多很多,比如有几百万,几千万,甚至单表几亿条数据都是有可能的,所
以此时你可能有大量的数据页,然后你的主键目录里就要存储大量的数据页和最小主键值,这怎么行呢?
所以在考虑这个问题的时候,实际上是采取了一种把索引数据存储在数据页里的方式来做的
也就是说,你的表的实际数据是存放在数据页里的,然后你表的索引其实也是存放在页里的,此时索引放在页里之后,就会有索引页,假设你有很多很多的数据页,那么此时你就可以有很多的索引页
但是现在又会存在一个问题了,你现在有很多索引页,但是此时你需要知道,你应该到哪个索引页里去找你的主键数据,是索引页20?还是索引页28?这也是个大问题
于是接下来我们又可以把索引页多加一个层级出来,在更高的索引层级里,保存了每个索引页和索引页里的最小主键值,如下图所示。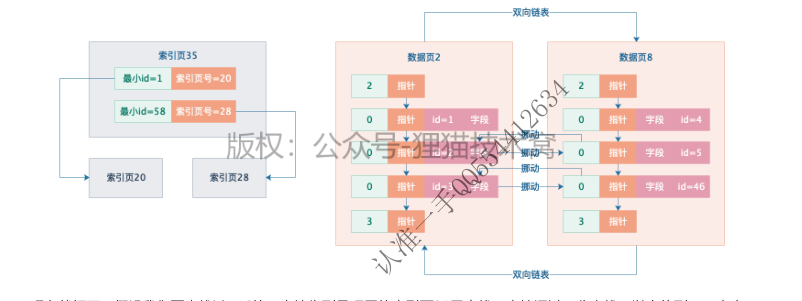
现在就好了,假设我们要查找id=46的,直接先到最顶层的索引页35里去找,直接通过二分查找可以定位到下一步应该到索引页20里去找,接下来到索引页20里通过二分查找定位,也很快可以定位到数据应该在数据页8里,再进入数据页8里,就可以找到id=46的那行数据了。
那么现在问题再次来了,假如你最顶层的那个索引页里存放的下层索引页的页号也太多了,怎么办呢?
此时可以再次分裂,再加一层索引页,比如下面图里那样子,大家看看下图。

这就是一颗B+树,属于数据结构里的一种树形数据结构,所以一直说MySQL的索引是用B+树来组成的
我们就以最简单最基础的主键索引来举例,当你为一个表的主键建立起来索引之后,其实这个主键的索引就是一颗B+树,然后当你要根据主键来查数据的时候,直接就是从B+树的顶层开始二分查找,一层一层往下定位,最终一直定位到一个数据页里,在数据页内部的目录里二分查找,找到那条数据
这就是索引最真实的物理存储结构,采用跟数据页一样的页结构来存储,一个索引就是很多页组成的一颗B+树
聚簇索引
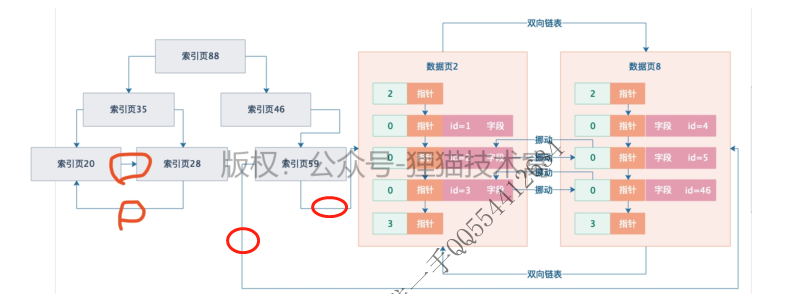
不知道大家把上面的图连起来看,有没有发现一些特点,就是说假设你把索引页和数据页综合起来看,他们都是连接在一起的,看起来就如同一颗完整的大的B+树一样,从根索引页88开始,一直到所有的数据页,其实组成了一颗巨大的B+树。
在这颗B+树里,最底层的一层就是数据页,数据页也就是B+树里的叶子节点了!
所以,如果一颗大的B+树索引数据结构里,叶子节点就是数据页自己本身,那么此时我们就可以称这颗B+树索引为聚簇索引!
也就是说,上图中所有的索引页+数据页组成的B+树就是聚簇索引!
针对主键之外的字段建立的二级索引
比如你插入数据的时候,一方面会把完整数据插入到聚簇索引的叶子节点的数据页里去,同时维护好聚簇索引,另一方面会为你其他字段建立的索引,重新再建立一颗B+树。
比如你基于name字段建立了一个索引,那么此时你插入数据的时候,就会重新搞一颗B+树,B+树的叶子节点也是数据页,但是这个数据页里仅仅放主键字段和name字段,大家看下面的示意图。
回表
就是说还需要根据主键值,再到聚簇索引里从根节点开始,一路找到叶子节点的数据页,定位到主键对应的完整数据行,此时才能把select 要的全部字段值都拿出来
*建立联合索引
比如name+age
此时联合索引的运行原理也是一样的,只不过是建立一颗独立的B+树,叶子节点的数据页里放了id+name+age,然后默认按照name排序,name一样就按照age排序,不同数据页之间的name+age值的排序也如此
多搞几个字段添加索引会有什么问题
1.每个字段的索引都是独立一颗B+树(空间占用大,耗费磁盘)
2.每次增删改数据记录时,都要维护多颗B+树,影响性能
(页内有排序,页间也有排序,会产生页分裂和合并,都要维护)
使用索引的一小点
order by 和group by时,若该字段无索引,还是会全表扫描
A表关联B表,B表关联字段需要加索引

若有收获,就点个赞吧
0 人点赞
